머신러닝
1.지도학습과 비지도학습
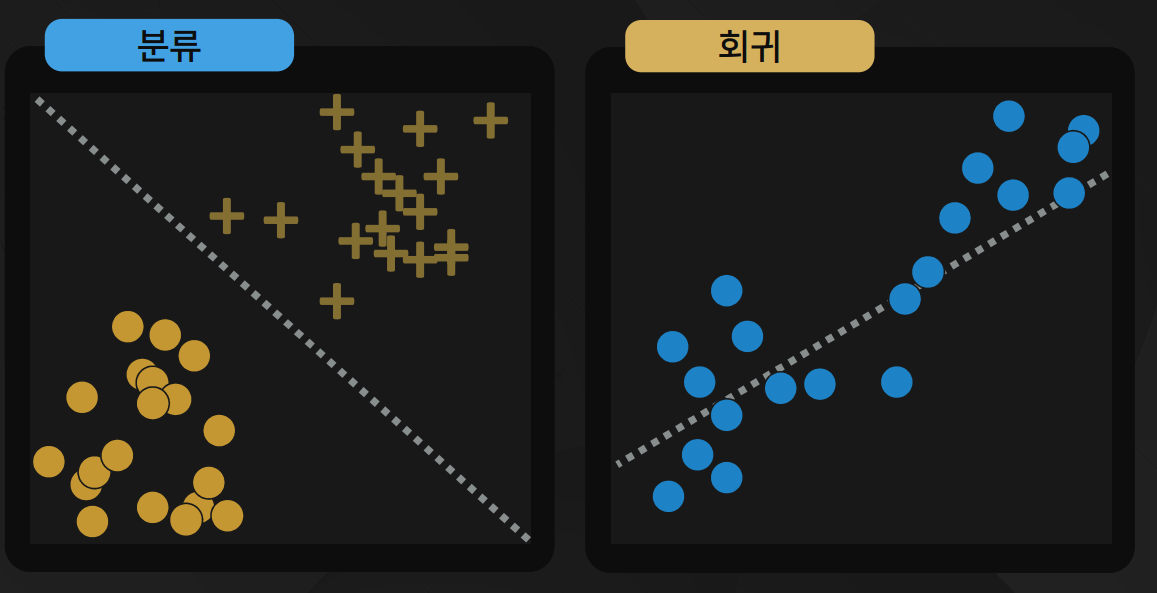
정답을 알려주면서 진행되는 학습이며, 학습 시 데이터와 함께 레이블(정답)이 항상 제공되어야 함주어진 데이터와 레이블을 이용해 새로운 데이터의 레이블을 예측해야 할 때 사용장점 : 손쉽게 모델의 성능을 평가할 수 있음단점 : 레이블이 없는 데이터는 레이블을 달기 위해
2.Scikit-learn 활용하기(의사결정나무, k-NN 예제)
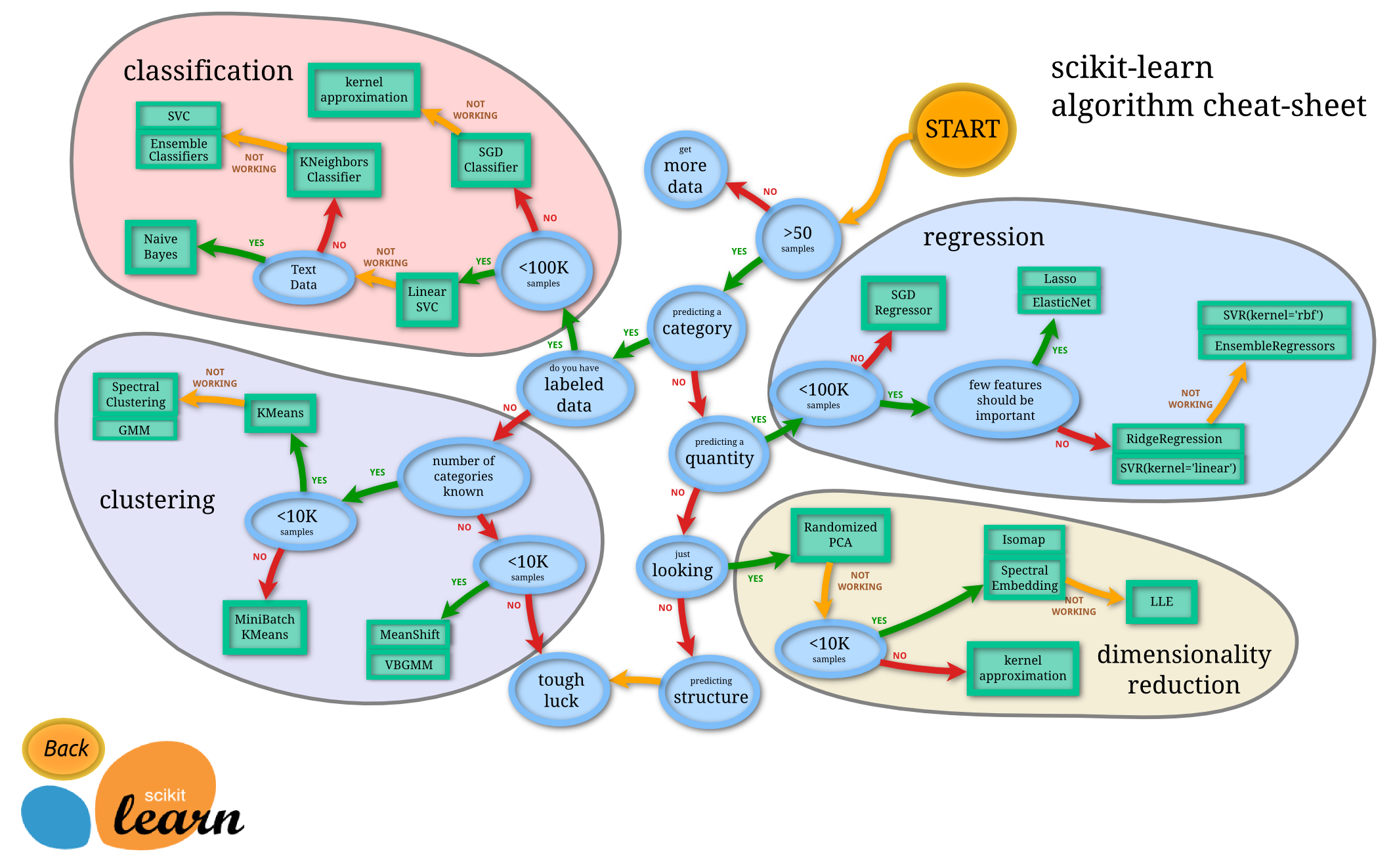
Scikit-learn이란?머신러닝 알고리즘을 파이썬에서 쉽게 활용할 수 있도록 도와주는 라이브러리.다양한 분류, 회귀, 클러스터링 알고리즘을 제공하며 쉽게 활용 가능데이터 전처리, 세부조정, 모델 평가 등을 쉽게 수행할 수 있음머신러닝 실습에 활용 가능한 샘플 데이터
3.SVM 알고리즘(분류)

