RLHF 전성시대에 supervised learning으로도 preference tuning을 할 수 있다는 선택지를 만든 논문TL;DR
- 23년 Neurips에 publish된 논문 Direct Preference Optimization (a.k.a DPO)
- DPO는 RLHF의 핵심 objective를 그대로 유지하면서도 복잡했던 reward model 학습, PPO rollout loop 제거, 단순 BCE loss로 policy 직접 최적화를 가능하게 만들었다.
- 즉, “Your language model is secretly a reward model.” RLHF를 offline supervised learning으로 바꿔버린 것이 DPO의 가장 큰 기여다.
1. Motivation
LLM은 방대한 지식을 학습하지만, 원하는 행동(align된 응답)을 정밀하게 제어하기 어렵다.
이를 해결하기 위해 RLHF가 널리 사용되었지만, RLHF는 구조적으로 복잡하고 불안정하다.
기존 RLHF의 문제점은 다음과 같다:
- 먼저 reward model을 학습해야 함
- 이후 PPO 같은 강화학습으로 policy를 optimize 해야 함
- 학습 과정에서 sampling loop가 필요해 비용이 큼
- KL constraint, reward scaling 등 하이퍼파라미터 튜닝이 까다로움
논문은 이 질문에서 출발한다:
“RLHF의 objective인 reward maximization을 굳이 강화학습으로 해야 하는가?”
저자들은 아래 그림과 같이 RL 없이 preference optimization을 직접 수행하는 방법 DPO를 제안한다. DPO는 RLHF objective를 유지하면서도 단순한 supervised learning으로 해결한다.
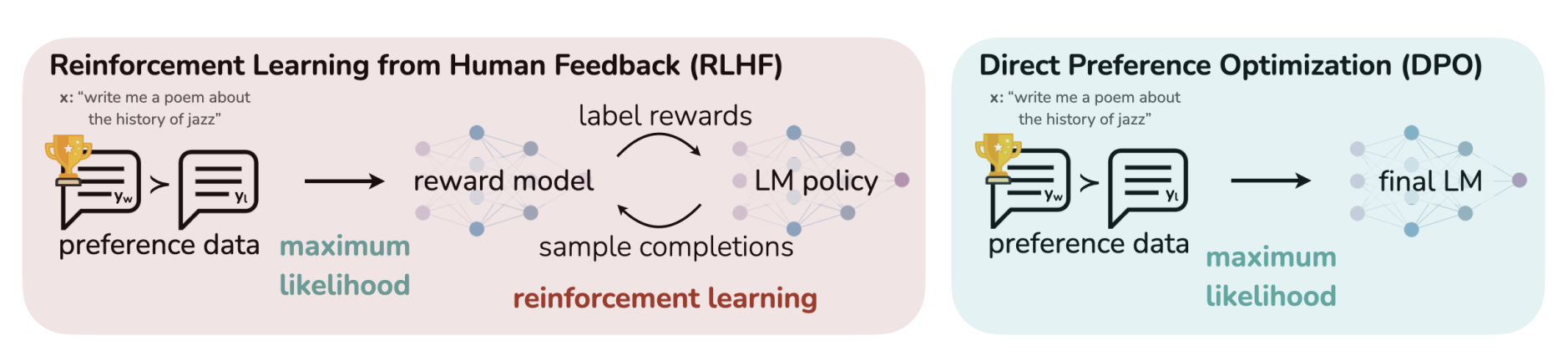
2. Background (=RLHF)
RLHF 파이프라인은 보통 3단계로 구성된다:
-
Supervised Fine-Tuning (SFT)
- pretrained LM을 고품질 데이터로 지도학습하여 초기 policy를 만든다.
