이번 장에서는 kaggle의 신용카드 데이터셋을 이용하여 신용카드 사기 검출 분류 실습을 수행한다.
ch4.10 Undersampling & Oversampling
일반적으로 사기 검출 (Fraud Detection) 이나 이상 검출 (Anomaly Detection) 과 같은 데이터셋은 레이블 값이 불균형한 분포를 가지기 쉽다.
불균형한 데이터셋으로 모델을 학습시킨다면 다수의 레이블로 치우친 학습으로 인해 제대로 된 이상 데이터 검출이 쉽지 않다. 이러한 문제를 해결하기 위해 사용되는 대표적인 방안으로 '오버 샘플링' (oversampling) 과 '언더 샘플링' (undersampling) 이 있다. 이때, 일반적으로 예측 성능에 유리한 '오버 샘플링'이 상대적으로 더 많이 사용된다.
-
언더 샘플링
많은 레이블을 가진 데이터셋을 적은 레이블을 가진 데이터셋 수준으로 감소 -
오버 샘플링
적은 레이블을 가진 데이터셋을 많은 레이블을 가진 데이터셋 수준으로 증식
단, 동일한 데이터셋을 증식하는 방법은 과적합의 원인이 되기 때문에 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식하는 방식을 취함
대표적으로 SMOTE (Synthetic Minority Over-Sampling Technique) 방법이 있음
- SMOTE
오버 샘플링의 대표적인 방법으로, 원본 데이터에 있는 개별 데이터들의 K-Nearest Neighbor 을 찾아서 이 데이터와 K 개의 이웃들의 차이를 일정 값으로 만들어 기존 데이터와 약간 차이가 나는 새로운 데이터를 생성하는 방식## SMOTE를 구현한 대표적인 파이썬 패키지 = imbalanced-learn conda install -c conda-forge imbalanced-learn
지금부터 불균형 데이터셋으로 인한 문제를 해결하고 모델 학습 및 평가를 진행한다.
ch4.10 Data
- 데이터 로드
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
card_df = pd.read_csv('/content/drive/MyDrive/파이썬 머신러닝 완벽 가이드/data/creditcard/creditcard.csv')
card_df- 데이터 불균형 확인
## 데이터 확인
card_df.info() ## class (int), 나머지 feature (float)
card_df.describe()
## 데이터 불균형 확인
card_df['Class'].value_counts()ch4.10 데이터 일차 가공
- 불필요한 피처 삭제
def get_preprocessed_df(df=None):
## 불필요한 Time feature 삭제
df_copy = df.copy()
df_copy.drop('Time', axis=1, inplace=True)
return df_copy- train / test 데이터셋 분리
from sklearn.model_selection import train_test_split
def get_train_test_dataset(df=None):
## Time feature을 삭제한 df를 받아옴
df_copy = get_preprocessed_df(df)
## X, y 분리
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:, -1]
## train, test으로 데이터셋 분리
X_train, X_test, y_train, y_test = train_test_split(
X_features, y_target,
test_size=0.3,
random_state=0,
stratify=y_target ## train, test의 레이블 값 분포도를 동일하게 설정
)
return X_train, X_test, y_train, y_test## train, test 비슷하게 분할 되었는지 label 비율 확인
print(y_train.value_counts() / y_train.count() * 100)
print(y_test.value_counts() / y_test.count() * 100)ch4.10 Eval Metric
- 모델 성능 평가 함수 선언
## 모델 성능 평가 함수 선언
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
f1 = f1_score(y_test, pred)
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f}, F1: {3:.4f}, AUC: {4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))ch4.10 데이터 변환 전 모델 성능 확인
- LogisticRegression
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(
max_iter=1000
)
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
lr_pred_proba = lr_clf.predict_proba(X_test)[:, 1]get_clf_eval(
y_test, lr_pred, lr_pred_proba
)
- LightGBM
def get_model_train_eval(model, ftr_train, ftr_test, tgt_train, tgt_test):
model.fit(ftr_train, tgt_train)
pred = model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:, 1]
get_clf_eval(tgt_test, pred, pred_proba)from lightgbm import LGBMClassifier
## model load
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1,
boost_from_average=False
)
## train and eval
get_model_train_eval(lgbm_clf, X_train, X_test, y_train, y_test)
ch4.10 데이터 분포도 변환 - StandardScaler
왜곡된 분포도를 가지는 데이터를 재가공한 뒤에 모델을 다시 테스트 해본다.
- Amount 피처 분포도 확인
데이터의 피처들 중, Amount 피처는 신용카드 사용 금액을 나타내는 피처로, 정상 혹은 사기 트랜잭션을 결정하는 매우 중요한 피처일 가능성이 높다. Amount 피처의 분포도를 확인해보면 다음과 같다.
