1. Introduction
-
정형 데이터 셋 모델링의 현황
- 여러 도메인에서 딥러닝은 많은 성공을 거두었으나, 정형 데이터 셋에는 그렇지 못함
- 여전히 GBDT같은 전통적인 머신러닝 기법들이 정형 데이터에서는 우위를 점하고 있음
-
딥러닝을 정형 데이터 셋에 적용하기 어렵게 하는 요인
- Lack of locality
이미지, 텍스트 데이터와는 달리 정형 데이터 셋은 feature 간 locality가 부족하다. 예를 들어, 이미지 데이터는 인근 픽셀 간 시각적으로 유사한 정보를 표함하는 특징이 있지만, 정형 데이터에서는 인근 컬럼 간 관계가 없을 확률이 높다.
- Data sparsity
정형 데이터는 대부분 sparse한 데이터를 포함한다. 예를 들어 cardinality가 10인 범주형 특성을 one-hot encoding 한다면, 열 개의 컬럼 중 하나를 제외하고는 모두 0이 된다. 이는 차원이 증가할 수록 더욱 문제되고, 딥러닝 모델은 이러한 데이터를 효과적으로 처리하기 어려울 수 있다.
- Mixed feature types
정형 데이터는 범주형 변수와 연속형 변수를 포함하며, 딥러닝 모델은 연속형 변수를 다루는 데 적합하여 범주형 데이터 처리에는 추가적인 전처리 과정 필요하며 이러한 과정은 위와 같이 data sparsity 문제가 발생할 수 있다.
- Lack of prior knowledge about data structure
딥러닝은 대량의 데이터와 해당 데이터에 대한 사전 지식이 있는 경우에 효과적인데, 정형 데이터는 데이터 구조에 대한 사전 지식이 부족하여 효과적인 모델 구성을 어렵게 만들 수 있다.
- Black box approach(Lack of transparancy and Interpretability)
정형 데이터의 분석은 종종 모델 예측의 설명을 요구하는 경우가 많은데, 딥러닝 모델은 black box approach를 통해 내부 동작 및 의사 결정 과정이 불투명함.
- Lack of locality
-
딥러닝을 정형 데이터 셋에 적용하기 위한 시도
- TabNet과 같은 GBDT를 능가할 만한 다양한 딥러닝 기법의 활용이 소개됨
-
정형 데이터 셋의 벤치마크 부재
- 이미지 분야의 ImageNet, 텍스트 분야의 GLUE가 있는 것 과는 달리, 정형 데이터에서는 이렇다 할 벤치마크 데이터 셋이 없음
작년에 이러한 한계를 극복하기 위해 벤치마크 데이터 셋을 구축하고자 나온 'Why Do Tree-based Models Still Outperform Deep Learning On Tabular Data?' 라는 논문이 있음
https://arxiv.org/pdf/2207.08815.pdf - 따라서 각 모델이 제안 된 논문에서는 각기 다른 데이터 셋으로 실험 진행됨
- 이런 상황에서 나온 각 결과들은 공정한 실험 결과라고 보기 힘듦
- 이미지 분야의 ImageNet, 텍스트 분야의 GLUE가 있는 것 과는 달리, 정형 데이터에서는 이렇다 할 벤치마크 데이터 셋이 없음
따라서 저자들은 논문의 주 목표를 설정하였다.
-
최근 제안된 딥러닝 모델들이 정말로 정형 데이터 셋에 추천될 만 한가?
- 각 모델들이 제안된 논문의 데이터 셋이 아니어도 정확할 것인가?
- 다른 모델들과 비교하였을 때 training 속도와 hyperparameter searching 시간이 얼마나 걸릴 것인가?
