[논문 리뷰] SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
논문리뷰
https://arxiv.org/pdf/2310.15308
UniReps Workshop at NeurIPS 2023, and the eLVM Workshop at CVPR 2024 에서 accept 된 논문
1. Introduction
CLIP, SAM, MAE, DINOv2와 같은 Vision Foundation Models(VFMs)는 도메인 별 데이터로 fine tuning하면 각 vision task에서 매우 뛰어난 성능을 보인다. 하지만 다양한 downstream task에 대해 이런 모델들을 유지하고 배포하는 것은 매우 비효율적이다. VFM들은 종종 매우 많은 양의 데이터셋을 필요로 하고, 계산량도 어마어마하다. 또한, 어떻게 최적의 데이터 셋을 섞을지, multi tasking에서 interfering gradients와 instabilities를 다룰지, 그리고 사유 데이터셋의 접근 제한 등으로 인해 실현 가능성은 제한된다.
이러한 문제를 극복하기 위해 model merging(모델 병합)은 연구 분야로써 급 부상하고 있다. 대부분의 병합 기법은 여러 task-specific 모델을 추가적인 학습 없이 단일 모델로 결합하는 데 초점을 둔다. Weight interpolation, parameter importance analysis, 모델에서의 invariance 활용 등이 사용될 수 있지만, 이는 데이터 사용이나 추가 학습, finetuning을 최소화하는 데 너무 집중한 나머지 성능 저하 등이 발생한다.
본 연구에서는 근본적으로 다른 목표로 학습되고 서로 다른 능력을 가지며, 다른 modalities와 상호작용할 가능성이 있는 VFMs를 병합하는 것을 목표로 한다.
2. Background
Vision-Language Models
CLIP과 ALIGN같은 vision-language models는 수십억 개 규모의 데이터셋에서 학습된다. 해당 모델들은 이미지 및 텍스트 인코더로 구성되며, 각각의 modality에 대한 임베딩을 생성해낸다. 학습 시에는 랜덤으로 샘플링된 image-text pairs 배치에 대해 대조학습을 진행하는데, 같은 쌍의 이미지와 텍스트 간 정렬을 최대화하도록 학습된다. 이렇게 학습된 모델은 zero-shot image-text retrieval, text prompts를 통한 zero-shot classification 등에 활용될 수 있다.
ViLT나 VLMo, BLIP같은 방법들은 이미지, 텍스트 modality 간 공유되고 혼합된 architecture를 탐색하여 Visual Question Answering이나 Captioning같은 추가적인 zero-shot 기능을 가능하게 하였다.
LiT, APE, BLIP-2같은 방법들은 pre-trained single-modal models를 활용하여 CLIP과 유사한 모델의 학습 비용을 절감하는 사용하는데, 이는 기존 사전 학습된 모델의 지식을 사용한다는 점에서 본 논문의 접근법과 유사하지만, 본 논문에서는 vision backbones를 단일 모델로 병합하는 multi-modal multi-encoder setup에 초점을 두고, 사전 학습된 모델의 zero-shot 능력을 trasnfer하는 것을 목표로 삼는다.
Segment Anything Model (SAM)
SAM은 프롬프트를 기반으로 segmentation을 가능케하는 대규모 데이터셋, 모델, 학습 방법을 도입한다. 해당 데이터셋은 image, geometric prompt, 그리고 segmentation mask 이렇게 세가지 요소로 구성되며, 아키텍처는 크게 세 요소로 구성된다.
- Image Encoder
- ViT-Det를 기반으로 하는데, MAE 목표로 사전학습되어 고주파 지역 정보가 풍부하다.
- Prompt Encoder
- Points, mask regions, bounding boxes같은 기하학적 input을 받는다.
- Mask Decoder
- 앞선 두 인코더의 출력을 기반으로 고해상도의 segmentation mask를 출력한다.
이후 FastSAM, MobileSAM 등 기존 SAM의 경량화 및 속도 향상을 목표로 하는 연구도 많이 진행되었고, 이러한 결과들은 본 연구에서 제안하는 방법의 기초적인 VFM으로 활용될 수 있다.
또한, SAM을 사용하여 가능한 모든 segmentation masks를 생성한 후, CLIP을 활용하여 해당 마스크에 label을 부여하는 방식으로 두 모델을 연결 가능함이 입증되었지만, 이는 두 모델을 동시에 로드 해야 해서 메모리 사용량이 매우 높고, forward pass량이 매우 높다.
Knowledge Distillation
.사전 학습된 대형 teacher model에 축적된 지식을 활용하여 압축된 classifier인 student model을 학습 시키는 방법이다. 본 연구와 관련해서는 최근 EVA, DIME-FM, CLIPPING, CLIP-KD와 같은 VLM을 위한 방법이 많이 탐구 되었고, 이를 통해 teacher model의 zero-shot 능력을 student model로 transfer 가능했다.
