[논문 리뷰] ReConPatch : Contrastive Patch Representation Learning for Industrial Anomaly Detection (WACV2024)
논문리뷰
https://arxiv.org/abs/2305.16713
1. Introduction
산업 제조에서 이상 탐지는 제품 결함을 식별하고 품질 유지에 핵심적인 역할을 하고, 자동화의 수요가 증가함에 따라 머신러닝 접근법이 널리 연구됨.
이에 따라 이전에 수집된 데이터를 기반으로 정상 케이스와 비정상 케이스를 구별하도록 학습하나, 실제 환경에서 이상 데이터가 정상 데이터보다 훨씬 적기에 제대로 학습되기엔 쉽지 않음.
대조 학습 기반 학습 방식에서 nominal instances에서 variation을 모델링하기에 취약하다는 점을 극복하고자 저자들이 제안하는 ReConPatch는 모델에서 얻은 feature 간의 contextual similarity를 pseudo-label로써 활용한다.
2. Related Work
One-class classification
SVDD는 신경망을 학습시켜 각 데이터를 hyperspherical embedding에 mapping하고, 초구면 중심으로부터 거리를 측정하여 이상 탐지를 수행한다.
Reconstruction-based
정상 데이터는 명목 데이터셋을 사용하여 학습된 모델에 의해 정확하게 재구성 될 수 있지만, 비정상 데이터는 그렇지 않음을 가정하여 재구성 오차에 따라 이상 탐지를 수행한다.
Memory bank
SPADE는 Hierarchical sub-image features를 비교하여 이상을 localizing 하였다.
Normalizing flow
Pretrained feature distribution과 잘 정의된 nominal data의 분포 사이 bijective mapping을 학습하는 데 유용하며, CFLOW-AD는 positional encoding을 사용한 condition normalizing flow를 제안하고, PatchCore는 locally aware patch feature와 efficient greedy subsampling 방법을 제안하여 core set을 정의한다.
3. Method
본 논문에서 제안하는 ReConPatch는 nominal image patches에서 추출된 특징을 mapping하는 representation space를 학습하는 데 초점을 맞추며, 비슷한 nominal 특성을 공유하는 경우 unsupervised learning 방식으로 특징들이 서로 가깝게 그룹화 되도록 한다.
저자들이 제안하는 접근법의 주요 개념은 정상 샘플의 variation에 따라 patch features의 분포를 퍼뜨리고, 유사한 특징들을 모으는 target-oriented features를 학습 시키는 것이다.
3.1. Overall structure
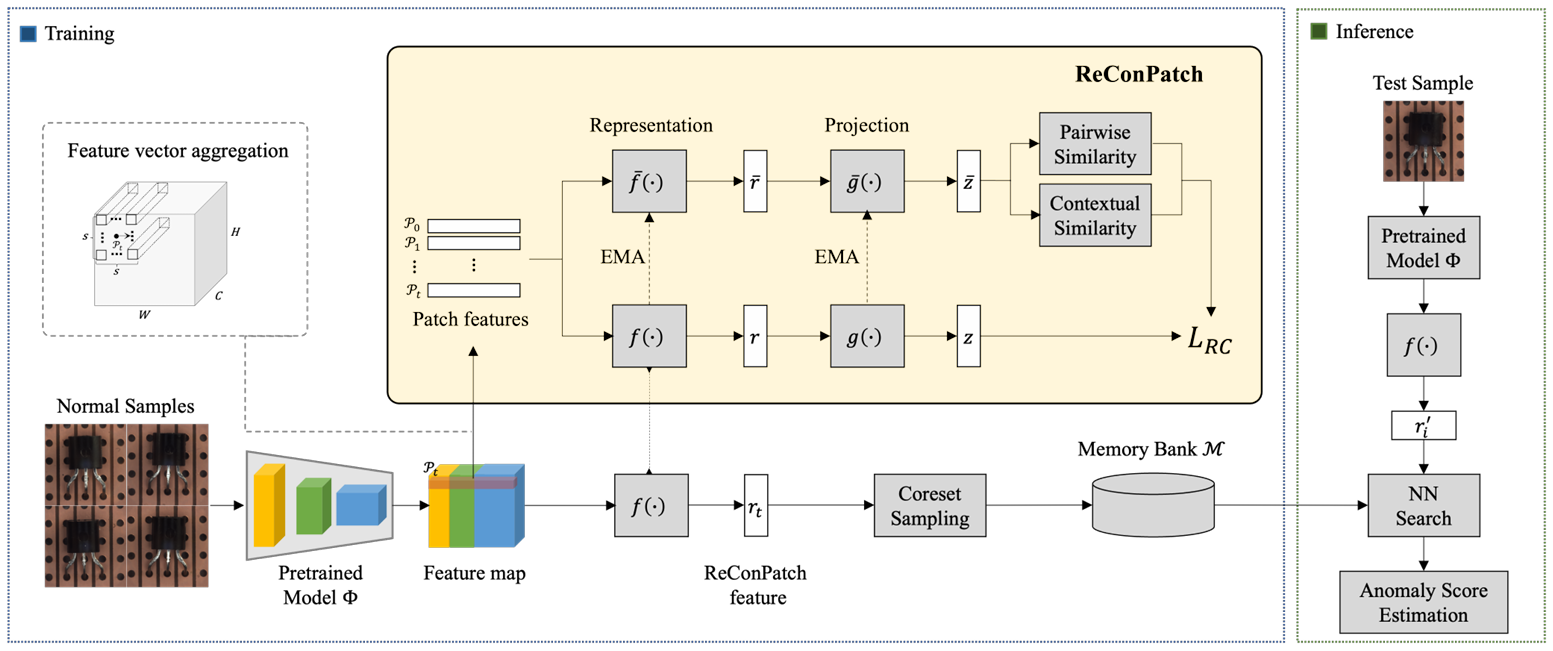
Framework는 training phase와 inference phase로 구성된다.