-
공정한 재실험 진행
-
네 개의 딥러닝 모델과 XGBoost를 각각 제안한 논문의 데이터 셋 9개를 포함한 11개의 데이터 셋을 이용하여 분석
-
실험 결과, 각 딥러닝 모델은 다른 데이터 셋에 대해서는 성능이 좋지 않음
-
XGBoost는 대체로 딥러닝 모델들을 능가하였고, hyperparameter searching 시간도 적음
-
-
앙상블 모델 실험
- XGBoost와 딥러닝 모델을 앙상블 한 결과가 딥러닝 모델만 앙상블 한 것과 classial 모델만 앙상블 한 것보다 효과가 좋았음
- No free lunch 이론이 있듯이, 우리가 필요한 건 오직 딥러닝 '뿐'은 아님
2. Background
Related Works
GBDT
- 전통적인 머신러닝 기법으로, 본 논문에서 딥러닝 모델과의 주 비교 대상
- LightGBM, CatBoost, XGBoost 등 다양한 모델이 존재하지만, 성능이 대체로 비슷하다는 점은 검증 됨
- 따라서 XGBoost를 대표로 실험
Differentiable trees
- 기존 트리 앙상블은 미분 불가하여 end-to-end training pipeline에 적용 될 수 없음
- Decision function을 smoothing하는 방식으로 미분 가능하게 만드는 방법이 있음
Attention based models
- 다른 분야에서 널리 쓰이던 Attention-based 모델을 정형 데이터 셋에 맞게 변형
- 최근 연구에서 Inter-sample attention, Intra-sample attention 기법들을 제안
Deep Neural Models for Tabular Data
TabNet
- Encoder 층에서 sparse learned masks를 이용하여 각 행 별로 중요 feature 선택
- Sparsemax 활성화 함수로 encoder는 더 작은 feature 집합 선택 가능
NODE (Neural Oblivious Decision Ensembles)
- 미분 가능한 Oblivious decision trees를 이용해 error gradients가 backpropagation 가능
- 이 때 하나의 ODT는 한 노드에서 한 feature와 그 가중치를 곱한 값을 learned threshold와 비교 후 분기
- 최종적으로 각 ODT의 결과들을 앙상블
DNF-Net
- NODE와 마찬가지로 미분 가능한 tree를 이용
- 여러 개의 의사결정 네트워크를 앙상블하여 예측 수행
1D-CNN
- Kaggle에서 정형 데이터에 best single model performance를 기록한 모델
- CNN 구조가 feature extraction을 잘 수행하는 것에 기반
- 정형 데이터는 feature ordering이 local characteristics를 갖지 않기 때문에 fully connected layer 이용하여 새로운 feature 생성
- Local characteristics를 갖게 된 위 feature을 1D-Conv layers와 사용
Model Ensemble
- 앞서 소개한 다섯 모델을 앙상블에 이용
- 데이터가 많을수록 보통 좋은 성능을 내기 때문에, 각 모델은 전체 훈련 데이터 셋 이용
Uniformly weighted mixture model
- 앙상블 할 모든 모델들의 가중치를 동등하게 주는 것
Weighted average model
- 앙상블 할 각 모델들 마다 normalized validation loss를 토대로 weight를 다르게 부여하는 것
