
너비 우선 탐색 Breadth First Search
지난번에 본 깊이 우선 탐색(DFS)는 한 정점에서 시작해서 갈 수 있는 정점까지 방문한 후에 방문하지 않은 인접 정점이 있는 정점으로 돌아와서 진행하는 방식이었습니다. 이번에 배울 너비 우선 탐색(BFS, Breadth First Search)은 정점에 인접한 정점들을 모두 한 번씩 방문하고 나서 방문했던 정점들의 인접한 정점들을 다시 한 번씩 방문하는 방식입니다. 또한 정점들마다 너비 우선 탐색을 수행하기 위해서 큐를 이용합니다. 이점도 DFS와 차이점을 보이고있습니다.
DFS와 마찬가지로 배열과 큐를 이용하는데 배열에는 방문 정보를 담고 큐에는 방문 기록을 남기기 위해 사용합니다.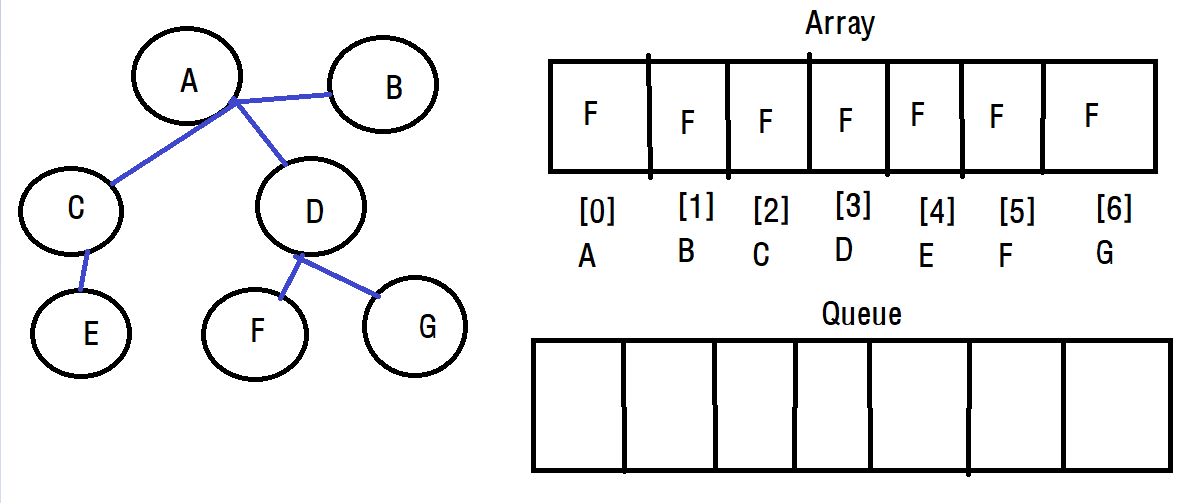
A에서 시작하도록 하겠습니다. A에서 시작했으니 방문 정보를 T로 바꿔주고 다음 정점들을 탐색합니다.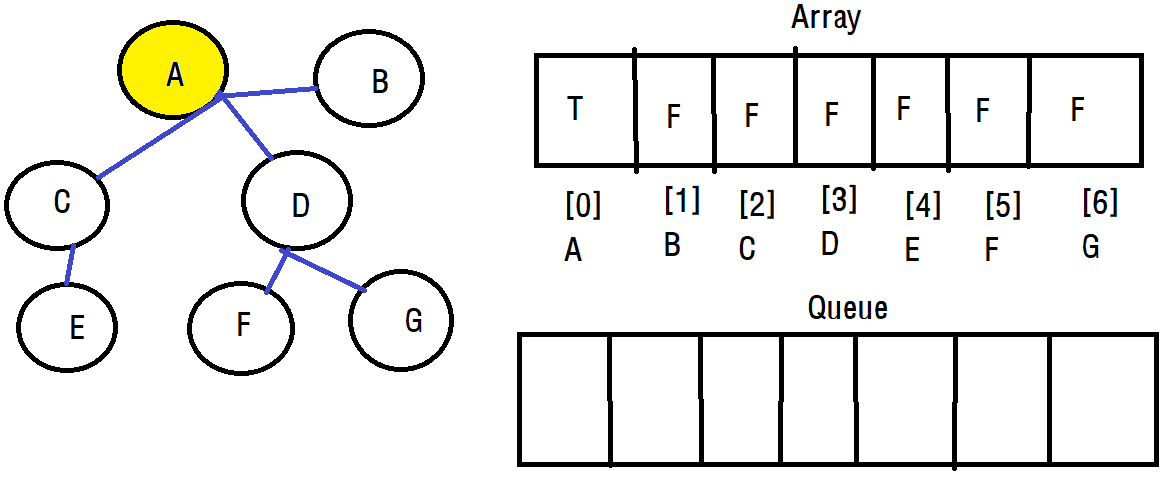
