✍의사결정나무(Decision Tree)란?
지도학습 알고리즘 중 하나로, 트리구조를 사용하여 데이터를 분류하거나 예측하는 모델
- 각 노드는 특정 특성을 기준으로 데이터 분할
- 변수 값에 의해서 분리하는 규칙 학습
- 데이터 전처리의 필요성이 낮음
- 특정 변수의 이산화 된 값으로 근사
의사결정나무 알고리즘 종류
| 알고리즘 | ID3 | C4.5 | C5.0 | CART |
|---|---|---|---|---|
| 데이터 타입 | 범주형 | 연속형, 범주형 | 연속형, 범주형, 날짜, 시간 | 연속형, 명목형 |
| 속도 | 느림 | ID3보단 빠름 | 빠름 | 평균 |
| 가지치기 | x | 사전 가지치기 | 사전 가지치기 | 사후 가지치기 |
| 부스팅 | x | x | o | o |
| 결측값 | x | x | o | o |
| 지표 | entropy | split info, gain info | split info, gain info | gini diversity index |
본 포스팅에서는 이 중 CART를 자세히 다루어보려 한다.
CART(Classification and Regression Trees)
- 분류 트리 분석
예측된 결과로 입력 데이터가 분류되는 클래스 출력
- 회귀 트리 분석
예측된 결과로 특정 의미를 지니는 실수 값 출력
장점
- 이해가 편하고 해석이 쉽다.
- 결측치가 있어도 모델에 넣을 수 있다.
- 수치형, 범주형 데이터 모두 가능하다.
⇨ 데이터 준비(preprocessing) 작업을 요구하지 않는다.
CART의 핵심 Idea
- 재귀적인 분리(Recursive partitioning)
- 데이터가 같은 파트에 속하는 데이터의 균질성(homogeneity)이 최대가 되도록 반복적으로 두 node 분리
- 학습 데이터(Training data)에 대해 100% 정확도로 적합(fitting) 할 수 있음
- 가지치기(Pruning the tree)
- 과적합(overfitting)의 방지를 위해 끝 규칙들을 제거
- 학습 데이터 분리 100% 정확도는 곧 과적합을 의미하기 때문에 일반화 성능을 높이려면 반드시 가지치기 작업을 수행해야 한다.
재귀적인 분리
ex) Normal과 Abnormal을 분리하는 의사결정나무 구축
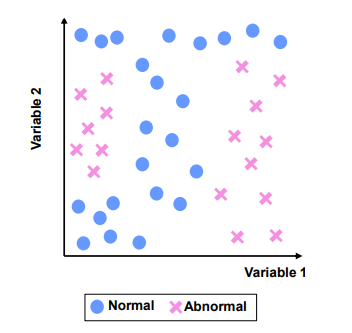
