[논문 정리] Faster Segment Anything: Towards Lightweight SAM For Mobile Applications
https://arxiv.org/pdf/2306.14289
Introduction
Segment Anything Model(SAM) 의 등장은 큰 화제가 되었는데, 이는 다음 요소들에 기인한다.
- NLP를 따라서 vision에서도 foundation model과 prompt engineering을 결합하는 방법을 추구할 수 있다는 것을 최초로 보여주었다.
- label-free한 segmentation 을 처음으로 수행하고자 하였고, 이는 label prediction과 나란히 이루어지는 vision task이다.
하지만 많은 경우 모바일 앱과 같은 자원이 한정된 edge device에서 실행되어야 한다.
SAM의 경우 대부분의 리소스를 image encoder에서 차지하기에, 저자들은 이를 가벼운 모델로 knowledge distillation을 이용하여 대체하고자 하는 연구를 진행하였다.

Table 1처럼 ViT-H 기반의 image encoder는 6억개가 넘는 파라미터를 갖고, ViT-B 기반 또한 8천만개가 넘는 파라미터 수를 가진다. 저자들은 ViT-H 기반으로 학습된 원본 image encoder에서 Tiny ViT 기반의 image encoder로 knowledge distillation을 하였고, 이후 mask decoder를 finetuning 하였다.(mask decoder의 파라미터는 원본 SAM에서도 작으므로 구조를 따로 변경하진 않았다고 한다.)
결과적인 MobileSAM은 원본 SAM보다 100배 적은 image encoder 파라미터 수를 가지면서도 동등한 성능을 낸다고 한다.
Proposed Method
원본 SAM에 대한 구조는 아래 글에서 확인 가능합니다.
https://velog.io/@barley_15/논문-정리-Segment-Anything
Coupled distillation
원본 SAM의 image encoder에는 ViT-H 모델로 학습된다. 이를 학습하는 덴 256 A100 GPU들로 68시간이나 걸린다. 따라서 훨씬 경량화 된 image encoder로 대체하고자 하였고, 재학습에는 ViT-H based SAM의 지식을 더 작은 image encoder에 transfer하는 knowledge distillation 기법을 활용하였다.
From semi-coupled to decoupled distillation
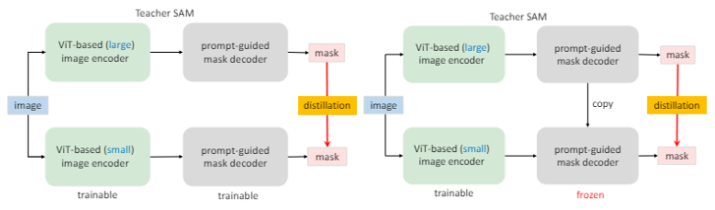
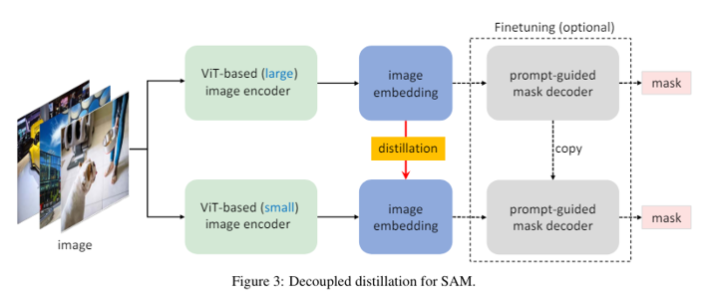
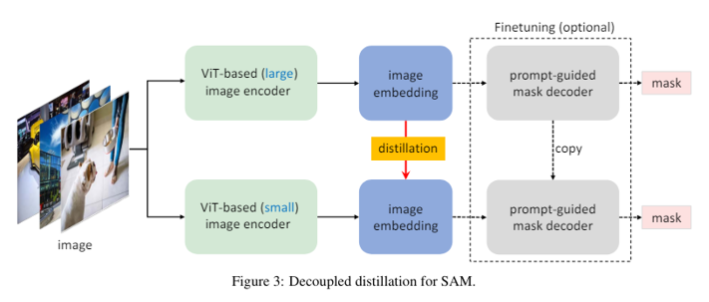
knowledge distillation(KD)를 진행할 때, 그림 왼쪽 방식의 image encoder와 decoder의 결합 최적화에 어려움이 있다. 둘 다 상태가 좋지 않으면 학습하기 쉽지 않다. 따라서 저자들은 divide-and-conquer 알고리즘에 영감을 받아 KD를 두 sub tasks로 분리하였는데, 각각 image encoder distillation과 mask decoder finetuning를 순서대로 수행하는 것이다.
오른쪽 그림의 방식인데, 먼저 image encoder를 원본에서 copy 된 frozen mask decoder와 결합한 상태로 최적화한다. mask decoder는 얼려져 있기 때문에, 만약 image encoder가 빈약하더라도 이에 악영향을 받지 않는다. 이러한 방식을 semi-coupled라고 명명한다(비록 얼려졌더라도 image encoder의 최적화가 mask decoder와 완전히 분리되어있진 않기 때문)
하지만 prompt의 선택은 랜덤이기때문에, semi-coupled 방식도 최적화에 어려움이 있을 수 있다.
그래서 저자들은 decoupled distillation도 구상했는데, 이는 mask decoder에 의존하지 않고 곧바로 KD를 하는 것이다. 이렇게 이미지 임베딩의 KD는 또한 마스크 예측에서 focal loss와 dice loss의 결합 대신, 간단한 MSE Loss 방식을 채택할 수 있다.
On the necessity of mask decoder finetuning
decoupled 방식은 원래의 frozen mask decoder와 맞지 않는 image encoder를 생성할 수도 있지만, 저자들은 경험적으로 student image encoder로부터 생성된 image encoding이 teacher image encoder로부터 생성된 것과 충분히 유사한 것을 확인했다. 그래서 위 그림에서도 mask decoder의 finetuning 과정을 optional하게 표현하였다.
Experiments
Experimental setup
ViT backbone 모델로는 Tiny ViT와 Deit-Tiny 중 더 성능이 좋은 Tiny ViT를 채택하였다.
image encoder는 이미지의 해상도를 낮추기 위해 4단계로 구성되어있으며, 1단계는 반전 잔차를 가지는 convolution blocks로 구성되고, 나머지 세 단계는 transformer blocks를 포함하는 단계들로 구성된다.
첫 downsampling은 두 개의 stride 2 Conv blocks를 지나면서 이루어지고, 다른 단계에서는 stride 2의 Conv Blocks를 지나면서 이루어지되, 원본 SAM에서의 image encoder output과 같은 해상도의 이미지로 맞추기 위해 마지막 단계에서는 stride 1의 Conv Block을 사용하였다고 한다. 이렇게 되면 원본 SAM의 image encoder output과 마찬가지로 16배 downscaling된 결과가 나온다.
Training and evaluation details

