지도학습
- 정답을 알려주면서 진행되는 학습이며, 학습 시 데이터와 함께 레이블(정답)이 항상 제공되어야 함
- 주어진 데이터와 레이블을 이용해 새로운 데이터의 레이블을 예측해야 할 때 사용
장점 : 손쉽게 모델의 성능을 평가할 수 있음
단점 : 레이블이 없는 데이터는 레이블을 달기 위해 많은 시간과 비용이 든다.
대표적 예 : 분류, 회귀
비지도학습
- 레이블(정답)이 없이 진행되는 학습이며, 학습 시 레이블 없이 데이터만 필요함
- 데이터 자체에서 패턴을 찾아내야 할 때 사용
장점 : 별도로 레이블을 제공할 필요가 없으므로 시간 절약 가능
단점 : 레이블이 없으므로 모델의 성능을 평가하는 데 다소 어려움이 있음
대표적 예 : 클러스터링, 차원 축소
머신러닝 - 비지도 학습
클러스터링 - 추천 시스템, 고객 세분화, 데이터 마이닝, 목표 마케팅
차원 축소 - 빅데이터 가시화, 특징 추출
머신러닝 - 지도 학습
분류 - 영상분류, 사기 탐지, 진단, 번호판 인식
회귀 - 시장 예보, 날씨 예측, 인구증가 예측
머신러닝 - 강화 학습
실시간 판단, 인공지능 게임, 로봇 네비게이션, 학습 업무
1. 분류
데이터가 입력되었을 때 지도 학습을 통해 미리 학습된 레이블 중 하나 또는 여러 개의 레이블로 예측하는 것
- 이진 분류 : 둘 중 하나의 값으로 분류 (예: 남/여 중 분류)
- 다중 분류 : 여러 개 중 하나로 분류 (예 : 숫자 0~9 중 하나)
- 다중 레이블 분류 : 두 개 이상의 레이블로 분류 (예 : 뉴스 카테고리 분류)
2. 회귀
입력된 데이터에 대해 연속된 값으로 예측
날씨 예측, 주가 예측, 주택 가격 예측
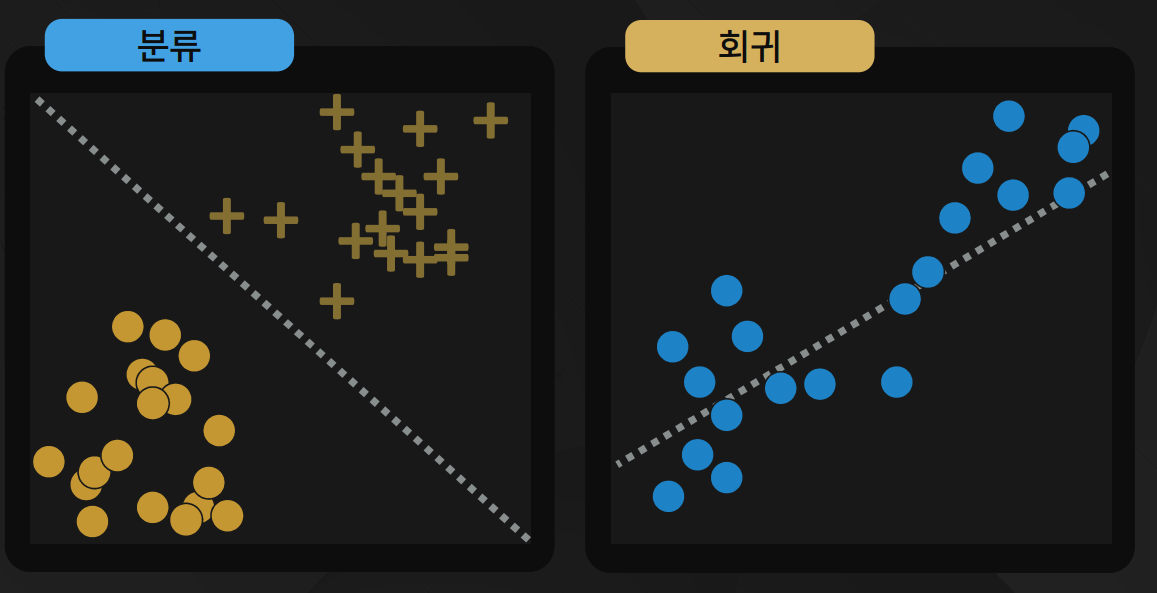
분류와 화귀의 차이점
분류 : 내일 날씨가 추울까요, 더울까요? (덥다, 춥다 예측)
회귀 : 내일 기온은 몇 도일까요? (32도 예측)
과대적합과 과소적합
과소적합(underfitting) : 모델 학습 시, 충분하지 못한 특징만으로 학습되어, 특정 특징에만 편향되게 학습된 것(편향이 높음)
- 테스트 데이터뿐만 아니라 하습 데이터에 대해서도 정확도가 낮게 나올 경우 과소 적합된 모델일 가능성이 높음
- 학습에 사용된 특징의 개수를 늘리는 방법을 통해 개선
과대적합(overfitting) : 학습 데이터에 대한 정확도는 매우 높지만 테스트 데이터 또는 학습 데이터 외의 데이터에는 정확도가 낮게 나오는 것(분산이 높음)
- 특징이 필요 이상으로 많은 경우 발생
- 훈련 데이터를 더 많이 모으거나 학습에 사용된 특징의 개수를 줄이는 방법을 통해 개선

씨앗 데이터 분석가.