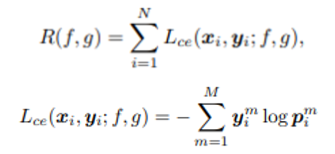
Coarse-labelled dataset에 sample 간 inter-sample relation을 활용한 새로운 contrastive learning 기법을 소개한 논문
Introduction
지도 학습과 심층 신경망을 사용한 성공은 이미지 분류, 행동 감지 및 객체 위치 지정과 같은 다양한 컴퓨터 비전 작업에서 큰 성과를 거둠. 하지만 몇몇 도메인에서의 주석 작업은 시간이 많이 걸리고 비쌈. 이에 따라 self-supervised learning과 semi-supervised learning 등을 이용한 learning framework가 많이 개발되고 있음. 해당 논문에서는 coarsely-labelled 데이터셋으로 fine-grained representation 학습에 집중하고자 함. 기존에도 self-supervised contrastive learning의 auxiliary task로 supervised learning을 결합하는연구가 많이 이루어졌고, 저자들은 inter-sample relation을 고려하는 MaskCon(Masked Contrastive Learning)을 소개함.
Methodology
는 라는 coarse label로 annotation 된 i.i.d samples. 은 샘플의 개수, 은 coarse 클래스의 개수. ‘ 을 씌우면 fine 클래스를 의미
Supervised learning
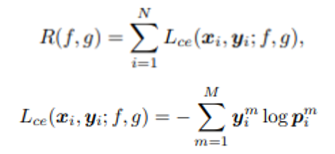
- 흔히 classification에서 사용되는 supervised learning framework의 cross entropy loss와 empirical risk
Contrastive learning
- supervised learning model의 parametric classifier 가 sample X의 semantic label Y로부터 학습되는 데 반해, Contrastive learnilng은 각 다른 샘플인 , 의 inter-sample relation을 의미하는 에 기반하여 학습. 가 1에 가까울수록 positive sample pairs
- inter-sample relation을 학습하기 위해, supervised learning 처럼 f라는 encoder 뒤에 라는 classifier가 오는 대신, 라는 projector가 붙음. 는 MLP로 구현되고, inter-sample relation인 Z를 정규화 함으로써 학습됨
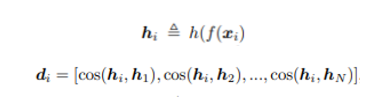
- 에는 각 의 prejection 끼리의 코사인 유사도 값들이 저장됨.
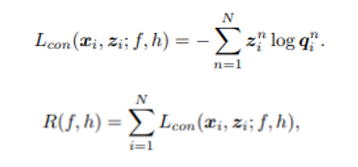
Self-supervised contrastive learning
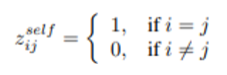
- 보통 self-supervised contrastive learning에서는 값은 원본 샘플이 같다면 1, 다르다면 0으로 간주. 목적은 같은 샘플로부터 augmentation 된 것들의 관계는 최대로, 다른 샘플로부터 나온 것들의 관계는 최소화 하는 것
- 저자들은 이러한 self-supervised loss를 으로 정의
Supervised contrastive learning
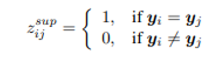
- contrastive learning을 supervised로 변환하는 방법은 간단함. sample , 가 같은 레이블을 가진다면 1, 다른 레이블이라면 0으로 를 정해주면 됨
- 저자들은 supervised contrastive loss를 으로 정의
Memory bank
- 실제 구현에서 와 모든 데이터 셋을 대조하는 것은 계산 및 메모리 제약이 크기 때문에, MoCo의 구조를 차용.
- 각 는 두 가지 랜덤하게 augmentation 된 (쿼리)와 (키)를 생성하고, 각각 projection을 거쳐 와 가 됨.
