https://arxiv.org/abs/2204.10377
1. Introduction
Deep networks는 train set과 test set이 동일한 분포를 따를 때 visual tasks 학습에서 좋은 성능을 보이지만, unseen dataset에 대해서 domain shift가 발생하면 일반화 능력은 저하되기 마련이다.
이러한 distribution shifts에 잘 적응하고자 하는 것이 domain adaptation의 목적이고, 본 논문에서는 target data에 adapting 하는 동안 source data에는 접근할 수 없는 test-time adaptation(TTA)에 초점을 맞추고자 한다.
TTA의 setting은 다음과 같은 질문들을 제기할 수 있다.
- 어떻게 ground truth annotation 없이 target domain의 representation을 학습할까?
- source domain classifier를 대리로 사용할 수 있는 상황에서 target domain classifier를 어떻게 구축할까?
본 연구에서는 self-supervised contrastive learning을 target domain에서 사용하여 target sample 간의 쌍별 정보를 활용하는 test time adaptation 전략인 AdaContrast를 도입하고, 이를 pseudo-labeling과 공동으로 최적화하여 TTA를 수행하고자 한다.
2. Related Work
Domain adaptation
Unsupervised domain adaptation의 목표는 source model이 다른 target domain에서 배포될 때(target annotations 없이) 발생하는 성능 격차를 줄이는 것이다. 기존 연구들은 feature space alignment를 중심으로 진전을 이루었다. 하지만 대부분의 경우 adaptation동안 source dataset과 target dataset 모두에 접근해야하는 방법들이었다.
최근 source-free/test-time adaptation은 오직 source model과 unlabeled target data만 사용 가능한 경우의 setting에 집중하는데, 본 논문에서는 contextual modeling을 위한 contrastive learning과, 최신 업데이트를 위한 online pseudo-label을 갖춘다.
Self-supervised learning
Self-supervised learning은 transferable visual representation을 생성하는 데 성공적이다. 따라서 domain adaptation에 self-supervised learning을 적용하려는 연구도 많이 생겨났다.
한 예시로 on-target adaptation은 제안된 framework의 별도 stage에서 contrastive learning을 활용하여 target domain feature를 초기화하지만, 본 연구에서는 contrastive learning과 pseudo-labeling을 결합한 공동 학습 접근법을 제안한다.
Pseudo labeling
Pseudo labeling은 실제 label이 없는 샘플에 대해서 예측된 label이나 cluster assignment를 실제 ground truth label인 것처럼 supervision을 제공한다. 본 연구에서는 weak-strong consistency를 regularizer로 활용하면서, 뒤에서 언급하는 online refinement를 통해 pseudo-label의 noise를 추가로 줄이는 방법을 사용한다.
3. Method
본 논문에서는 source data가 adaptation 동안 사용될 수 없는 closed-set TTA를 다룬다.
- Source model은 source pairs인 (는 각각 image와 label)로부터 학습된다.
- 이러한 Source model이 주어졌을 때, 이를 unlabeled target data인 에 adaptation하고자 하는 것이 목표이고, 는 평가 목적으로만 접근된다.
- 이 때 source domain 과 target domain은 모두 같은 label space를 공유한다. (source에 없던 label이 target에 존재하진 않고, 그 역도 성립한다는걸 의미하는 듯)
- Source model은 feature extractor인 → 와 classifier → 를 포함하는 일반적인 architecture (는 feature dimension, 는 클래스 수)
- Test-time adaptation phase에서, target model인 는 source model의 매개변수 로 초기화 된다.
3.1. Online pseudo label refinement
Adaptation동안 source weights로 초기화된 target model을 사용하여 unlabeled target data에 대한 pseudo labels인 를 생성하는데, 이는 source domain에서 학습된 지식을 재사용하면서 점진적으로 target domain으로 bootstrapping하는 방식이다. 자세히 살펴보자.
Memory queue
Nearest Neighbor search를 위해 길이 의 memory queue 에 weakly augmented target samples에 대한 features와 predicted probabilities()를 저장한다. 그리고 현재 미니배치로 실시간으로 업데이트한다. 업데이트는 MoCo와 유사하게 enqueue와 dequeue로 수행되고, feature space를 더 안정적으로 유지하기 위해 천천히 변화하는 momentum model 를 사용하여 update features 와 probabilities 를 계산한다.