A의 인접 정점인 B, C, D를 차례대로 방문합니다. 방문하면서 배열의 방문정보를 T로 변경해주고, 큐에 enQueue합니다. 여기서 주의점은 DFS의 스택은 방문했다 떠난 정점을 스택에 push했지만 BFS의 큐는 방문한 정점만들 enQueue한다는 차이점이 있다는 것 입니다.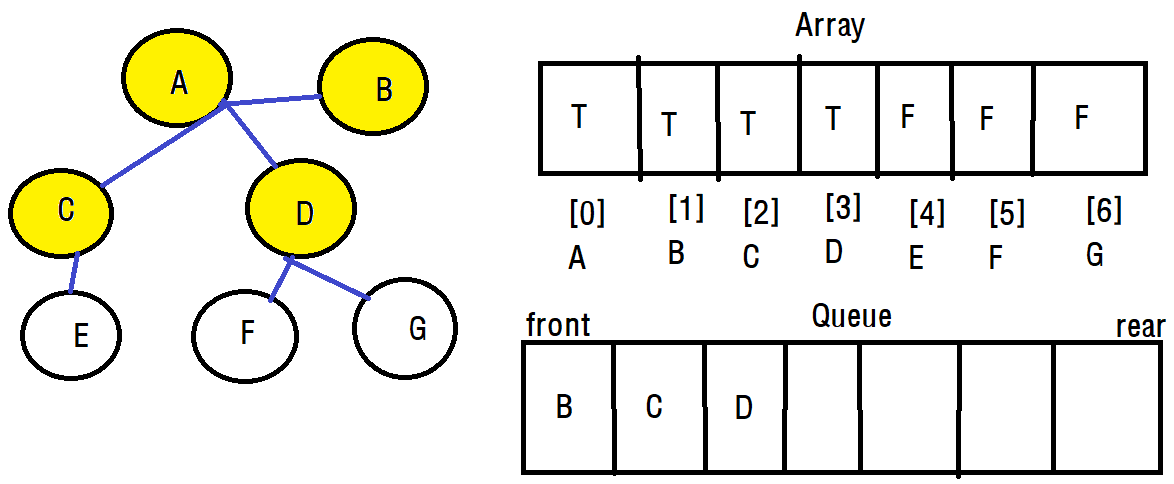
첫번째 탐색이 종료되었습니다. 그러나 아직 남아있는 정점들이 있죠. 이제 방문했던 정점들에 대해서 다시 한 번 너비 우선 탐색을 해볼 차례입니다. 정점들이 다른 정점과 연결되어 있다면 말이죠.
우선 선입선출의 구조인 큐이기 때문에 front의 B 정점부터 deQueue해서 확인합니다. 그러나 정점 B는 다른 정점과 연결되어 있지 않습니다. 그러면 한 번 더 deQueue하여 C정점을 확인해보니, 연결된 다른 정점이 존재합니다. 이러면 C에 대해서 다시 한 번 너비 우선 탐색을 진행합니다.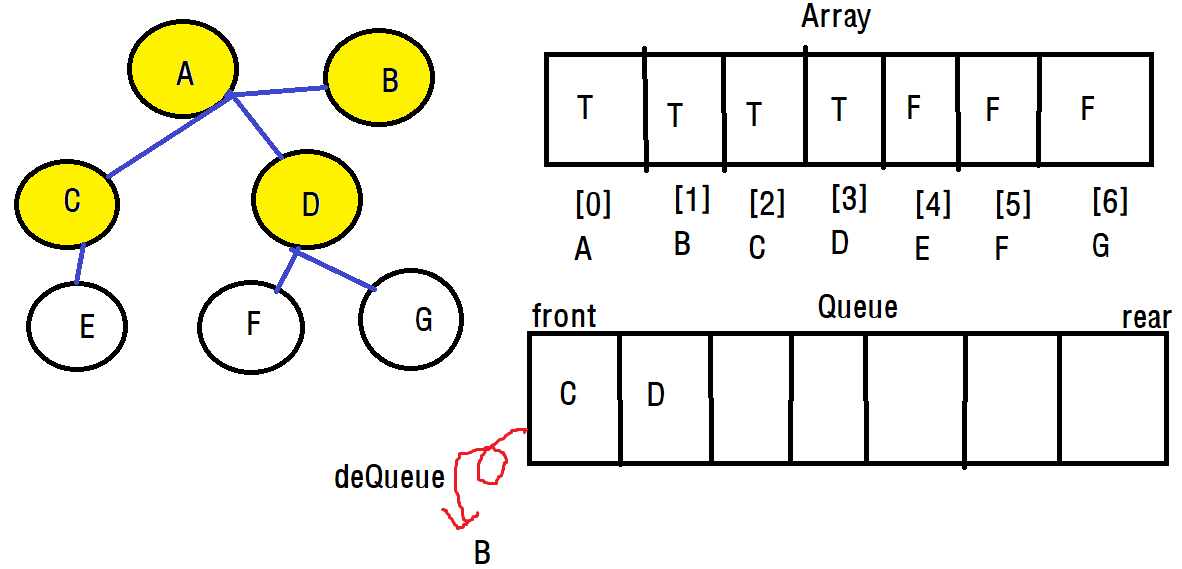