3. Comparing the Models
실험 과정
- 다양한 데이터 셋에서의 딥러닝 모델들, XGBoost, 그리고 여러 앙상블들의 성능 평가
- 앙상블의 다양한 구성 요소를 분석, 어떤 모델을 선택할 지 연구
- 좋은 결과에 딥러닝 모델이 필수적인지, classical model들을 결합하는 것이 충분한 지 테스트
- 정확도와 계산 자원 요구 사항 간의 tradeoff를 탐구
- 모델 별 hyperparameter tuning 과정을 서로 비교
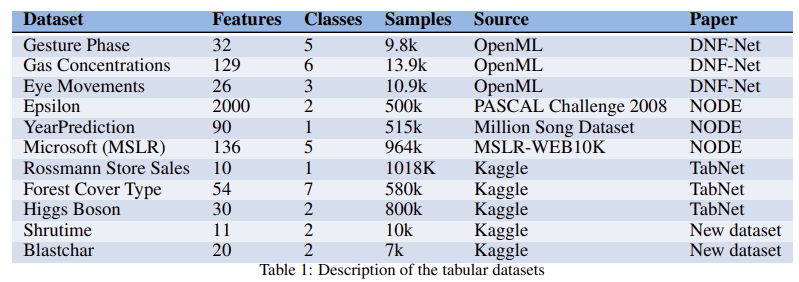
Data-sets Description
- DNF-Net, NODE, TabNet 논문에서 실험에 쓰인 9가지 데이터 셋 + 2가지 새로운 데이터 셋
- 1D-CNN이 best performance를 기록한 한 가지 데이터 셋은 사용하지 않음
- 각 데이터 셋의 전처리는 해당 모델 논문에서의 실험과 똑같이 진행
- 평균은 0, 분산은 1이 되도록 표준화 되었고, 이에 대한 통계는 훈련 데이터를 기반으로 계산
Implementation Details
The Optimization Process
- Bayesian optimization을 쓰는 HyperOpt 사용
- 각 데이터셋 마다 validation set에 대한 결과를 최적화하며 1000 step 실시
- 초기 hyperparameter는 원래 논문의 것을 사용
- 각 모델 별로 쓰인 hyperparameter는 6~9개
- 각 모델 논문에서처럼 데이터 셋은 training,validation, test sets로 나눔
- 기존 분할 방식이 랜덤 분할이었다면 랜덤 분할을 3번 반복하고 그 결과의 평균 및 표준 오차를 report
- 랜덤 분할이 아니었다면, 4개의 random seed initialization 후 그 평균을 report
Metrics and evaluation
- 이진 분류 : cross-entropy loss
- 회귀 문제 : RMSE(root mean square error)
- 각 hyperparameter 조합에 대해 다른 4개의 random seed로 실험 반복
Statistical significance test
- RMSE, cross-entropy loss 뿐 아니라 프리드만 검정으로 유의성 검정
- 프리드만 검정은 각 데이터의 정규성 가정을 만족하지 않는 데이터에 대한 비모수적 검정
- 각 모델의 성능 순위를 비교하여 각 모델의 순위 합을 계산하고 p-value 획득
- p-value 값이 0.05 미만이면 실험 결과가 통계적으로 유의하므로 귀무가설 기각
Training
※ 각 모델 별로 기존 논문의 데이터 셋으로 훈련 된 모델을 original model, 그 외의 데이터 셋을 unseen dataset으로 표기
- 딥러닝 모델은 각각 기존 논문의 implementation을 따름
- Learning rate schedules 없이 Adam optimizer 이용
- 각 데이터 셋, 모델 별로 Batch size 최적화
- Validation set의 성능 향상 없을 때까지 100 consecutive epochs로 training
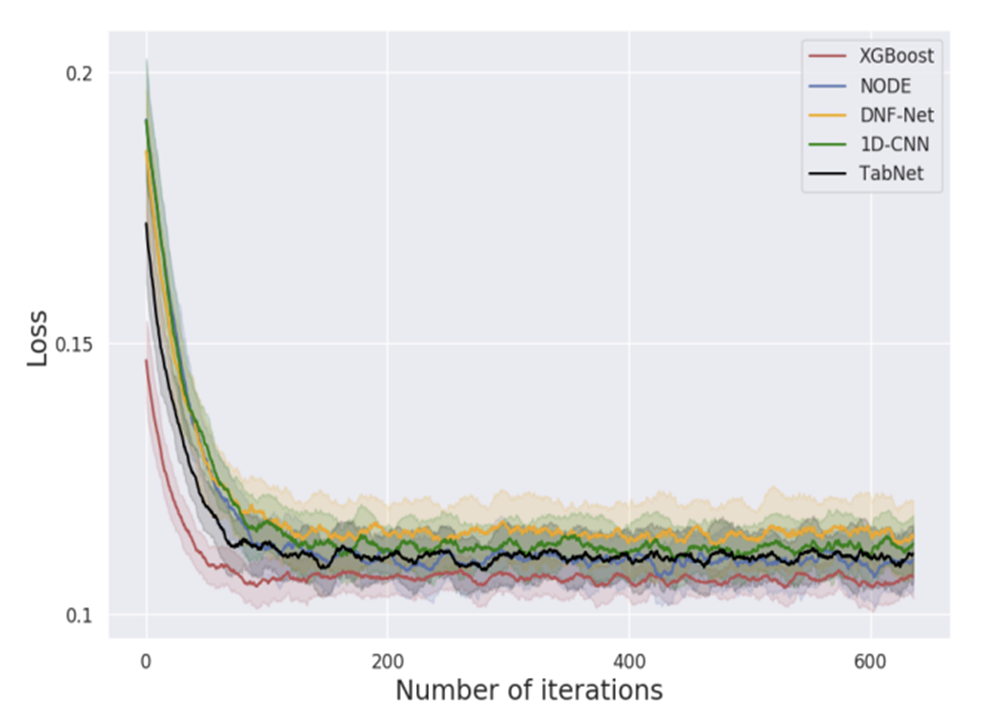
4. Results
Do the deep models generalize well to other datasets?