Momentum model 의 파라미터 는 초기에 source weights인 로 초기화되고, 각 미니배치 step마다 backpropagation이 아닌, momentum 으로 업데이트된다.
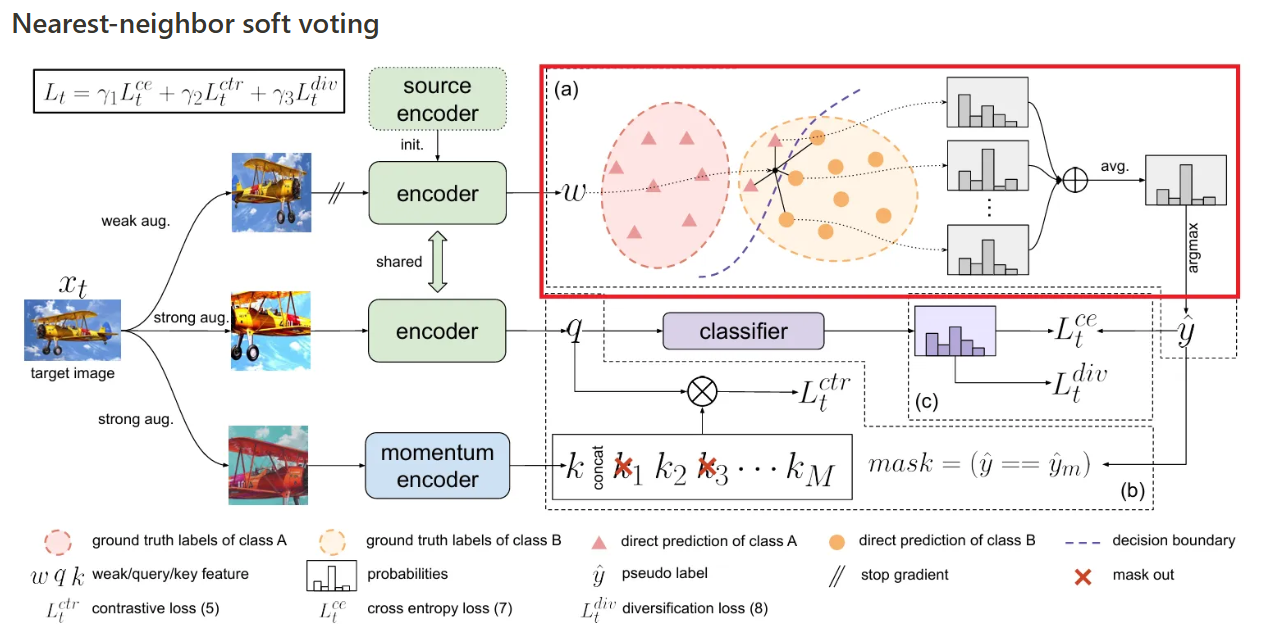
Nearest-neighbor soft voting

현재 classifier는 domain shift로 인해 target samples에 대해서 잘못된 결정을 내릴 수 있지만, 인근 포인트들의 지식을 집계함으로써 더욱 정보에 기반한 추정치를 얻을 수 있고, 잠재적으로 올바른 label을 복원할 수 있다.
Memory queue인 는 evolving target space를 잘 표현하기에, 저자들은 weakly-augmented image 의 feature vector 를 사용하여 로부터 개의 이웃들을 얻고, (간 코사인 유사도 기반) 이렇게 얻은 개의 이웃들의 probabilities를 아래와 같이 평균을 취해 soft voting을 진행한다.

여기서 는 에 대한 개 이웃 중 샘플 인덱스를 의미하고, 이렇게 soft voting을 취한 후, target sample에 대한 categorical probability의 덜 noisy한 추정을 얻고, 이를 기반으로 아래와 같이 pseudo label을 결정한다.