Training phase
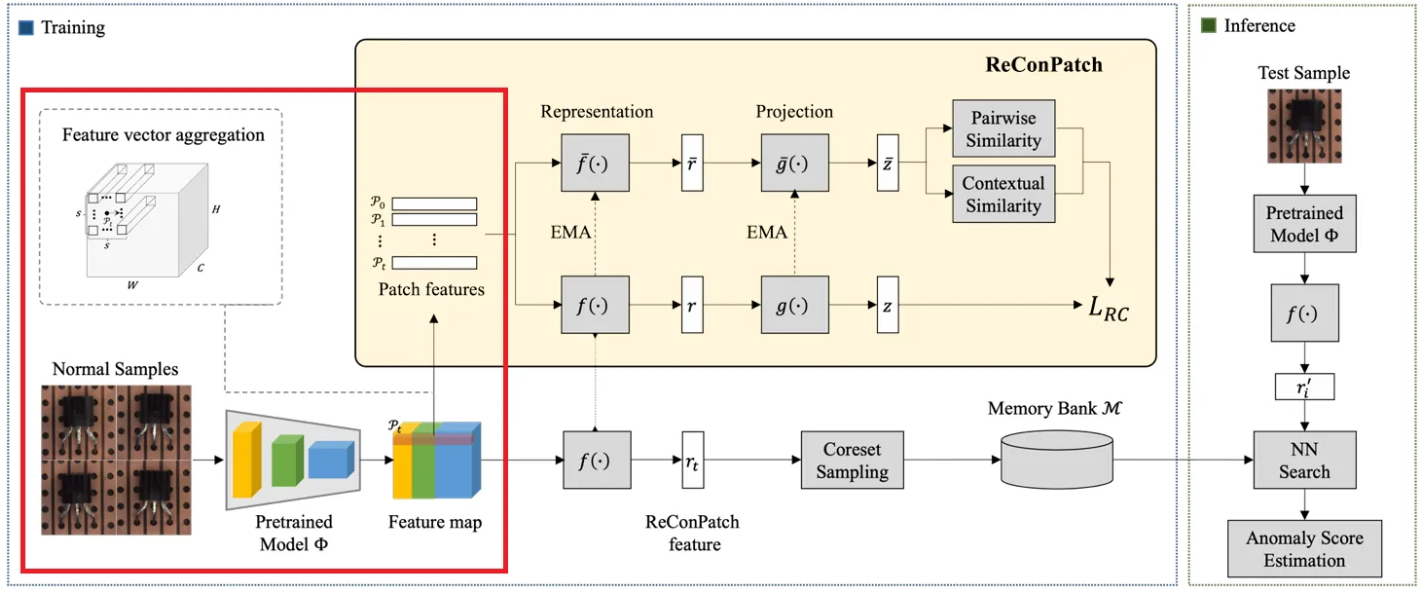
먼저 pretrained model 를 사용하여 layer 에서 feature map을 얻은 후 interpolation을 통해 동일한 해상도로 맞춘 후 특정 patch size 내에서 neighborhood의 feature vector를 집계하여 patch-level features 를 생성한다. 이 때 local aggregation에는 max pooling이 사용된다.
이후 patch-level features의 representation을 학습시키기 위해 두 개의 네트워크를 활용한다.
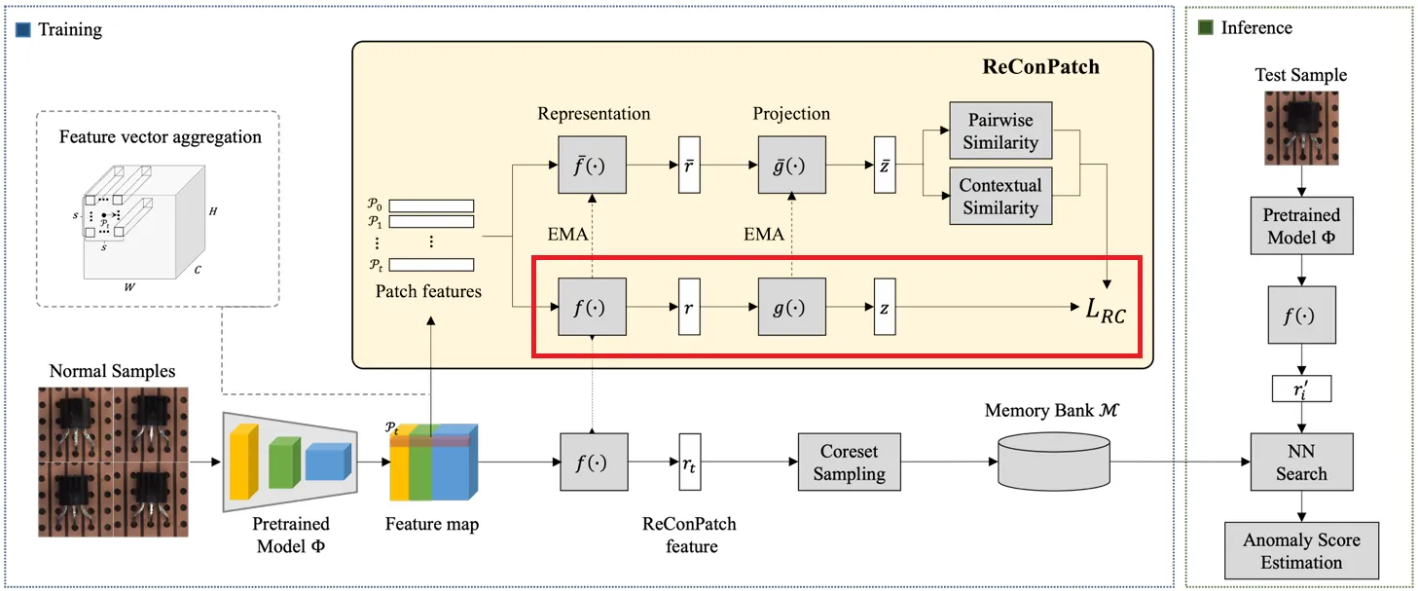
첫 번째 네트워크는 patch-level feature representation learning을 위한 네트워크로, 뒤에서 자세히 설명할 relaxed contrastive loss 를 통해 학습된다. feature representation layer인 와 projection layer인 로 구성되며 를 계산할 때 모든 feature 쌍에 대하여 pseudo labels가 제공돼야 한다.