각 딥러닝 모델들이 unseen dataset에서도 성능이 뛰어났는지 XGBoost와 비교
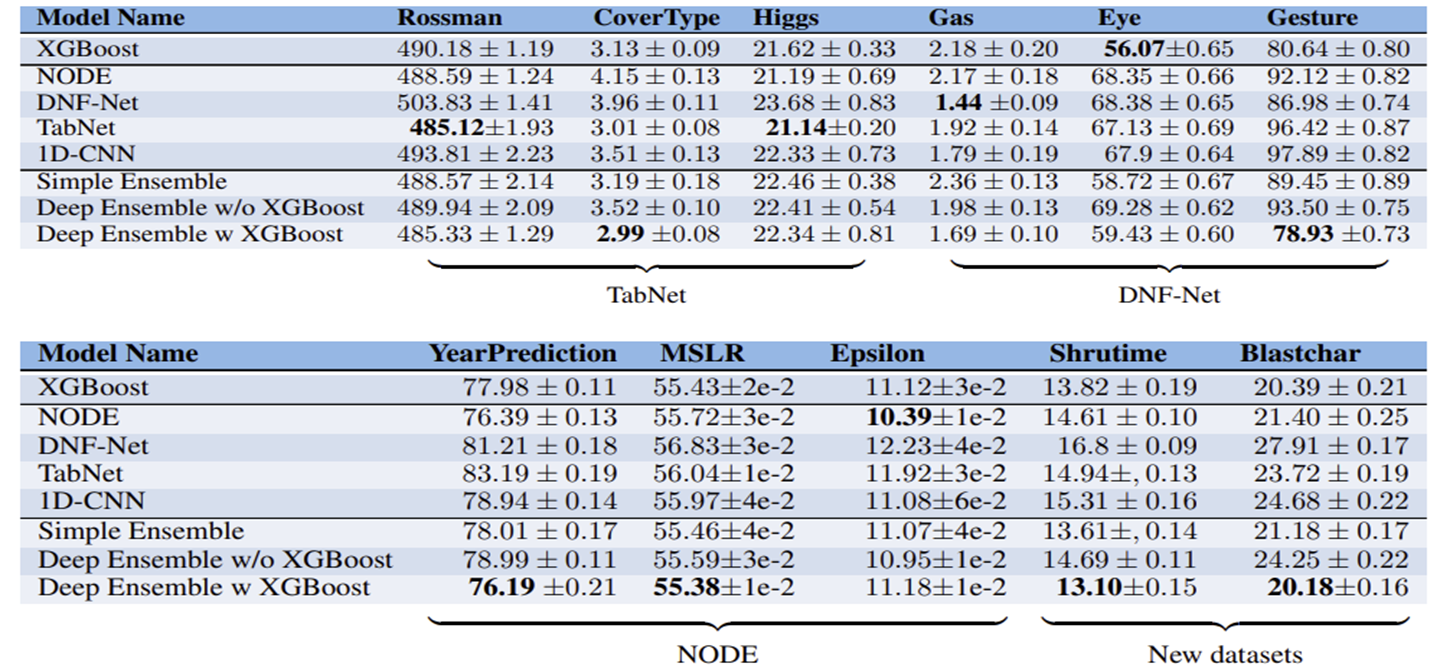
- 대부분의 모델은 unseen dataset에서 original model보다 좋지 못한 성능을 보임
- XGBoost는 대체적으로 딥러닝 모델보다 좋은 성능을 보임(original model들을 제외하고)
- 어떠한 딥러닝 모델도 일관되게 다른 모델을 능가하지 못함
- 각 모델과 unseen dataset에는 성능이 좋지 못했고, 이러한 점에서 original dataset없이 실험한 것 치고 1D-CNN은 그나마 나은 결과를 보여줌
- 딥러닝 모델과 XGBoost를 앙상블한 결과는 다른 모델들을 능가했고, 이는 통계적으로 유의했음 (p-value < 0.005)
왜 single deep model들은 XGBoost나 full ensemble보다 unseen dataset에 민감할까?