이렇게 얻어진 pseudo-label은 contrastive learning과 self-training의 공동 최적화에 사용된다.
3.2. Joint self-supervised contrastive learning

Test time adaptation 동안 target data에 대하여 self-supervised contrastive learning을 self-training과 공동으로 적용한다. 이 때 contrastive learning은 동일 이미지의 서로 다른 view는 가깝게, 다른 이미지의 view는 멀리하도록 하는 instance discrimination 원칙을 따랐다.
target image 가 주어졌을 때, 동일 분포 에서 두 개의 strong augmentation을 랜덤하게 추출하여 를 얻고, 를 각각에 적용하여 와 를 얻는다. 자세한 내용은 MoCo의 prototype을 따르고, 몇몇 변경된 사항은 아래에서 다룬다.
Encoder initialization by source
SimCLR, MoCo, BYOL 등에서 처럼 image encoder를 처음부터 학습하는 대신, 저자들은 source model의 가중치로 초기화된 target encoder 를 재활용한다. 또한, MoCo의 momentum encoder 도 채택하고, 이 또한 source weights로 초기화된다.

이 때 momentum encoder는 3.1절에서 언급한 memory queue 를 업데이트 하는 데 사용된 momentum encoder와 동일한 것으로, source weight 에 포함된 지식을 재사용함으로써, constrastive learning은 정보가 많은 feature space에서 시작하므로 학습 수렴에 있어서 매우 적은 epoch만으로도 충분하다고 한다.
Exclusion of same-class negative pairs
앞서 언급했듯이 target image는 두 개의 다른 버전인 와 로 augmentation 된 후 각각의encoder를 거쳐 와 로 인코딩 되는데, 각각은 query()와 key()가 된다. 길이 의 Memory queue인 는 를 저장하고, 이는 로부터 업데이트된다.
MoCo의 InfoNCE loss는 와 간 코사인 거리를 최소화하도록 하면서, 각 와 의 모든 요소 간 거리는 최대화하도록 학습을 유도한다.

