https://arxiv.org/abs/2212.06242
1. Introduction
Human instance segmentation은 image regions에서 서로 다른 개개인을 찾는 task이고, 크게 single-stage와 multi-stage 방법으로 나눌 수 있다.
그 중에서도 two-stage 방법은 일반적으로 detection을 먼저 수행한 후 segmentation을 순차적으로 진행하는 접근법이고, multi-stage 방법은 이러한 two-stage 방법을 여러 번 반복하는 방법이다. 보통 detection때는 특정 객체를 localization하여 region of interest(ROIs)를 얻고, segmentation은 각 instance에 대한 mask를 생성해낸다. 본 논문에서는 이러한 two-stage framework 중 하나이면서 pose와 instance segmentation을 공동으로 추정하는 Mask-RCNN을 활용한다.
주요 contribution은 아래와 같다.
- 하나의 unlabelled test image에 human segmentation을 적응 시키기 위한 test-time method를 제안한다.
- 새로운 domain에서 human segmentation network의 성능을 향상 시키기 위한 training-time method를 제안한다.
- 위 두 방법의 성능을 평가하고, 도메인 변화의 정도에 따른 TTA와 TTG의 장단점을 보여준다.
2. Related Work
Non-Adaptive Instance Segmentation
Non-adaptive instance segmentation methods는 일반적으로 single-stage나 multi-stage 접근법을 통해 강화된 architecture를 가진다.
- Single-stage methods는 전체 이미지에 대한 feature map을 만들고 각 instance에 대한 feature map을 추출해 해당 mask를 만들어 내는 분산된 접근법이 있고, 대표적인 예시로는 InstanceFCN, CondInst, YOLACT 등이 있다.
- Multi-stage methods는 일반적으로 두 단계를 가지는데, 먼저 bounding box를 활용하여 객체를 탐지하고, 해당 ROIs에서 feature를 추출해서 원하는 mask를 생성하는 방식이 있다. 본 논문에서 초점을 맞출 Mask-RCNN이 이러한 방식에 해당하고, 그 외에도 query 기반 multi-stage method인 QueryInst 등이 있다.
Adaptive Instance Segmentation
Adaptive instance segmentation에 대한 연구는 비교적 드문데, 대부분은 nuclei, cells 등 biomedical entity의 segmentation을 목표로 한다.
Adaptive human instance segmentation은 연구된 바가 많지 않지만, source dataset에서 적응시켜 임상의의 pose와 instance mask를 공동으로 추정하는 방식을 사용한 연구가 있다.
Human Instance Segmentation
Human instance segmentation은 pose와 같은 추가적인 정보를 활용하여 인간을 segment한다. 초기 연구에는 Pose2Seg, PersonLab, Pose2Instance 등이 있었고, 최근 연구에는 pose attention module과 keypoint sensitive combination을 사용하는 LSNet, 별도의 헤드에서 얻은 pose와 instance의 품질을 개선하기 위한 refinement network를 제안한 PosePlusSeg 등이 있다.
3. Method
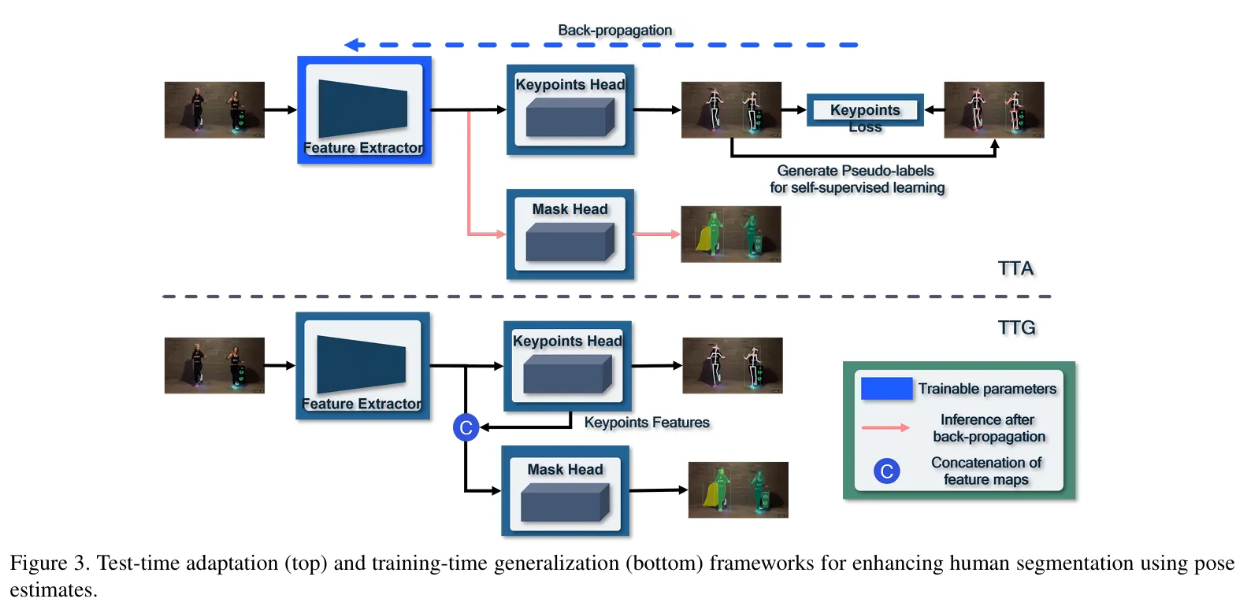
먼저 keypoints를 사용한 human segmentation task를 설명하고, 최종으로는 TTA와 TTG의 이득을 향상시키기 위해 고안한 heuristics와 keypoints head variants를 소개한다.
3.1. Human Segmentation using Keypoints

