
✍ 해당 시리즈 포스팅은 미시간 대학의 EECS 498-007 강의 내용을 정리한 글입니다. cs231n 강의와 유사하여 해당 시리즈 포스팅과 겹치는 부분이 많이 있을 수 있습니다.
Recap: Fast R-CNN Feature Cropping
지난 시간에 Fast R-CNN에서 region proposals를 image feature에 cropping하던 부분을 다시 살펴보자.
Cropping Features: RoI Pool

최종으로 생성된 feature의 shape이 512x20x15라면, 먼저 기존 이미지에서 region proposal을 구한 후, 이를 feature map에 맞춰 mapping하는 방식을 사용한다.

하지만 이는 feature map의 grid에 완벽히 mapping되지 않을 수 있으므로, grid cells에 맞춰서 snap (반올림)하는 과정이 필요하게 된다.

그리고 2x2 정도의 sub regions로 나눈 후 각각의 sub region에 대하여 max pooling을 진행한다. 이 방법을 통해 각각 다른 사이즈의 region proposals 에 대해서도 같은 사이즈의 region features를 얻을 수 있다.
하지만 snapping 과정에서 정렬이 무조건 잘 되는 건 아니고, 일부 sub-region 크기가 너무 크거나 작아지는 현상이 발생할 수 있다. 또한, RoI pooling은 좌표가 항상 정해진 grid cell에 snap되어 좌표 값이 미세하게 변해도 gradient가 변하지 않게 되고,
예를 들어 x좌표가 24.3 에서 24.4로 미세하게 변화하여도 결국 반올림하여 같은 grid가 되는데, 결과적으로 입력값 변화에 대한 출력값 변화가 없으므로 미분 값은 0이 된다.)
이에 따라 bounding box regression 학습 시 좌표에 대한 미분이 불가능하여 backpropagation이 불가능하다는 단점이 있었다.
Cropping Features: RoI Align
이에 대한 해결책이 RoI Align인데, 지난 시간엔 거의 없다시피 넘어가서, 이번 시간에 자세히 설명해주신다. Mask R-CNN에서 나온 방법이다.

우선 RoI pooling에서 발생하는 모든 snapping을 제거하여 모든 부분을 연속으로 만들어야 한다.
따라서 Region Proposal을 가져와 feature grid에 투영할 때, bilinear interpolation을 통해 grid snap 없이 feature를 뽑아오게 된다.
이는 먼저 region proposal을 4등분하고, 위 슬라이드에서 연두색 점으로 표시된 것 처럼 각각의 sub regions 별로 같은 간격의 sample point들을 잡는다.

그 후, 각 sample point 마다 bilinear interpolation을 적용해서 sample point가 하나의 새로운 값을 갖도록 한다.
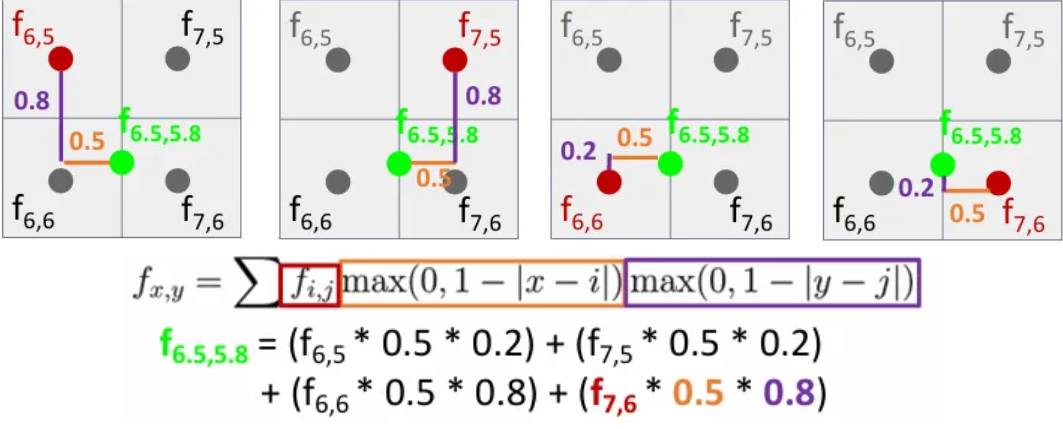
현재 sample point와 가장 가까운 4개의 grid cell의 feature 값들을 이용하여 가까운 거리의 feature에 더 큰 가중치를 주어 더하면 되는 방식이다.