-
Reward Modeling
- prompt 에 대해 두 응답 를 생성하고 사람이 더 좋은 응답을 선택
- 이 preference는 보통 Bradley–Terry 모델로 가정하고 수식(2)처럼 MLE로 학습
- Bradley–Terry 모델 =
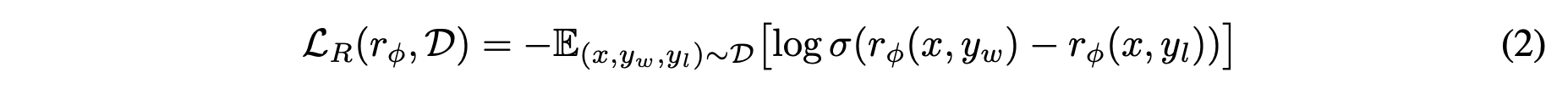
-
RL Fine-tuning
-
PPO를 사용하는 경우 최종 policy는 아래와 같이 구해진다.
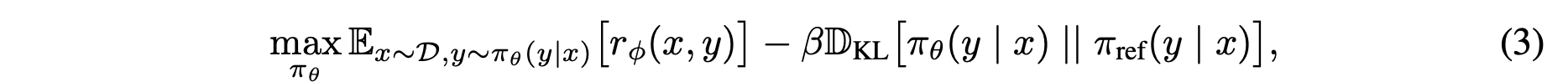
-
이걸 gradient ascent로 optimize 하려면 미분이 가능해야하는데, LLM은 discrete action space (argmax, top-k, top-p sampling, etc)이기 때문에 가 정의가 안된다.
-
그래서 policy gradient류 알고리즘에선 log-derivative trick을 써서 해결한다. (이해가 어렵다면 PPO 논문 리뷰 보러가기)
-
3. Method (=DPO)
DPO의 핵심은 다음 한 문장이다:
Reward model을 따로 학습하지 말고, policy 자체를 reward로 reparameterize하자.
3.1 Optimal policy의 closed-form
KL-constrained reward maximization의 optimal solution을 전개해보자.
- 논문에서 작성한 전개 방식을 그대로 따라가면 잘 이해가 되지 않을 수 있으니 내가 작성한 flow를 잘 따라오길 바란다.
- 결국 저자는 수식 (3)이 곧 임을 보이고 싶은 것이다. (는 임의의 상수 )
- 위 식만 보인다면 최적화해야 할 대상 는 closed form으로 가 될 수 있음을 알 수 있다. 그럼 정확히 closed form을 구해보자.
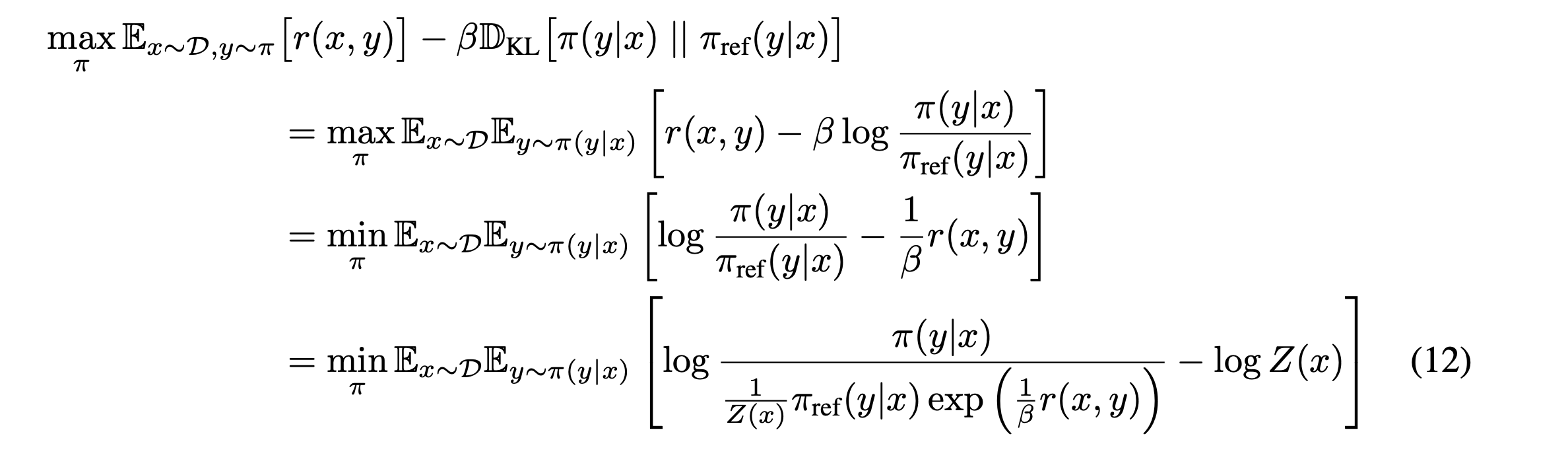
이 식 12가 곧 위에서 내가 작성한 form이다. ( -> KL term + constant이니까) - 이때 Z는 바로 아래와 같다. (12번 수식에서 3번째 -> 4번째 식으로 넘어가는 부분을 잘 보면 된다.)