Segmentation network는 test 이미지가 training dataset과 큰 domain shift를 보일 경우 성능이 저하될 수 있다. 위 그림을 예시로 보면 남성에 대한 mask가 여성까지 흘러넘치는 걸 확인할 수 있다.
재미있게도 segmentation 성능이 좋지 않아도 human keypoints에 대한 추정은 잘 이뤄진다는 것을 확인 가능하다. 이는 저자들이 keypoints estimates를 사용하여 TTA와 TTG로 human instance segmentation을 향상시키고자 함에 대한 동기가 되었다.
3.2. Test-time Adaptation

먼저 Test-time-adaptation method에서는 완전히 학습된 human instance segmentation/keypoints 추정 네트워크가 있다고 가정한다. 즉, 와 하나의 unlabelled test image가 있다고 가정한다. 또한 backpropagation을 통해서 가중치를 test-time에 적응하는 것은 허용하지만, source dataset에 대한 접근은 허용하지 않는다.

TTA의 알고리즘으로 key point 추정치를 pseudo-labels로 변환하고, 이를 key point와 함께 keypoints loss에 입력하여 이러한 self-supervised loss를 역전파하여 backbone()의 가중치를 조정한다.
이 때 person bounding box 점수가 0.5 이상이라면 최소 확률 0.05를 갖는 key points를 선택하고, 56x56 heatmaps에서 가장 높은 값을 pseudo-labels로 활용하게 되고, keypoints loss로는 multi-category cross entropy를 사용한다. 마지막으로 적응된 segmentation mask는 적응된 feature map에서 mask head를 실행하여 생성된다.
3.3. Training-time Generalization

TTG때는 학습이 따로 필요하지 않은 human segmentation / pose estimation network()가 있다고 가정하며, labelled source dataset에 대한 접근을 허용한다. 하지만 test image나 target domain에 대한 지식은 가용성은 가정하지 않는다. 또한, 네트워크 가중치의 test-time adaptation도 허용하지 않는다.

