비지도 학습 : 레이블이 없는 데이터에서 특징 파악을 통해 일정한 규칙을 찾아내는 머신러닝 기법
- k-평균 군집화(K-means clustering)
- 계층적 군집화(Hierarchical Clustering)
- DBSCAN
k-평균 알고리즘(k-means clustering)
- 주어진 데이터를 k개의 클러스터로 묶는 비지도학습 알고리즘
- 데이터의 특징만으로 비슷한 데이터끼리 모아 군집화 된 클래스로 분류
k-평균 알고리즘 계산 순서
K값/중심 설정 -> 데이터의 클러스터 결정 -> 클러스터 내 중심 이동 -> 중심이 변경되지 않을 때까지 2,3번 과정 반복
k-평균 알고리즘 예제
교실에 있는 학생들의 키와 몸무게 값 : 3개의 군집으로 분류하기
- k값/최초 중심 설정 : k는 몇 개의 클래스로 분류할 것인지 나타내는 변수(k=3) -> k값에 따라 모델의 성능이 좌우됨
- 최초 중심 설정 방법 :
1. 무작위로 설정- 사용자가 직접 설정
- k-means++ << 주로 사용
k-means++ 중심 정하기
- 데이터를 가장 가까운 클러스터로 결정
- 첫 번째 데이터부터 마지막 데이터까지 순회하면서 데이터로부터 가장 가까운 클러스터로 데이터를 소속
- 마지막 데이터까지 순회하면 모든 데이터들이 어느 한 클러스터에 속하게 됨
- 클러스터 내 중심 이동
- 데이터의 순회가 완료되면 각 클러스터의 중심값을 실제 클러스터 내부의 데이터들의 중앙값으로 변경
- 중심이 변경되지 않을 때까지 반복
- 클러스터의 중심이 바뀌었기 때문에 일부 데이터는 소속된 클러스터가 바뀜
- 데이터의 순회가 완료되면 다시 클러스터의 중심을 소속된 데이터들의 중앙으로 옮김
- 이 과정을 소속된 데이터가 변경되지 않을 때까지 또는 클러스터의 중심이 변경되지 않을 때까지 반복
k-평균 알고리즘 장단점
장점 :
- 간단한 알고리즘으로 구현이 용이
- 계산 시간이 비교적 짧음(속도가 빠름)
단점 :
- 초기 클러스터 개수와 중심에 따라 결과가 크게 달라질 수 있음
- 결과 해석이 쉽지 않음
k-평균 알고리즘 기초 실습
# 라이브러리 import
import pandas as pd
from sklearn.cluster import KMeans
import seaborn as sns
from google.colab import drive
drive.mount('/gdrive')
filename = '/gdrive/My Drive/kmeans.csv'
#사이즈 코리아(https://sizekorea.kr/)
#2015년 남/녀 신장과 몸무게 데이터(500명)
df = pd.read_csv(filename)
print(df.head())
print(df.shape)
sns.lmplot(x='height', y='weight',
data=df,
fit_reg= True,
scatter_kws={"s": 50})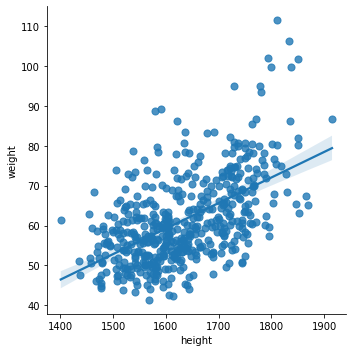
# 클러스터링 수행
data_points = df.values
kmeans = KMeans(n_clusters=3).fit(data_points)
kmeans.labels_[:10]
df['cluster'] = kmeans.labels_
df.head() 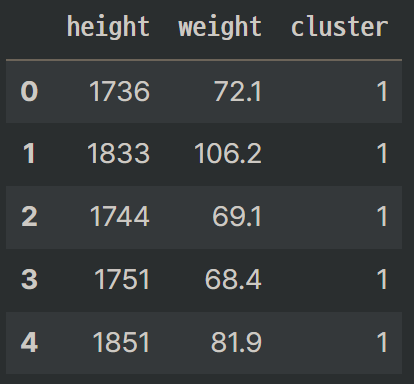
sns.lmplot(x='height',y='weight',
data=df,
fit_reg=False,
scatter_kws={"s": 30},
hue='cluster')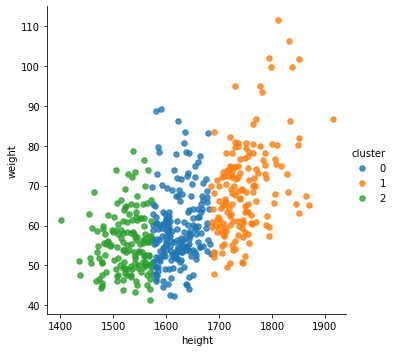
iris 데이터로 클러스터링
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
iris = load_iris()
data = iris.data[:,[0,1]]
data[:10]
# 클러스터링 수행 및 시각화
kmeans_iris = KMeans(n_clusters=3).fit(data)
labels = kmeans_iris.labels_
plt.title('Clustering Result', fontsize=20)
plt.scatter(data[:,0], data[:,1], c=labels, s=60) 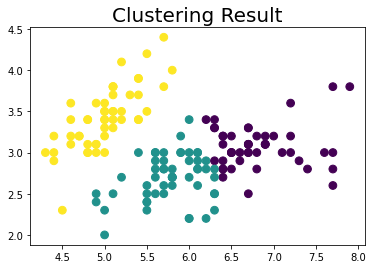
# 분류 정확도 확인
target = iris.target
df = pd.DataFrame({'labels': labels, 'target': target})
ct = pd.crosstab(df['labels'], df['target'])
ct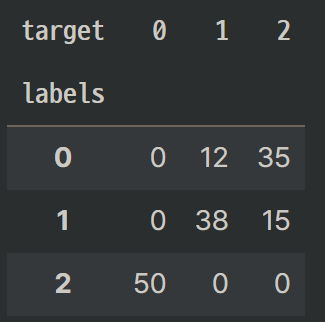
# 최적의 k값 찾기
num_clusters = list(range(2, 9))
inertias = []
for i in num_clusters:
model = KMeans(n_clusters=i)
model.fit(data)
inertias.append(model.inertia_)
plt.plot(num_clusters, inertias, '-o')
plt.xlabel('Num. of Clusters')
plt.ylabel('Inertia')
plt.show() 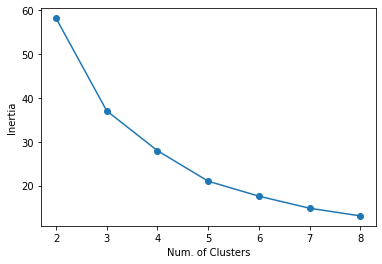

씨앗 데이터 분석가.