-
Selection bias
- 각 딥러닝 모델 논문에서 쓰인 데이터 셋은 각 모델에 잘 맞는 데이터 셋을 골랐을 가능성이 있음
-
Optimization of hyperparameters
- 각 논문에서는 본 논문보다 더 광범위한 hyperparameter tuning 과정을 거침
- Original dataset에 대해서는 튜닝을 똑같이 진행했고, 여기서도 결과는 같았기 때문에 Implementation issue는 배제 가능
Do we need both XGBoost and deep networks?
여러 앙상블 모델들의 결과 비교
Simple Ensemble : XGBoost와 classical model 앙상블
Deep Ensemble w/o XGBoost : 딥러닝 모델만 앙상블
Deep Ensemble w XGBoost : 딥러닝 모델과 XGBoost 앙상블
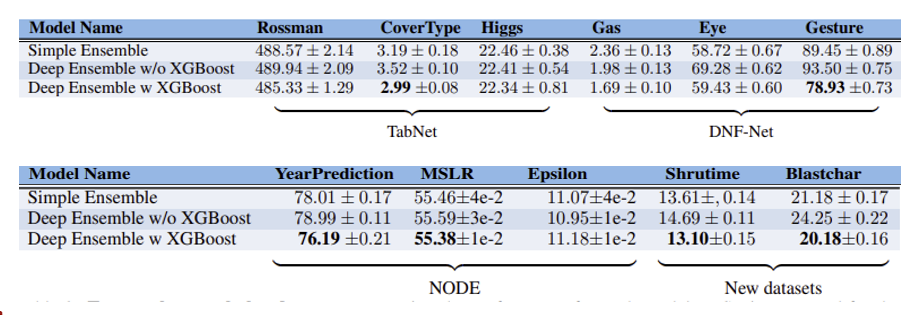
- 딥러닝 모델과 XGBoost를 앙상블 한 결과가 다른 앙상블 모델보다 성능이 좋았음
- 이러한 차이는 통계적으로 유의하였음 (p-value < 0.005)
Subset of models
다섯가지 모델 중 어떤 순서로 앙상블 모델의 Subset을 구성하는 것이 효율적인가?
- 낮은 validation loss를 갖는 모델 순으로
- 각 예제에서 모델의 Uncertainty를 기반으로 가장 높은 confidence를 갖는 모델 순으로
- Random order
Unseen dataset인 'Shrutime'으로 실험 진행

실험 결과
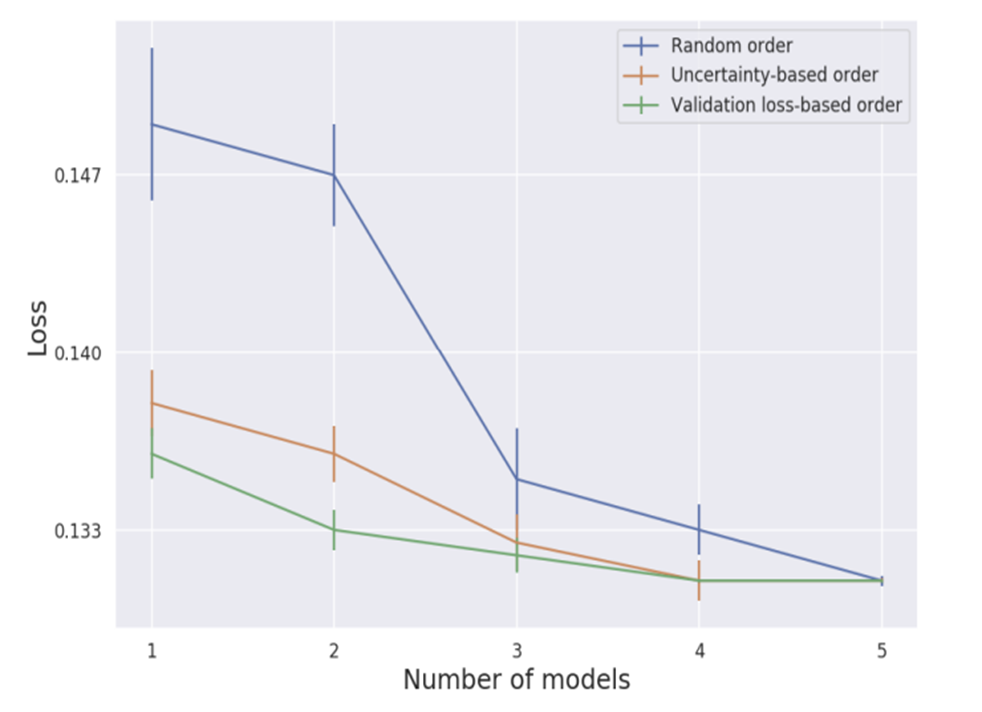
- 낮은 validation loss 순으로 모델을 추가할 때가 best
- Random order는 나머지 둘에 비해 적은 모델 수에서 확연히 높은 Loss를 보임
