여러 가지 지도학습 모델이 서로 도와가며 학습하는 방법!
앙상블 기법이란?
여러 개의 분류기를 생성하고, 그 예측을 결합하여 더욱 정확한 예측을 도출하는 기법
- 강력한 하나의 모델 < 약한 모델 여러 개를 조합하여 사용해 강한 모델 생성
배깅(Bagging)
- 샘플을 여러 번 추출 -> 2. 모델을 학습 -> 3. 결과물을 집계
-
알고리즘의 안정성 및 정확성 향상을 위해 수행
-
부트스트랩(bootstrap)과 어그리게이팅(aggregating)을 합친 단어
-
대표적인 모델 : 랜덤 포레스트(Random Forest)
-
부트스트랩 : 분류 모델을 여러 개 만들어서 서로 다른 학습 데이터로 학습
-
어그리게이팅 : 서로 다른 예측값들을 투표를 통해 가장 높은 예측값으로 결정
부트스트랩
데이터를 약간 편향되도록 샘플링하는 기법. 의사결정 트리처럼 과대적합되기 쉬운 모델을 앙상블할 때 많이 사용
- 데이터 샘플링 시 편향을 높임으로써 분산이 높은 모델의 과대적합 위험을 줄이는 효과를 가져옴
- 각 분류 모델은 총 N개의 데이터보다 적은 데이터로 학습하되, 중복된 데이터를 허용함으로써, 편향이 높은 학습 데이터로 학습
- 데이터 샘플링 크기는 보통 전체 데잍의 60~70%를 사용
어그리게이팅
여러 분류 모델이 예측한 값들을 조합해서 하나의 결론을 도출하는 과정. 결론은 투표(voting)를 통해 결정
-
하드 보팅 : 배깅에 포함된 K개의 분류 모델에서 최대 득표를 받은 예측값으로 결론 도출
-
소프트 보팅 : 각 분류값별 확률을 합한 값을 점수로 사용해 최대 점수를 가진 분류값을 결론으로 도출
랜덤 포레스트(Random Forest)
- 다수의 결정 트리들을 배깅해서 예측을 실행하는 앙상블 기법
- 각 노드에 주어진 데이터를 샘플링해서 일부 데이터를 제외한 채 최적의 특징을 찾아 트리를 분기
- 모델의 편향을 증가시켜 과대적합의 위험을 감소
- 다양한 분야에서 비교적 좋은 성능을 보여줌
배깅을 이용한 포레스트 구성 : 트리들이 서로 조금씩 다른 특성을 갖게 되어 일반화 성능을 향상할 수 있음
부스팅(Boosting)
이전 분류기의 학습 결과를 바탕으로 다음 분류기의 학습 데이터의 샘플 가중치를 조정하여 학습하는 방법
- 동일한 알고리즘의 분류기를 순차적으로 학습해서 여러 개의 분류기를 만든 후, 테스트할 때 가중 투표를 통해 예측값을 결정
- 대표적인 모델 : XGBoost와 AdaBoost, GradientBoost
배깅 - 병렬적학습, 부스팅 - 순차적 학습
부스팅 예제
- 인물 사진 안에 있는 인물을 보고, 남자 또는 여자로 분류하는 의사결정 트리를 부스팅
- 테스트 결과, 남자 분류가 미흡할 경우, 남자 학습 데이터를 보강한 후 두 번째 의사결정 트리를 학습
- 두 번째 의사결정 트리의 테스트 결과에 따라 학습 데이터를 보강해서 세 번째 의사결정 트리를 학습
가중 투표 - 하드 보팅
- 분류기의 성능에 따라 가중치를 반영하여 투표 결과를 조정
가중 투표 - 소프트 보팅 - 단일 예측값이 아닌 모든 분류값에 대한 확률에 가중치를 곱한 값으로 최종 결론을 도출
앙상블 기법 활용 실습
# 라이브러리 import
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# 데이터셋 로드 및 확인
mnist = fetch_openml('mnist_784')
mnist_data = mnist.data[:10000]
mnist_target = mnist.target[:10000]
print(mnist_data)
print(mnist_data.shape)
print(mnist_target)