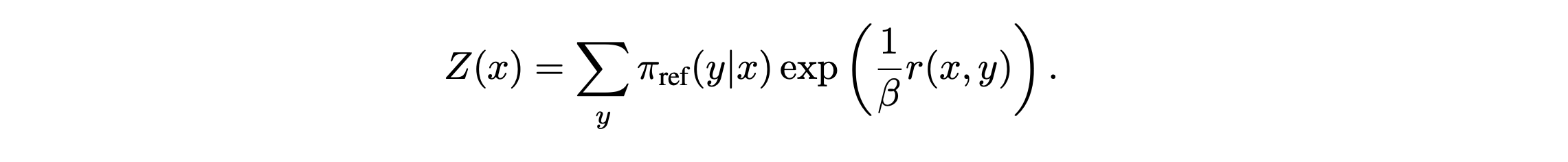
- 최종적으로 얻는 optimal policy의 closed form은
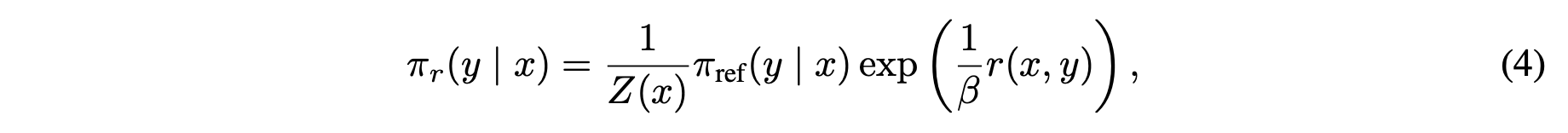
3.2 Reward를 policy로 표현하여 reward model 학습
그럼 이제 이걸 그대로 사용하면 되나?
이론적으로는 가능하지만, Z를 계산하려면 모든 가능한 y에 대해 를 구해야 하므로 현실적으로 불가능하다. 그래서 저자는 식(4)에서 학습 대상을 reward function으로 본다. r이 실제 reward 분포와 동일하다면 아래와 같이 밝혀진대로 이 정해지기 때문이다.
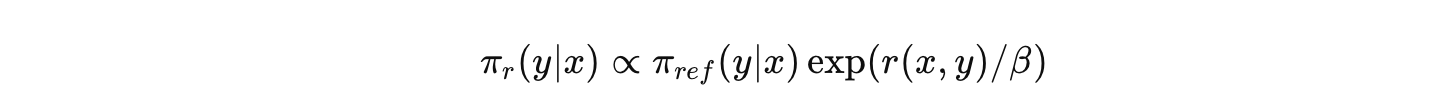
여기서 이 논문의 제목이 나온다. Your Language Model is Secretly a Reward Model 즉, reward를 language model의 policy로 표현한 뒤 reward model 학습시키듯이 학습하는 것이다!
