[Python] Python으로 웹 스크래퍼 만들기 (2.8 Extracting Locations and Finishing up)
Python으로 웹 스크래퍼 만들기

노마드 코더 Python으로 웹 스크래퍼 만들기
https://nomadcoders.co/python-for-beginners
2.8 Extracting Locations and Finishing up
✍️ 회사 정보 추출하는 부분 따로 빼서 새로운 함수 만들기
회사 정보(직무, 회사명, 위치, 링크)를 추출하는 부분이 길어질 거라
extract_indeed_jobs 함수에서
직무와 회사 이름을 추출하는 부분을 따로 빼서 함수를 새로 만들어 준다.
함수이름은 extract_job, 인자로 html을 받는다.
extract_indeed_jobs 함수에서 이 부분 빼서 함수 새로 만들어주기

import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html): # 직무와 회사명 추출하는 부분을 따로 빼서 함수 만듦
title = result.find("h2", {"class": "title"}).find("a")["title"]
company = result.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
print(title, company)
def extract_indeed_jobs(last_page): # 여기서 빼옴
jobs = []
#for page in range(last_page):
result = requests.get(f"{URL}&start={0*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
return jobsextract_job 함수에서
job을 dictionary 형태로 반환하는 걸로 수정
return {'title': title, 'company': company}

extract_indeed_jobs 함수에서 extract_job 함수 호출하기

result가 html을 담고 있으므로 result를 html로 수정
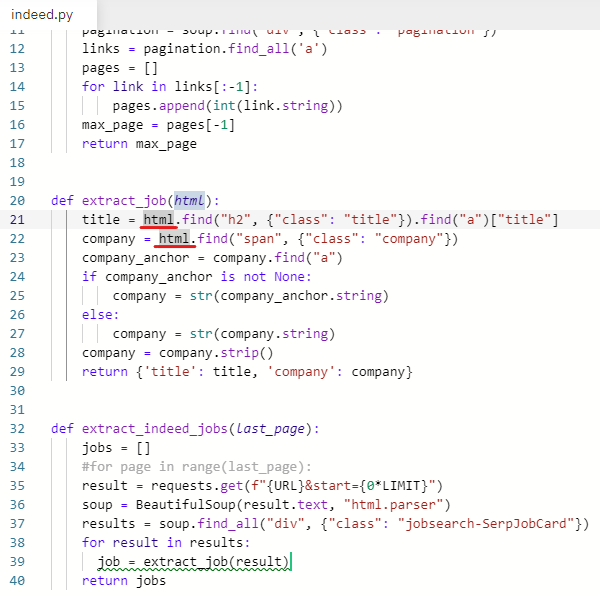
잘 동작하는지 확인하기 위해 출력해본다.
print(job)

for문으로 extract_job을 반복해서 호출하여
title과 company를 dictionary 형태로 반환한 결괏값을 print해주었다.

