의료 분야와 같이 제한된 데이터셋을 이용하여 모델을 학습시키고자 하는 경우, '적은 데이터셋으로 모델을 학습시킬 수 있는가'에 대한 고민을 하게 된다. 이와 관련하여 여러 레퍼런스를 찾아보던 도중, Few-shot Learning 을 알게되었다.
Few-shot Learning 이 어쩌면 그 해결책의 일부분이 될 수 있겠다 싶어서 찾아봤다.
Few-shot Learning
-
특징
- few 한 데이터도 잘 분류할 수 있다는 것
- few 한 데이터로 학습을 한다는 의미는 아님
-
기존의 딥러닝과 사람의 인지과정의 차이
- 사람에게 아래의 Support Set 을 보여주고, Query 가 어느쪽에 해당하는지 물어보면, 아마도 Pangolin 이라고 잘 대답할 것임

- 하지만 기존의 딥러닝이라면? 아마도 두 클래스에 대한 수많은 사진을 준비하고 모델을 학습시켜야 했을지도!
- 그렇다면 사람은 어떻게 Query 가 바로 Pangolin 클래스에 속한다는 것을 알 수 있을까?
- 바로 우리는 "구분하는 방법"을 배웠기 때문! 가령 고양이와 강아지가 다르다는 것을 배우는 것과 같이 다른 수많은 데이터에서 겪은 경험과 시행착오를 기반으로 가능한 것임
- 이렇게 "구분하는 방법을 배우는 것"을 Meta Learning 이라 하며, "Learn to Learn" 이라고도 표현함
- 사람에게 아래의 Support Set 을 보여주고, Query 가 어느쪽에 해당하는지 물어보면, 아마도 Pangolin 이라고 잘 대답할 것임
-
Few-shot Learning
- Few-shot Learning 은 바로 위와 같은 사례에서 착안한 Meta Learning 임
- 따라서, "구분하는 방법"을 배우고자 하는 방법론이고, 즉 이를 위해 수많은 데이터가 필요한 것은 마찬가지
- 하지만 기존의 딥러닝과 다른 점은 "구분하고자 하는 대상"이 반드시 학습 데이터셋에 없어도 된다는 점!
- Few-shot Learning Process
- 즉, Few-shot Learning 을 위해서는 1) Training Set 2) Support Set 3) Query image 가 필요함
- Training Set 을 이용하여 "구분하는 방법"을 배움
- Query image 가 들어왔을 때, Query image 가 Support Set 중 어떤 것과 같은 종류인지를 맞춤
- 결과적으로 "어떤 클래스에 속하는가"를 맞추는 것이 아닌 "특정 클래스와 같은 클래스인가"를 푸는 문제라고 생각하면 됨
- k-way 와 n-shot 이라는 표현을 씀
- k-way 는 Support Set 이 k 개의 클래스로 이루어졌다는 것을 의미, 즉 k 값이 클수록 모델의 정확도는 낮아짐
- n-shot 은 각 클래스가 가진 sample 수로, 비교해볼 사진이 많을수록 어떤 클래스에 속하는지 구분이 쉽기 때문에 n 이 클수록 모델의 정확도는 높아짐
- n=1 일 경우 one-hot learning 이라 함
Few-shot Learning 학습 방법
- Few-shot Learning 의 기본 학습 방법은 유사성을 학습하는 것
- 즉, Query image 가 주어졌을 때, Support Set 의 사진들과 잘 비교하여 (각 이미지들의 특징을 잘 추출하고 파악하여) 어떤 클래스에 속하는지를 알아내는 것이 중요
- 즉, Training Set 에서 각 사진별로 중요한 특징들을 잘 추출해서 "같은지 다른지를 구분하는 방법"을 잘 학습해야 함