## feature Amount는 신용카드 사용 금액을 의미하는 피처인데, 이는 정상 / 사기를 결정하는 매우 중요한 속성일 가능성이 높음
## Amount 분포 확인
import seaborn as sns
plt.figure(figsize=(8, 4))
plt.xticks(range(0, 30000, 1000), rotation=60)
sns.histplot(card_df['Amount'], bins=100, kde=True)
plt.show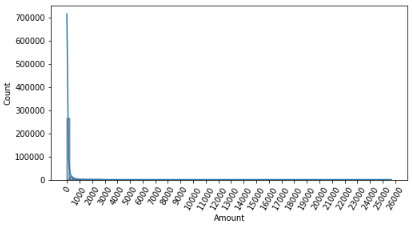
대부분의 선형 모델은 중요 피처들의 값이 정규 분포 형태를 유지하는 것을 선호하는데, 위 결과를 통해 Amount 피처는 대부분의 값들이 1000 이하에 집중되어 있고, 꼬리가 긴 형태의 분포 곡선을 가지고 있음을 알 수 있다.
- Amount 피처를 표준 정규 분포 형태로 변환
from sklearn.preprocessing import StandardScaler
def get_preprocessed_df(df=None):
## df copy
df_copy = df.copy()
## Amount 피처를 표준 정규 분포 형태로 변환
scalar = StandardScaler()
amount_n = scalar.fit_transform(df_copy['Amount'].values.reshape(-1, 1))
## 변환된 피처를 새로운 열로 추가
df_copy.insert(0, 'Amount_Scaled', amount_n)
## 기존의 Time, Amount 피처 삭제
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copyX_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
- 모델 학습 및 평가
print('## logistic regression ##')
lr_clf = LogisticRegression(
max_iter=1000
)
get_model_train_eval(lr_clf, X_train, X_test, y_train, y_test)
print('## lightgbm ##')
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1
)
get_model_train_eval(lgbm_clf, X_train, X_test, y_train, y_test)
ch4.10 데이터 분포도 변환 - log1p
로그 변환은 원래의 값을 log 값으로 변환하여 원래 큰 값을 상대적으로 작은 값으로 변환하기 때문에 데이터 분포도의 왜곡을 상당 수준 개선해 준다. 넘파이의 log1p() 함수를 이용하여 적용이 가능하다.
- Amount 피처 로그 변환
def get_preprocessed_df(df=None):
## df copy
df_copy = df.copy()
## Amount 피처를 로그 변환
amount_n = np.log1p(df_copy['Amount'])
## 변환된 피처를 새로운 열로 추가
df_copy.insert(0, 'Amount_Scaled', amount_n)
## 기존의 Time, Amount 피처 삭제
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
return df_copyX_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
- 모델 학습 및 평가
print('## logistic regression ##')
lr_clf = LogisticRegression(
max_iter=1000
)
get_model_train_eval(lr_clf, X_train, X_test, y_train, y_test)
print('## lightgbm ##')
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1
)
get_model_train_eval(lgbm_clf, X_train, X_test, y_train, y_test)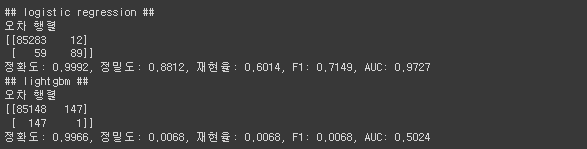
ch4.10 이상치 제거
아웃라이어 (Outlier) 라고도 불리는 이상치 데이터는 전체 데이터의 패턴에서 벗어난 이상 값을 가지는 데이터를 의미하며, 일반적으로 IQR 방식을 적용하여 제거한다.