- 초기 세 가지 모델 선택에서 성능의 차이는 통계적으로 유의하였음 (p-vaue < 0.005)
How difficult is the Optimization?
어떻게 모델 별로 최적화 시간을 비교할 것인가?
- Hyperparameter 최적화를 위해 필요한 연산량을 계산하기 위해 FLOPS 측정
- 각 hyperparameter 별로 다른 FLOPS를 가지기 때문에 다른 모델끼리 비교하는 것은 불가능
- 모델 학습과 최적화 총 시간을 비교하는 방법이 있으나, 이는 소프트웨어의 최적화 수준에 큰 영향을 받음
- 널리 사용되는 라이브러리와 논문에서 제공되는 최적화되지 않은 구현을 직접 비교하는 것은 공정하지 않음
⇨ 그렇다면 대신 수렴할 때 까지의 iteration 수를 비교하자!
- Default hyperparameters가 best solution으로부터 얼마나 떨어져 있는 지와 모델의 강건함에 대한 대리 측정으로 활용 가능
- 소프트웨어의 최적화 수준과는 관계없는, 모델의 내재된 특성을 대변함
실험 결과
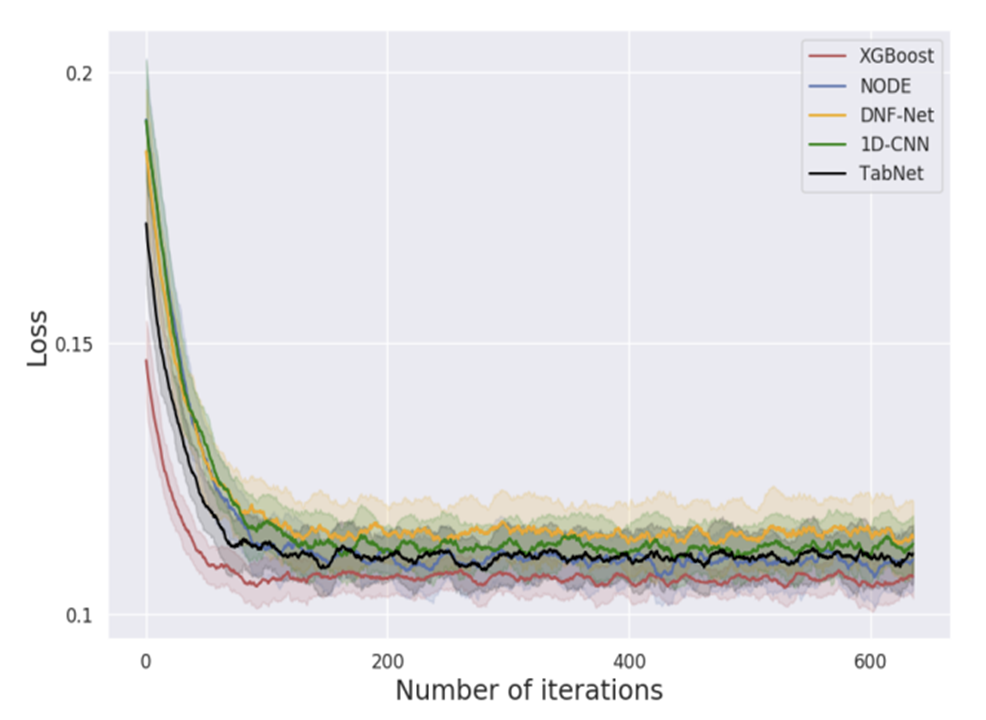
⇨ XGBoost가 가장 적은 iterations 에서 수렴(빠름)
Factors
-
위 실험에서는 Bayesian hyperparameter optimization process를 사용하였는데, 다른 optimization process를 쓰면 충분히 다른 결과가 나올 수 있음
-
XGBoost의 초기 hyperparameters는 더 많은 데이터셋을 기반으로 제안되었을 수도 있음. 딥러닝 모델의 다양한 데이터 셋에 잘 맞는 초기 hyperparameters를 찾을 수도 있을 것
-
강건하고 최적화를 쉽게 해주는 XGBoost만의 내재된 특성이 있을 수 있음
5. Discussion and Conclusion
-
XGBoost와 딥러닝 모델의 비교
