나이브 베이즈의 이해 및 활용
나이브 베이즈 : 데이터를 나이브(단순)하게 독립적인 사건으로 가정하고, 독립 사건들을 베이즈 이론에 대입시켜 가장 높은 확률의 레이블로 분류를 실행하는 알고리즘
P(A|B) = 어떤 사건 B가 일어났을 때, 사건 A가 일어날 확률
P(B|A) = 어떤 사건 A가 일어났을 때, 사건 B가 일어날 확률
P(A) = 어떤 사건 A가 일어날 확률
P(B) = 어떤 사건 B가 일어날 확률
나이브 베이즈 알고리즘의 종류
- 가우시안 나이브 베이즈 분류
- 특징들의 값들이 정규 분포(가우시안 분포)가 되어 있다는 가정 하에 조건부 확률을 계산
- 연속적인 특징이 있는 데이터를 분류하는 데 적합
- 다른 종류의 나이브 베이즈 분류
- 이산적인 데이터의 경우, 나이브 베이즈 분류 모델 중 하나를 상황에 맞게 사용
다항 분포 나이브 베이즈 : 데이터의 특징이 출현 횟수로 표현되었을 때 사용. (예: 주사위를 10번 던졌을 때, 1이 한 번, 2가 두 번, 3이 세 번, 4가 네 번 나왔을 경우, (1,2,3,4,0,0)으로 나타남
베르누이 나이브 베이즈 : 데이터의 특징이 0 또는 1로 표현되었을 때 사용 (예: 주사위를 10번 던졌을 때, 1이 한 번, 2가 두 번, 3이 세 번, 4가 네 번 나왔을 경우, (1,1,1,1,0,0)으로 나타남
나이브 베이즈 알고리즘의 장단점
장점 :
- 실전에서 높은 정확도
- 문서 분류 및 스팸 메일 분류에 강함
- 계산 속도가 다른 모델들에 비해 상당히 빠름
단점 : - 모든 데이터의 특징을 독립적인 사건이라고 가정하는 것은 문서 분류에 적합할지는 모르나, 다른 분류 모델에는 제약이 될 수 있음
나이브 베이즈 알고리즘 활용하기
데이터 : iris
- sepal length(cm) : 꽃받침 길이
- sepal width(cm) : 꽃받침 너비
- petal length(cm) : 꽃잎 길이
- petal width(cm) : 꽃잎 너비
- target : 붓꽃(iris)의 종류
(setosa, versicolor, virginica)
# 필요한 라이브러리 import
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn import metrics
from sklearn.metrics import accuracy_score
# 데이터 획득 및 탐색
dataset = load_iris()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df['target'] = dataset.target