본 연구에서는 distillation과 self-distillation을 수행하여 두 개의 teacher model로부터 서로 다른 zero-shot 능력을 단일 모델로 transfer한다.
Continual Learning
본 연구는 기존 모델에 새로운 지식을 추가하는 continual learning과도 연관이 있는데, 이를 통해 이전에 학습한 지식이 손실되는 catastrophic forgetting을 최소화하고자, memory replay와 distillation을 기반으로 두 모델을 병합하도록 하였다.
Zero-shot Semantic Segmentation
zero-shot semantic segmentation은 특정 객체 클래스에 대한 사전 지식이나 fine-tuning 없이, open form의 text prompt를 받아서 dense segmentation mask를 예측하는 것을 목표로 한다.
최근 GroupViT, ViewCo, CLIPpy, ViL-Seg, OVS, TCL, SegCLIP 등의 연구에서는 image-text pairs 데이터셋과, CLIP같이 사전학습된 VLM의 internal representation을 통하여 dense segmentation masks를 얻는다.
본 연구에서는 텍스트 정보를 직접 사용하지 않는 대신, 텍스트 의미 정보는 사전 학습된 CLIP에서 얻어진다.
Merging Models
서로 다른 모델들의 능력을 단순한 interpolation 작업으로 결합하는 것이다. 본 연구에서는 data-dependent한 병합 방식이며, replay를 통해 각 모델의 original behavior을 반복적으로 상기하여 각 모델의 지식이 병합되도록 한다.
3. Proposed Approach
해당 섹션에서 저자들은 사전 학습된 VFM들을 효율적으로 병합하는 접근을 설명한다.
먼저 auxiliary VFMs로부터 base VFM으로 최소한의 forgetting으로 지식을 전이하는데, 이 때 각각의 VFMs는 vision encoder와, 다른 modality encoder들 및 task-specific decoders/heads를 가진다고 가정한다. 본 논문의 목표는 vision encoder들을 하나의 backbone으로 결합하여, 가중치가 얼려진 다른 modality encoder들과 함께 사용될 수 있도록 하는 것이다.
여기서 SAM을 basic VFM으로, CLIP을 auxiliary VFM으로 사용한다. SAM은 localization 및 고해상도 이미지 segmentation을 잘 하지만, 의미적 이해에는 한계가 있다. 반면에, CLIP은 의미적 이해를 위한 강력한 image backbone을 제공하는데, 이를 아래 그림의 실험을 통해 보여준다.
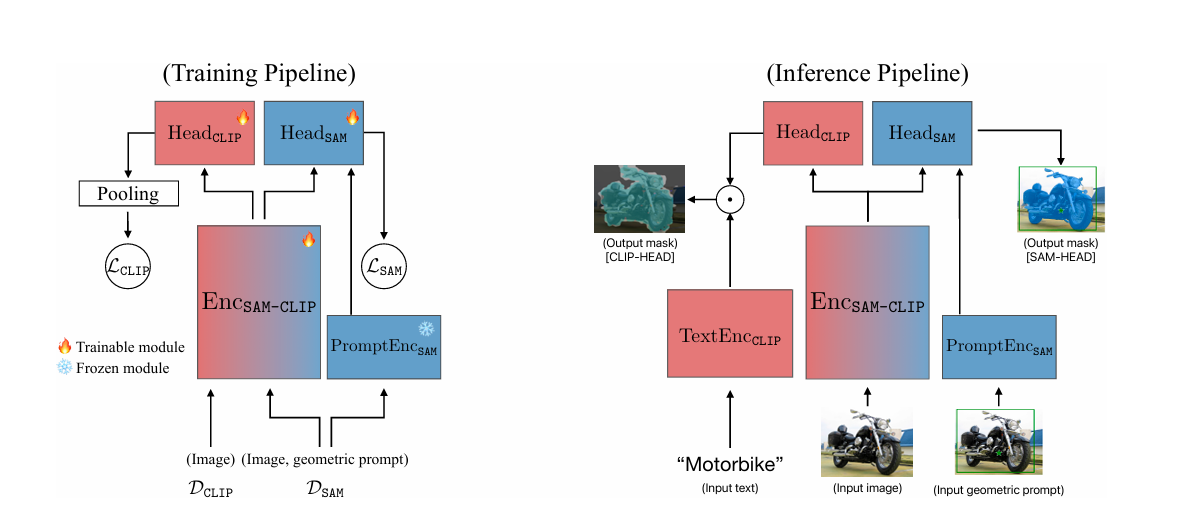
이론적으론 CLIP을 basic VFM으로 시작하고 SAM의 지식을 병합할 수도 있지만, 기존의 사전 학습된 CLIP의 ViT 모델은 SAM 학습에 사용되는 고해상도 이미지를 다루는 데 비효율적이므로, SAM을 base model로 선택하고 고해상도 input을 효율적으로 처리 가능한 ViT-Det 구조를 사용하기로 하였다.