-
이상치 제거 후 모델 학습 및 평가 프로세스
1. 어떤 피처의 이상치 데이터를 검출할 것인지 선택
레이블과 상관성이 높은 피처들을 위주로 이상치를 검출하는 것이 좋다!2. 이상치 데이터 검출하기
일반적인 데이터가 가질 수 있는 최댓값 = 3/4 분위수 (Q3) + IQR x 1.5 로 설정
일반적인 데이터가 가질 수 있는 최솟값 = 1/4 분위수 (Q1) - IQR x 1.5 로 설정
(단, 1.5 값이 아닌 다른 값을 적용할 수 있으며, 일반적으로 사용되는 값은 1.5임, IQR은 Q1 ~ Q3 구간의 범위를 의미함)
→ 이때, 설정한 최솟값과 최댓값 사이에 있지 않은 데이터를 이상치로 간주한다!3. 이상치 데이터 제거
- 어떤 피처의 이상치 데이터를 검출할 것인지 선택하기
import seaborn as sns
plt.figure(figsize=(9, 9))
corr = card_df.corr() ## dataframe의 각 피처별로 상관도를 구함
sns.heatmap(corr, cmap='RdBu') ## 상관도를 시본의 heatmap으로 시각화 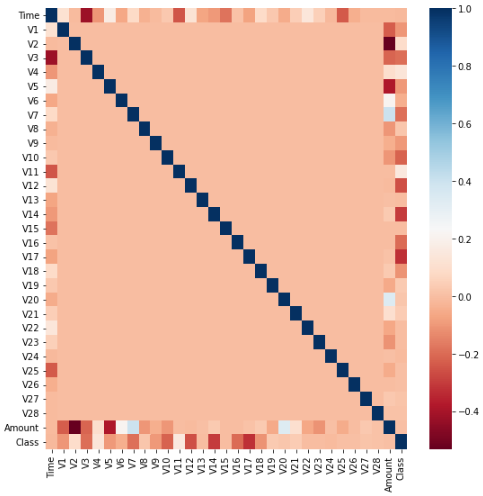
- 이상치 데이터 검출하기
## 위 결과는 양의 상관관계가 높을수록 파란색, 음의 상관관계가 높을수록 빨간색으로 표현된 결과
## 피처 선정 - V14 (class와 음의 상관관계가 가장 높은 V14, V17 중 V14에 대해 이상치 검출 후 제거 수행할 것임)
import numpy as np
def get_outlier(df, column, weight=1.5):
## Q1, Q3 지점을 np.percentile로 구하기
fraud = df[df['Class']==1][column]
q_25 = np.percentile(fraud.values, 25)
q_75 = np.percentile(fraud.values, 75)
## IQR 구하기
iqr = q_75 - q_25
iqr_weight = iqr * weight
## 최소, 최대 설정하기
low_val = q_25 - iqr_weight
high_val = q_75 + iqr_weight
## 최소와 최대 사이에 있지 않은 값은 이상치로 간주하고 인덱스 반환
outlier_index = fraud[(fraud < low_val) | (fraud > high_val)].index
return outlier_indexoutlider_index = get_outlier(card_df, 'V14', 1.5)
outlider_index
- 이상치 데이터 제거
def get_preprocessed_df(df=None):
## df copy
df_copy = df.copy()
## Amount 피처를 로그 변환
amount_n = np.log1p(df_copy['Amount'])
## 변환된 피처를 새로운 열로 추가
df_copy.insert(0, 'Amount_Scaled', amount_n)
## 기존의 Time, Amount 피처 삭제
df_copy.drop(['Time', 'Amount'], axis=1, inplace=True)
## 이상치 데이터는 삭제하는 로직 추가
outlier_index = get_outlier(df_copy, 'V14', 1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copyX_train, X_test, y_train, y_test = get_train_test_dataset(card_df)- 모델 학습 및 평가
print('## logistic regression ##')
lr_clf = LogisticRegression(
max_iter=1000
)
get_model_train_eval(lr_clf, X_train, X_test, y_train, y_test)
print('## lightgbm ##')
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1
)
get_model_train_eval(lgbm_clf, X_train, X_test, y_train, y_test)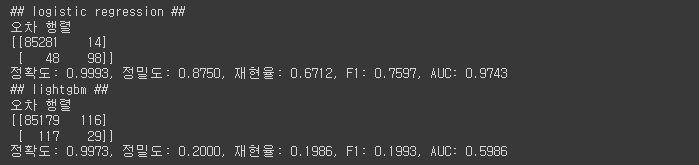
위와 같이 이상치 제거 후 모델 성능이 향상된 것을 확인할 수 있다!
ch4.10 SMOTE 오버 샘플링 적용
SMOTE 기법으로 오버 샘플링 적용 시, 올바른 검증을 위해 반드시 학습 데이터셋만 오버 샘플링을 해야 한다.
- fit_resample()을 이용한 SMOTE 오버 샘플링 적용
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
## SMOTE 오버 샘플링 적용
X_train_over, y_train_over = smote.fit_resample(X_train, y_train)
## 데이터 확인
print('SMOTE 적용 전 학습용 데이터셋:')
print(X_train.shape, y_train.shape)
print()
print('SMOTE 적용 후 학습용 데이터셋:')
print(X_train_over.shape, y_train_over.shape)
print()
## SMOTE 적용 후 레이블 값 분포
print('SMOTE 적용 후 레이블 값 분포:')
print(pd.Series(y_train_over).value_counts())
print()
- 모델 학습 및 평가
print('## logistic regression ##')
lr_clf = LogisticRegression(
max_iter=1000
)
get_model_train_eval(lr_clf, X_train_over, X_test, y_train_over, y_test)
print('## lightgbm ##')
lgbm_clf = LGBMClassifier(
n_estimators=1000,
num_leaves=64,
n_jobs=-1
)
get_model_train_eval(lgbm_clf, X_train_over, X_test, y_train_over, y_test)
모델 성능 결과를 보면, 재현율은 개선되었지만 정밀도가 떨어졌음을 알 수 있다. 이처럼 일반적으로 SMOTE를 적용하면 재현율은 높아지지만, 정밀도는 낮아지는 경향이 있다. 때문에 SMOTE는 정밀도 지표보다 재현율 지표를 높이는 것이 중요한 TASK에서 사용하면 좋다.