여기서 한 가지 더 기발한 점이 있는데, reward를 학습시키려는 이유는 바로 Z를 없앨 수 있기 때문이다. (Z는 서로 상쇄되어서 날라감)
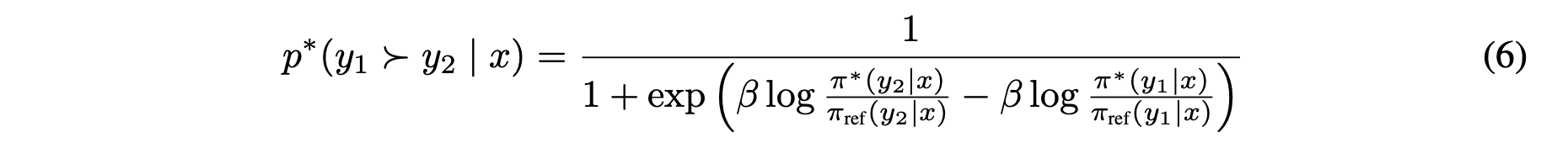
그래서 최종 DPO objective는 일반적인 reward model 학습과 같다. (일반적인 reward model 학습은 어떻게 할까?)
직관적으로는 preferred response를 생성할 확률은 올리고 dispreferred response를 생성할 확률은 내리는 BCE loss로 RLHF objective를 직접 최적화한다고도 볼 수 있겠다.
이제 reward model이 학습이 잘 될 수록 가 잘 학습되었다고 볼 수 있다!
3.3 DPO pipeline outline
- ) (모든 prompt x에 대하여 출력 y를 생성)
- (human preference labeling으로 데이터셋 구축)
- Gradient descent로 최적화
이때 꿀팁을 방출한다. 이미 pulbicily available한 preferecne dataset을 재사용하고 싶을 때, model weight()가 공개되어있다면 그걸로부터 DPO 학습을 하고, 없다면 로 직접 를 학습한 뒤 DPO 학습을 한다고 한다.
PPO 기반 RLHF 대비 훨씬 간편하지 않은가! value function 학습도 필요없고, 별도의 reward model 학습도 필요없다.
4 Theoretical Analysis of DPO
4.1 Your Language Model Is Secretly a Reward Model
이 섹션에서 말하고자 하는 바는 "reward model의 표현력이 줄어드는게 아니다"이다.
-
Reward modeling의 본질은reward 절대값을 맞추는 것이 아니라 preference ordering을 맞추는 것
-
따라서 policy를 직접 학습하는 것은 reward model을 학습하는 것과 동치이며 RL 없이 optimal policy recovery가 가능하다.
증명) 결국 아래 Deifinition 1은 reward는 원래 상대적인 ordering만 중요하다는 것을 주장하는 것이고, 이게 맞다면 RLHF는 별도의 function으로 reward를 계산하는 반면 일부로 partition function인 Z를 삭제함으로써 간결성을 올리나 ordering을 위한 Loss로 학습하기 때문에 핵심은 동일하다를 보일 수 있다.
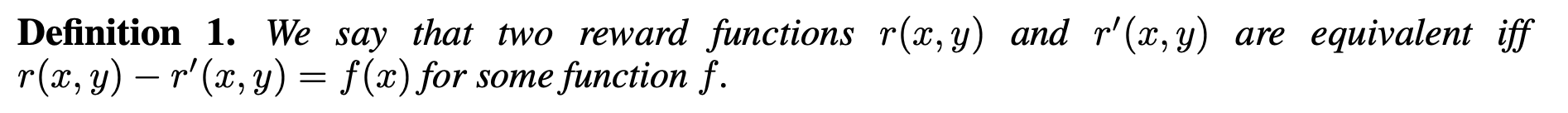
근거는 간단하다. 1) BT 모델은 원래 상대적 차이만 본다. 2) f(x)는 policy에 아무 영향도 미치지 않는다. (이 이유는 밑밑 사진 참고)
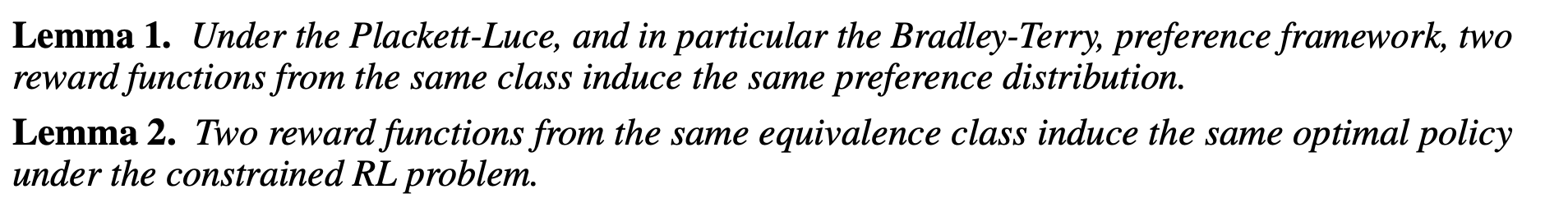

결론: reward model을 학습하는 것은 policy를 직접 학습하는 것과 동치이며 RL 없이 optimal policy recovery가 가능하다.