이 때 basic VFM과 auxiliary VFM을 훈련하는 데 사용된 데이터 셋의 제한된 일부정도는 접근 가능하다고 가정하여, 이를 통해 continual learning setup에서의 memory replay function 역할을 한다. 이를 각각 과 으로 표기하고, 해당 데이터 셋의 자세한 설정은 4.1절에서 자세히 설명한다.
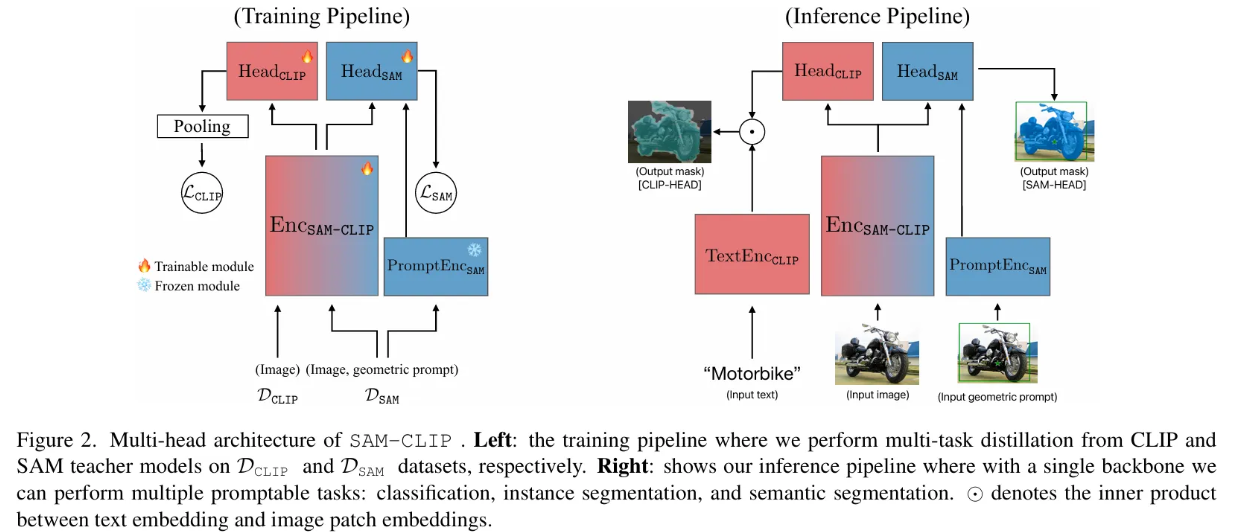
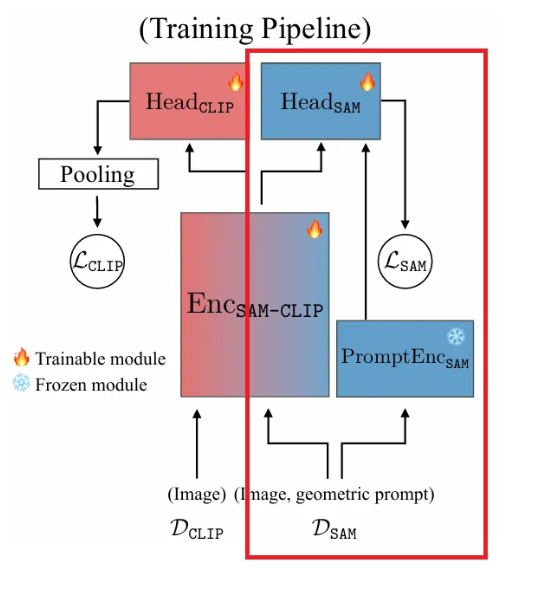
위 그림과 같이 multi-head architecture를 사용하며, 아래와 같은 특징을 가진다.
- Basic VFM인 SAM은 image encoder인 , prompt encoder인 , mask decoder인 을 가진다.
- Auxiliary VFM인 CLIP은 image encoder인 , text encoder인 을 가진다.
- 위 두 개의 image encoder를 합쳐서 하나의 backbone인 을 만드는데, 이는 초기엔 으로 초기화된다.
- 각 VFM에 대응하는 경량화된 head인 과 를 갖는다.
- 이 때 은 으로 초기화되고, 은 랜덤 weights로 초기화된다.
- 다른 modality encoder인 과 은 얼린 채로 사용된다.
병합 방식을 더 자세히 살펴보자.
Baseline 병합 접근법으로, cosine distillation loss를 사용하여 에 대한 knowledge distillation을 수행한다.