그렇게 각 모든 연두색 feature들을 bilinear interpolation을 통해 구하였다면, 이를 max pooling하여 최종으로 2x2 사이즈의 region features를 얻게된다. 위 방식을 사용하게 되면 각각의 region proposal이 cropping 되는 과정에서 좌표가 조금만 변화해도 결과도 같이 변화하여 미분이 가능하게 되고, 이에 따라 backpropagation이 가능해진다.
Object Detection without Anchors

R-CNN 시리즈를 지난시간까지 알아보았는데, 결국 Faster R-CNN도 anchor boxes에 의존하게 된다. Anchor boxes 없이 객체 탐지를 하는 방법은 없을까?
CornerNet

그러한 방법 중 하나가 CornerNet으로, 이는 객체의 왼쪽 상단과 오른쪽 상단 코너를 예측하여 객체를 감지하는 방법이다.
이는 backbone CNN에서 얻은 feature map에서 왼쪽 상단 좌표를 예측하기 위한 히트맵과, 오른쪽 하단 좌표를 예측하기 위한 히트맵을 얻도록 학습된다.
이후 같은 객체의 코너를 연결해야 하는데, 이는 공간의 모든 위치에 대한 embedding vector를 예측하고, embedding vector가 유사한 왼쪽 상단, 오른쪽 하단끼리 쌍을 이루게 된다.
Semantic Segmentation

이제 이미지 픽셀 별 category label을 지정하지만, 다른 instance까지 구분하지는 않는 semantic segmentation을 알아보자.
Sliding Window

과거 조금 단순무식한 방법은, 입력 이미지를 아주 작은 단위의 패치로 쪼갠 다음 각 패치에 대한 classification을 수행하는 것이다. 어느 정도 동작은 할 수 있으나, 모든 픽셀에 대해서 작은 영역으로 쪼개고, 이 모든 영역을 forward/backward pass 하는 것은 매우 비효율적이고, 서로 다른 영역이더라도 겹치는 구간이 어느 정도는 존재하게 된다.
Fully Convolutional Network

Fully connected layer가 없고, conv layer로만 구성된 네트워크이다. Convolution을 할 때 3x3 zero padding을 수행하게 되면 이미지의 spatial information을 잃지 않으면서 최종 출력은 CxHxW 크기인데, 이 때 C는 클래스의 수이다. 모든 픽셀의 Classification loss를 계산하고 평균을 취해서 back propagation을 수행한다.
이 방법은 아래와 같은 단점들이 있다.
- receptive field가 선형적으로 증가하기 때문에, 전체적인 receptive field를 얻기 위해서는 많은 양의 layer가 필요하게 된다.
- 만약 고해상도의 이미지가 들어오게 되면 계산량과 메모리가 너무 많이 든다.

따라서 네트워크 내부에서 downsampling 및 upsampling을 적용해주는 구조가 많이 쓰이게 되었다. 앞쪽의 높은 해상도에서는 conv layer를 조금만 사용하고, 점점 max pooling과 stride를 높여가면서 feature map을 downsampling 한다.
Image Classification 에서도 앞까지는 유사한 구조지만 뒤에는 보통 FC layer가 있었다. 하지만 Semantic Segmentation에서는 다시 spatial resolution을 다시 키우는 과정이 붙는다.
Downsampling은 pooling이나 strided convolution으로 한다 치고, Upsampling은 어떤 방식을 사용해야할까?
Unpooling

- Nearest Neighbor
- 2x2 를 input으로 받았다면, 해당하는 receptive field로 값을 그저 복사해서 4x4 를 출력한다.
- Bed of Nails
- unpooling region에만 값을 복사하고 다른 곳에는 모두 0으로 채워 넣는 방식이다.
Bilinear Interpolation

