
DB 데이터의 물리적 저장
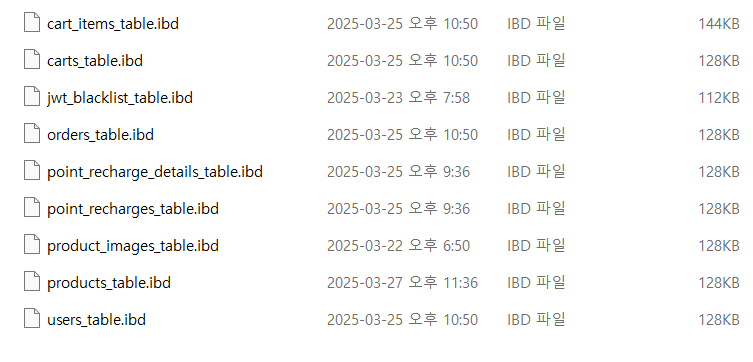
DBMS를 조작하여 데이터베이스 테이블을 생성하고 데이터를 저장하는 경우 이때 실제 물리적 저장장치(HDD, SSD 등)에 저장됩니다. 실제로 C:\ProgramData\MySQL\MySQL Server 8.0\Data (처음 설치 시 저장 경로를 따로 설정하지 않은 경우) 디렉토리에 들어가본다면 다음 이미지 처럼 생성한 db와 테이블에 대한 정보 및 저장된 데이터들이 존재함을 알 수 있습니다.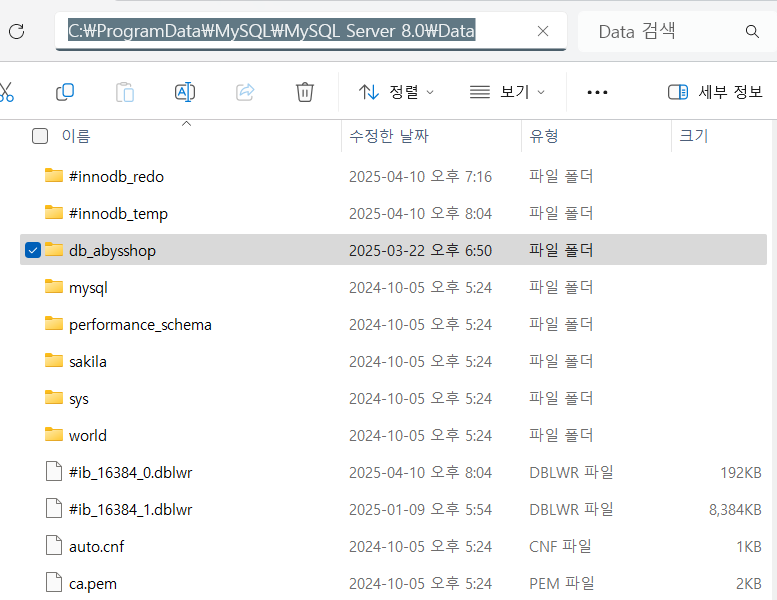
SHOW VARIABLES LIKE 'datadir';명령을 이용해서 데이터가 저장된 위치를 알 수 있습니다.
MySQL 인덱스
인덱스 개념
인덱스 Index는 자료구조의 일종으로 데이터를 효율적으로 찾을 수 있게 만들어주는 자료구조입니다. DB에서 인덱스는 테이블의 행(튜플, 레코드)의 키 값에 대한 물리적인 위치를 저장해둡니다.
그래서 어떤 레코드를 요구하면 인덱스에서 해당 레코드의 키 값 위치를 찾아내어 빠르게 탐색을 수행할 수 있도록 만들어줍니다.
대부분의 RDBMS 그리고 여기서 설명하고자하는 MySQL의 인덱스는 B-Tree를 이용해서 인덱스를 구성합니다.
인덱스의 특징은 다음과 같습니다.
- B-Tree 구조를 채택한 RDBMS가 많다
- 빠르고 효율적인 검색과 레코드 접근
- 한 개 이상의 속성을 사용하여 생성
- 정렬된 속성과 데이터의 위치만 저장하기 때문에 저장 공간을 적게 쓴다
- 데이터 수정/삭제 시 인덱스가 재구성 (B-Tree 삽입 삭제 참조)
이 특징들은
B-Tree포스트에서 해당 자료구조의 특징들을 살펴보신다면 더 쉽게 이해할 수 있습니다.
그리고 이후 내용도B-Tree에 대한 내용을 어느정도 포함한 채로 설명이 되기 때문에B-Tree에 대한 이해도가 필요합니다.
정확히는 MySQL 구 버전에서 사용된 것이
B-Tree,InnoDB 엔진이 사용되는 버전부터는B+Tree가 인덱스에 사용되고 있습니다.
B+Tree는B-Tree가 개선된 자료구조이므로 여기서는 기본이되는B-Tree를 이용해서 설명합니다.
MySQL의 인덱스
MySQL에서 인덱스는 클러스터 인덱스, 보조 인덱스로 나누어집니다. 두 인덱스 모두 B-Tree 기반의 인덱스입니다.
클러스터 인덱스 Clustered Index
클러스터 인덱스는 연속된 키 값(PK)을 가진 레코드들을 묶어서 같은 블록에 저장합니다. 테이블 당 하나의 클러스터 인덱스만 생성가능합니다.
클러스터 인덱스는 다음과 같은 특징을 갖습니다.
- 리프 노드에 실제 테이블의 레코드가 저장됩
- 레코드가 키 순서대로 저장
- 범위 검색에 유리(키 순차 저장으로 인해 물리적으로 읽기 쉬움)
- 인덱스가 단순해져서 저장 공간을 적게 차지
보조 인덱스 Secondary Index
보조 인덱스는 PK 이외의 컬럼들에 대해 생성되는 인덱스입니다.
보조 인덱스는 다음과 같은 특징을 갖습니다.
- 리프 노드에 클러스터 인덱스의 키를 저장해놓고 실제 레코드 데이터는 클러스터 인덱스를 통해 탐색
- 인덱스 조작 시 키를 정렬하지 않음
- 이에 따라 보조 인덱스 탐색 > 클러스터 인덱스 탐색 2 단계의 탐색을 수행
- 테이블 당 여러 인덱스를 생성하기에 이들을 조합하여 유연하게 쿼리에 대응
인덱스 생성
인덱스는 다음 명령으로 생성할 수 있습니다.
CREATE INDEX 인덱스_이름
ON 테이블_이름(컬럼, ...);데이터를 빠르게 찾을 수 있기만 한 것 처럼 이야기했지만 무조건적으로 인덱스가 빠르진 않습니다. 데이터 자체가 많이 없거나, 데이터 값의 경우가 적은 경우(flag 처럼 true/false 두 가지라던가)에는 오히려 인덱스 없이 사용하는게 더 빠를 수도 있습니다.
그래서 인덱스를 생성할 때는 다음과 같은 사항들을 고려해보고 생성해야합니다.
- WHERE에 자주 사용될 것
- JOIN에 자주 사용될 것
- 테이블 당 4~5 개 정도만 생성
- 속성이 가공되지 않아야한다
- 속성의 값들이 아주 다양한 경우
인덱스 생성 이후 테이블 내의 데이터가 변경되었다면 다음 명령어를 통해 인덱스를 재구성합니다.
ANALYZE TABLE 테이블_이름;추가적으로 인덱스 삭제는 DROP을 이용합니다.
DROP INDEX 인덱스_이름;