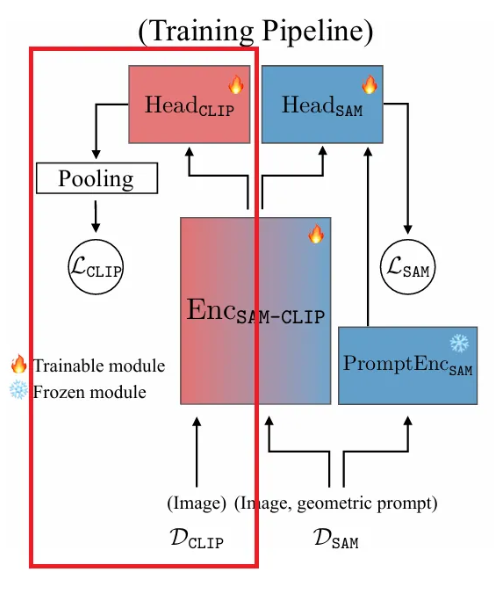
- 에 데이터 를 input으로 넣어서 인코딩 진행
- 에 를 input으로 넣은 후 그 출력을 의 input으로
- step 2의 결과를 spatial pooling인 거친후 step 1 결과와 행렬 곱한 후, 1에서 뺀 값이 loss
- 각 에 대한 step 3 결과를 평균
위 설정에서 과 의 파라미터는 learnable 하지만, 은 동결되어 teacher model 역할을 한다. 위 과정은 SAM에 CLIP의 의미적 능력(semantic abilities)을 주입하지만, SAM의 기존 능력을 잊어버리게 된다. 이를 해결하기 위해, rehearsal 기반의 multi-task distillation을 제안하게 되는데, 이는 두 가지 주된 목표를 갖는다.
- Auxiliary VFM(CLIP)에서 base VFM(SAM)으로의 효율적인 지식 전달을 촉진
- base VFM(SAM)의 기존 능력을 보존
이에 따라 head-probing과 multi-task distlillation이라는 two-stage training을 고려하게 된다.
만약 여러 개의 Head가 서로 다른 다양한 해상도에서 학습되는 경우, resolution adaptation이라는 선택정인 단계를 추가할 수도 있다. Resolution adaptation은 4.1절에서 자세히 다룰 예정.
-
Head Probing
- 이 단계에서는 먼저 image backbone인 을 동결 상태로 유지하고, 위에서 본 loss을 사용하여 만 학습한다. 이는 을 변경하기 전(까먹을 위험이 있는 상태에서), 랜덤 초기화된 에 대해 합리적인 값을 먼저 학습할 수 있도록 한다.
-
Multi-task distillation
- 각각의 head (, ) 뿐 아니라, 단일 image encoder 또한 학습 가능하게 설정하고, 이후 아래와 같은 multi-task 학습을 수행한다.
여기서 는 위에서 살펴본 바 있고, 은 아래와 같이 설정된다.
- 의 input 에 대해서 와 을 거쳐 얻은 segmentation mask 를 얻음 (이 자체가 teacher model이 돼서, self-distillation이라고 하는 듯)
- 에 넣어서 인코딩 된 기하학적 프롬프트와, 에 넣어서 인코딩 된 input 를 함께 (원래 SAM의 mask decoder에서 초기화됨) 에 넣어서 예측된 segmentation mask를 얻음
- step 1, step 2에서 구한 각각의 segmentation mask끼리 focal loss와 dice loss의 선형 결합으로 이루어진 loss인 를 구함
- step 3에서 얻은 loss를 각각의 샘플에 대하여 평균
이 때, , 샘플은 각각 해당하는 , 에만 기여하게 되고, forgetting 문제를 최소화하기 위해 과 의 learning rate는 보다 훨씬 작은 값으로 설정한다.
다시 한번 학습 파이프라인을 큰 순서로 정리하자면,
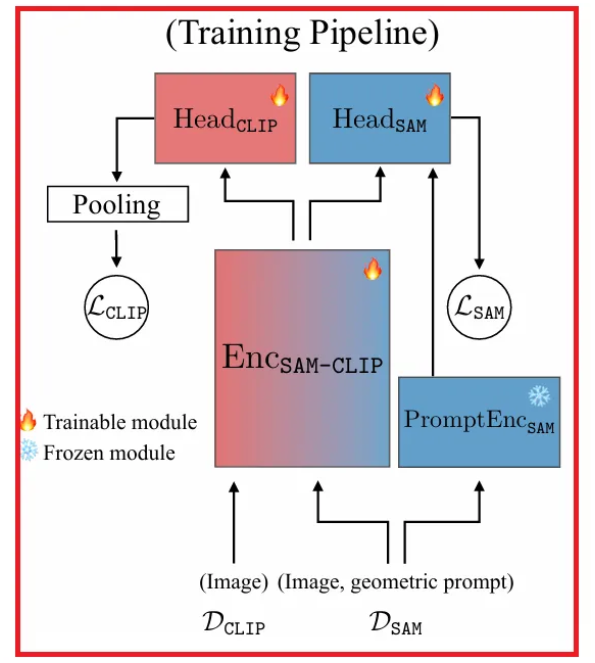
- 의 일부 샘플을 활용하여 은 얼린 뒤 을 최소화하도록 을 학습한다.