Few-shot Learning 데이터셋
- 아래와 같이 Positive Set, Negative Set 으로 구성하여 학습 진행

Few-shot Learning Network
- 이때, Feature extraction 을 잘 수행할 수 있도록 모델의 아키텍처를 구성해야 하는데, 일반적인 Conv-ReLU-Pooling layer 도 충분히 적합함
- 기초 Few-shot Learning 에서는 Siamese Network (샴 네트워크) 를 사용하는데, 이는 같은 CNN 모델을 이용하여 hidden representation 을 각각 구한 뒤, 이 차이를 이용하는 방식을 의미함
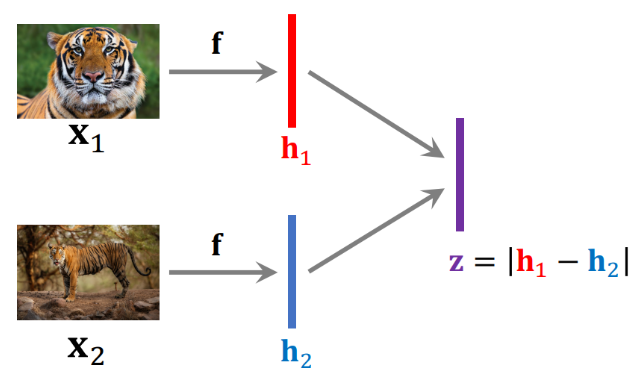
- 이후, Positive pair 에 대해 한 번, Negative pair 에 대해 한 번, 이렇게 번갈아가며 학습을 진행함
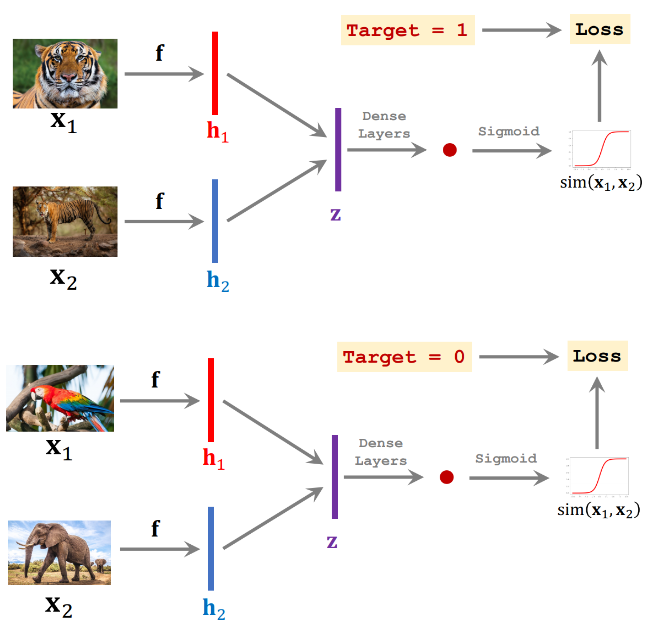
- Prediction 에서는 위 방식과 같이 Support set 의 이미지의 representation 과 Query 이미지의 representation 간의 차이를 Siamese Network 를 이용하여 계산하고 그 유사성을 구함
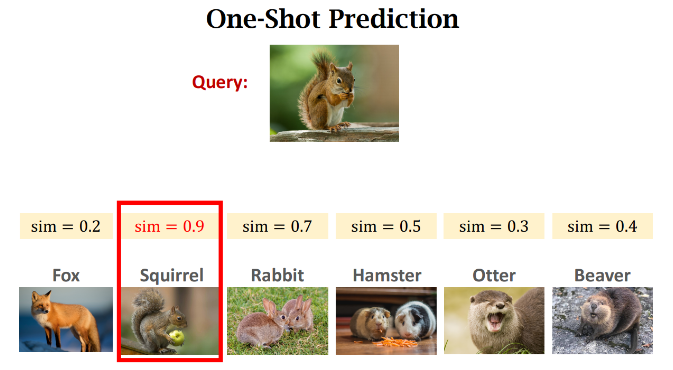
한마디로 정리하면, Few-shot Learning 은 "구분하는 방법"을 배운다는 것!
References

행복한 소히의 이것저것