5.2 Instability of Actor-Critic Algorithms
RLHF의 objective는 아래와 같다.
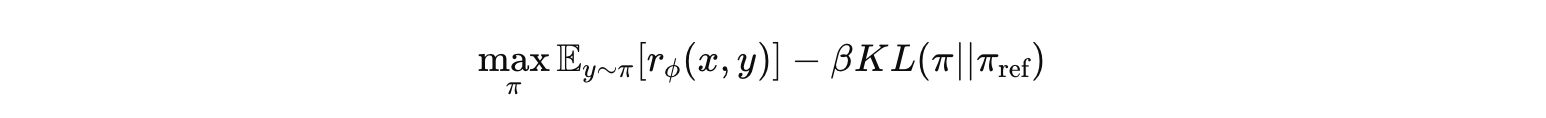
여기서 control-as-inference 관점 ()으로 본다면 수식(10)처럼 에 가 붙는다.
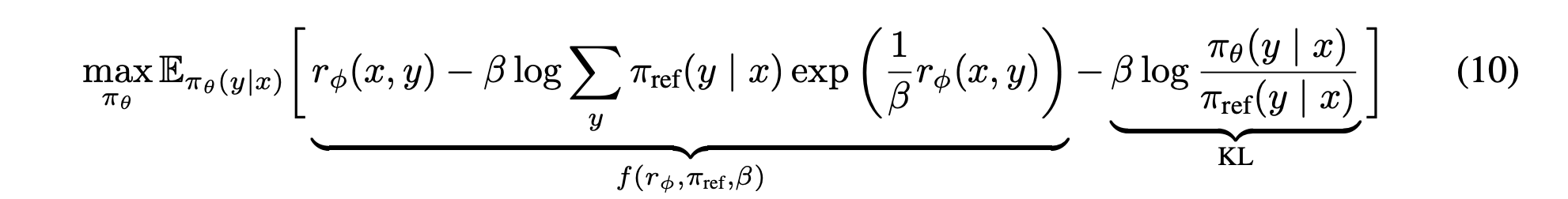
결국 policy gradient 방식으로 optimal한 policy로 간다면 저 Z term을 정확히 예측해야하는데,
- PPO는 그걸 baseline/value function으로 근사해야 해서 불안정
- DPO는 그 term이 구조적으로 사라지므로 안정적
5. Evaluation
이 섹션은 DPO가 "이론적으로 대체 가능하다"를 넘어서 실제로 PPO를 대체할 수 있는가를 실험으로 검증한다.
5.1 Experimental Setup: 공통 실험 프레임워크
모든 실험은 preference dataset 형태 () 동일하게 구성된다.
평가 방식은 두 가지로 나뉜다.
-
Ground-truth reward가 있는 controlled task
→ reward–KL frontier 직접 측정 가능 -
Real-world task (summarization/dialogue)
→ reward function이 없으므로 win-rate 기반 평가. GPT-4를 인간 평가 proxy로 사용한다.
5.2 Controlled Sentiment Generation (IMDb)
Preference optimization이 잘 되는지 가장 통제된 환경에서 확인한다.
- IMDb 리뷰 prefix를 prompt로 주고
- 긍정 sentiment completion을 생성
Preference label은 sentiment classifier로 자동 생성한다.