- 메모리 뱅크는 Queue(FIFO)로, 각 샘플의 를 저장
- 는 번째 샘플에 대한 와 자신을 포함한 개의 의 코사인 유사도를 저장
Baseline methods
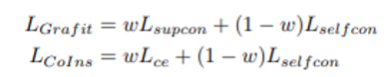
이전에 진행된 연구에서 self-supervised contrastive loss와 supervised 방식의 loss를 결합한 연구가 있었는데, 위(Grafit)는 앞서 정의했던 을 결합하였고, 아래(Colns)는 (supervised learning의 cross entropy)를 결합함.
는 각 loss의 weight
MaskCon: Masked Contrastive learning
단순히 coarse class가 같으면 같은 가중치를 주는 대신 fine class가 같은 샘플을 강조하기 위해 저자들은 MaskCon이라는 새로운 contrastive learning 기법을 소개하는데, 이는 inter-sample relation을 직접적으로 활용
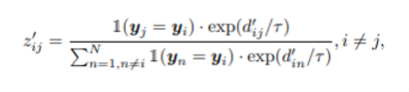
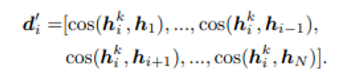
-
번째 샘플의 query와 key의 유사도는 항상 양성이 될 것이므로, 자신에 대한 key의 projection만 뺀 나머지 샘플 projection의 key값들과의 코사인 유사도를 활용하여 를 구함
-
주목할 점은 두 비교 대상의 클래스가 다르다면 는 0이 되도록 마스킹 한다는 것. 같은 coarse class인 것을 항상 양성으로 두기에는(같은 fine label일 확률을 매우 높게 보는 것) 위험이 존재하지만, 서로 다른 coarse class를 가지면 항상 음성이라는 것은 확신 가능. 이를 통해 의 noise를 줄일 수 있음. 기존 방식과 비교하자면,
- self-supervised contrastive learning은 같은 샘플에서 augmentation 된 것만 양성으로
- supervised contrastive learning은 같은 label로부터 augmentation 된 것만 양성으로
- maskCon은 다른 coarse label로부터 augmentation 된 것은 0으로, 같은 coarse label로부터 augmentation 된 것은 코사인 유사도에 기반하여 weight 부여. 같은 샘플로부터 나온 것은 1
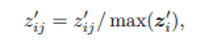
- 모든 를 구한 후에는 위처럼 rescaling 진행. 최종 loss는 아래와 같음
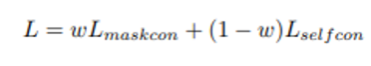
Experiments
Datasets
CIFAR, ImageNet-1K, Stanford Online Products dataset, Standford Cars 196 dataset
Comparison model
위에서 언급한 Grafit과 Colns 위주로 비교를 하였는데, w를 조절함에 따라 0이 되면 둘 다 SelfCon, 1이 되면 Grafits는 SupCon, Colns는 SupCE가 됨. 추가적으로, 실제 fine label로 학습 시킨 모델은 SupFine으로 정의.
Evaluation protocol
Recall@K 라는 지표를 활용. 각 test image에서 가장 가까운 개의 이웃들을 뽑아서, 하나라도 같은 fine label이 존재한다면 1, 하나도 없다면 0
CIFARtoy dataset
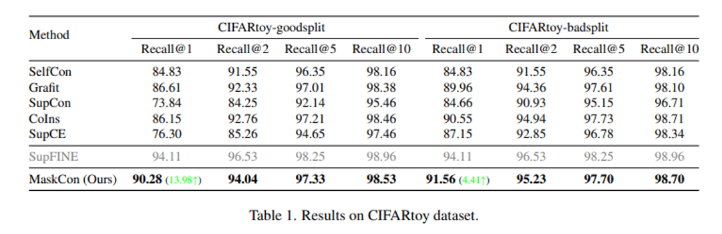
CIFAR10 데이터 셋에서 만든 장난감 데이터 셋. coarse label은 A와 B로 각각 유기체이냐, 아니냐에 따라 A는 ‘airplane’, ‘truck’, ‘automobile’, ‘ship’으로, B는 ‘horse’, ‘dog’, ‘bird’, ‘cat’으로 fine label이 나뉨. 추가적으로, bad split이라고 해서 몇 fine class는 섞어서 A는 ‘airplane’ ,’automobile’, ‘bird’, ‘cat’, B는 ‘horse’, ‘dog’ ,’ship’, ‘truck’으로 나누어 테스트도 진행.