위에 RoI Align에서 사용하였던 방식인 bilinear interpolation을 활용할 수도 있는데, input channel이 2x2 크기라면, 이 input feature grid에 균일하게 4x4 grid를 배치하고, 앞서 배웠던 bilinear interpolation을 적용하면 된다.
Bicubic Interpolation
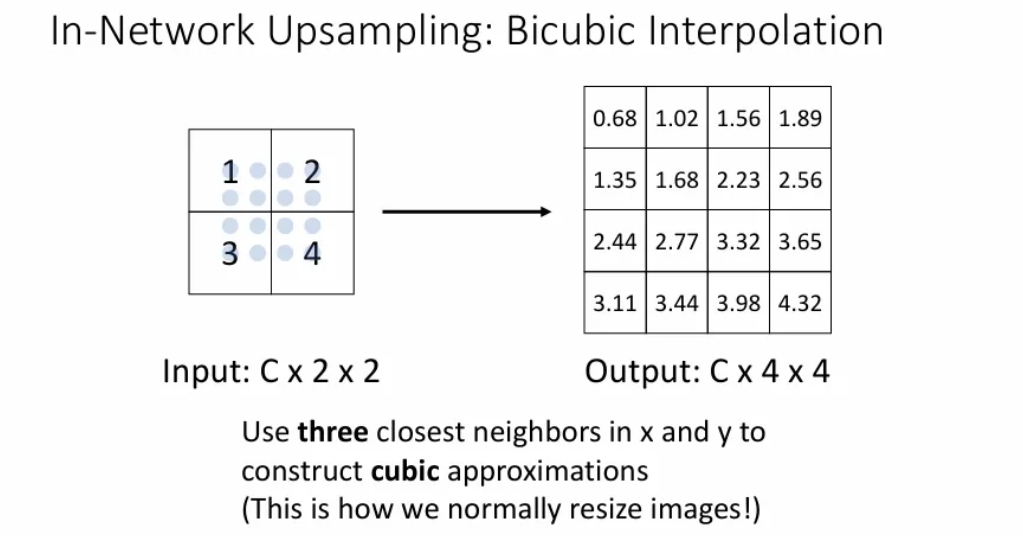
인접한 16개 픽셀을 이용하여 보간값을 계산하는 방법으로 bilinear보다 선명한 이미지를 얻을 수 있다.
Max Unpooling

Bed of Nails와 유사하되, 같은 자리에 값을 넣는 게 아니라 이전 max pooling에서 선택된 위치에 맞게 채워준다. 따라서 max pooling을 할 때 이전 max pixel 위치를 기억해야 한다.
Transposed Convolution
Downsampling 시 Strided convolution(stride를 늘려서 downsampling)은 고정된 함수가 아닌, 어떤 식으로 downsampling을 수행할 지 학습이 가능하다. 마찬가지로 feature map을 어떤 식으로 Upsampling 할 지 학습 가능한 방법이 Transpose Convolution이다.

우선 Stirde 2인 strided convolution을 보면, stride 를 2로 설정함으로써 이 2라는 값은 입력, 출력에서 움직이는 거리 사이의 비율이라고 해석할 수 있다. 위 슬라이드를 예시로 본다면 output에서 한 칸 움직이려면 input에서는 2칸 움직여야 한다. 이는 학습 가능한 방법으로 2배 downsampling 하는 것이다. (일반적인 pooling은 학습 없음)
이제 여기서 stride를 1보다 작은 값으로 설정하고, 입력에서 모든 포인트에 대해 출력에서 여러개의 포인트를 stride하는 방법이 transpose convolution이고, 이는 learnable한 upsampling이 될 것이다.

그럼 이제 Transpose Convolution을 자세히 살펴보자.
우선 input feature map에서 값을 하나 선택한다. 위 슬라이드의 input에서 빨간 값이 선택되었다고 하자. 이 값은 하나의 스칼라 값이다.
이제 이 스칼라 값은 3x3 필터와 곱해서 출력의 3x3 영역에 그 값으로 채워 넣는다. 필터와 입력의 내적이 아닌, 입력 값은 필터에 곱해지는 일종의 가중치 역할을 하게 된다.

그럼 이제 input의 빨간 값에서 한 칸 움직여서 파란 값이 선택되면, output에서는 두 칸 움직인다. 마찬가지로 똑같이 파란 스칼라 값을 필터에 곱해서 출력 값에 넣어준다. 이 때 출력에서 이전 receptive field와 겹치는 부분은 두 값을 더해준다.