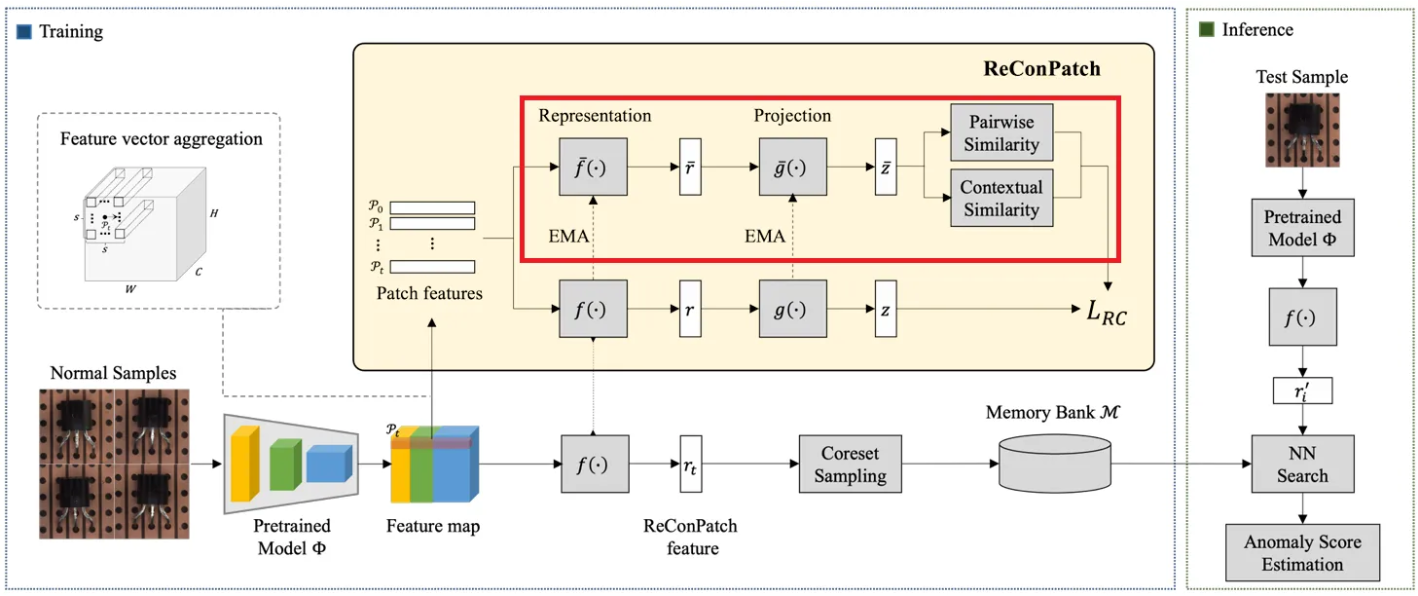
두 번째 네트워크는 patch-level feature 쌍 간의 pairwise와 contextual similarities를 계산하는 데 사용된다. 이는 representation network의 exponential moving average(EMA)에 의해서 점진적으로 업데이트된다. 마찬가지로 representation layer인 와 projection layer인 로 구성된다.