서포트 벡터 머신(SVM) : 데이터 분류를 위하여 마진(margin)이 최대가 되는 결정 경계선(decision boundary)을 찾아내는 머신러닝 방법결정 경계선(Decision boundary) : 한강은 도시가 강북인지, 강남인지를 구분하는 결정 경계선. 서로
4.의사결정 트리(decision tree) 알고리즘
어떤 항목에 대한 관측 값과 목표 값을 연결시켜주는 예측 모델로써 결정 트리를 사용하는 머신러닝 방법영향력이 큰 특징을 상위 노드로, 영향력이 작은 특징은 하위 노드로 선택하는 것의사결정 트리는 특징별 영향력의 크고 작음을 비교하기 위해 두 가지 방법 중 하나를 사용함
5.나이브베이즈 알고리즘
나이브 베이즈 : 데이터를 나이브(단순)하게 독립적인 사건으로 가정하고, 독립 사건들을 베이즈 이론에 대입시켜 가장 높은 확률의 레이블로 분류를 실행하는 알고리즘$P(A|B) = \\frac{P(B|A) P(A)}{P(B)}$P(A|B) = 어떤 사건 B가 일어났을 때
6.앙상블 기법
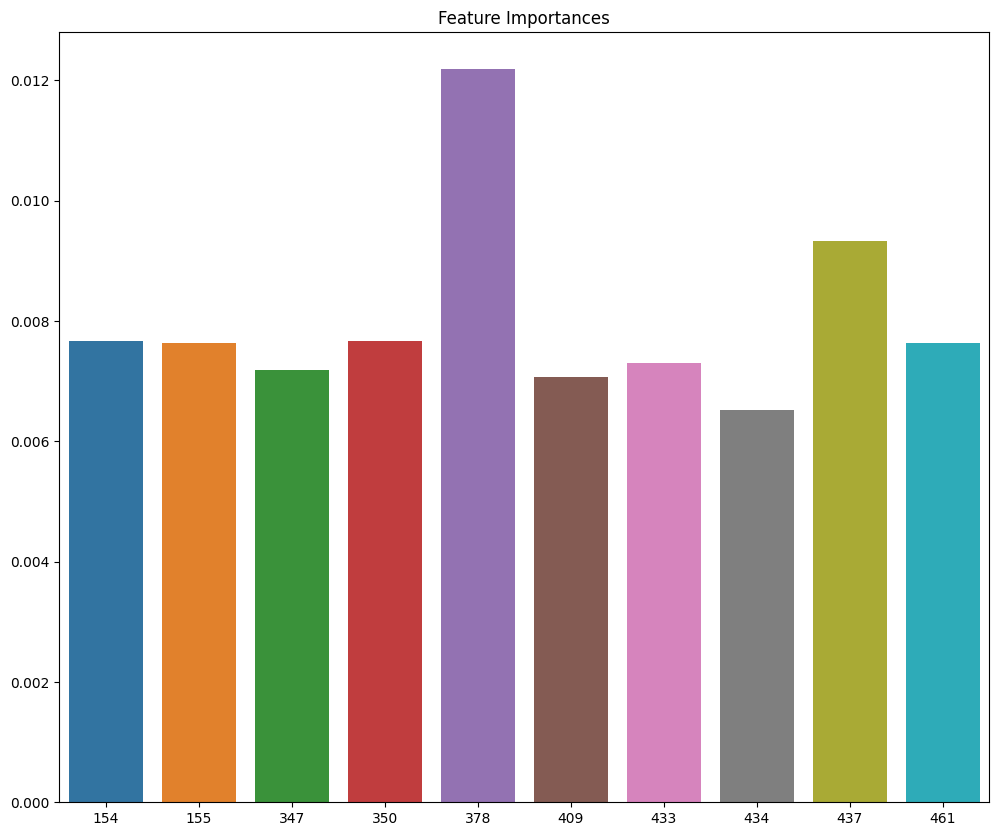
여러 가지 지도학습 모델이 서로 도와가며 학습하는 방법!여러 개의 분류기를 생성하고, 그 예측을 결합하여 더욱 정확한 예측을 도출하는 기법강력한 하나의 모델 < 약한 모델 여러 개를 조합하여 사용해 강한 모델 생성샘플을 여러 번 추출 -> 2. 모델을 학습 ->
7.k-means(k-평균) 알고리즘, 비지도학습
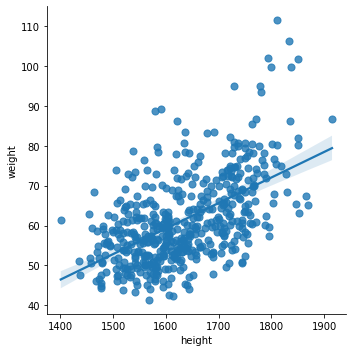
비지도 학습 : 레이블이 없는 데이터에서 특징 파악을 통해 일정한 규칙을 찾아내는 머신러닝 기법k-평균 군집화(K-means clustering)계층적 군집화(Hierarchical Clustering)DBSCAN주어진 데이터를 k개의 클러스터로 묶는 비지도학습 알고리