
컴공 복전생의 하루 한 개 글 작성하기
혼자 공부하는 머신러닝 - 2주차
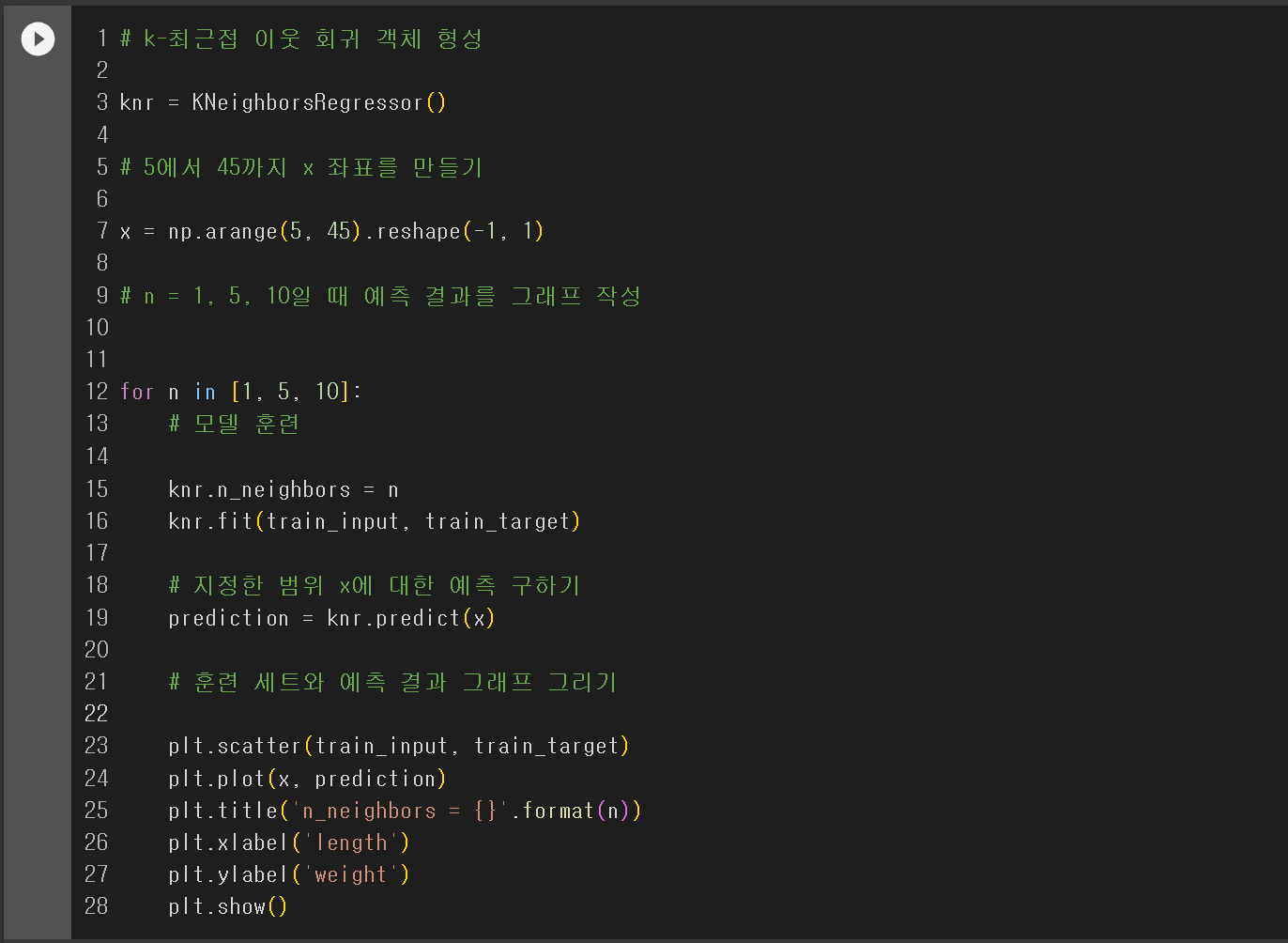
핵심 포인트(1) 회귀 : 임의의 수치를 예측하는 문제, 타깃값도 임의의 수치가 된다.(2) k-최근접 이웃 회귀 : k-최근접 이웃 알고리즘을 사용하여 가장 가까운 이웃 샘플을 찾고 이 샘플들의 타깃값을 평균하여 예측으로 삼는다.(3) 결정계수 : 1에 가까울 수록
2023년 7월 16일