TTG의 알고리즘으로 keypoints head를 먼저 두 개의 subnets인 와 로 분리하여 feature extraction과 regression을 각각 수행하도록 구성한다. (자세한 내용은 뒤에서)
mask head도 추가적인 keypoints features를 수용하기 위해 로 수정되어야 한다.
이렇게 수정된 는 원래의 segmentation, pose losses를 사용하여 labelled source dataset에서 학습되고, test-time에는 aggregation 된 feature map에서 TTG mask head를 실행하여 segmentation mask를 생성한다.
3.4. Heuristics and Keypoints Head Variants
TTA와 TTG의 성능은 각 keypoint head에서 생성되는 pseudo-label과 feature의 품질에 크게 의존한다. 따라서 해당 섹션에서는 세 개의 keypoints head 변형과 이에 대한 heuristics를 논의한다. 여기서 feature map의 차원은 이며 은 person bounding box의 수이다.
Mask-RCNN
- 는 8개의 2d-convolutional layers로 구성되고, 각각은 512 채널의 output, 3x3 kernel size와 stride1로 설정된다. 따라서, 512개의 추가 keypoints features가 있다.
- 는 17개의 output channels, 4x4 kernel size와 stride 2를 가진 2d-transposed convolutional layers로 구성된다. 이후 bilinear upsampler를 통해 keypoints heatmap 해상도는 으로 증가된다.
Variant 1

- Mask-RCNN에서 keypoints head는 keypoint의 위치를 추정하지만, 이들의 visible과 occlusion(키포인트가 다른 요소에 의해 가려지는 것) 여부는 예측하지 않고, 이러한 특징은 위처럼 TTA의 성능에 악영향을 미칠 수 있다. 왼쪽 사람의 팔꿈치 위치는 정확히 추정되지만, occlusion으로 지정되지 않아 꽃다발 일부가 TTA mask에 포함되었다.
- 이를 해결하기 위해 모든 variants는 keypoints가 visible한지 occlusion한지 예측한다. (Variant 2는 이를 위해 2D-transposed-convolutional layer의 출력를 51로 바뀐 것을 제외하고는 Mask-RCNN과 같음
variant 1에 대한 설명을 오타 낸건가..?)
Variant 2

- Convolutional head에서 나온 keypoints estimation은 품질이 낮을 수 있어 TTA/TTG에 심각한 영향을 미칠 수 있다. 이를 향상시키기 위해 variant 2는 transformer를 사용한다. 즉, 는 6개의 layer, 8개의 head, width 256인 17개의 query를 가진 transformer decoder로, backbone feature map에서 작동한다.
- Input queries는 학습 가능한 파라미터이고, output queries는 keypoints에 mapping되고 3 layer MLP에 의해 keypoints heatmap으로 decoding된다. 그러므로 51개의 추가 keypoints features를 가진다.
- 는 heatmap 해상도를 56x56으로 늘리기 위해 bilinear upsampler를 포함한다.
Variant 3
- Variant 2는 target dataset에서 약간 더 나은 를 보여주지만, source dataset에서 Mask R-CNN과 variant 1에 비해 훨씬 낮은 결과를 보인다. 이는 variant 2에서 transformer 출력 query가 convolutional layer를 사용하지 않고 직접 14x14 heatmap으로 decoding되기 때문이다.
- 이를 해결하기 위해 variant 3에서는 마지막 transformer layer의 value projections와 attention weights를 사용하여 각 keypoints에 대해 별도의 15x14x14 feature map을 형성한다. 따라서 17x15개의 추가 keypoints feature가 생성된다.
- 는 keypoints feature map을 서로 독립적으로 추가 처리하는 두 개의 group 2D-convolutional layer와 하나의 group 2D-transposed-convolutional layer로 구성되며, 이후 bilinear upsampler를 통해 56x56 heatmaps를 얻는다.
4. Experiments
본 섹션에서는 TTA와 TTG를 비교한다.
4.1. Experimental Details
COCOPersons와 OCHuman 데이터 셋에서 평가를 보여준다. 자세한 실험 세팅과 방법은 논문 원문 참고
4.2. TTA vs. TTG Results


- COCOPersons validation set에서 OCHuman validation 및 test로 이동할 때 Mask-RCNN의 가 30% 이상 하락했고, 이는 두 데이터 간의 상당한 domain shift를 보여준다.
- Source dataset인 COCOPersons validation set에서 variant 2는 variant 3의 보다 4~5%뒤쳐지지만, target dataset에서는 1%정도 이점을 보이는데, 이는 variant 2가 convolutional layer를 사용하지 않고 keypoints token을 직접 spatial heatmap으로 디코딩하는 것을 원인으로 본다.
- 위 그림과 표에서 확인 가능하듯, transformer 사용은 keypoints pseudo-label의 품질을 개선하지 못하며, 이는 TTA 성능을 제한한다.

