분분한 낙화
1.시간 복잡도 (Time complexity)
시간 복잡도란? 알고리즘을 구상할때 원하는 결과 도출을 목표로 하는 것을 1순위 목표로 설정하되 효율적으로 코드를 구성하였는지도 항상 염두할 것 -> 효율적으로 코드를 구성한다는 것은 시간복잡도를 최소화한다는 것과 동일 의미 시간 복잡도를 최소화 할 수 있는 방법
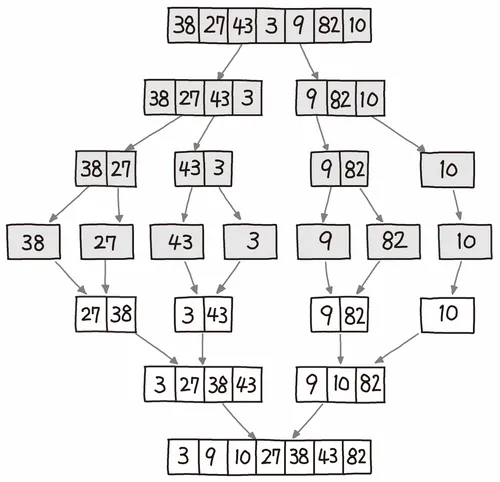
2.합병 정렬이란?