→ 저자들은 이 방식을 조금 바꿔서, 동일 클래스 pair는 멀어지지 않도록 하는 것이 의미론적으로 더 의미있는 cluster를 학습할 수 있다고 주장한다. 따라서 pseudo labels인 도 같이 저장해서 과거 key features와 같은 class에 속하는 쌍은 negative pairs에서 제외하도록 하였다.
Joint optimization with self-training
본 논문에서 제안하는 AdaContrast는 test-time adaptation phase에서 constrastive objective를 self-training과 공동으로 최적화된다.
3.3. Additional regularization
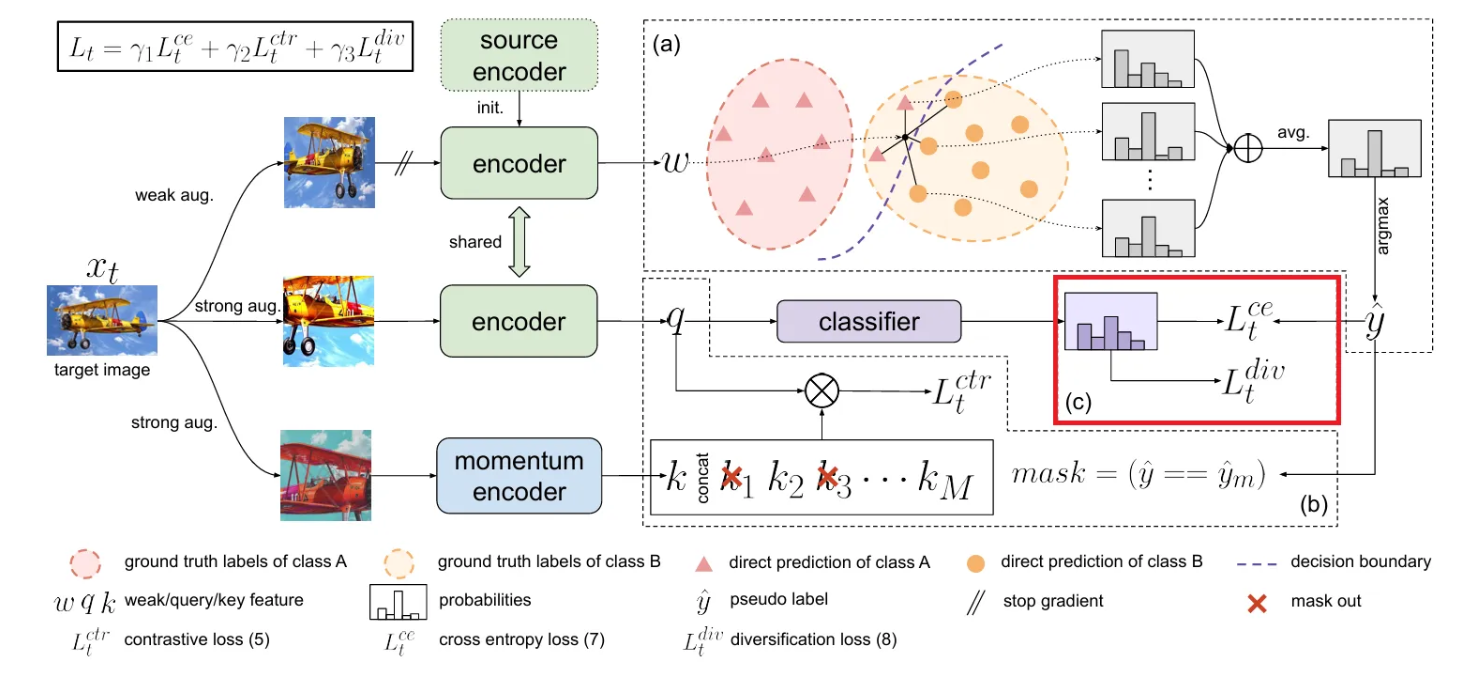
Weak-strong consistency
FixMatch에서 영감을 받아, weakly-augmented target image로부터 얻은 pseudo label 를 사용하여 strongly-augmented version에 대한 모델 예측을 “supervised”한다. 이 때 이전 연구와는 다른 몇 가지 차이점이 있다.
- 어떤 Ground Truth label도 접근할 수 없다.
- Pseudo-label을 사용하기 전에 refine한다.
- Confidence thresholding을 사용하지 않는다.
- Model은 source initialization에서 시작한다.
이러한 regularization은 cross-entropy loss에 반영된다.

여기서 는 이고, 이는 strongly-augmented query image 에 대한 예측 확률과 같다.
Diversity regularization
3.1절에서 도입된 online pseudo label refinement는 domain shift로부터 발생한 pseudo labels의 노이즈를 효과적으로 줄이지만, 여전히 Ground Truth labels와 완전히 동일하지는 않다. 따라서 adaptation동안 모델이 잘못된 label을 맹목적으로 믿는 것을 방지하기 위해 아래와 같이 class diversification을 장려하는 regularization term을 loss function에 추가한다.

이렇게 얻은 세 가지 종류의 loss를 선형결합하여 아래와 같은 전체 loss function을 얻는다.

여기서 각 값은 실험에서 조정 없이 모두 동일하게 1로 사용하였고, 이는 하이퍼파라미터에 민감하지 않다는 장점을 보여준다.
4. Experiments
해당 섹션에서는 주요 benchmarks에서 closed-set adaptation을 수행하여 제안된 AdaContrast와 이전 SOTA 알고리즘들의 결과를 비교하고, ablation과 analysis를 진행한다.
4.1. Experimental setup
실험에 사용된 dataset과 metrics, model architectures, baseline models, 그 외 implementation details는 논문 원문을 보면 자세히 나와있으니 참고
4.2. Results
VisDA-C train → val

VisDA-C의 train to val로의 shift에서 SOTA UDA 모델들과 비교한 결과, AdaContrast는 가장 좋은 성능을 보인 CAN과 거의 유사하며, TTA 설정에서는 SHOT에 비해 더 좋은 결과를 보였다.
DomainNet-126 seven domain shifts

Domain shifts of DomainNet-126에서 Adaptation동안 source data가 필요 없는 AdaContrast는 기타 TTA 방법들과 비교했을 때 가장 높은 평균 성능을 기록했다.
4.3. Analysis and Discussion
AdaContrast has better model calibration than entropy minimization-based methods.
Entropy minimization-based method들은 모델이 target predictions에서 “확신”하도록 만들어 좋은 성능을 보였지만, 이는 실제 label과 상관없이 직접적인 entropy optimization으로 인해 model calibration(머신러닝 모델의 신뢰도와 실제 정확도 간 일관성)이 방해받을 수 있다.
저자들은 TTA에 있어서 model calibration이 아주 중요한 요소인 점을 주장하였다.