- 이 어느 정도 학습이 되었다면, 이젠 를 learnable하도록 수정한다.
- 의 일부 샘플을 input으로 하여 다시 한 번 을 구하고,
- 그 옆에서는 의 일부 샘플 및 geometric prompt를 각각 과 에 넣어 을 구한 후,
- 를 최소화하도록 학습한다.
4. Experiments
4.1. Implementation Details
구현에 있어서, CLIP으로부터 zero-shot classification 능력을 배움과 동시에, SAM의 instance segmentation 능력을 최대한 보존하는 trade-off를 밸런싱하는 것에 초점을 두었다.
Model Architecture
SAM은 ViT-B/16 버전을 base architecture로 사용하되, CLIP의 기능을 통합하기 위해 backbone에 3개의 Transfomer layer로 이루어진 경량 CLIP head를 추가한다.
이러한 CLIP head로부터 얻은 patch token은 pooling layer를 거쳐 image level의 embedding을 생성하게 되는데, 이는 ViT에서 CLS token output과 유사한 역할을 한다.
Max pooling을 쓰는 이유는, average pooling보다 zero-shot classification 및 semantic segmentation 성능을 향상시키는 데 효과적이고, max pooling이 공간적, 시간적 특징의 학습을 촉진하는 데 유리하다는 연구 결과를 반영한다.
Dataset Preparation
- CLIP 지식을 distillation 하기 위해, CC3M, CC12M, YFCC-15M, YFCC-100M의 subset, ImageNet-21K 데이터를 합쳐 총 4,060만 개의 label이 없는 이미지로 구성된 을 생성
- SAM의 self-distillation을 위해 기존 1,100만 개의 이미지와 11억 개의 마스크로 이루어진 SA-1B 데이터 셋의 5.7%를 샘플링하여 을 구성
- Validation set은 과 에서 1%를 랜덤으로 선택하여 구성
이를 통해 총 4,080만 개의 이미지로 구성된 train set을 구축하고, 이를 Merged-41M으로 명명
Training
학습은 계속 언급했 듯 “Probing” 후 “full fine-tuning” 방식.
- 학습에서 가장 처음 단계인 probing은 앞서 언급했든 backbone()은 얼린 상태에서 으로 20 epoch동안 이루어진다.
- 이 때 teacher model은 DataComp-1B dataset으로 학습된 OpenCLIP ViT-L/14 모델이다.
- 두 번째 multi-task distillation 때는 을 learnable하게 unfreezing 한 후, 및 과 함께 joint fine-tuning을 수행한다.
- 이 때 에서 둘의 비율은 1:10으로 설정된다().
- 여기서 의 teacher model은 기존 SAM ViT-B 모델이다.
- CLIP distillation 시에는 224px 및 448px 해상도 사용
- SAM distillation 시에는 1024px 해상도 유지
- 각 최적화 단계에서는 에서 2048개 이미지를 샘플링하고, 에서 32개 이미지와 각 이미지 당 32개 마스크 주석을 샘플링하고, 이를 결합하여 학습 진행
Resolution Adaptation
앞선 두 단계의 훈련을 거친 후, SAM-CLIP은 으로 224/336/448 px에서 zero-shot classification 등의 CLIP 작업 수행이 가능하고, 으로 1024px에서 inference가 가능하다. 하지만 만약 특정 task에서 두 개의 head를 단일 input image에 함께 적용해야 할 때, 두 헤드 각각에 대해서 같은 이미지를 서로 다른 해상도로 encoder에 두 번 입력하는 것은 비효율적이다.
이를 위해서 를 얼린 후, 1024px 이미지를 input으로 넣어 만 loss를 사용하여 3 epoch동안 fine-tuning을 진행하는 adaptation을 추가로 진행한다.
→ 마지막으로 input image를 1024px로 바꿔서 head probing을 적은 epoch으로 한 번 더 수행한다고 보면 된다.
더 자세한 사항은 appendix를 참고하면 자세히 나와있다.