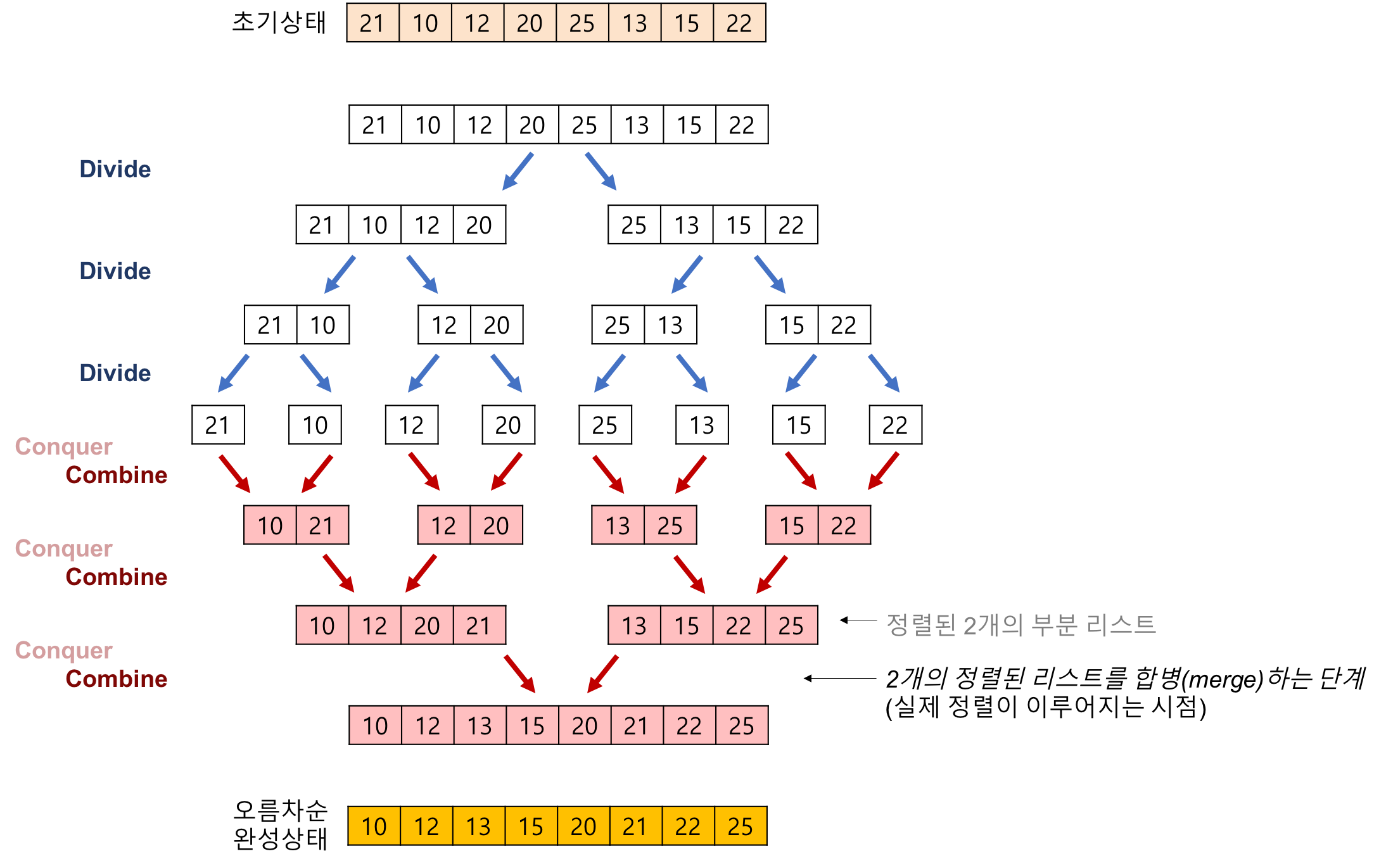
퀵정렬과 마찬가지로 분할 정복 정렬방법 중 하나특징n개의 데이터가 있을 때 리스트의 크기가 단위크기가 될 때까지 리스트를 분할하고 정렬하면서 병합한다.\-> $$log(n)$$ 번 분할 연산이 수행되고 n번 병합됨으로 $$n\*log(n)$$ 의 시간 복잡도를 가진다.
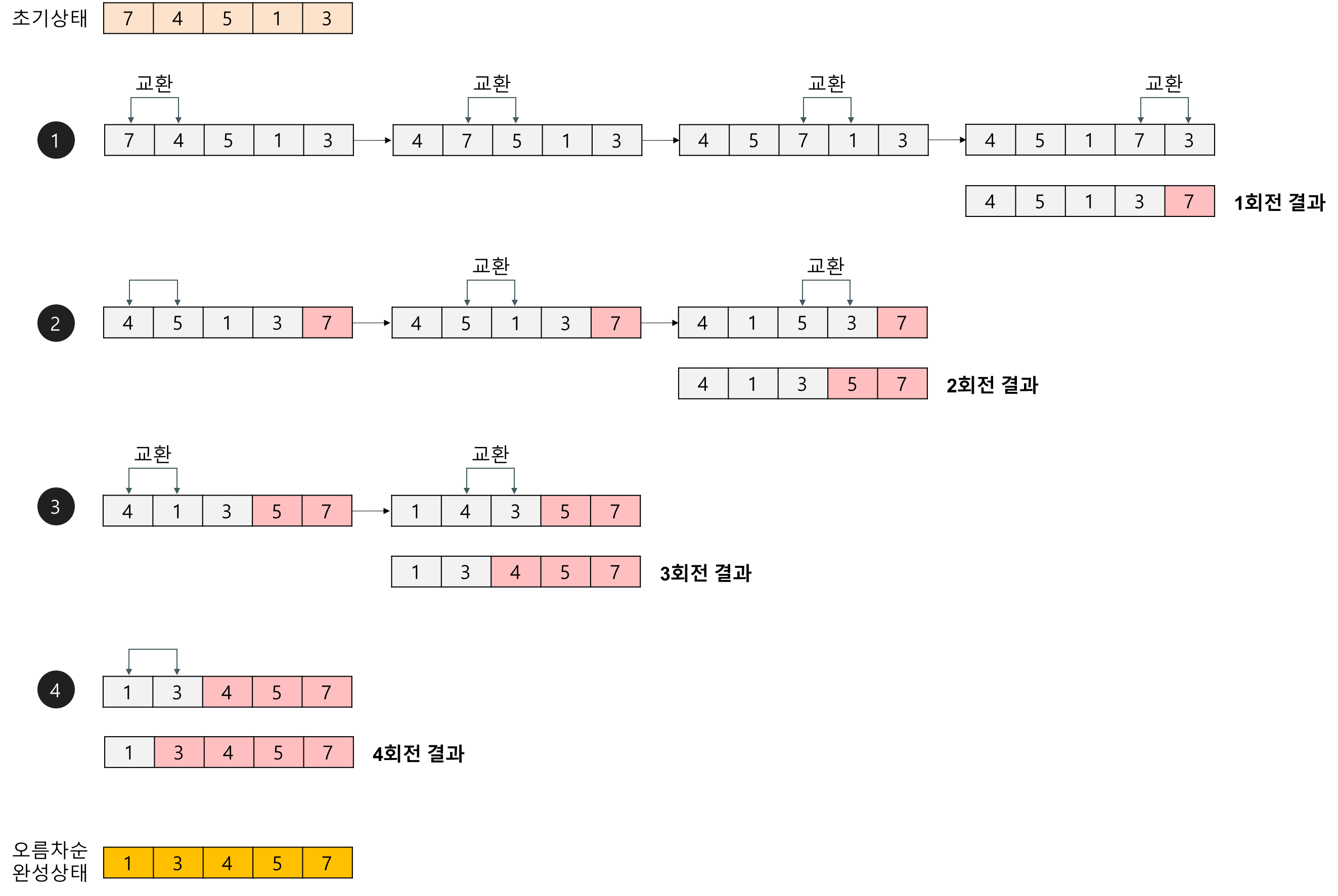
3.퀵 정렬이란?