오류 없이 실행되는 것을 확인했다.
✍️ job을 빈 리스트(jobs)에 넣어주기
아까 print해 본 job을 jobs 라는 빈 리스트에 넣어주어야 한다.
job을 jobs에 넣어주어야 한다.
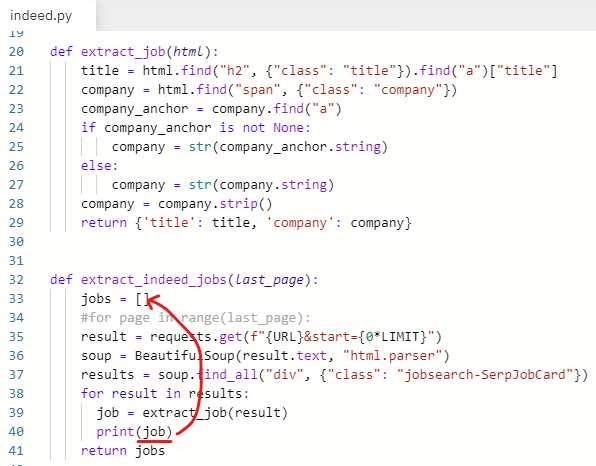
빈 리스트(jobs)에 값을 추가하기 위해 jobs.append(job) 입력
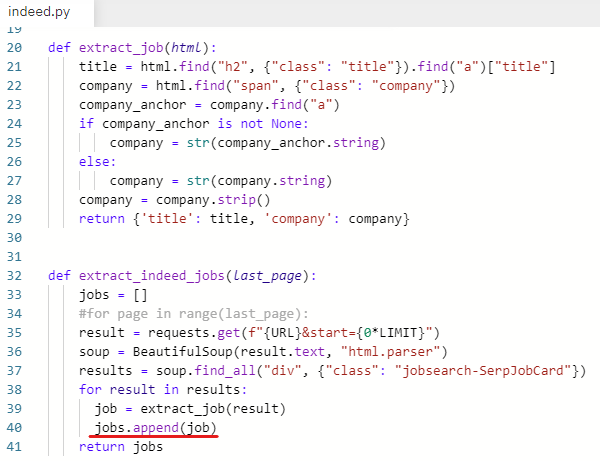
main.py로 가서 print(indeed_jobs) 입력
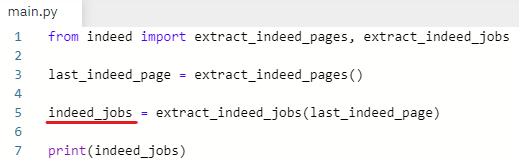
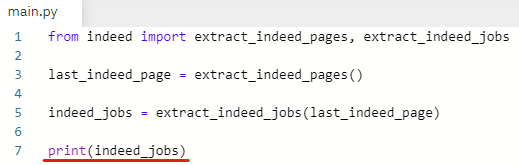
indeed_jobs = extract_indeed_jobs(last_indeed_page)
indeed_jobs 라는 변수는 extract_indeed_jobs 함수의 결괏값이다.
print(indeed_jobs)
indeed_jobs(extract_indeed_jobs 함수의 결괏값) 출력
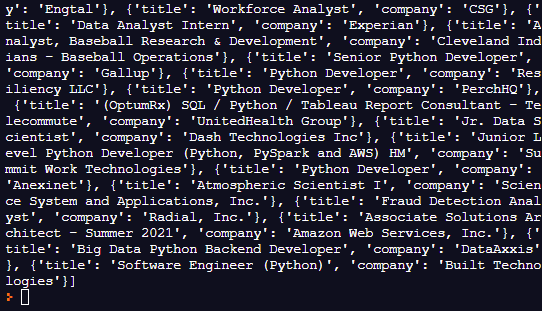
빈 리스트 안에 딕셔너리 형태의 값이 추가되어 반환된 것이 출력되었다.
✍️ 회사 위치(location) 추출하기
회사 위치를 추출하기 위해 무엇을 가져오면 되는지 봐야 한다.
indeed 사이트에서 inspect 실행
class명이 location인 span을 가져오면 된다.
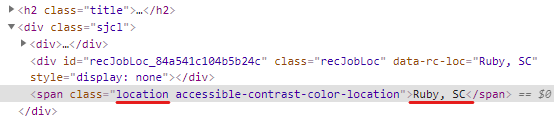
location 변수 생성
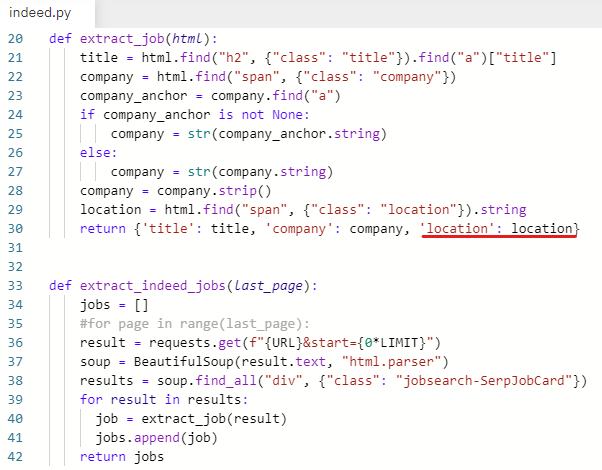
location = html.find("span", {"class": "location"}).string
class명이 location인 span 안에 들어있는 string 가져오기