·
2개의 댓글·
0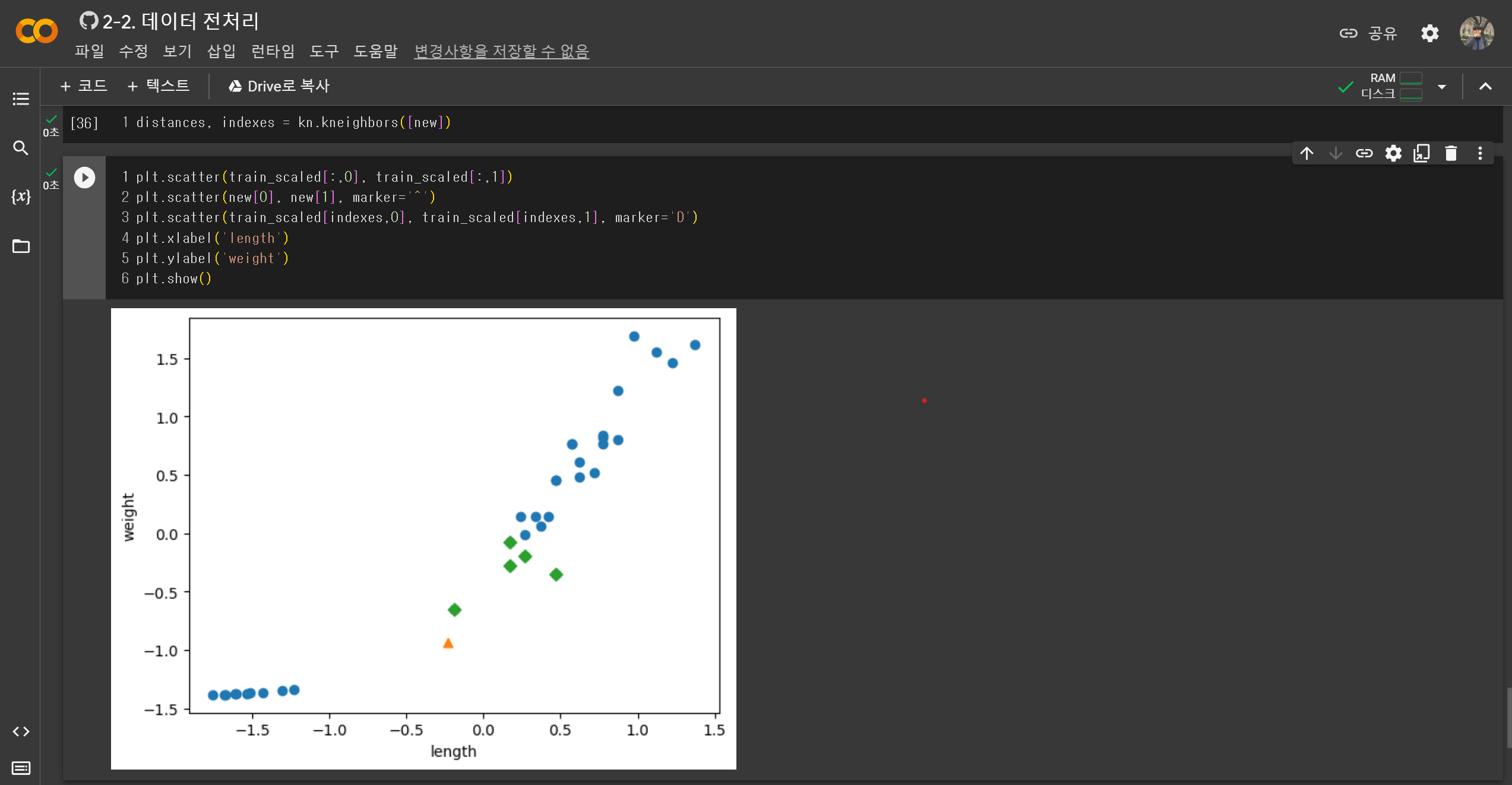
혼자 공부하는 머신러닝 - 1주차 과제
실제 구글 코랩에서 돌렸을 때의 실습 화면데이터 전처리 : 머신러닝 모델에서 훈련 데이터를 주입하기 전에, 가공하는 단계를 뜻함.표준점수 : 훈련 세트의 스케일을 바꾸는 대표적인 방법중 하나임브로드캐스팅 : 크기가 다른 넘파이 배열에서 자동으로 사칙 연산을 모든 행이나
2023년 7월 9일
·
0개의 댓글·
0