http://cnnlocalization.csail.mit.edu/Zhou_Learning_Deep_Features_CVPR_2016_paper.pdf
Introduction
기존 CNN은 물체의 localizing에 탁월하지만, 최종적으로 분류를 위해 덧붙여지는 fully-connected layer에 의해 그 능력을 잃게 된다. 이에 NIN이나 GoogLeNet과 같이 fully-convolutional layer를 사용하는 연구도 많이 등장했다.
저자들은 regularizer로서 global average pooling(GAP)을 이용하였고, 그 결과 분류를 위해 훈련된 모델에서도 간단하게 물체의 위치까지 유추할 수 있게 되었다.
Class Activation Mapping
저자들은 Network in Network(NIN), GoogLeNet을 기반으로 한 architecture를 사용하였다고 한다. convolutional feature map에 global average pooling을 적용하고, 이를 fully-connected layer의 feature로 활용한 간단한 연결 구조를 이용하여 이미지의 region 별 중요도를 파악할 수 있다. 이는 output layer의 weight를 convolutional feature maps에 다시 projecting 하는 class activation mapping(CAM)이라는 기법을 활용한다.
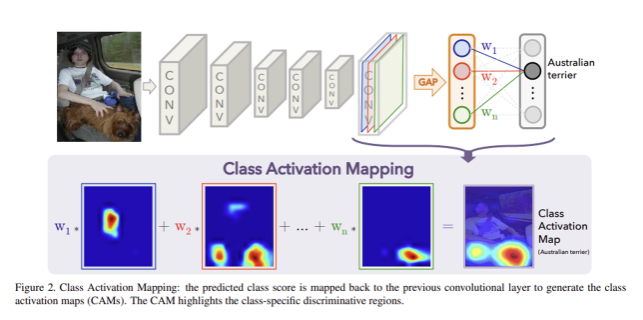
위 그림처럼 최종 convolutional layer의 각 feature map 별 global average pooling을 적용한 결과에 weighted sum을 적용하여 최종 output을 생성해낸다. 그리고 최종 convolutional layer의 각 feature map에 대해서도 weighted sum을 계산하여 class activation map을 얻는다.
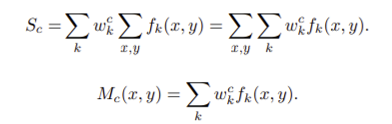
는 spatial location 에서의 last convolutional layer의 번째 unit의 activation
는 unit 에 대해 global average pooling을 적용한 결과이고, 위 그림에서 파랑, 빨강, 초록 feature map들이 GAP을 거쳐 나온 원이다. 주어진 어떤 클래스 에 대해서 softmax의 input이 되는 는 해당 에 대한 와 각 의 가중합이다.
는 class 에 대한 activation map으로 정의
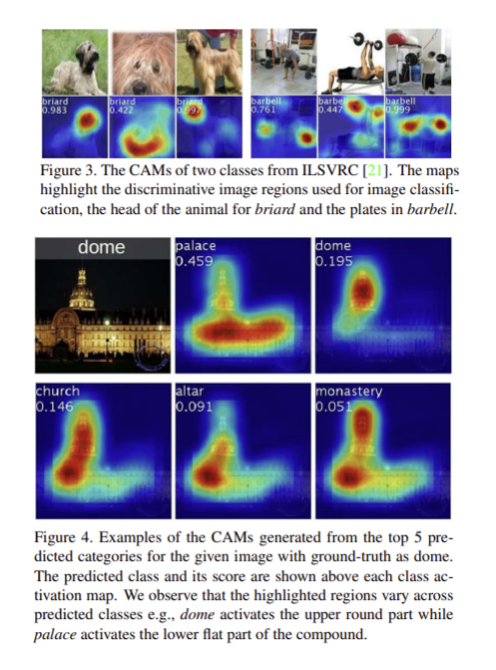
아래는 결과 예시
Global average pooling vs Global max pooling
weakly supervised object localization에서 GAP, GMP 적용 결과는 직관적인 차이가 존재한다. GMP는 하나의 discriminative part를 식별하는 데 유용하지만, GAP loss는 물체의 크기를 식별하는 데 유용하다. 따라서 classification에 있어서는 둘이 비슷한 성능을 내지만, localization에는 GAP가 더 좋은 성능을 보인다고 한다.
Weakly-supervised Object Localization
Setup
- AlexNet, VGGNet, GoogLeNet 구조를 활용하나 앞서 언급했듯, 마지막의 fully connected layer 대신 Global Max Pooling layer를 적용하였다. 세팅을 위해 각 구조 별로 특정 conv layer를 제거.
- 각 network는 ILSVRC 2015의 1.3M 크기의 training image로 훈련된 모델을 fine-tuning
- 비교 대상은 분류에서는 original AlexNet, VGGNet, GoogLeNet, NIN.