- Source dataset인 COCOPersons validation set에 대한 다양한 모델의 를 보여주는데, TTG가 약 1%를 개선하는 반면, TTA는 비슷한 정도가 저하되었다.
- TTG는 segmentation head를 학습하기 위해 추가적인 ground truth label을 사용하여 를 개선하지만, TTA는 single labelled test image에서 이미 최적화된 모델 가중치를 조정할 만큼 COCOPersons train set과 validation set 간 domain shift가 충분하지 않기 때문에 가 저하된다.

- Target dataset인 OCHuman validation 및 test set에 대한 를 보여준다. 가장 중요한 해석은 TTG의 효과가 TTA보다 훨씬 좋았다. 이는 TTG가 keypoints estimations를 직접 사용하지 않고, 정보가 더 많은 keypoints feature를 사용하기 때문이다.

- ResNet-101-FPN backbone에 대한 결과를 제공하는데, table5처럼 domain shift가 충분하지 않다면 TTA는 성능 저하로 이끌고 TTG 또한 미미한 이득을 준다.

- 마찬가지의 경우에서, domain shift가 충분하다면 TTA의 이득은 작고, 사용된 heuristics에 의존적이며, TTG는 이득이 더 크고 모델의 변형에 덜 민감하다.

- Related works에서 소개했던 기존 모델들과 비교했을 때, TTG는 충분히 경쟁력 있는 성능을 보여주었다. 이는 TTG가 사용된 heuristics에 덜 의존적이고 아키텍처의 변형에 강건하다는 점을 보여준다.
4.3. Ablation Studies

- 위 세 가지 표는 variant 2에 대하여 각각 TTA 의 adaptation learning rate, min-person-score, min-keypoint-prob을 변경하면서 실험했을 때의 결과이다.
- 이러한 매개변수들은 관련 sweet-spot 내에 있지만, target domain에 대한 지식이 있다고 가정하지 않기 때문에 최적의 값을 사용할 수 없다.

예를 들면, 위 그림에서 min-person-score를 0.5에서 0.8로 늘리면 배구 장면에서 일부 false-positive가 제거되지만, 아이스 스케이팅 장면에서는 일부 true-positives가 사라진다.
또한, test image에 따라서 TTA learning rate와 같은 하이퍼파라미터를 동적으로 선택하면 오른쪽 그림에서 0.5e-3의 경우 남성 mask의 spill over가 해결되지만, 더 큰 4e-3으로 설정할 경우 여성의 mask를 축소하여 성능이 저하된다.

- backbone이 partially adaptive한 시나리오에 대해서 실험을 진행하였을 때, 낮은 learning rate에서는 partially adapted backbone이 fully adapted backbone보다 TTA의 효력이 낮지만, 큰 learning rate에서는 더 효력이 컸다.

- 마지막으로 TTG 모델이 test 시점에서 adapted 된 경우의 인데, TTG가 이미 최적화된 경우엔 TTA의 효력은 매우 미미하거나 거의 없음을 보여준다.
5. Conclusion
본 논문에서는keypoints estimation을 사용한 human segmentation masks를 더 잘 얻고자 TTA, TTG 두 가지 접근법을 비교하였다. 추가로 TTG에서 keypoints head를 backbone feature에 추가하고 이를 활용하는 방법을 제안하였고, pseudo-label의 품질을 개선하기 위해 세 가지 추가적인 pose-head variants를 고안하였다.
또한 Ablation study에서는 두 접근법을 평가하고 TTA의 성능을 제한하는 요인을 살펴보았다.