print(mnist_target.shape)
# 학습/테스트 데이터 나누기
X_train,X_test,y_train,y_test=train_test_split(mnist_data,
mnist_target,test_size=0.2)# 파라미터 없이 학습하기
dt_clf = tree.DecisionTreeClassifier()
rf_clf = RandomForestClassifier()
dt_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
accuracy_dt = accuracy_score(y_test, dt_pred)
accuracy_rf = accuracy_score(y_test, rf_pred)
print('의사결정트리 예측 정확도: {0:.4f}'.format(accuracy_dt))
print('랜덤 포레스트 예측 정확도: {0:.4f}'.format(accuracy_rf))의사결정트리 예측 정확도: 0.8065
랜덤 포레스트 예측 정확도: 0.9460 # 특징 중요도 확인
ft_importances_values = rf_clf.feature_importances_
ft_importances = pd.Series(ft_importances_values)
top10 = ft_importances.sort_values(ascending=False)[:10]
plt.figure(figsize=(12,10))
plt.title('Feature Importances')
sns.barplot(x=top10.index, y=top10)
plt.show()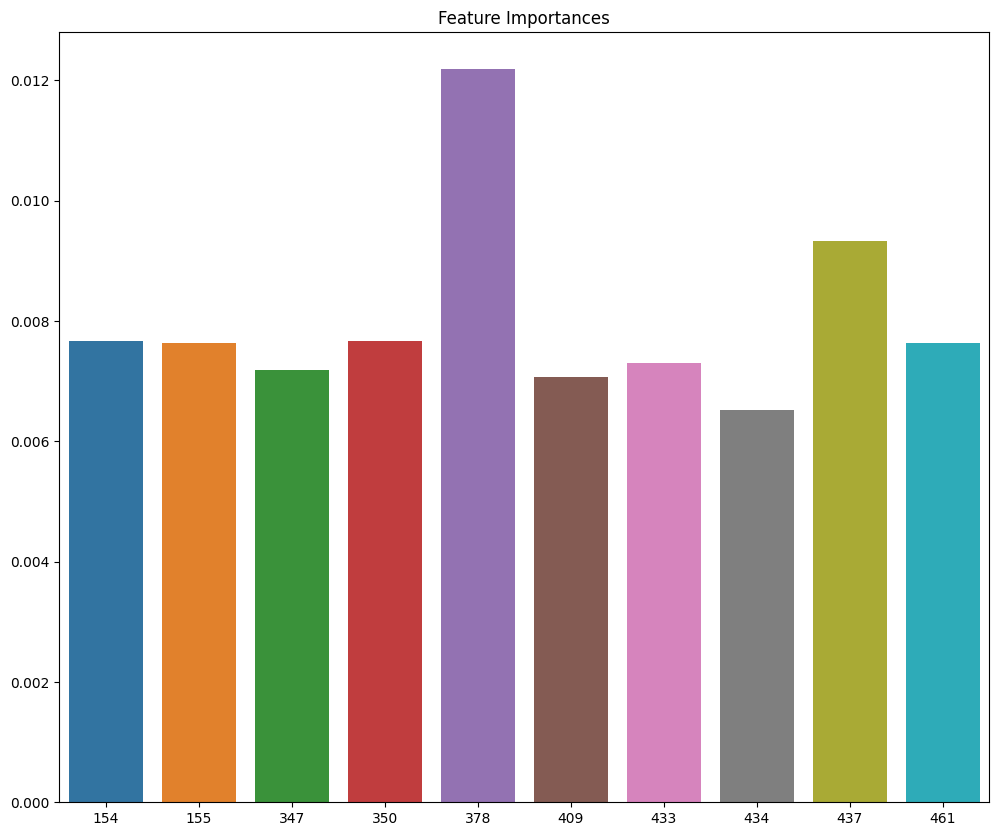
# 파라미터를 사용하여 학습하기
rf_param_grid ={
'n_estimators' : [100, 110, 120],
'min_samples_leaf' : [1, 2, 3],
'min_samples_split' : [2, 3, 4]
}
rf_clf = RandomForestClassifier(random_state = 0)
grid = GridSearchCV(rf_clf, param_grid = rf_param_grid, scoring='accuracy', n_jobs=1)
grid.fit(X_train, y_train)
print('최고 평균 정확도 : {0:.4f}'.format(grid.best_score_))
print(grid.best_params_)
'''
최고 평균 정확도 : 0.9449
{'min_samples_leaf': 1, 'min_samples_split': 3, 'n_estimators': 120}
'''보팅 앙상블 손글씨 분류
# 라이브러리 import
from sklearn import datasets
from sklearn import tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
# 손글씨 데이터 로드
np.random.seed(5)
mnist = datasets.load_digits()
features, labels = mnist.data, mnist.target
X_train,X_test,y_train,y_test=train_test_split(features,labels,test_size=0.2)
# 단일 모델 정확도 측정
dtree = tree.DecisionTreeClassifier(
criterion="gini", max_depth=8, max_features=32)
dtree = dtree.fit(X_train, y_train)