- localizaiton에서는 original GoogLeNet, NIN, 그리고 CAM 대신 backpropagation을 이용한 모델.추가적으로, global average pooling과 global max pooling을 비교하기 위한 GoogLeNet-GMP
Results
Classification
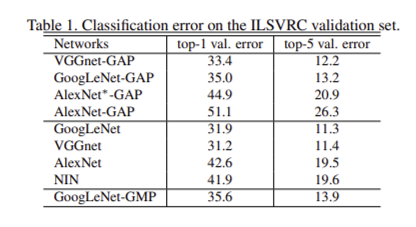
각 아키텍처 별로 conv layer를 조금씩 제거했지만 AlexNet-GAP를 제외하고는 크게 성능이 하락한 모델은 없었다. AlexNet-GAP도 GAP layer 직전 두 개의 conv layer를 추가하여 새로 만든 AlexNet*-GAP 모델에서는 original AlexNet과 비슷한 분류 결과를 낼 수 있었다.
Localization
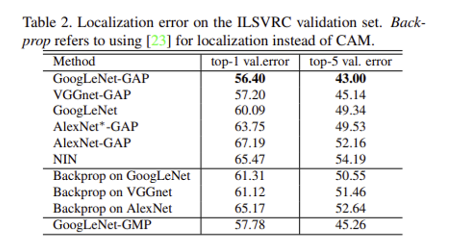
- localization을 수행할 땐 히트맵에서 max 값의 20% 이상인 region만 thresholding 적용 한 후 그 모든 부분을 cover하는 가장 작은 bounding box를 생성
- GoogLeNet-GAP 모델이 다른 baseline 모델 및 backpropagation 모델들을 능가.
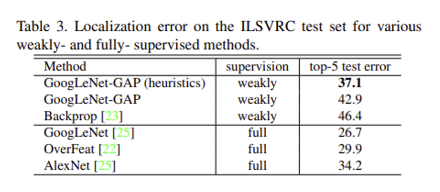
저자들은 이미 존재하는 weakly-supervised, fully-supervised methods와의 차이를 비교하기 위한 실험도 진행함. ILSVRC test set에 대해 실험하였고, 여기서는 heuristic 방식의 bounding box selection strategy를 추가로 실험. heuristic 방식이 weakly-supervised에서는 좋은 성능을 보였지만 아직 fully-supervised에 비해서는 아직 갈 길이 멀다.
Deep Features for Generic Localization
GAP를 통해 얻은 representation이 다른 task에도 generic feature로써 좋은 성능을 낼 수 있는지를 평가하기 위해 GAP 결과에 linear SVM을 학습시킴으로써 성능 평가

결과는 위와 같이 어느정도 좋은 성능을 내었음을 확인할 수 있음
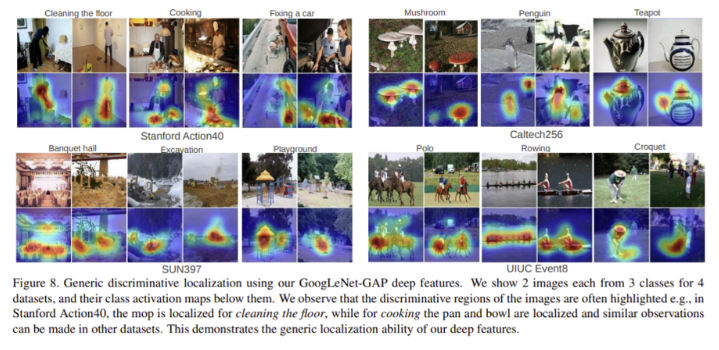
추가로, 이렇게 linear SVM의 weight를 곱해 얻은 CAM이 다른 데이터 셋에 대해서도 localization을 잘 수행하는지 실험하였는데, 아래와 같이 중요한 region을 잘 찾아낸 것을 확인할 수 있었다.
Fine-grained Recognition
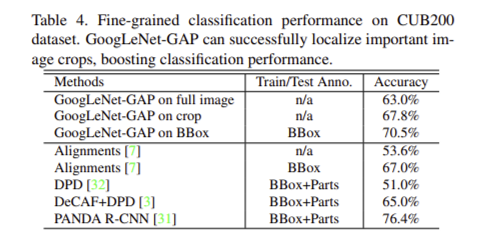
BoundingBox annotation이 있는, 200가지 새 이미지 데이터 셋인 CUB200 에 대하여 fine-grained recognition 실험
- 그냥 전체 이미지로 GoogLeNet-GAP을 학습시킨 모델보다, GAP를 통해 생성한 bounding box 만큼의 이미지를 crop한 후 다시 학습시킨 모델의 정확도가 거의 5%나 올라감
- BBox가 없으면 53.6%, BBox가 있어도 67%의 정확도를 내는 Alignments 모델과 비교했을 때 GAP 모델은 비교적 성능이 뛰어남
Conclusion
Global Max Pooling(GAP)를 사용하여 CAM이라는 기법을 제안한 논문이다. 이를 통해 bounding box annotation을 활용하지 않고도 물체의 위치를 학습할 수 있고, 결과로 나온 class activation map은 주어진 이미지에서 예측된 클래스 점수를 시각화하여 CNN이 감지한 식별 가능한 객체 부분을 강조해 줄 수 있다. 또한, Weakly supervised learning 으로서의 object localization 뿐 아니라, 다른 visual recognition tasks에도 잘 적용될 수 있다.