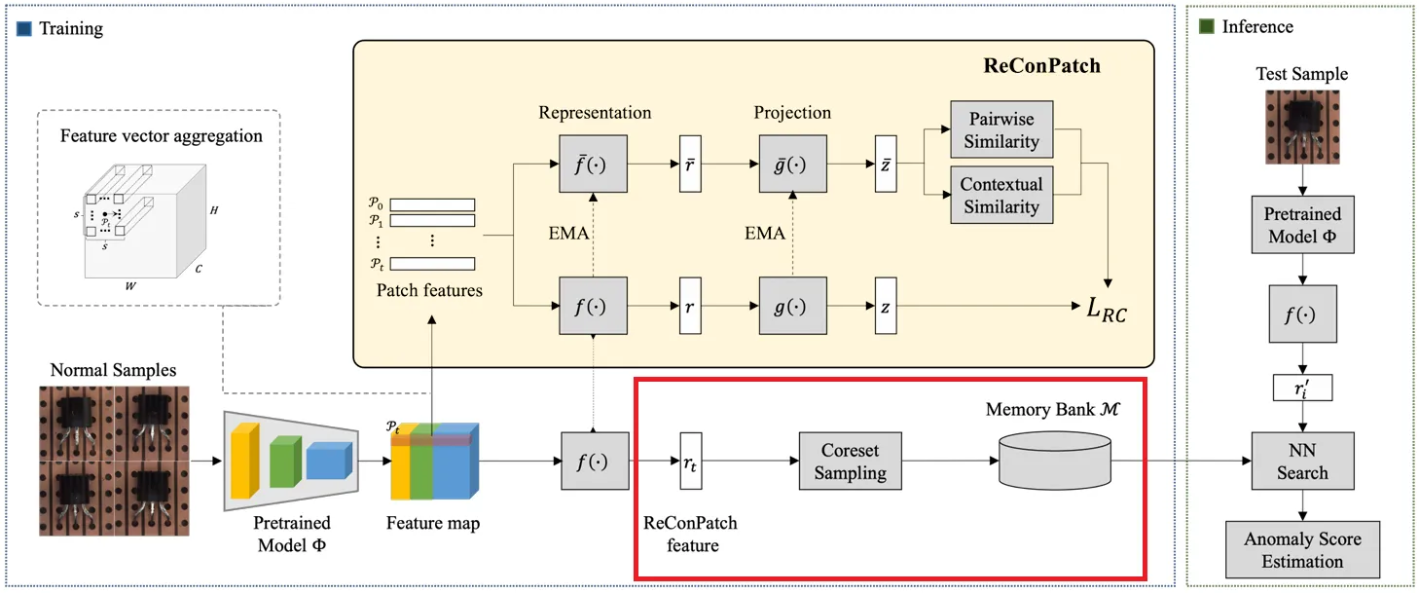
이렇게 feature representation layer 를 거친 patch-level features는 이제 target-oriented features로 변환된다. 이러한 feature들은 greedy approximation algorithm에 기반한 coreset subsampling의 접근법을 통해 선택되어 memory bank 에 저장된다.
Inference phase
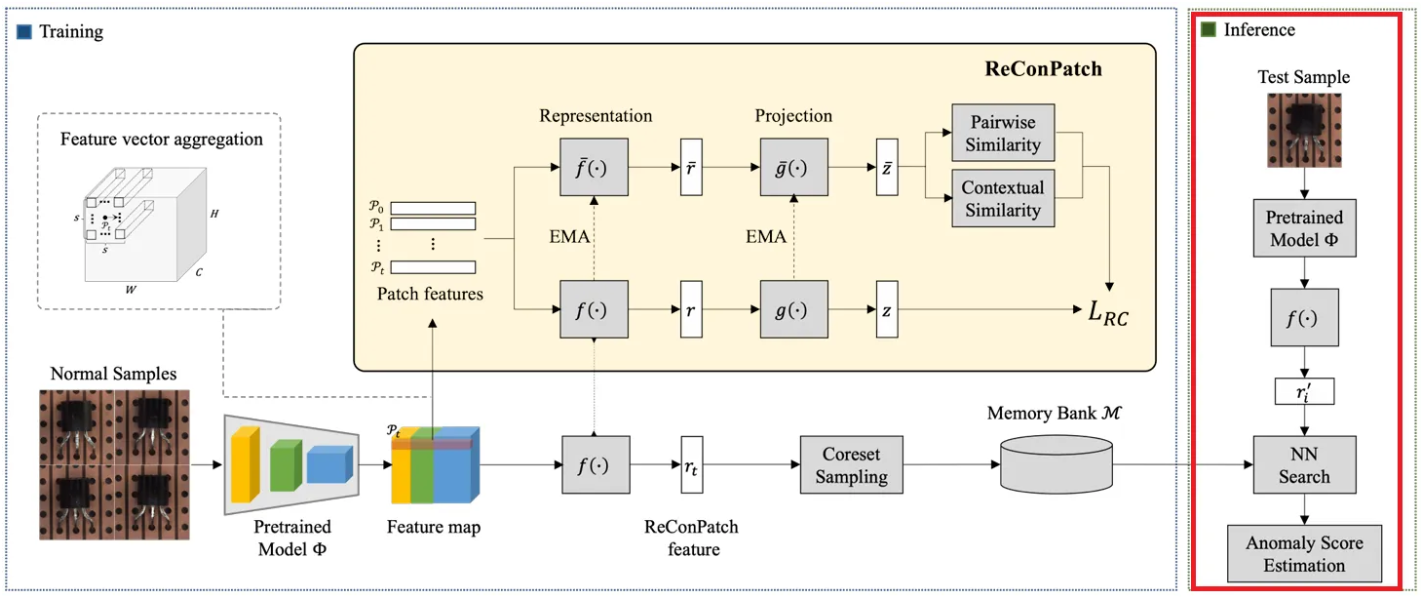
추론 단계에서는 테스트 샘플의 feature를 동일한 과정으로 추출하고, anomaly score는 memory bank에 저장된 정상 표현들과 비교하여 계산된다.
3.2. Patch-level feature representation learning
ReConPatch의 목표는 patch-level의 features에서 target-oriented features를 학습하여 정상과 비정상 특징 간의 더 효과적인 구분을 가능하게 하는 것이다. 이를 위해 patch-level features representation learning 접근법을 적용하여 유사도가 높은 특징들은 모으고, 낮은 특징들은 멀리 떨어뜨린다.
이를 위해 필요한 patch-level features 간 similarity는 pairwise similarity와 contextual similarities를 pseudo-labels로 활용한다. 유사도가 높으면 해당 쌍은 positive로 pseudo labeling되고, 낮다면 negative로 labeling 된다.