df.target = df.target.map({0:"setosa", 1:"versicolor",
2:"virginica"})
df.head()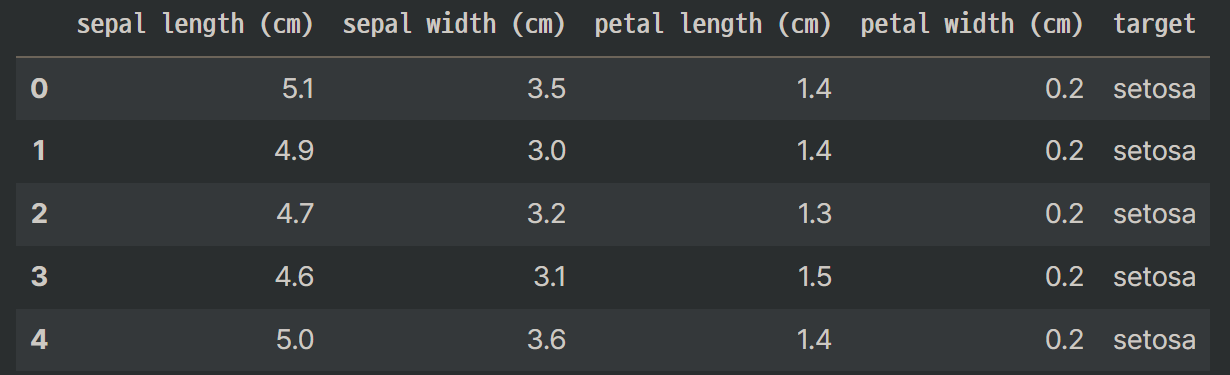
df.target.value_counts()
# 데이터 시각화
setosa_df = df[df.target == "setosa"]
versicolor_df = df[df.target == "versicolor"]
virginica_df = df[df.target == "virginica"]
ax = setosa_df['sepal length (cm)'].plot(kind='hist')
setosa_df['sepal length (cm)'].plot(kind='kde',
ax=ax,
secondary_y=True,
title="setosa sepal length",
figsize=(8,4))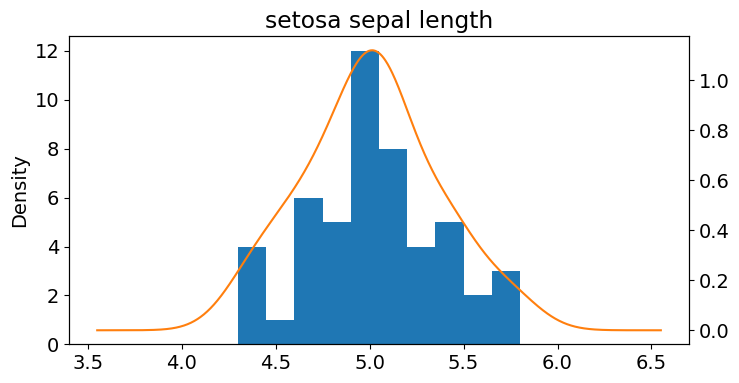
ax = versicolor_df['sepal length (cm)'].plot(kind='hist')
versicolor_df['sepal length (cm)'].plot(kind='kde',
ax=ax,
secondary_y=True,
title="versicolor sepal length",
figsize 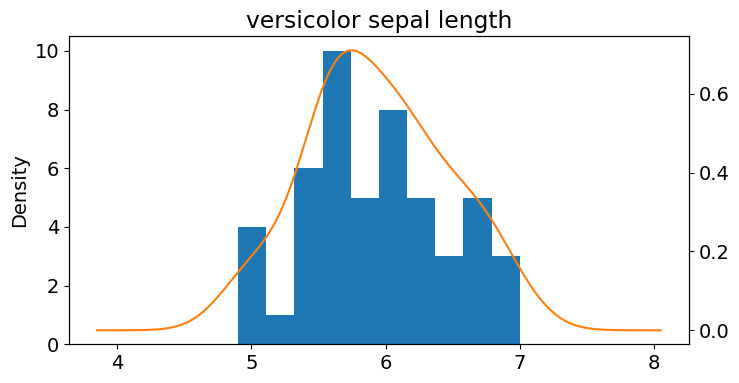
# 가우시안 나이브 베이즈 분류하기
X_train,X_test,y_train,y_test=train_test_split(dataset.data, dataset.target, test_size=0.2)
model = GaussianNB()
model.fit(X_train, y_train)
expected = y_test
predicted = model.predict(X_test)
print(metrics.classification_report(y_test, predicted))
print(accuracy_score(y_test, predicted)) precision recall f1-score support
0 1.00 1.00 1.00 11
1 1.00 0.89 0.94 9
2 0.91 1.00 0.95 10
accuracy 0.97 30
macro avg 0.97 0.96 0.96 30
weighted avg 0.97 0.97 0.97 30
0.9666666666666667# 혼동행렬 확인하기
print(metrics.confusion_matrix(expected, predicted)) [[11 0 0]
[ 0 8 1]
[ 0 0 10]]
씨앗 데이터 분석가.