따라서 VisDA-C validation set에서 SHOT과 AdaContrast의 model calibration 결과를 비교하였고, SHOT은 모델이 over-confidence를 보였지만, AdaContrast는 더 나은 calibration을 보여주었다.
AdaContrast is insensitive to hyper-parameters choices.
이전 TTA 문헌들에서 hyperparameter sensitivity가 가끔 무시될 때가 있는데, 저자들은 이를 TTA 알고리즘에 있어서 매우 중요한 측면으로 여긴다 .

따라서 이해 대한 실험도 진행한 결과, AdaContrast에 특화된 다양한 선택 범위에서 하이퍼파라미터인 Queue size와 Neighbor 수를 변경해가며 실험했을 때, 어느정도 일관성있는 성능을 보여주어 하이퍼파라미터 선택에 있어서 강건함을 보여주었다.
AdaContrast has strong performance in online test-time adaptation setting
저자들은 AdaContrast가 global memory bank나 adaptation 이전에 전체 데이터 셋을 처리하는 데 의존하지 않기 때문에, target image가 미니배치의 흐름에 따라 도착하고 각 이미지는 한 번만 보여지는 online adaptation에 적합하다고 주장한다.
위의 Table 1,2를 보면 online setting에서 몇 가지 offline 방법들보다도 나은 결과를 보이는 것을 확인할 수 있다.
4.4. Ablation studies
해당 섹션에서는 AdaContrast의 주요 요소인 online pseudo label refinement, joint contrastive learning, regularizations을 순차적으로 추가해가며 ablation을 진행하였다.


처음엔 각 epoch 시작 때 entire target dataset에 대해 추론을 수행하고, 각 predictions를 해당 epoch의 pseudo-label로 사용하는 가장 간단한 형태의 pseudo-labeling부터 적용한다. 이는 DN-126, VisDA-C에 대해 적용하였을 때 좋은 성능을 보인다.
Online pseudo label refinement
Table 4에서 3.1절에서 소개한 pseudo-labeling 방식으로 변경하여 online pseudo label refinement를 추가 적용하였을 때, 성능을 크게 향상시키지만, learning rate 10x에서는 noisy pseudo-label로 인해 모델이 과적합되고 성능이 급격히 하락한다.
Joint self-supervised contrastive learning
Joint contrastive learning을 추가로 적용하였을 때, Domain-126에서 추가 성능 향상을 보였고, VisDA-C lr1x에서는 약간 성능이 하락하지만 VisDA-C lr10x에서는 매우 큰 성능 회복을 보였다.
Diversity and weak-strong regularization
마지막으로 regularization까지 적용하였을 때 hyper-paremeter sensitivity가 낮고 안정적인 성능을 보여준다.
5. Limitations
Adaptation methods는 새로운 domain에 배포된 모델의 강건함을 올려줄 수 있지만, 이는 더 큰 AI applications에 이익과 해를 증폭시킬 수 있다.
6. Conclusion
본 논문에서는 Closed-set Domain Adaptation(DA)을 위한 새로운 Test-Time Adaptation(TTA) 기법을 제안하였다.
Pre-trained 모델을 기반으로 contrastive learning과 pseudo-labeling을 활용하였고, nearest-neighbors voting 기법으로 pseudo-label refinement를 추가하여 더 나은 pseudo-labels를 얻도록 하였으며 이는 기존 SOTA TTA 방법들보다 우수한 성능, 낮은 hyper-paremeter sensitivity, 더 나은 model calibration, 그리고 global memory banks의 불필요함을 보여주었다.