이 과정을 반복하는 것이 Transpose Convolution이다. Deconvolution이라고도 하지만, 신호처리 관점에서 deconvolution은 정확히 convolution의 역 연산을 의미하기 때문에 Transpose Convolution이라고 하자. 이 외에도 up convolution(Unet 논문에서는 이렇게 표현), fractionally strided convolution, backwards strided convolution 이라고도 불린다.

Transpose Convolution을 이해하기 쉽게 1D로 표현하면 위 슬라이드처럼 표현될 수 있다.
그래서 왜 Transpose Convolution이라고 이름이 붙여졌을까?

stride가 1인 경우, 좌측 행렬곱에서 1D 필터는 , , 세개의 값을 갖는 3x1 벡터라고 생각하고, input 는 벡터인데, 이에 1D convolution을 진행 한다는 건 행렬과 벡터를 행렬 곱 한 결과와 같다.
그렇다면 우측 행렬곱을 보자. 단지 의 전치(Transpose) 행렬과 를 곱했을 때 결과는 위와 같은데, 이 결과는 기본 convolution과 결과는 유사하다.

하지만 stride가 2 이상인 경우, 의 전치 행렬과 의 곱은 위에서 예시로 보았던, 우리가 Transpose Convolution이라고 부르는 연산 결과와 같아진다. 그래서 Transpose Convolution이라고 부르는 듯하다.
강의를 들으며 ‘왜 겹치는 부분은 합을 취해주는가?’ 라는 의문이 있었는데, 이에 대한 답은 Transpose Convolution 수식과 맞추기 위함인 것 같다. 실제로 이 때문에 checkerboard artifacts가 발생하는 문제가 있고, 4x4 stride 2 혹은 2x2 stride 2로 사용하면 문제가 조금은 완화된다고 한다.
Instance Segmentation

이번엔 똑같은 segmentation이지만, 같은 클래스여도 다른 객체인 것 까지 판별하는 instance sementation에 대해 알아보자.
Mask R-CNN

기존에 Object detection에 쓰이던 Faster R-CNN에서 조금 변형하여 instance segmentation task를 수행 가능케하는 아키텍처이다.

입력 이미지를 CNN에 통과시켜 얻은 feature map으로 RPN을 거쳐서 ROIs를 얻는 것 까지는 Faster R-CNN과 동일하다. 하지만 그 후 Classification / Bbox Regression을 하는 것이 아니라, 각 Bbox를 갖고 해당 ROI 영역 내에서 Segmentation mask를 예측하도록 한다.
ROI pooling을 진행한 후에는 두 갈래로 나뉘게 되는데, 상단 갈래는 Faster R-CNN처럼 각 ROI가 어떤 카테고리에 속하는지 계산하고, 그 좌표를 보정해주는 Bbox regression도 수행한다.
하단 갈래에는 Semantic Segmentation을 위한 미니 네트워크가 있어서 각 픽셀마다 객체인지 아닌지를 분류한다.

Mask R-CNN에서 training targets는 bounding box에 따라 달라지는 것을 확인할 수 있다. 1열처럼 같은 의자여도 바운딩 박스에 따라서 segmentation이 이루어지는 것을 확인할 수 있고, 2열처럼 객체의 category에 레이블에 따라서도 각각에 대한 segmentation을 진행하게 된다.
Beyond Instance Segmentation
해당 섹션에서는 좀 더 발전된 segmentation tasks를 소개한다.
Panoptic Segmentation


Semantic segmentation과 instance segmentation을 결합한 방식으로, 이미지 내 모든 픽셀을 분류하면서, 개별 객체를 구분하는 기술이다.
개별 객체를 구분해야하는 클래스(사람, 자동차)로 instance segmentation 기법을 사용하는 “Thing” 클래스와 명확한 개별 경계가 없는 클래스(하늘, 도로)로 semantic segmentation 기법을 사용하는 “Stuff” 클래스로 나뉜다.
Human Keypoints

어떤 사람의 여러 key points를 통해 그 사람의 포즈를 분석하는 task이다.
Reference
유튜브 강의: https://www.youtube.com/watch?v=qcSEP17uKKY&list=PL5-TkQAfAZFbzxjBHtzdVCWE0Zbhomg7r&index=4
PDF: https://web.eecs.umich.edu/~justincj/slides/eecs498/FA2020/598_FA2020_lecture16.pdf