MaskCon은 fine label로 학습된 SupFine과 유사한 성능을 내었고, 신기하게도 good split보다 bad split에서 더 좋은 결과가 나왔음
CIFAR100 dataset
20개의 coarse class가 존재하고, 그 마다 5개의 fine class가 있음. 즉, 총 합 100개의 fine class 존재. 결과는 아래와 같이 MaskCon이 Recall@10 지표를 활용했을 때 Colns를 제외하곤 우세
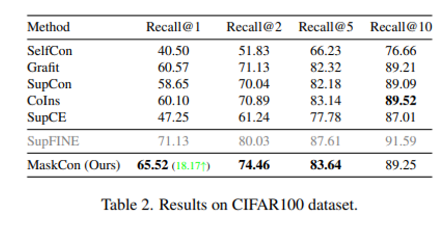
ImageNet-1K dataset
효율을 위해 32x32로 downsampling 하여 이용. coarse label이 따로 없기 때문에, WordNet hierarchy에 기반한 coarse label을 만들어줌. 성능이 썩 좋진 않았으나, 다른 모델에 비해 우세
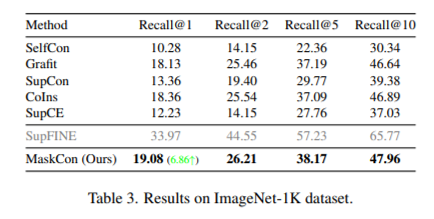
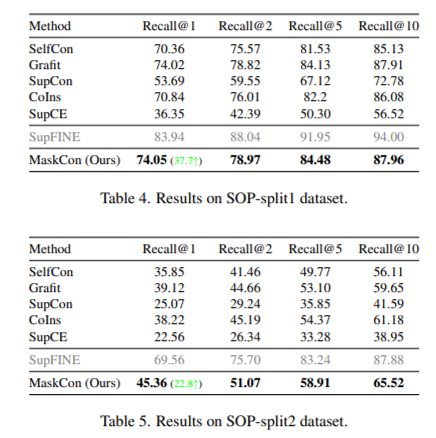
Stanford Online Products dataset
22,634개의 자동차 제품에 대하여 각각 다른 각도에서 찍은 2~12개의 이미지 데이터 셋으로, 총 120,053장의 이미지가 있음. 8장 이상의 이미지가 있는 제품들만 뽑아서 train, test set으로 분리한 SOP-split1와, 12장 모두 있는 제품들만 뽑아서 각 제품 당 10장을 train, 나머지 2장을 test로 분리한 SOP-split2 으로 실험 진행. 두 경우 모두 MaskCon 우세
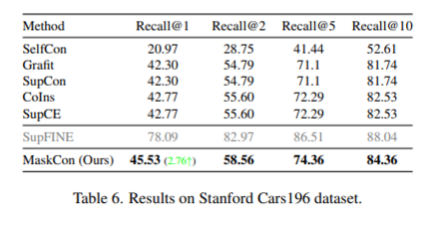
Stanford Cars196
196종류의 자동차 이미지들로 따로 coarse label이 정해져 있지 않기 때문에 ‘Cab’, ‘Sedan’, ‘SUV’, ‘Convertible’, ‘Coupe’, ‘Hatchback’ ,’Wagon’, ‘Van’ 종 8가지의 coarse class를 정의해줌. 모두 MaskCon 우세
더 자세한 데이터 셋에 대한 설명 및 실험 세팅은 원본 논문을 참고


nice 성호쿤!