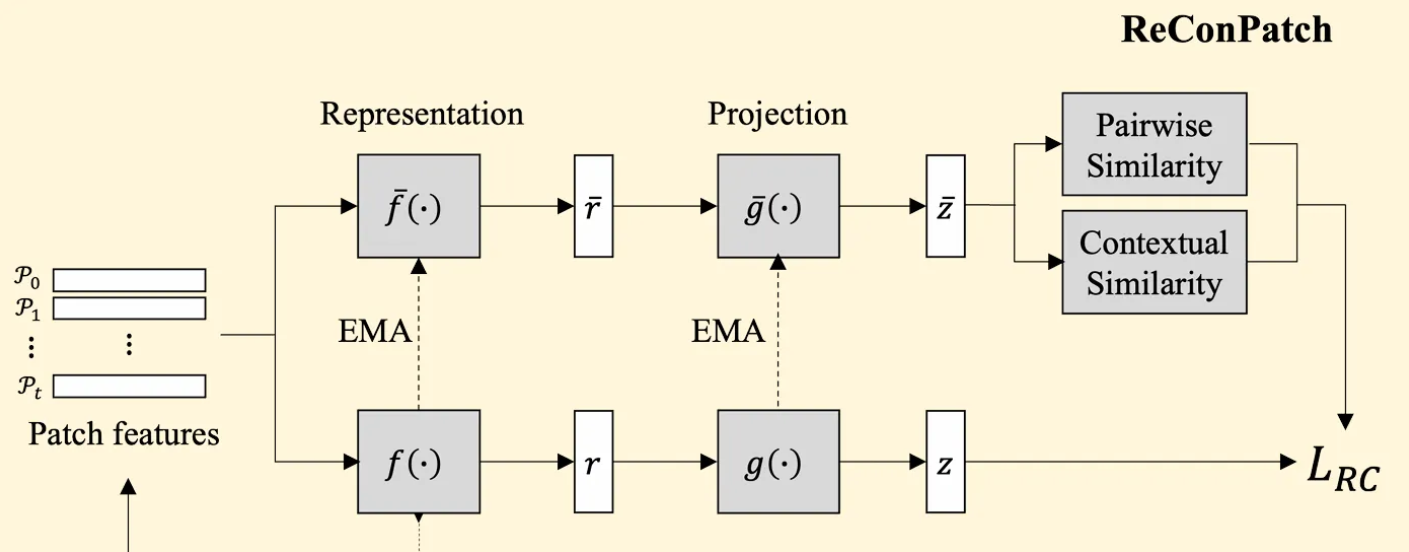
로부터 얻어진 patch-level features인 와 는 각각 projection까지 거쳐서 와 가 되고, 둘의 유사도는 아래와 식과 같이 얻어진다.
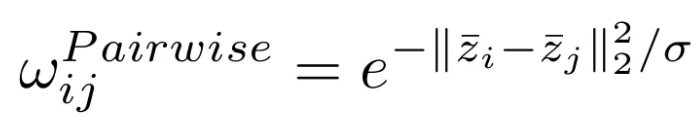
는 gaussian kernel의 bandwidth로, similarity measure에서 smoothing 정도를 조정해준다. 위 식은 anomaly scores를 계산할 때 흔히 사용되는 수식이지만, 이러한 pairwise similarity만으로는 그룹 간의 특징 관계를 고려하기에 충분하지 않다.
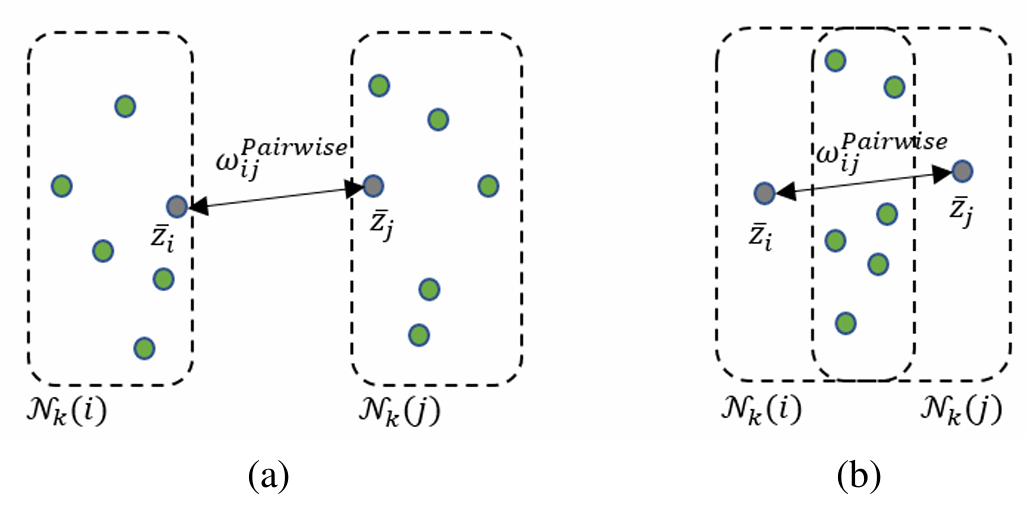
위 그림처럼 (a)와 (b)의 경우 모두 는 같은 값을 갖는다. (a)의 경우에는 와 가 다른 그룹의 feature에 속하므로 분리되어야 하고, (b)의 경우에는 같은 그룹에 속하므로 모아져야 한다.
이로 인해 embedding vector의 neighborhood를 고려한 contextual similarity를 동시에 고려해야 한다. 번째 feature의 k-nearest neighbors는 로 정의되며, 여기서 은 번째 가까운 이웃이고, 는 두 임베딩 사이의 euclidean distance를 의미한다.
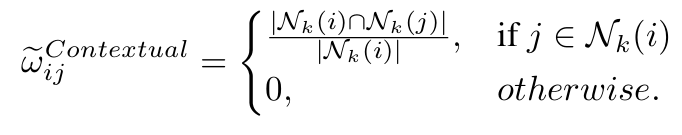
두 개의 patch-level features가 공통으로 더 많은 nearest neighbors를 가진다면 contextually similar하다고 보게 된다.