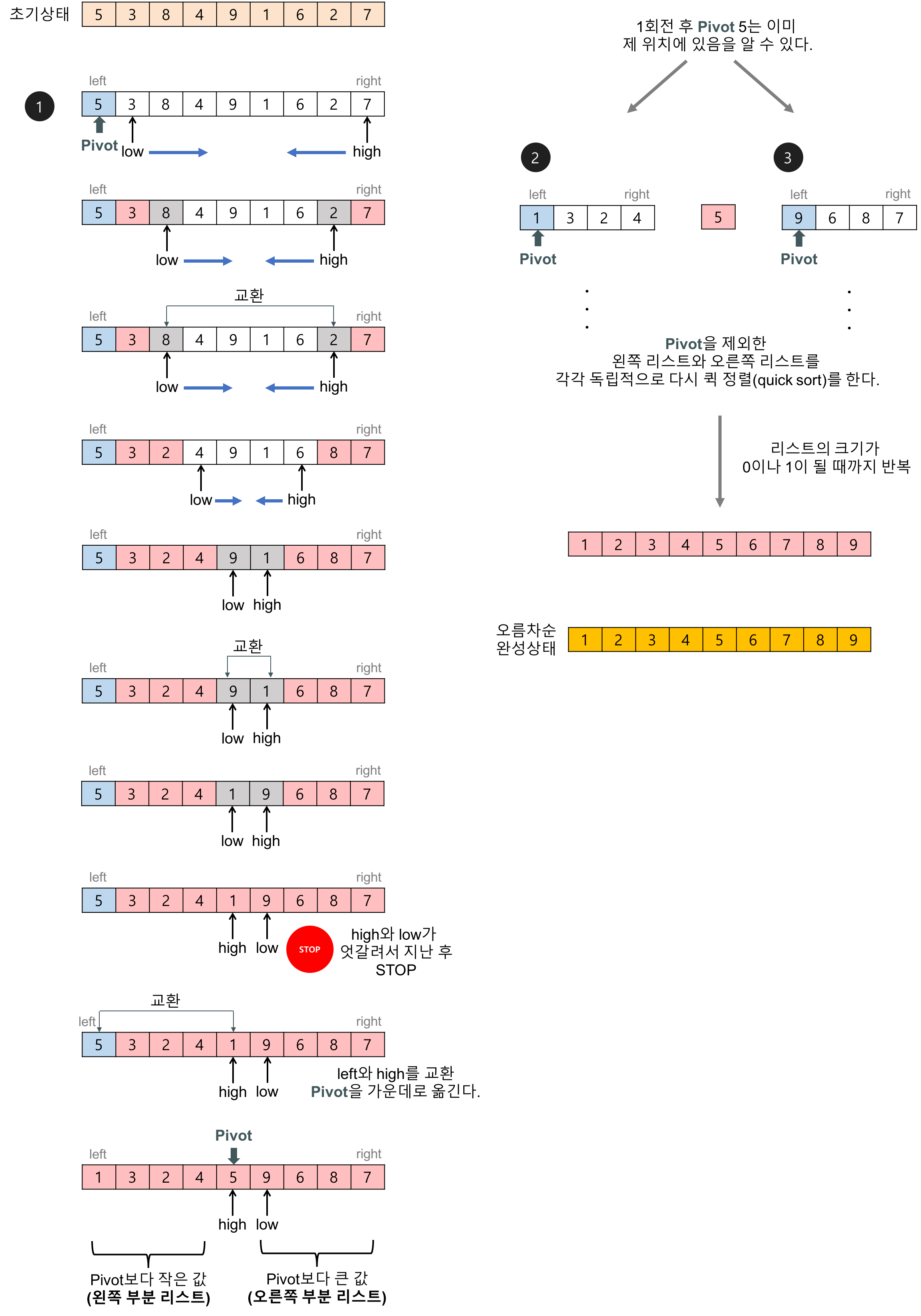
sorting 성능에서 구현이 간단한 버블정렬과 선택정렬은 $$O(n^2)$$의 시간복잡도를 가진다. 성능 면에서 퀵 정렬은 $$n*log(n)$$ 의 시간 복잡도를 가지며 최악의 경우에는 $$O(n^2)$$ 의 시간복잡도를 가진다. > 정렬 방법 먼저 피봇(piv
4.정렬 알고리즘 종류
데이터를 탐색하기 위함. 컴퓨터는 이론상 무한개의 데이터를 처리할 수 있어야한다.
5.구조체란? / C

구조체란? 데이터 타입이 다른 데이터들을 다루기 위해 C언어의 기본 타입을 가지고 사용자가 새롭게 지정할 수 있는 사용자 정의 타입 배열은 같은 데이터 타입 (int, char, float 등)만을 묶어서 데이터를 저장할 수 있다. 하지만 학생의 이름, 키, 나이 등
6.인라인 함수, 매크로함수란? / C
인라인 함수는 인라인으로 정의한 함수 호출 시 호출된 자리에 코드 자체가 안으로 들어간다.즉, 정의된 함수의 내용을 호출해서 실행하는 것이 아니라 호출하는 코드 자체가 함수 내용의 코드로 실행된다.알고리즘의 실행속도가 빨라진다.함수가 호출될때마다 처리해야하는 작업들이
7.이진 탐색 트리란?
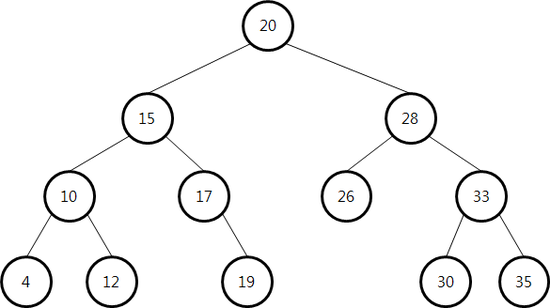
