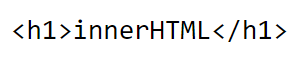속성 값 노드
지난 포스트들에서는 요소를 다루는 법에 대해 알아봤습니다. 노드 취득, 워킹을 통해 속성 값도 또한 다룰 수 있는데요. 오늘은 어떤 방법으로 속성 값을 다룰 수 있는지에 대해 알아보겠습니다.
속성 이름으로 접근하기
첫 번째 방식으로는, 속성 이름으로 접근하는 방식입니다. 가장 기본적으로 직관적인 방법이기도 합니다. 이 방식은 노드를 취득한 후, 객체의 프로퍼티에 접근하듯이 닷 연산자.를 이용해서 속성에 접근하는 방식입니다.
다음 코드는 <a>의 href속성에 접근하는 예제입니다.
<a id="myBlog" href="https://velog.io/@bami">let linkA = document.getElementBtId('myBlog');
let url = linkA.href; //취득하거나
linkA.href = "https://github.com/Bam-j"; //설정하기이 방식은 주의점이 있는데요. class 속성처럼 자바스크립트에서 이미 예약어로 사용되는 문자들이 있습니다. 이럴경우 속성 이름(class)과 접근하는 이름(className)이 다르다는 것을 알아야합니다.
<img class="album">let imgNode = document.getElementByClassName('album');
imgNode.className = 'thumbnail'; //class 속성은 className이라는 프로퍼티로 접근getAttribute, setAttribute
속성 이름 접근 방식에서 class처럼 속성 이름과 접근 방식이 다른 경우를 방지하기 위해 만들어진 메소드입니다. 다음과 같이 사용합니다.
요소.getAttribute(속성명);
요소.setAttribute(속성명, 속성 값);이 방식은 접근 이름과 속성 이름이 같은 경우를 생각하지 않아도 되고, 문자열로 접근할 수 있다는 장점을 갖습니다.
attributes
attributes는 프로퍼티로, 끝이 -s에서 눈치 챌 수도 있겠지만 취득한 요소의 모든 속성을 반환하는 프로퍼티입니다. 다수의 속성을 반환 할 경우 NamedNodeMap 객체의 형식으로 반환됩니다.
추출해 낸 속성들 중 하나의 속성에 접근할 때 속성 이름은 .name, 속성 값은 .value로 접근합니다.
텍스트 노드
태그 사이에 적는 일반 문자열도 문서 트리 구조에서는 텍스트 노드라는 이름의 노드로 취급합니다. 이러한 텍스트 노드 또한 자바스크립트로 접근해서 사용할 수 있습니다.
innerHTML
innerHTML은 텍스트를 교체하는데, 이때 HTML 문자열로 해석합니다. html 문자열로 해석한다는 것은 문자열 내에 태그 등이 들어가있으면 HTML 태그로 인식을 하고 결과에 반영합니다.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bam</title>
<link href="../CSS/css.css" rel="stylesheet" type="text/css">
</head>
<body>
<p id = 'text'>기존 텍스트</p>
<script src="../js/hello_world.js" type="text/javascript"></script>
</body>
</html>
document.addEventListener('DOMContentLoaded', function (){
document.getElementById('text').innerHTML = '<h1>innerHTML</h1>';
});
textContent
textContent는 주어진 문자열을 그대로 텍스트로 출력합니다. 또한, innerText라는 것도 존재하는데, 두 프로퍼티가 하는 일은 같습니다.
document.addEventListener('DOMContentLoaded', function (){
document.getElementById('text').textContent = '<h1>innerHTML</h1>';
});