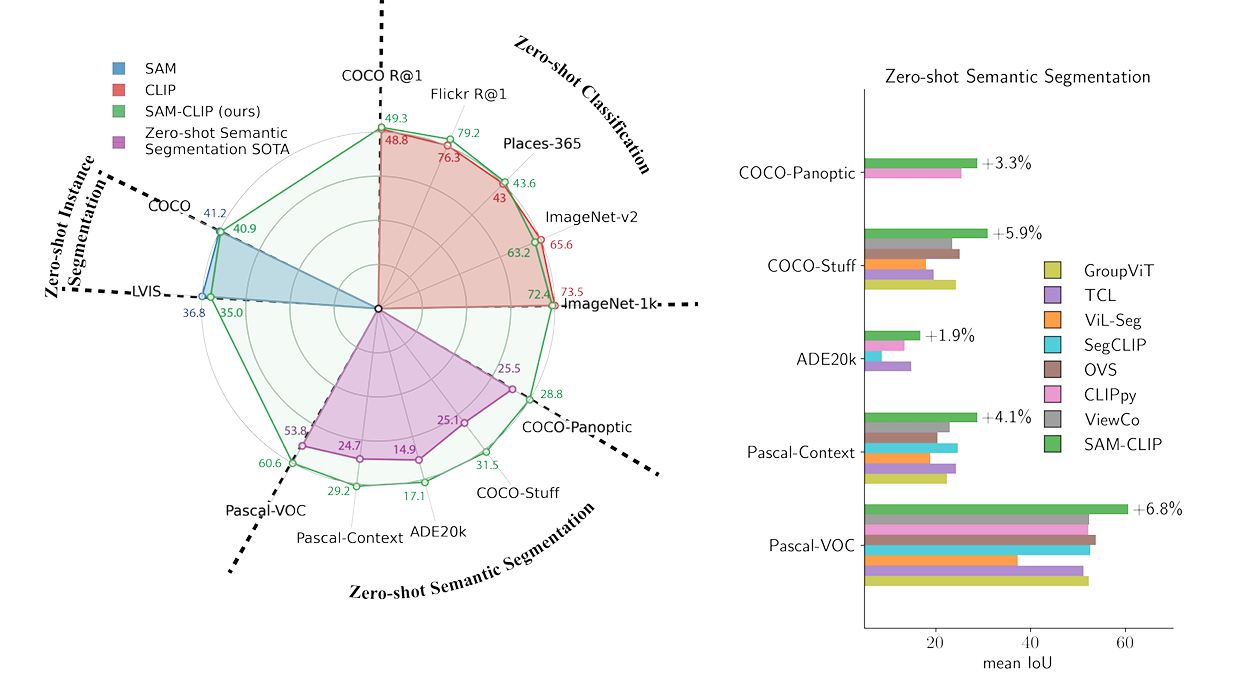
4.2. Zero-Shot Evaluations
CLIP Tasks: Zero-shot Image Classification & Text-to-Image Retrieval
SAM-CLIP의 CLIP 관련 기능을 평가하기 위해 zero shot classificaiton과 zero shot text-to-image retrieval 실험을 진행하였다.
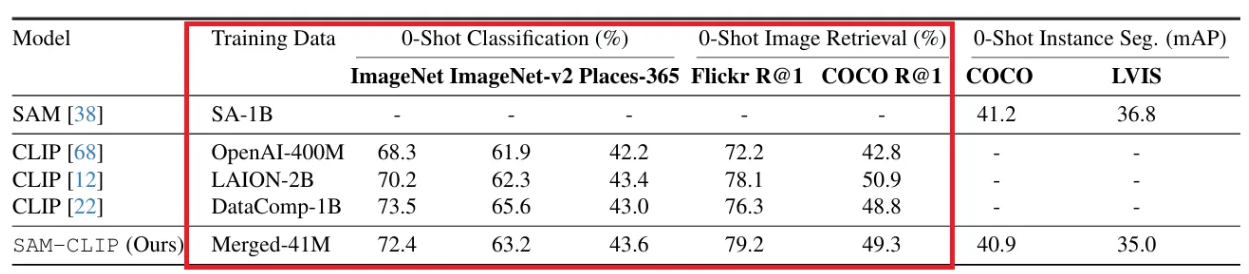
- LAION-2B와 DataComp-1B로 사전 학습된 CLIP ViT-B 모델들과 비교하여 SAM-CLIP 정확도는 유사하게 나타났고, 이는 본 논문의 결합 방식이 CLIP의 zero shot classification 능력을 잘 이어받음을 보여준다.
- Text-to-image retrieval task에서도 사전 학습된 CLIP ViT-B 모델들과 비교하여 유사하거나 더 나은 성능을 보여주고 있다.
SAM Task: Zero-shot Instance Segmentation
COCO 및 LVIS 데이터셋에서 zero-shot instance segmentation 성능을 평가하였다. 기존 SAM의 방식에 따라, 먼저 ViT-Det 모델로 bounding boxes를 얻고, 이를 SAM의 geometric prompt로 활용하여 이후 각 instance에 대한 마스크를 얻는 방식으로 진행하였다.