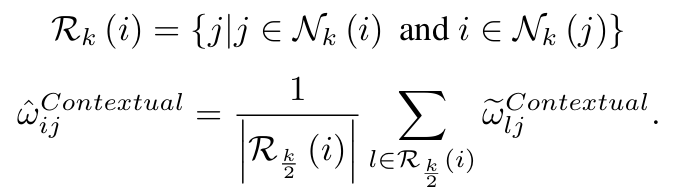
추가로, 정보 검색을 개선하기 위해 널리 사용되는 query expansion의 아이디어를 채택하여 이웃의 이웃으로 확장하여 은 위와 같이 얻어지게 되고,
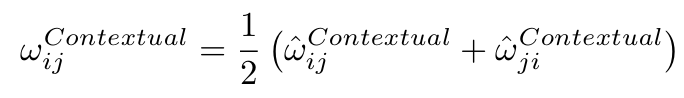
는 비대칭이기 때문에 최종 contextual similarity는 pair의 양방향 유사도의 평균으로 사용하게 된다.
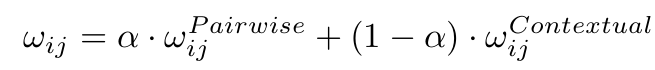
그렇게 두 개의 patch-level features 와 의 최종 similarity는 위와 같이 두 similarity의 선형 결합으로 완성된다.
Target-oriented features를 얻기 위해 inter-feature similarity를 pseudo-labels로 간주하는 relaxed contrastive loss를 채택하였다.
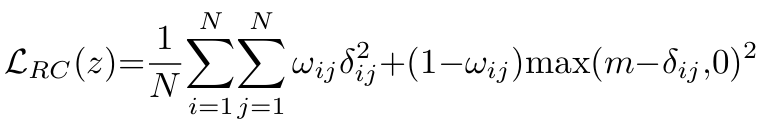
- 는 미니 배치 내 embedding vectors 간 상대 거리를 의미한다.
- 는 에 의해 추론된 embedding vectors
- 은 미니배치 내 인스턴스 수
- 은 repelling margin
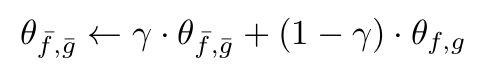
Representation learning networks인 와 가 relaxed contrastive loss로 학습되고, similarity calculation network인 와 는 와 의 파라미터의 EMA를 통해 천천히 업데이트된다. (는 momentum update 비율을 조절하는 하이퍼파라미터)
3.3. Anomaly detection with ReConPatch
학습이 끝난 후, 새로 학습된 feature representation 에서 greedy approximation algorithm을 사용하여 coreset이 샘플링되고, 이를 memory bank 에 저장한다. 이는 representative feature 역할을 하며, anomaly score를 계산하는 데 사용된다.
Pixel-wise anomaly score는 representation layer output인 와, memory bank 내 가장 이웃한 coreset 사이의 거리를 계산하여 얻어진다.
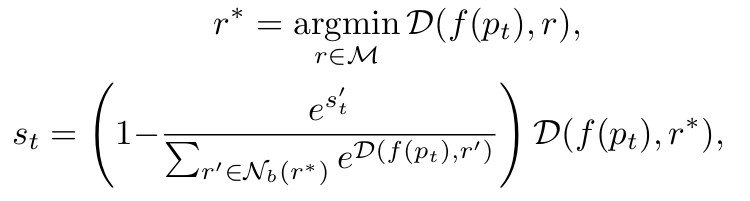
여기서 는 memory bank 내 의 b-nearest neighbors 집합이고, image-wise anomaly score는 이미지 내 모든 patch feature에 대해 계산된 anomaly scores의 최대값으로 계산된다.
이후 anomaly detection의 정확도는 여러 모델로부터의 score-level ensemble을 통해 개선 가능하다. 각 anomaly score는 아래와 같이 modified z-score로 정규화 된다.
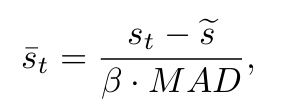
여기서 와 는 각각 anomaly scores의 중앙값과 학습 중 전체 데이터의 mean absolute deviation이다. 는 constant scale factor로, anomaly score가 정규분포를 따른다고 가정할 때 1.4826으로 설정된다.
4. Experiments and analysis
4.1. Experimental setup
Dataset
Industrial anomaly detection benchmark인 MVTec AD와 BTAD로 평가
Metrics
- Detection 성능 평가에는 image-level AUROC를 평가 지표로 활용
- Segmentation 성능 평가에는 pixel-level AUROC를 평가 지표로 활용\
Implementation details
자세한 내용은 본 논문 참고
4.2. Ablation study
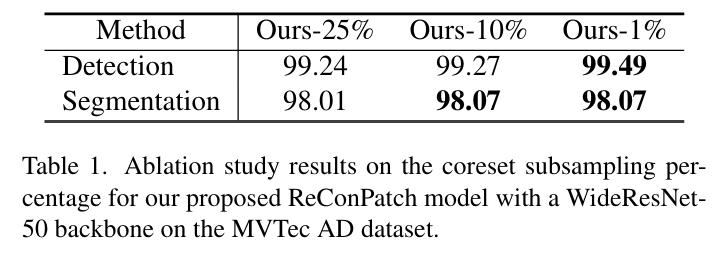
첫 번째로 최적의 coreset subsampling 비율을 결정하기 위한 실험을 수행하였다. 25%, 10%, 1%를 비교했을 때 1%로 설정했을 때 가장 높은 성능을 보여주었다.