MobileSAM image encoder의 파라미터 수는 원본과 비교했을 때 대폭 감소하였다. 위에서 언급된 ViT-B 모델(8600만개)과 비교해도 훨씬 적은 양이다. Image encoder에 decoupled KD에는 단일 GPU와 SA-1B(원본 SAM 훈련에 쓰인 데이터 셋) 1%의 데이터 셋만으로 8 epochs 훈련시켰다.
Teacher image encoder에서 한 번 image embedding을 뽑아낼 때 오랜 시간이 걸리기 때문에, 시간 단축을 위해 한 번만 실행하고 저장해서 사용하는 방식을 썼다.
MobileSAM performs on par with the original SAM

원본 SAM과 비교했을 때, MobileSAM은 유사하게 만족스러운 마스크 결과를 보여주었다.
Abslation study
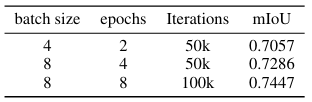
- 같은 반복 횟수에서 batch size를 늘릴 경우 모델 성능이 향상되었음을 확인할 수 있다.
- 같은 배치 크기에서 epochs을 늘릴 경우에도 성능이 향상되었다.
→ GPU 수를 늘려 더 큰 batch size나 반복 횟수를 늘리면 성능이 더 향상 될 것으로 기대할 수 있다.
MobileSAM outperforms FastSAM
SAM에서 속도 및 파라미터 수 절감에 초점을 두었던 또 다른 모델인 FastSAM 과 비교하였을 때, mobileSAM은 속도 - 사이즈 측면, mIoU측면에서 모두 훨씬 좋은 결과를 보인다.