반환하는 딕셔너리 안에 location 값 추가하기
return {'title': title, 'company': company, 'location': location}
실행했더니 none의 string은 가져올 수 없다고 오류 남
location 중에 none이 있는지 확인하기 위해 출력해본다.
.string 지우고 print(location) 입력
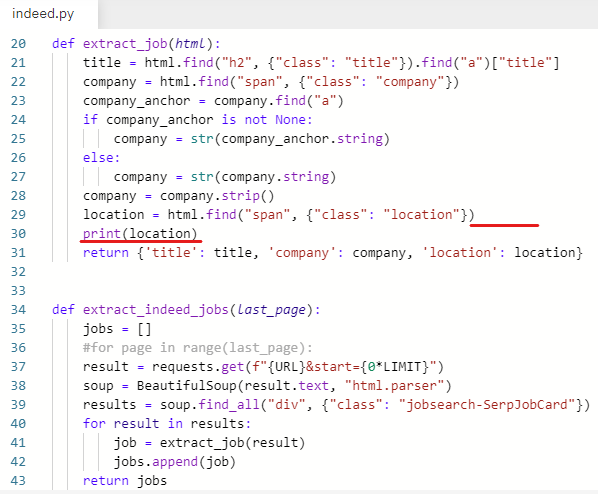

딕셔너리에 들어있는 값 중 'location': None이 있다.
location만 print하기 위해 main.py로 가서 print(indeed_jobs) 지워준다.

location만 출력되게 다시 실행한다.

None이 있다.
location 값이 없는 회사는 none으로 나온다.
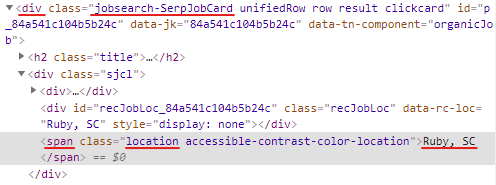
span을 가져오지 않고 다른 걸 가져오기로 한다.


display 값이 none으로 되어 있는 div에 location 정보가 있다.
div에 있는 data-rc-loc라는 attribute를 가져오기로 한다.
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
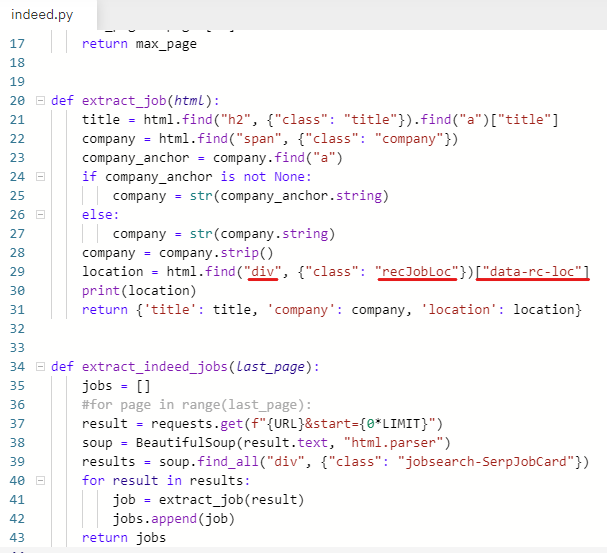
잘 동작하는지 확인하기 위해 실행해본다.
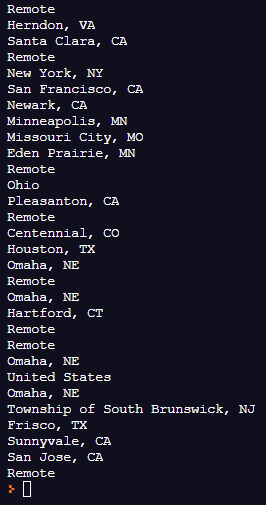
none 없이 location이 잘 출력되었다.
✍️ 입사 지원 링크 추출하기
command나 ctrl키를 누른 채로 구직 정보 제목을 클릭하면
입사 지원 링크가 새로운 창으로 연결 된다.
새로 열린 창의 주소를 보면 id가 추가되어 있다.