두 번째로는 layer의 차원에 따른 결과를 비교하였는데, 512 차원일 때 가장 높은 성능을 보여주었다. 심지어 64차원일 때도 1024차원의 PatchCore보다 좋은 성능을 보여주었다.
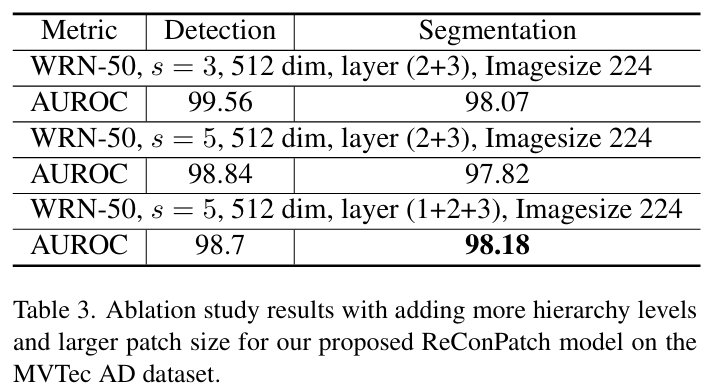
세 번째로, MVTec AD에서 더 많은 hierarchy level과 더 큰 patch size를 적용한 ablation을 수행하였을 때, patch size는 5, hierarchy level은 1,2,3이 사용될 때 segmentation은 가장 좋은 성능을, detection에서는 약간 감소한 성능을 보였다.
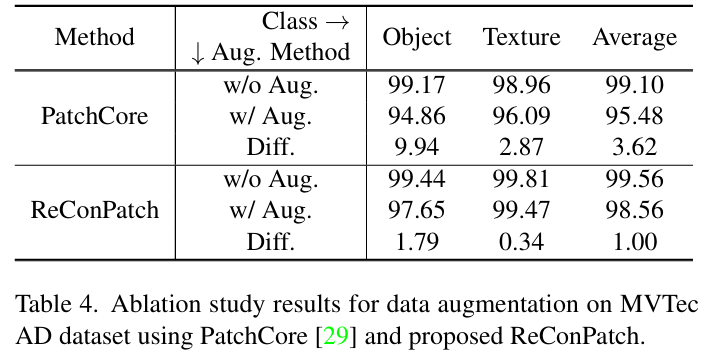
마지막으로 Real-world 시나리오에서는 이미지 품질에 다양한 영향을 미치는 환경 조건이 있기 때문에, rotation, shift, color jitter, gaussian blur 등등의 정확도 및 신뢰성에 악영향을 줄 수 있는 augmentation을 추가하여 실험하였을 때, PatchCore에 비해 성능 하락 폭이 훨씬 작은 것을 확인할 수 있다.
4.3. Anomaly detection on MVTec AD
해당 섹션에서는 MVTec AD 데이터셋에서 제안된 ReConPatch의 anomaly detection 성능을 평가한다.
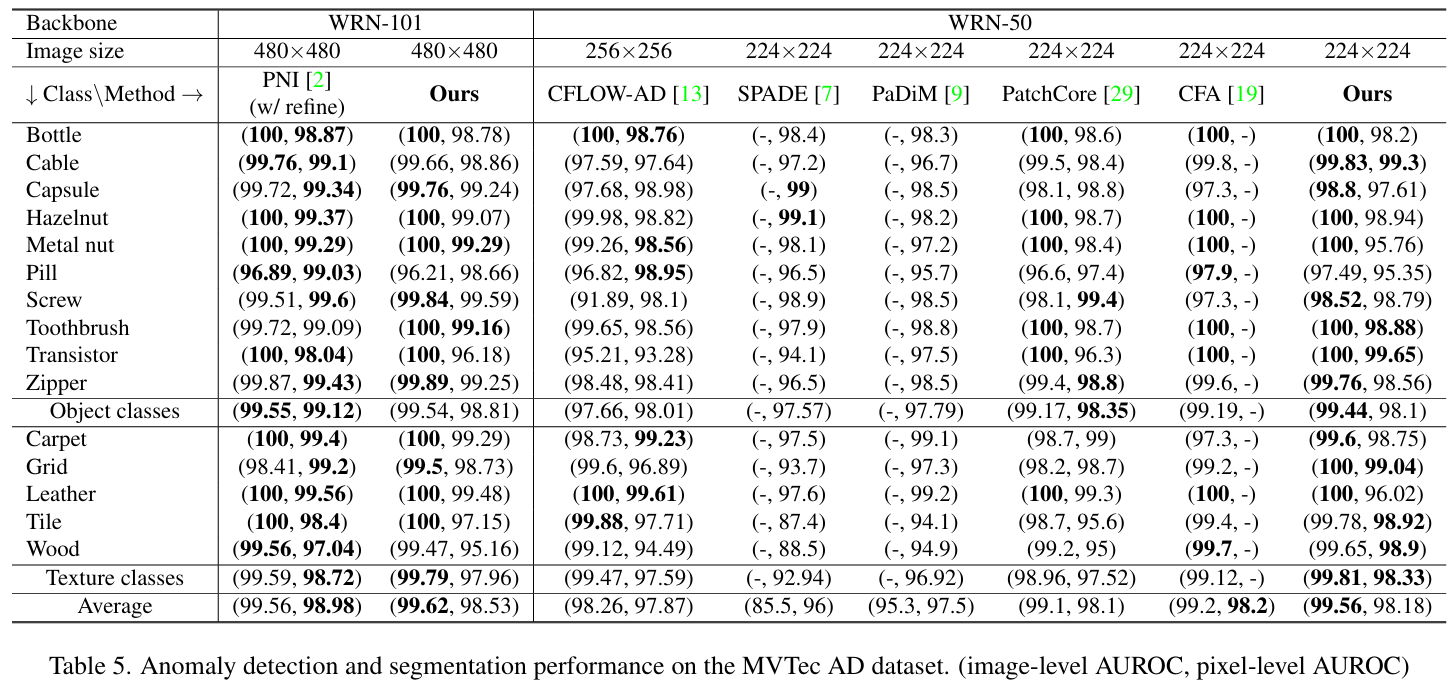
MVTec AD의 각 category에 대한 단일 모델의 detection / segmentation 성능 결과는 위 표와 같다. 제안된 접근법은 anomaly detection 성능을 개선하는 데 초점을 맞추는 데 성공했음을 보인다.