- 딥러닝 모델들은 Unseen dataset에서 XGBoost보다 약한 성능을 보임
- 최적화 과정에서도 딥러닝 모델이 XGBoost보다 어려움을 겪음
-
XGBoost와 딥러닝 모델의 앙상블
- 다른 경우의 수보다 좋은 성능을 보임
- 이러한 결과는 앞으로의 연구에 또 다른 가능성을 제시해 주지만, 딥러닝 모델 최적화의 어려움으로 인해 아직 한계
- 따라서, 앞으로의 연구는 최적화가 쉬운 딥러닝 모델을 발전시키는 방향성이 필요함을 제시
Comment
연구실 논문 리뷰 세미나 발표를 위해 처음으로 맡은 논문이었는데, 타 논문들은 본인들이 새로 제시한 모델에 대해 최대한 좋은 점만 보여주는 점에 반해 위 논문은 적어도 정형 데이터 셋에서는 어떤 모델이든 모든 데이터 셋에서 우위를 점할 순 없다는 'No free lunch' 이론을 잘 대변하는 것 같다.
개인적인 생각으로 읽으면서 '딥러닝 모델과 GBDT 모델을 비교하는 건데 왜 GBDT 모델은 XGBoost만 쓴거지?', '앙상블 모델에 대한 실험은 좀 부족한 것 같은데?' 라는 생각이 먼저 들었다. 하지만 저자들이 위 논문을 통해 궁극적으로 하고 싶은 말은 제목 그대로 "정형 데이터에 당신이 필요한 것은 딥러닝 '뿐'만은 아니다." 라는 점에 주목할 필요가 있다. 그저 어떤 딥러닝 모델을 들고와도 단 하나의 GBDT 모델을 모든 데이터 셋에서 이기지 못한다면 '딥러닝 모델이 최고다!' 라는 주장은 반박될 수 있고, 앙상블에 대한 내용은 XGBoost와 딥러닝 모델의 앙상블이 좋은 결과를 보여주었다는 내용이기에 논점인 'GBDT와 딥러닝 다 고려해야 한다!' 를 흐리지 않고 있고, 최종적으로는 둘의 앙상블은 성능은 좋았지만, 아직 그 내부 딥러닝 모델의 hyperparameter tuning을 쉽게 하는 과정은 더 연구가 필요하다는 앞으로의 도전 과제를 잘 제시하고 있다고 생각한다.
References