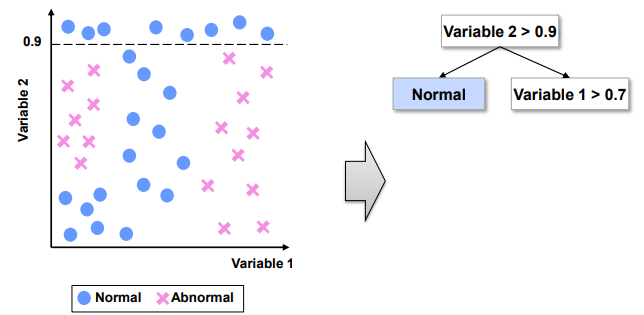
Step1. Greedy Search 방식으로 Variable 2 > 0.9 규칙 생성. 참이면 Normal로 분류, 거짓이면 Step2 진행
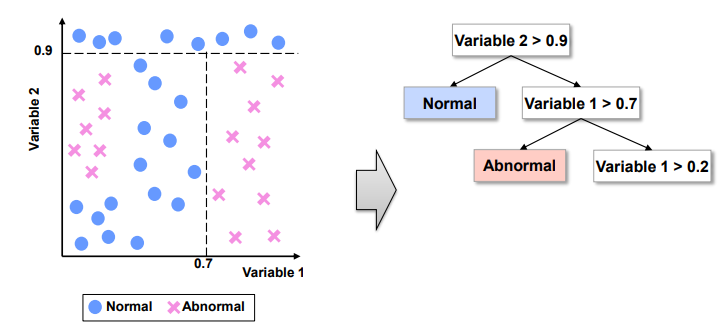
Step2. Variable 1 > 0.7 규칙 생성. 참이면 Abnormal로 분류, 거짓이면 Step3 진행
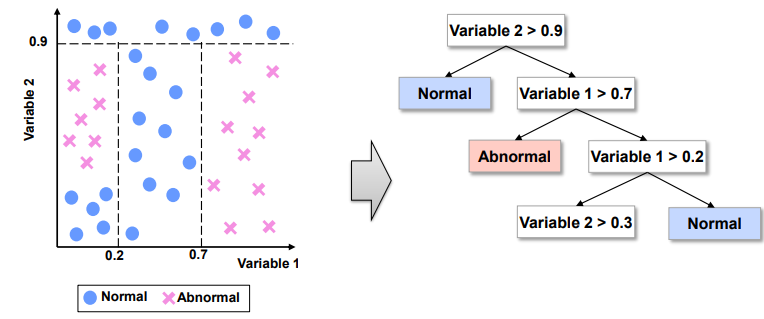
Step3. Variable 1 > 0.2 규칙 생성. 거짓이면 Normal로 분류, 참이면 Step4 진행
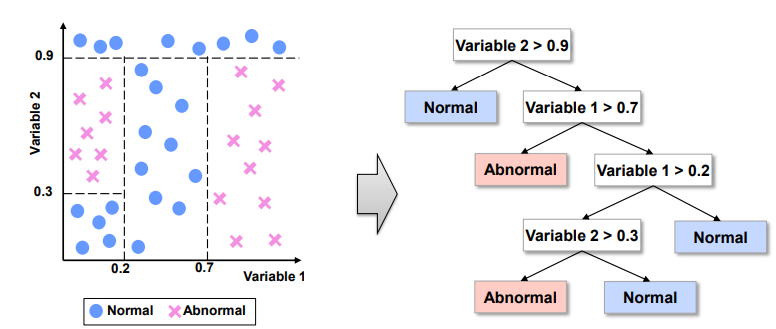
Step4. Variable 2 > 0.3 규칙 생성. 참이면 Abnormal, 거짓이면 Normal로 분류
⇨ 학습 데이터에 대한 100% 분리 정확도를 가지는 트리 완성
가지 치기
✍과적합 문제란?
기계학습에서 학습데이터를 과하게 학습하여 학습 데이터에만 높은 정확도를 보이고 새로운 데이터에 대해서는 예측 성능이 낮아지게 되어 일반화 성능을 떨어뜨리게 되는 현상

⇨ 의사결정나무에서 재귀적 분리 방식으로 트리를 생성하면 결국 학습 데이터 100% 분리 정확도를 가지고, 그 결과 과적합이 발생한다. 따라서, 가지치기 과정을 진행하여 과적합 문제를 사전에 방지해야 한다.
의사결정나무의 지표 - Impurity
✍불순도(Impurity)란?
해당 범주 안에 있는 데이터가 얼마나 섞여있는지를 의미. 불순도가 높을수록 데이터가 많이 섞여있다.
⇨ 의사결정나무에선 최대한 분기하여 각 노드 내 불순도를 낮추는 것을 목표로 한다.
불순도(Impurity) 측정 방법
- Gini index
- Entropy
- Information gain
Gini index
데이터의 통계적 분산정도를 정량화 한 값
: 지니 점수 (
: 개별 class
: 전체 class 수
: class의 관측치 비율
지니계수가 높을수록 불순도가 높다는 것을 의미한다.
Entropy
불순도에 대한 정보량의 기대수치
: 엔트로피 점수 (
: 개별 class
: 전체 class 수
: class의 관측치 비율
엔트로피가 높을수록 불순도가 높다는 것을 의미한다.
아래는 예제 코드이다.