(자세한 세팅은 논문 원문 참고)
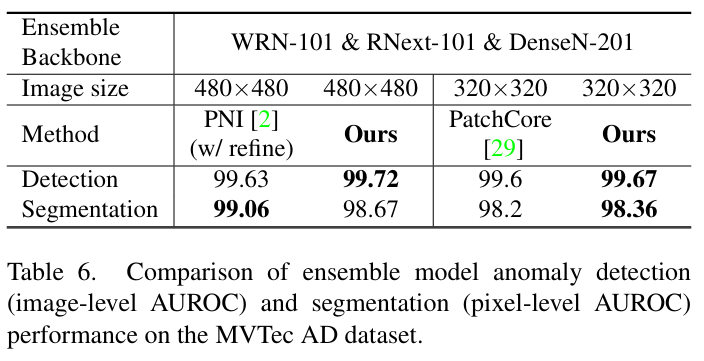
Ensemble의 성능 결과를 타 모델과 비교했을 때 SOTA를 달성하였다.
4.4. Anomaly detection on BTAD
해당 섹션에서는 BTAD 데이터셋에서 제안된 ReConPatch의 anomaly detection 성능을 평가한다.

class 별 평균을 냈을 때, anomaly detection 부문에서는 SOTA를 달성하였고, segmentation은 PatchCore를 능가하는 성능을 보였다.
4.5. Qualitative analysis
본 섹션에서는 ReConPatch의 학습이 feature space에 미치는 영향을 평가하기 위해, MVTec AD 데이터셋으로 PatchCore와 ReConPatch의 feature space를 비교한다.
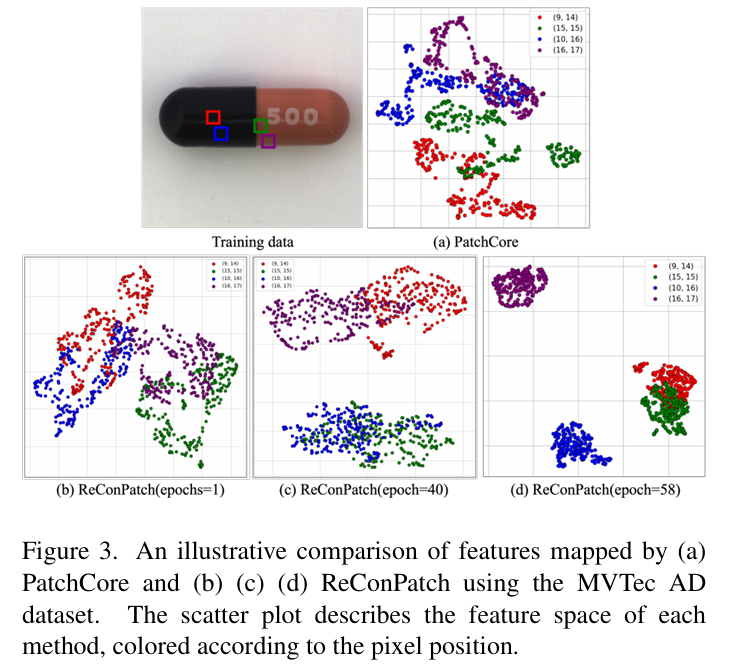
UMAP을 활용하여 2D로 patch features를 시각화 할 때, ReConPatch의 학습이 유사한 위치의 특징들이 가깝게 모이도록 유도함을 보여준다.
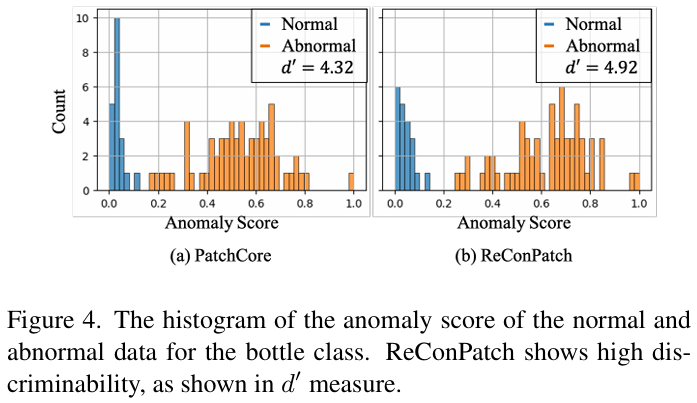
Image-level anomaly scores의 히스토그램을 보았을 때, MVTec AD bottle class에서 ReConPatch는 정상 데이터의 score 분포를 압축하면서 비정상 데이터의 분포를 정상으로부터 더 멀리 분리시키는 것을 확인 가능하다.

Ground Truth와 비교하여 superior class인 cable, transistor, tile, wood와 inferior class인 screw, pill, leather에 대한 Anomaly score maps를 시각화한 그림으로, superior class 뿐 아니라 inferior class에서도 강력한 성능을 보여줌을 확인 가능하다.
Reference
