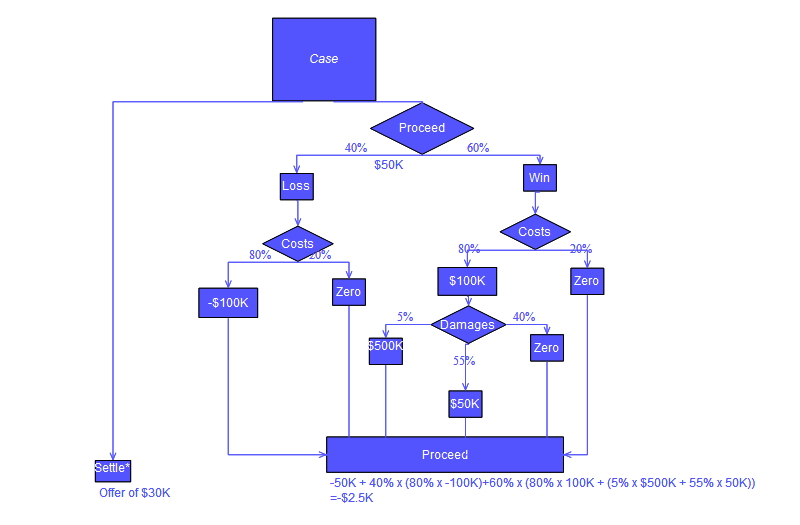
의사결정 트리
어떤 항목에 대한 관측 값과 목표 값을 연결시켜주는 예측 모델로써 결정 트리를 사용하는 머신러닝 방법
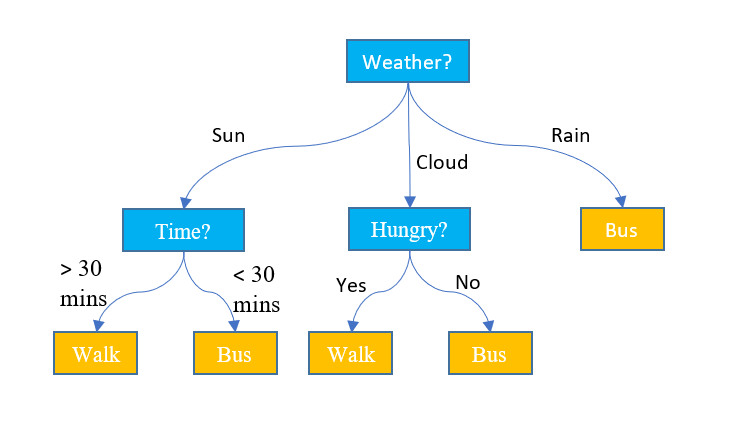
의사결정 트리의 핵심
- 영향력이 큰 특징을 상위 노드로, 영향력이 작은 특징은 하위 노드로 선택하는 것
- 의사결정 트리는 특징별 영향력의 크고 작음을 비교하기 위해 두 가지 방법 중 하나를 사용함
의사결정 트리 알고리즘의 장단점
장점 :
- 수학적인 지식이 없어도 결과를 해석하고 이해하기 쉬움
- 수치 데이터 및 범주 데이터에 모두 사용 가능
- 정확도가 비교적 높은편
단점 :
- 과대적합의 위험성이 높음
- 최적의 솔루션을 보장하지 않음
의사결정 트리 알고리즘 활용하기
서울 지역(구의) 경도와 위도 정보를 학습해서 임의로 입력된 지역(동)을 강동, 강서, 강남, 강북으로 분류하는 모델 구현
레이블의 의미
- district : 행정 구역(서초구, 송파구 등)
- dong : 구보다 작은 행정 구역(대치동, 도곡동)
- latitude : 위도
- longitud : 경도
- label : 한강 기준으로 동,서,남,북으로 구분한 지역 명칭
# 서울의 지역(구) 위치 데이터
district_dict_list = [
{'district': 'Gangseo-gu', 'latitude': 37.551000, 'longitude': 126.849500,
'label':'Gangseo'},
{'district': 'Yangcheon-gu', 'latitude': 37.52424, 'longitude': 126.855396,
'label':'Gangseo'}, …
{'district': 'Gangdong-gu', 'latitude': 37.554194, 'longitude': 127.151405,
'label':'Gangdong’},
{'district': 'Jungrang-gu', 'latitude': 37.593684, 'longitude': 127.090384,
'label':'Gangdong’}
]
train_df = pd.DataFrame(district_dict_list)
train_df = train_df[['district', 'longitude', 'latitude', 'label']]
# 서울의 대표적인 동 위치 데이터
dong_dict_list = [
{'dong': 'Gaebong-dong', 'latitude': 37.489853,
'longitude': 126.854547, 'label':'Gangseo'},
{'dong': 'Gochuk-dong', 'latitude': 37.501394,
'longitude': 126.859245, 'label':'Gangseo'}, …
{'dong': 'Amsa-dong', 'latitude': 37.552370,
'longitude': 127.127124, 'label':'Gangdong'},
{'dong': 'Chunho-dong', 'latitude': 37.547436,
'longitude': 127.137382, 'label':'Gangdong'}
]
test_df = pd.DataFrame(dong_dict_list)
test_df = test_df[['dong', 'longitude', 'latitude', 'label
