ch4.11 스태킹 vs. 배깅, 부스팅
스태킹 (Stacking) 과 배깅, 부스팅 비교
- 공통점은 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출한다는 것
- 차이점은 스태킹 앙상블의 경우, 1) 개별 알고리즘으로 예측한 데이터를 기반으로 2) 다시 예측을 수행한다는 것
ch4.11 스태킹 모델
스태킹 모델은 아래의 두 종류의 모델이 필요하다.
- 개별적인 모델
- 이 개별 모델의 예측 데이터를 학습 데이터로 만들어 학습하는 최종 메타 모델
즉, 스태킹 모델의 핵심은 여러 개별 모델의 예측 데이터를 각각 스태킹 (다시 합하는) 형태로 결합하여 최종 메타 모델의 학습용 피처 데이터셋과 테스트용 피처 데이터셋을 만든다는 것!
ch4.11 기본 스태킹
- 데이터 로드
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer_data = load_breast_cancer()
X_data = cancer_data.data
y_label = cancer_data.target- 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(
X_data, y_label,
test_size=0.2,
random_state=0
)- 개별 ML 모델 생성
knn_clf = KNeighborsClassifier(n_neighbors=4)
rf_clf = RandomForestClassifier(n_estimators=100, random_state=0)
dt_clf = DecisionTreeClassifier()
ada_clf = AdaBoostClassifier(n_estimators=100)- 스태킹으로 만들어진 데이터셋을 학습할 최종 모델 생성
lr_final = LogisticRegression()- 개별 ML 모델 학습
knn_clf.fit(X_train, y_train)
rf_clf.fit(X_train, y_train)
dt_clf.fit(X_train, y_train)
ada_clf.fit(X_train, y_train)- 개별 ML 모델 예측
knn_pred = knn_clf.predict(X_test)
rf_pred = rf_clf.predict(X_test)
dt_pred = dt_clf.predict(X_test)
ada_pred = ada_clf.predict(X_test)- 각 개별 모델의 정확도 확인
accuracy_score(y_test, knn_pred)
accuracy_score(y_test, rf_pred)
accuracy_score(y_test, dt_pred)
accuracy_score(y_test, ada_pred)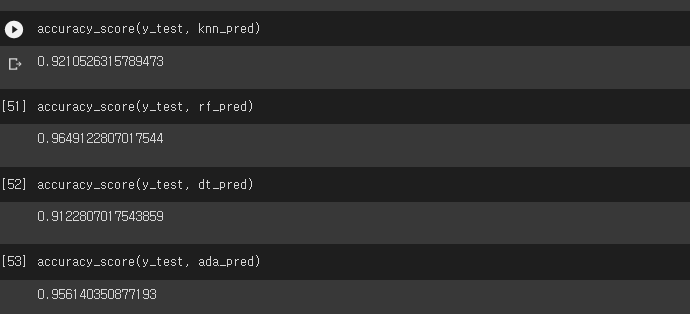
- 개별 ML 모델의 예측 결과를 피처로 만듦
pred = np.array([knn_pred, rf_pred, dt_pred, ada_pred]) ## 예측 결과를 행 형태로 붙임
pred.shapepred = np.transpose(pred)
pred.shape- 최종 메타 모델인 로지스틱 회귀 학습 및 평가 수행
lr_final.fit(pred, y_test)
final = lr_final.predict(pred)## 최종 메타 모델의 예측 정확도
accuracy_score(y_test, final)
ch4.11 CV 세트 기반의 스태킹
... 이어서 정리하기

행복한 소히의 이것저것