# Iris 데이터 셋으로 의사결정나무 생성하고 시각화하는 예제코드
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
# Iris 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 의사결정나무 모델 학습
model = DecisionTreeClassifier()
model.fit(X, y)
# 의사결정나무 시각화
dot_data = export_graphviz(model, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
graph = graphviz.Source(dot_data)
graph.render("decision_tree") # 의사결정나무 그래프 저장
# 의사결정나무 시각화 결과 출력
graph.view()
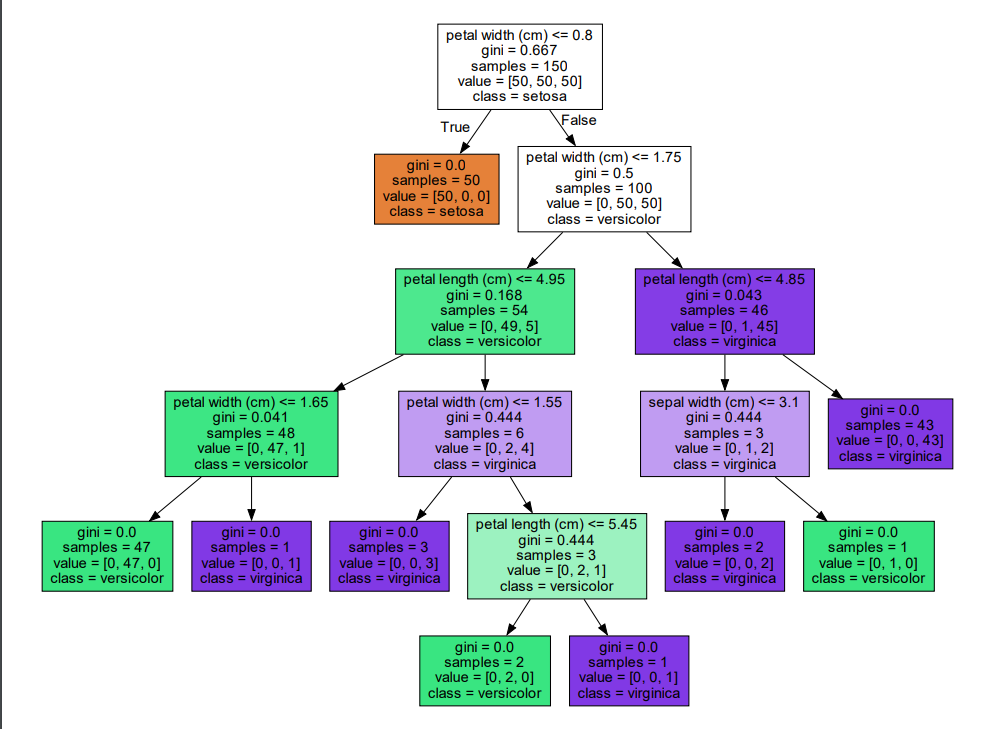
- 실행 결과
위 코드에서는 가지치기 작업을 따로 수행하지 않았기 때문에 모든 노드의 지니계수가 0이 될 때까지 분기한다. 가지치기를 진행한 코드는 아래에서 확인할 수 있다.
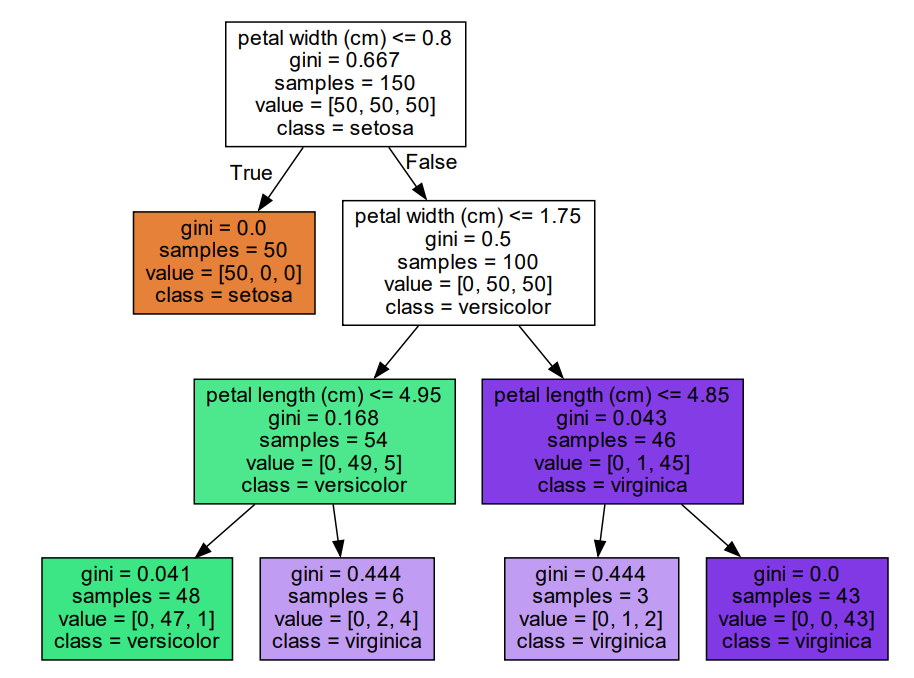
# 가지치기 진행한 예시 코드
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
# Iris 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target
# 의사결정나무 모델 학습
model = DecisionTreeClassifier(max_depth=3)
model.fit(X, y)
# 의사결정나무 시각화
dot_data = export_graphviz(model, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
graph = graphviz.Source(dot_data)
graph.render("decision_tree_pruned") # 의사결정나무 그래프 저장
# 의사결정나무 시각화 결과 출력
graph.view()
- 실행 결과
좀 더 자세히 실습한 코드는 아래 링크에 정리해 두었다.
https://github.com/YoongSeongHong/decisionTree_homework