이진 탐색 트리 이진 트리를 탐색 가능할 수 있도록 원소 크기에 따라 노드 위치를 정한 것 모든 원소는 서로 다른 key 값을 가진다. 왼쪽 서브 트리에 있는 원소들의 key는 루트의 key보다 작다. 오른쪽 서브 트리에 있는 원소들의 key는 루트의 key보다 크다. 왼쪽 서브 트리와 오른쪽 서브 트리도 이진 탐색 트리이다. 이진 탐색 트리의 탐색, 삽...
8. 함수 포인터란?
변수 뿐만 아니라 함수도 포인터로 가리킬 수 있다. 함수에도 할당된 주소가 존재하기 때문에 변수처럼 포인터로 가리킬 수가 있다. 일반 포인터와 마찬가지로 (*)을 사용해서 주소를 가리켜주면 된다. (1)int (2)(*showArr) (3)(int arr[], int n) 지정 양식 (1) 함수의 반환형 (2) 함수 포인터의 이름 (임의 설정) (3...
9.메모리 동적할당 malloc / C
메모리 동적할당이란? 알고리즘이 실행되는 도중, 런타임 과정에서 사용할 메모리 공간을 할당하는 것 동적할당되는 메모리는 힙 영역에 생성되며 컴파일 과정에서 메모리 크기가 결정되는 데이터 영역과 스택 영역에서의 정적 메모리 할당과는 다른 개념이다. malloc malloc 함수는 void형 포인터를 반환 하고 인자값으론 동적으로 할당할 메모리의 크기 를 ...