dtree_predicted = dtree.predict(X_test)
knn = KNeighborsClassifier(n_neighbors=299).fit(X_train, y_train)
knn_predicted = knn.predict(X_test)
svm = SVC(C=0.1, gamma=0.003,
probability=True).fit(X_train, y_train)
svm_predicted = svm.predict(X_test) print("[accuarcy]")
print("d-tree: ", accuracy_score(y_test, dtree_predicted))
print("knn : ", accuracy_score(y_test, knn_predicted))
print("svm : ", accuracy_score(y_test, svm_predicted))[accuarcy]
d-tree: 0.7916666666666666
knn : 0.8944444444444445
svm : 0.8916666666666667svm_proba = svm.predict_proba(X_test)
print(svm_proba[0:2]) [[0.0020036 0.00913495 0.00860886 0.00431856 0.0047931 0.8975483
0.0019513 0.01046554 0.04855539 0.0126204 ]
[0.00290208 0.01165787 0.86869732 0.00809384 0.00503728 0.01857273
0.00301187 0.00945009 0.05716773 0.0154092 ]]# 하드 보팅
voting_model = VotingClassifier(estimators=[
('Decision_Tree', dtree), ('k-NN', knn), ('SVM', svm)],
weights=[1,1,1], voting='hard')
voting_model.fit(X_train, y_train)
hard_voting_predicted = voting_model.predict(X_test)
accuracy_score(y_test, hard_voting_predicted)
# 결과 : 0.94722222222
# 소프트 보팅
voting_model = VotingClassifier(estimators=[
('Decision_Tree', dtree), ('k-NN', knn), ('SVM', svm)],
weights=[1,1,1], voting='hard')
voting_model.fit(X_train, y_train)
hard_voting_predicted = voting_model.predict(X_test)
accuracy_score(y_test, hard_voting_predicted)
# 결과 : 0.9333333333# 정확도 비교 시각화
x = np.arange(5)
plt.bar(x, height= [accuracy_score(y_test, dtree_predicted),
accuracy_score(y_test, knn_predicted),
accuracy_score(y_test, svm_predicted),
accuracy_score(y_test, hard_voting_predicted),
accuracy_score(y_test, soft_voting_predicted)])
plt.xticks(x, ['decision tree','knn','svm','hard voting','soft voting']); 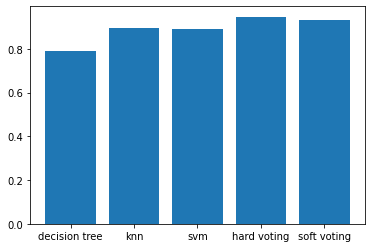

씨앗 데이터 분석가.