모델의 성능 평가 지표와 관련된 내용은 네이버 블로그에서 정리한 바 있다. 오늘은 분류 알고리즘 중 결정트리를 중심으로 정리한다.
해당 시리즈는 '파이썬 머신러닝 완벽 가이드' 교재를 공부하며 작성함을 밝힌다.
ch4.1 분류 (Classification)
지도학습의 대표적인 유형으로는 'Classification'이 있다. 이는 기존의 데이터가 어떠한 레이블에 속하는지 패턴을 알고리즘으로 인지한 뒤에 새로운 데이터에 대한 레이블을 판별하는 것을 말한다.
분류는 다양한 알고리즘으로 구현이 가능하며, 그중 'Ensemble Learning'은 높은 성능으로 인해 정형 데이터 의 예측, 분석 영역에서 가장 많이 사용되는 알고리즘이라 할수 있겠다. 앙상블 방법은 ch4.3에서 자세하게 다룰 예정이며, 이번 글에서는 'Decision Tree'에 대해 정리한다.
ch4.2 결정트리 (Decision Tree)
- 결정트리 (Decision Tree)
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 모델 (if/else 기반) 을 의미한다.
결정트리에는 루트 노드, 브랜치 노드, 리프 노드, 서브 트리로 이루어져 있으며, 각각은 시작 노드, 더 이상의 자식 노드가 없는 노드, 자식 노드가 있는 노드 (자식 노드를 만들기 위한 분할 규칙 조건을 가지고 있는 노드), 하위 트리를 의미한다.
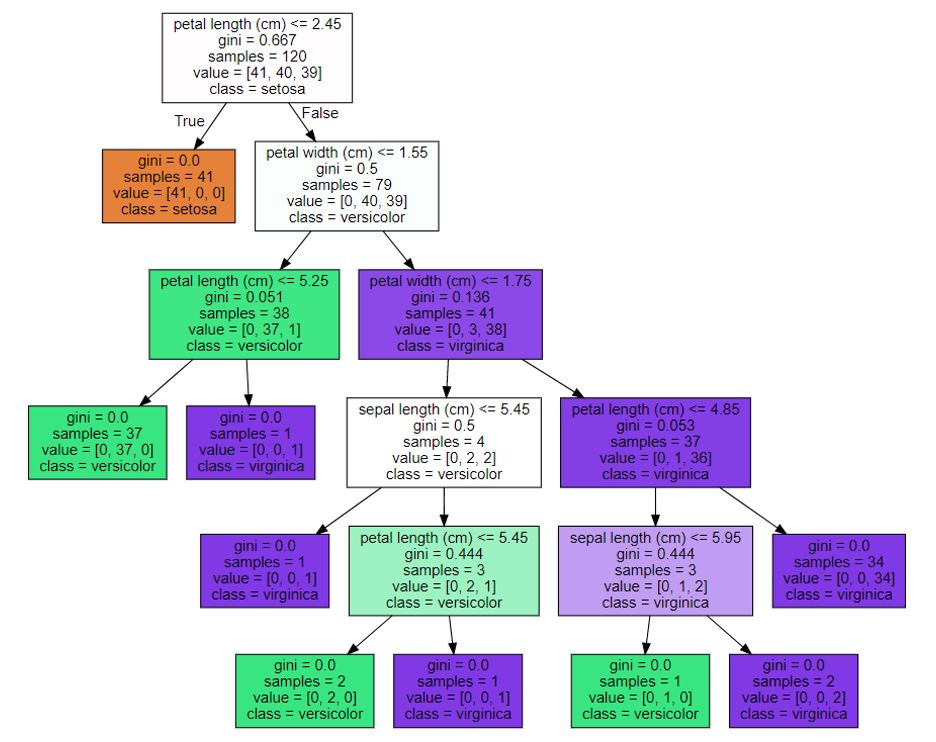
- 트리 분할의 중요성
트리의 깊이가 깊어질수록 과적합이 발생하기 쉽다. 때문에 최대한 많은 데이터셋이 해당 분류에 속할 수 있도록 결정노드의 규칙이 정해져야 한다. 즉, 최대한 균일한 (같은 클래스에 속하는 데이터셋이 많도록) 데이터셋을 구성할 수 있도록 분할하는 결정노드의 규칙이 필요하다.
-
데이터셋 균일도 측정 방법
- 정보 이득 지수 (Information Gain)
정보 이득은 엔트로피라는 개념을 기반으로 한다. 엔트로피는 주어진 데이터 집합의 혼잡도를 의미하고, 정보 이득 지수는 (1 - 엔트로피 지수)를 의미한다. - 지니 계수
지니 계수는 불평등 지수를 나타낼 때 사용하는 계수이다. 0에 가까울수록 데이터 균일도가 높은 것을 의미하며, 1에 가까울수록 데이터 균일도가 낮은 것을 의미한다.
- 정보 이득 지수 (Information Gain)
사이킷런의 DecisionTreeClassifier (결정트리 알고리즘) 은 기본적으로 지니 계수를 이용하여 데이터셋을 분할한다. 즉, 지니 계수가 낮은 분할 기준을 찾아서 자식 트리노드에 걸쳐 반복적으로 분할하고, 데이터가 모든 특정 분류에 속하게 되면 분할을 멈추고 분류를 결정한다.
-
장점
- 쉽고 직관적이다.
- '균일도'만 신경쓰면 된다. 즉, 피처 스케일링이나 정규화 등의 사전 전처리 작업이 굳이 필요하지 않다.
-
단점
- 피처가 많고 균일도가 다양하게 존재할수록 트리의 깊이가 깊어져 과적합 발생 우려가 있다.
- 이를 극복하기 위해 트리의 크기를 사전에 제한하는 튜닝이 필요하다.
ch4.2 결정트리 파라미터
사이킷런의 결정트리 알고리즘에는 분류를 위한 'DecisionTreeClassifier'과 회귀를 위한 'DecisionTreeRegressor'이 존재한다. 두 알고리즘 모두 아래의 동일한 파라미터를 사용한다.
-
min_samples_split
- 노드를 분할하기 위한 최소한의 샘플 수, 과적합 제어
- 디폴트 값은 2이며, 작을수록 과적합 가능성 증가
-
min_samples_leaf
- 말단노드 (leaf) 가 되기 위한 최소한의 샘플 수
- imbalanced 데이터의 경우 특정 클래스의 데이터가 매우 작을 수 있으므로 해당 값은 작게 설정 필요
-
max_features
- 최적의 분할을 위해 고려할 최대 피처 개수
- sqrt는 전체 피처 중 sqrt(전체 피처 개수)
- auto는 sqrt와 동일
- log는 전체 피처 중 log2(전체 피처 개수)
- None은 전체 피처 선정
-
max_depth
- 트리의 최대 깊이를 규정, 과적합 방지
- 디폴트는 None, 과적합 방지를 위해 적절한 값으로 제어 필요
- None은 완벽하게 클래스가 결정 값이 될 때까지 깊이를 계속 키우며 분할하거나 min_samples_split보다 작아질 때까지 깊이 계속 증가
-
max_leaf_nodes
- 말단 노드 (leaf) 의 최대 개수
ch4.2 결정트리 모델의 시각화
Graphviz 패키지를 이용하여 학습된 결정트리 모델을 시각화할 수 있다. 사이킷런은 export_graphviz() API를 제공한다.
-
export_graphviz() 함수 인자
- Estimator
- 피처 이름 리스트
- 클래스 이름 리스트