C에 대해서 너비 우선 탐색을 진행한 결과 E정점에 방문해서 방문 기록 배열을 T로 만들고 큐에 enQueue하게 됩니다.
이렇게 C에 대해서도 너비 우선 탐색이 종료되었으면 다시 큐를 deQueue합니다.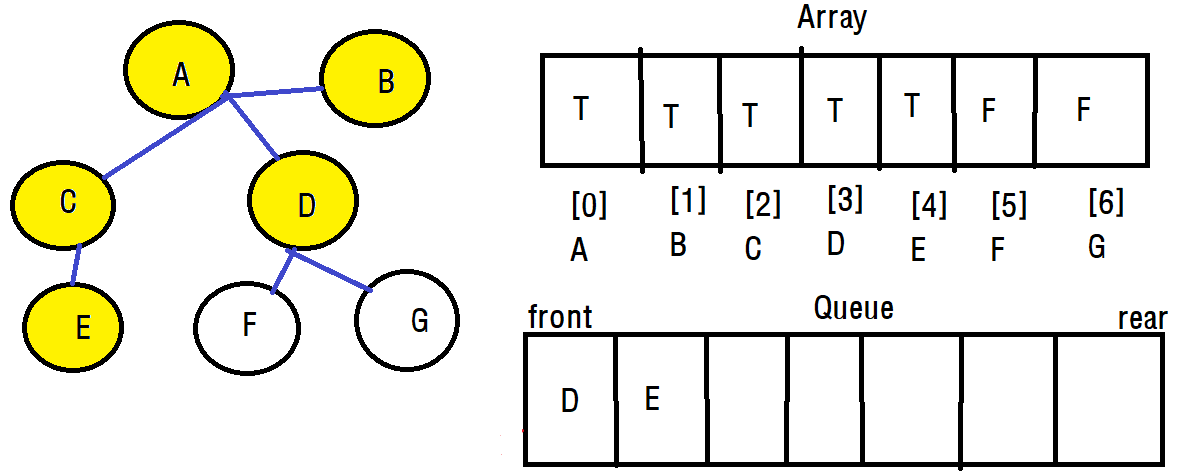
deQueue한 결과인 D 정점에 대해서 너비 우선 탐색을 진행합니다. 이 결과로 우리는 그래프에 대해 모든 정점을 방문하게 되었고 이것이 너비 우선 탐색법입니다. 하지만 모든 과정이 끝난것은 아닙니다.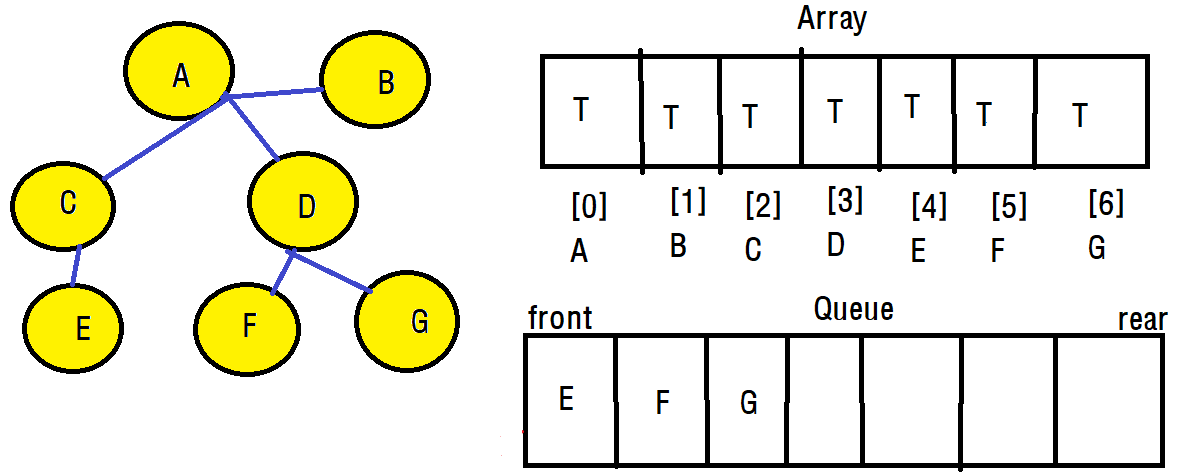
우리는 그래프의 모든 정점을 방문했다고 알 수 있지만, 사실은 확실하지도 않고 컴퓨터도 알 수 없습니다. 그렇기에 모든 정점을 탐색했더라도 큐에 남아있는 정보를 모두 deQueue하면서 남은 정점에 연결된 정점이 있는지 확인해야합니다.