뒤에 부분을 지워본다.
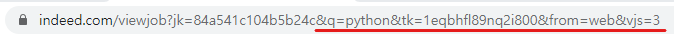
지워도 같은 페이지가 나온다.

inspect 하여 id를 어디서 가져오는지 확인한다.
class명이 jobsearch-SerpJobCard인 div의 data-jk라는 attribute에 있다.
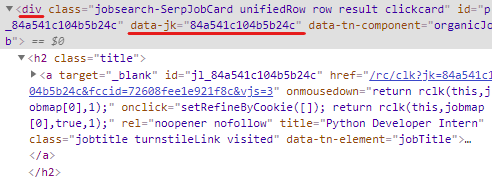
이 div는 result다.
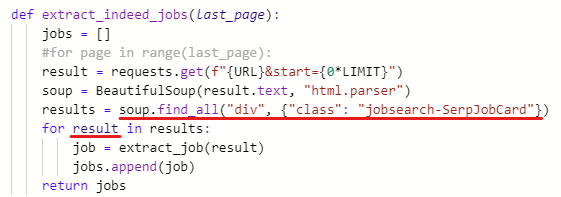
입사 지원 링크 추출하는 부분도 extract_job 함수에 입력한다.
job_id라는 변수를 만들어주고
job_id = html["data-jk"]
잘 동작하는지 확인을 위해 출력해본다.
print(job_id)
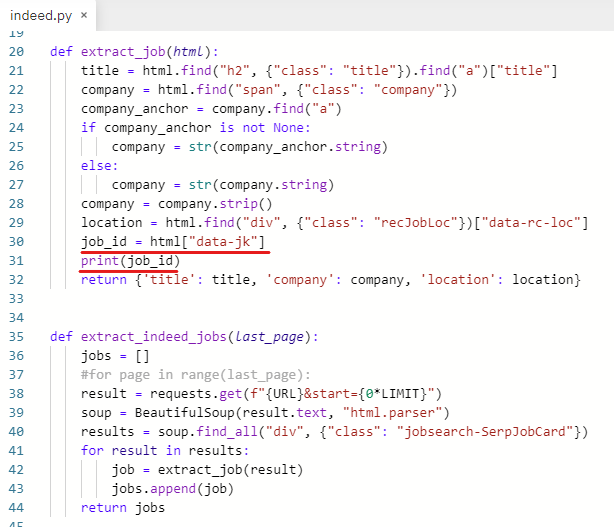

id를 다 가져왔다.
job_id를 이용해서 입사 지원 링크를 완성해준다.

'link': f"https://www.indeed.com/viewjob?jk={job_id}"

실행해보면 오류 안 남
✍️ 직무, 회사명, 위치, 지원링크 출력해보기
이제 main.py로 가서 indeed_jobs를 출력해본다.

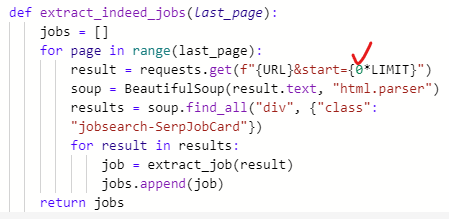
20페이지 모두 실행되는 걸 방지하기 위해 주석 처리 해놓았던 for문을 풀어준다.
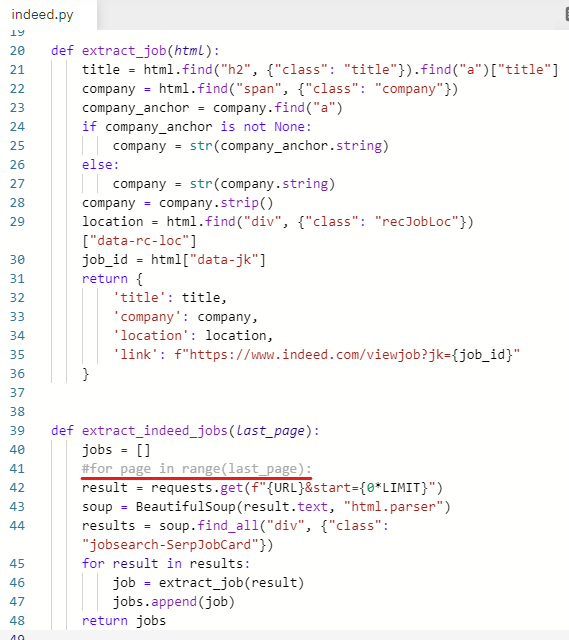
내어쓰기 했던 부분도 들여쓰기로 다시 바꿔준다.

