ch4.2 결정트리 시각화 예시
결정트리 모델의 시각화는 export_graphviz() API를 사용하여 할 수 있다고 정리한 바 있다. 붓꽃 품종 데이터셋으로 결정트리 모델을 학습시키고 시각화한 예시 코드는 아래와 같다.
- 데이터 로드 후 결정트리 모델 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
## DecisionTreeClassifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
## load iris data
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11)
## training model
dt_clf.fit(X_train, y_train)- export_graphviz() API를 사용하여 시각화 결과 저장
from sklearn.tree import export_graphviz
## DecisionTreeClassifier Results visualization
## 시각화 결과를 tree.dot 파일로 저장
export_graphviz(dt_clf, out_file='tree.dot', class_names=iris_data.target_names, feature_names=iris_data.feature_names, impurity=True, filled=True)- Graphviz를 사용하여 시각화
import graphviz
## 생성된 tree.dot 파일을 graphviz가 읽어서 시각화
with open("/content/tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)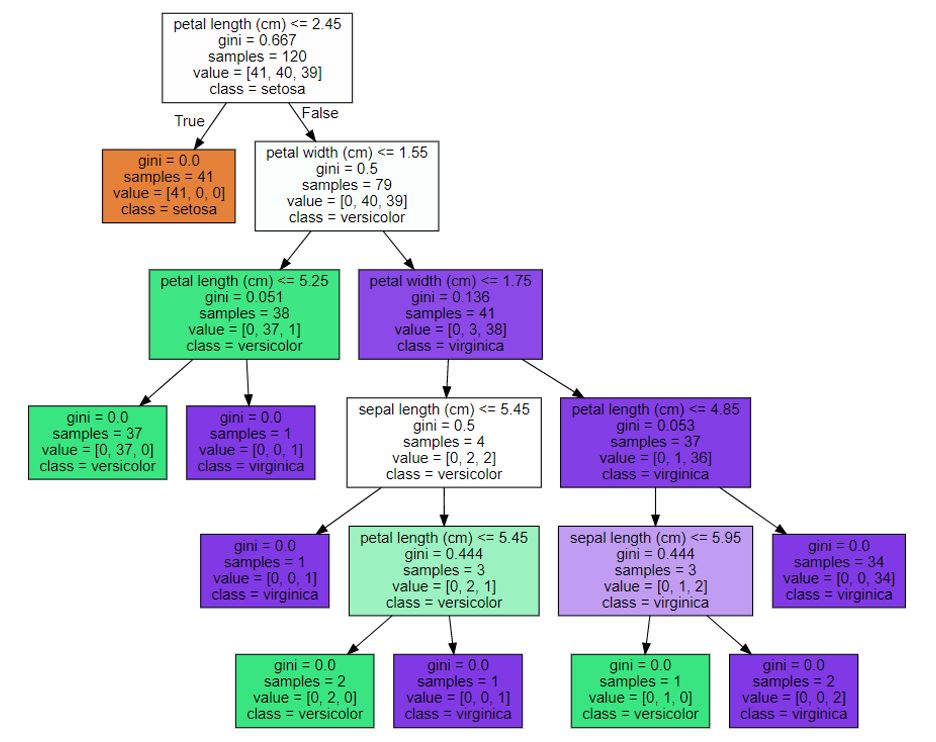
위 예시는 파라미터를 조정하지 않은 결정트리 모델의 학습 결과이다. 8번 노드의 서브 트리를 보면 해당 모델은 과적합이 상당히 높은 모델임을 알 수 있다.
ch4.2 하이퍼 파라미터 변경
과적합을 줄이기 위해 max_depth 하이퍼 파라미터를 변경한 결과는 다음과 같다. 아래와 같이 하이퍼 파라미터를 조정하여 더 간단한 결정트리를 생성할 수 있다.
- 데이터 로드 후 결정트리 모델 학습 (하이퍼 파라미터 max_depth=3 지정)
## 과적합 방지를 위해 max_depth 하이퍼 파라미터 변경
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
## DecisionTreeClassifier 생성
dt_clf = DecisionTreeClassifier(max_depth=3, random_state=156)
## load iris data
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=11)
## training model
dt_clf.fit(X_train, y_train)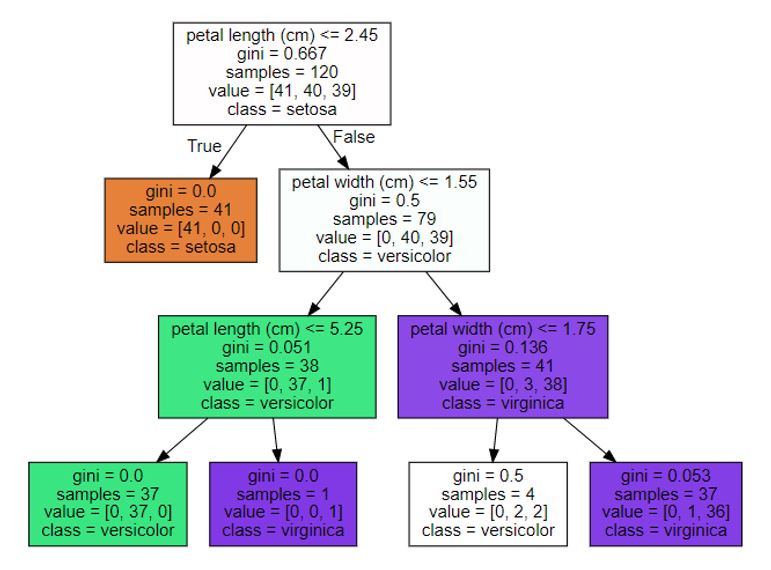

행복한 소히의 이것저것