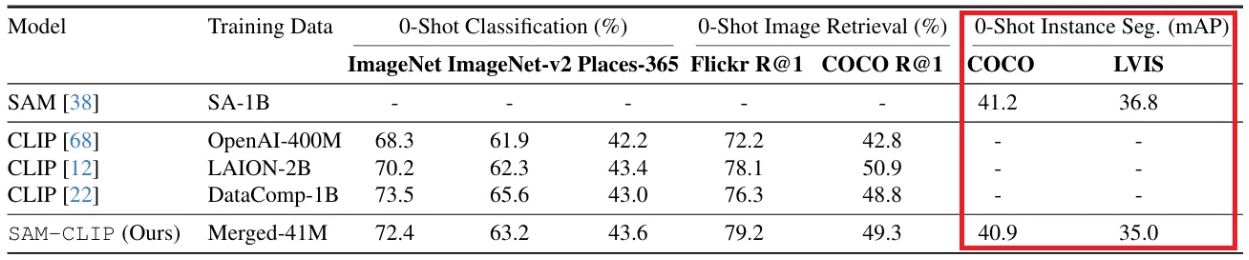
위 표에서 확인 가능하듯, 두 벤치마크 데이터셋에서 원본 SAM과 어느정도 유사한 성능을 보여주었고, 이는 catastrophic forgetting이 발생하지 않았음을 보여준다.
Zero-Shot Transfer to Semantic Segmentation
5개 데이터셋에 대해서 zero-shot semantic segmentation을 진행하였는데, 여기서 프롬프트는 텍스트가 활용되었다.
순서는 아래와 같은 evaluation protocol을 진행하였다.
- 각 이미지 사이즈를 448x448 크기로 resize하여 SAM-CLIP의 image encoder와 에 전달하여 28x28 크기의 patch features를 얻는다.
- OpenAI에서 미리 정의한 80개의 CLIP text template을 활용하여 각 semantic class에 대한 text embedding을 생성. 이러한 embedding은 mask prediction classifiers로써 작동하고, 에서 추출된 patch features에 적용된다.
- Input image와 차원을 맞추기 위해 mask prediction logits를 선형적으로 upscaling한다.
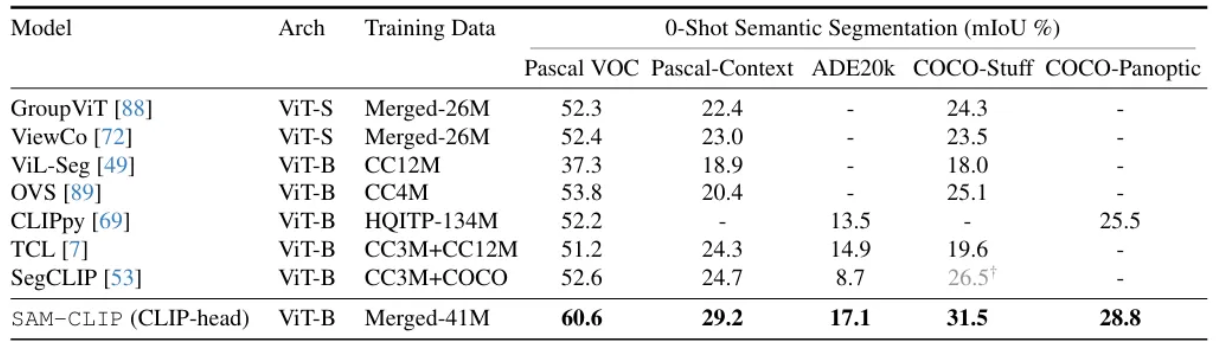
이 결과 SAM-CLIP이 모든 데이터셋에서 새로운 SOTA를 달성했고, 기존 연구 대비 상당한 성능 향상을 보여주었다.
4.3. Head-Probing Evaluations on Learned Representations
저자들은 segmentation task에 필요한 low-level spatial visual details를 포착하는 데 뛰어난 SAM의 강점과, 전체 이미지를 포괄하는 high-level semantic visual information을 전문적으로 처리하는 CLIP의 강점을 합한다면 다양한 후속 vision tasks에서의 활용성이 향상될 것이라는 가설을 세운다.
이러한 가설을 검증하기 위해 SAM, CLIP, SAM-CLIP에 대해 image backbone을 고정한 상태에서 head만 학습하는 head-probing을 수행하였다.