이렇게 모든 정점에 대해서 확인이 종료된다면 너비 우선 탐색이 종료되게 됩니다.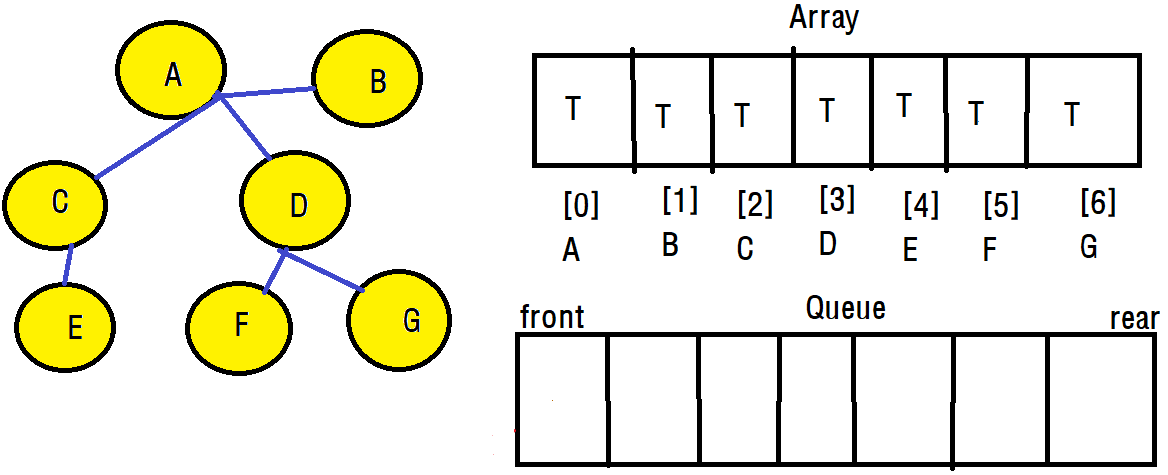
너비 우선 탐색 구현
연결 리스트 기반 그래프로 BFS를 구현합니다.
void BreadthFirstSearch(graphType* g, int v) {
graphNode* currentNode; //현재 위치한 정점
QueueNode* Q;
Q = createLinkedQueue(); //큐 생성
g->visitedNode[v] = TRUE; //시작 정점의 방문은 TRUE로 설정
enQueue(Q, v); //큐에 시작 정점(=현재 정점)을 enQueue
//큐가 공백이 아닌동안에 너비 우선 탐색 계속 수행
while (!isEmpty(Q)) {
//큐에서 deQueue된 정점을 v로 지정
v = deQueue(Q);
//현재 정점에 인접 정점이 있다면 수행
for (currentNode = g->adjacentListHeadPtr[v]; currentNode; currentNode = currentNode->link) {
//인접 정점이 방문하지 않은 정점일 경우 if문 실행
if (!g->visitedNode[currentNode->vertex]) {
//방문하고 정보를 true로 변경
g->visitedNode[currentNode->vertex] = TRUE;
//큐에 enQueue
enQueue(Q, currentNode->vertex);
}
}
}
}인접 리스트 그래프가 포함된 전체 코드는 GitHub에서 확인하실 수 있습니다.