# 학습 및 테스트에 불필요한 특징 제거
train_df.drop(['district'], axis=1, inplace = True)
test_df.drop(['dong'], axis=1, inplace = True)
X_train = train_df[['longitude', 'latitude']]
y_train = train_df[['label']]
X_test = test_df[['longitude', 'latitude']]
y_test = test_df[['label']]
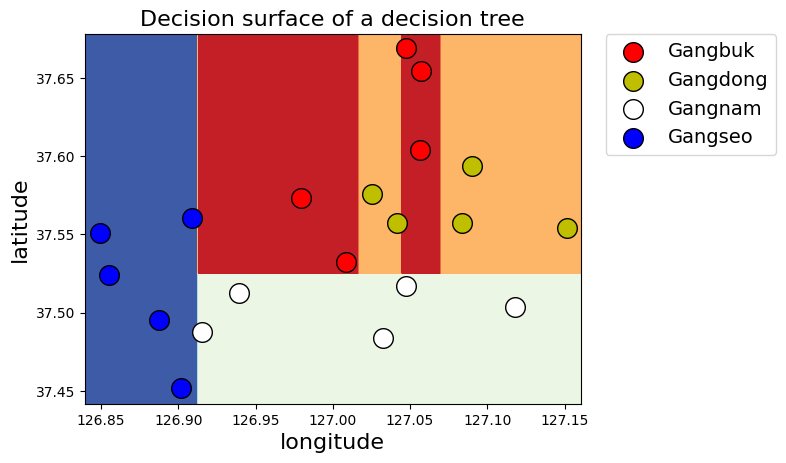
# 파라미터 없이 학습한 모델 시각화하기
from sklearn import tree
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
y_encoded = le.fit_transform(y_train)
clf = tree.DecisionTreeClassifier(random_state=35)
.fit(X_train, y_encoded)
display_decision_surface(clf,X_train, y_encoded)
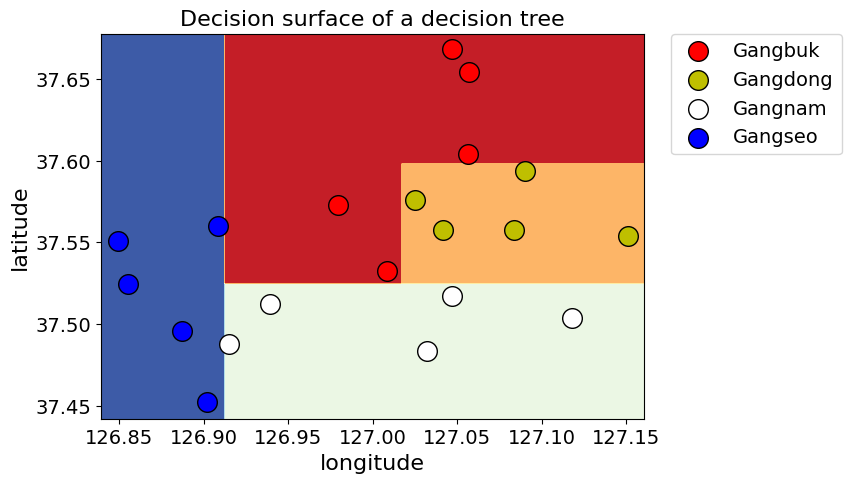
설정 가능한 파라미터
- max_depth : 트리의 최대 한도 깊이
- min_samples_split : 자식 노드를 갖기 위한 최소한의 데이터 개수
- min_samples_leaf : 리프 노드의 최소 데이터 개수
- random_state : 동일한 정수를 입력했을 때 학습 결과를 항상 같게 만들어주는 파라미터
# 파라미터를 설정한 모델 시각화하기
clf = tree.DecisionTreeClassifier(max_depth=4,
min_samples_split=2,
min_samples_leaf=2,
random_state=70).fit(X_train,
y_encoded.ravel())
display_decision_surface(clf,X_train, y_encoded)
# 모델 테스트 및 예측값 확인
from sklearn.metrics import accuracy_score
pred = clf.predict(X_test)
print("accuracy : " + str( accuracy_score(y_test.values.ravel(),
le.classes_[pred])) )
comparison = pd.DataFrame({'prediction':le.classes_[pred],
'ground_truth':y_test.values.ravel()})
comparisonaccuracy : 1.0
prediction ground_truth
0 Gangseo Gangseo
1 Gangseo Gangseo
2 Gangseo Gangseo
3 Gangseo Gangseo
4 Gangseo Gangseo
5 Gangnam Gangnam
6 Gangnam Gangnam
7 Gangnam Gangnam
8 Gangnam Gangnam
9 Gangnam Gangnam
10 Gangbuk Gangbuk
11 Gangbuk Gangbuk
12 Gangbuk Gangbuk
13 Gangbuk Gangbuk
14 Gangbuk Gangbuk
15 Gangdong Gangdong
16 Gangdong Gangdong
17 Gangdong Gangdong
18 Gangdong Gangdong
19 Gangdong Gangdong
씨앗 데이터 분석가.