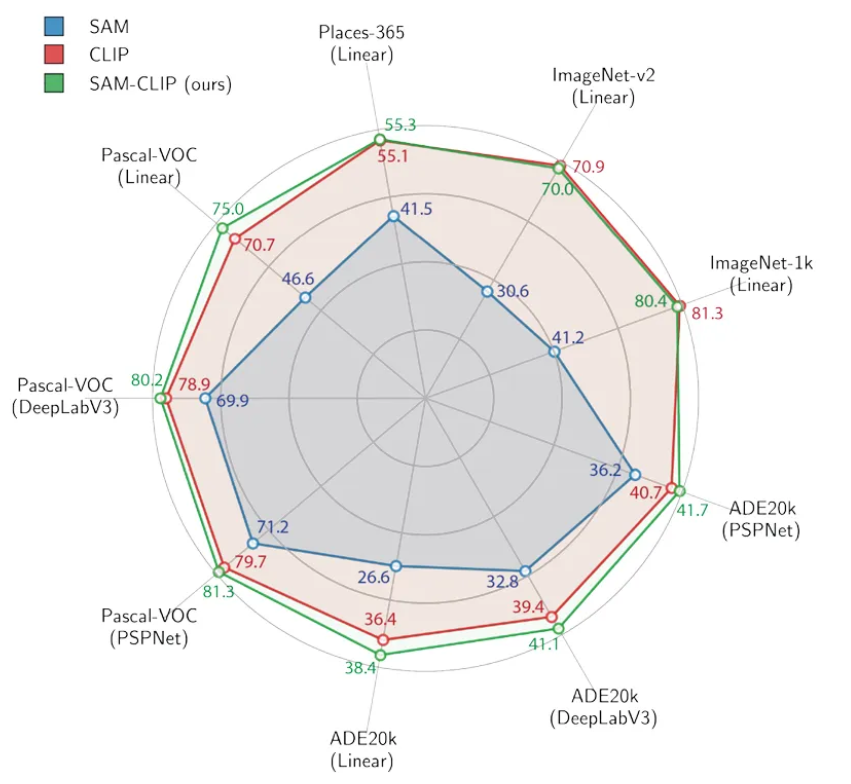
Pascal VOC, ADE20k라는 두 개의 semantic segmentation 데이터셋을 대상으로 다양한 segmentation head structure(linear head, DeepLab-v3, PSPNet)를 활용하여 실험 진행한 결과, SAM의 표현 학습이 semantic understanding이 필요한 작업 뿐 아니라, semantic segmentation에서도 CLIP만큼 효과적이지 못하다는 것을 확인 가능하지만, SAM-CLIP은 다양한 head 구조와 데이터셋에서 SAM과 CLIP 모두를 능가하였다.

그리고 이러한 모델들에 대하여 두 개의 image classification datasets에 대한 추가적인 Linear Probing을 진행한 후 시각화한 그림 및 표이다. SAM-CLIP은 CLIP과 유사한 성능을 보여주는데, 이는 SAM-CLIP의 image-level 표현 학습이 잘 이루어졌음을 시사한다.
4.4. Comparing Both CLIP and SAM Heads for Better Segmentation
SAM-CLIP이 SAM과 CLIP head를 갖춘 multitask model이라는 점을 고려하여, 두 head를 간단하게 조합하여 zero-shot semantic segmentation 성능을 향상하고자 한 실험을 진행하였다.
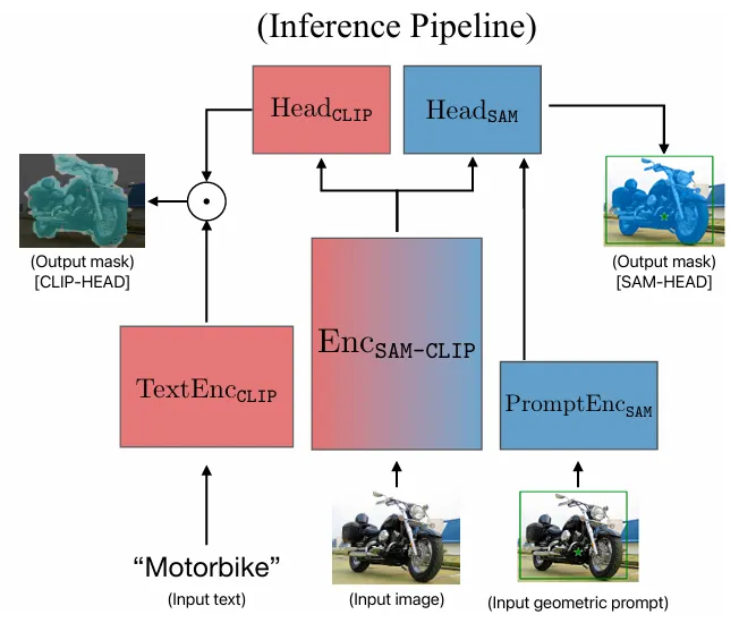
실험 파이프라인은 아래 순서와 같다.
- Input image를 1024px로 리사이즈한 후 을 통과시키고, 을 사용하여 text prompt 기반 32x32의 저해상도 mask prediction을 생성한다.
- Step 1에서 얻은 mask prediction을 기반으로 importance sampling을 적용하여 일부 point prompts만 뽑아낸다.
- Step 1,2에서 얻은 mask prediction 및 point prompts를 geometric prompts로써 다시 한 번 에 전달한다.
- 은 및 의 embedding을 받아서 256x256의 고해상도 mask prediction을 생성한다.
아래 한 샘플을 예시로 보면, 을 통해 (c)를 얻고, 이 prediction mask에서 얻은 point prompts들을, 혹은 이 prediction mask 자체를 gemetric prompt로 활용하여 더 조정된 결과인 (d)를 얻게된다.


이러한 고해상도 파이프라인을 통해서 zero-shot semantic segmentation 성능이 추가적으로 향상될 수 있음을 보여준다.