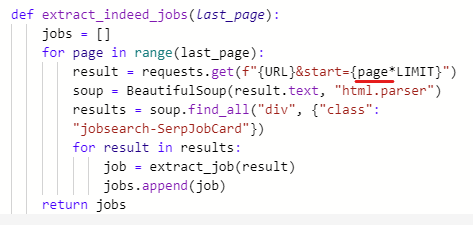
0을 지우고 page로 수정해준다.
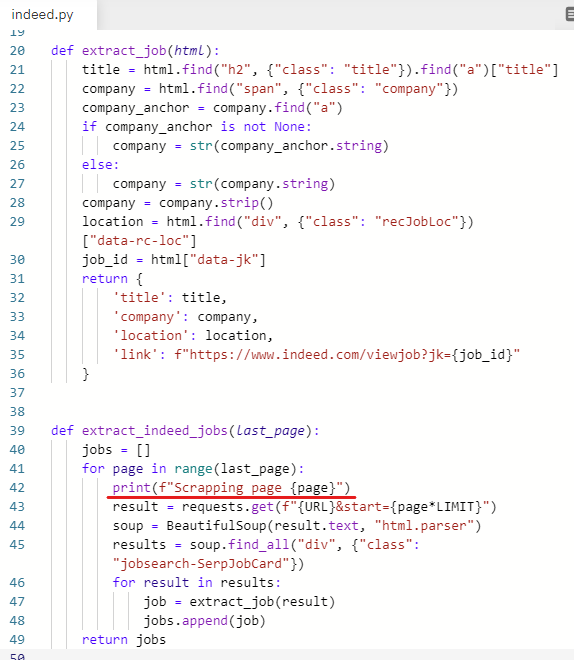
왜 해주는 건지 모르겠지만
print(f"Scrapping page {page}")
import requests
from bs4 import BeautifulSoup
LIMIT = 50
URL = f"https://www.indeed.com/jobs?q=python&limit={LIMIT}"
def extract_indeed_pages():
result = requests.get(URL)
soup = BeautifulSoup(result.text, "html.parser")
pagination = soup.find("div", {"class": "pagination"})
links = pagination.find_all('a')
pages = []
for link in links[:-1]:
pages.append(int(link.string))
max_page = pages[-1]
return max_page
def extract_job(html):
title = html.find("h2", {"class": "title"}).find("a")["title"]
company = html.find("span", {"class": "company"})
company_anchor = company.find("a")
if company_anchor is not None:
company = str(company_anchor.string)
else:
company = str(company.string)
company = company.strip()
location = html.find("div", {"class": "recJobLoc"})["data-rc-loc"]
job_id = html["data-jk"]
return {
'title': title,
'company': company,
'location': location,
'link': f"https://www.indeed.com/viewjob?jk={job_id}"
}
def extract_indeed_jobs(last_page):
jobs = []
for page in range(last_page):
print(f"Scrapping page {page}")
result = requests.get(f"{URL}&start={page*LIMIT}")
soup = BeautifulSoup(result.text, "html.parser")
results = soup.find_all("div", {"class": "jobsearch-SerpJobCard"})
for result in results:
job = extract_job(result)
jobs.append(job)
return jobs실행해 본다.

실행되는 중...
잘 동작됐다.
직무, 회사명, 위치, 지원링크 다 가져옴
지원 링크 잘 되는지 확인하기 위해 복사해서 주소창에 붙여넣기 해 본다
(콘솔창에 나와있는 링크 클릭해서 바로 들어가면 오류 뜨는데
주소 복사해서 주소창에 복붙해서 들어가면 잘 들어가짐)