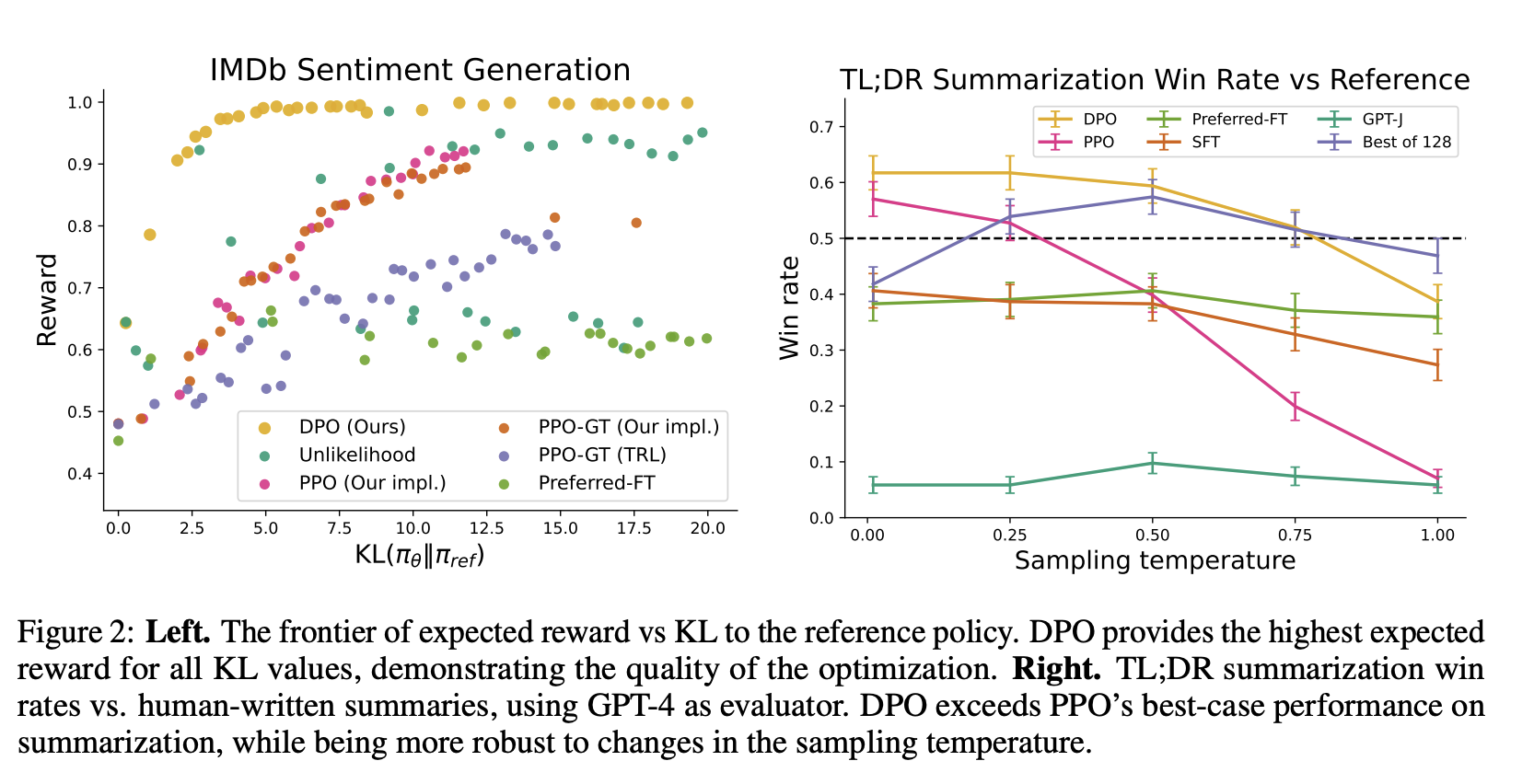
핵심 결과: Reward–KL Frontier
Figure 2 (Left)에서 DPO는 모든 KL 수준에서 PPO보다 더 높은 reward를 달성한다. 즉 DPO는 RL 없이도 reward maximize–KL constraint trade-off를 가장 효율적으로 달성한다.
5.3 TL;DR Summarization (Reddit)
Reddit forum post를 요약하는 RLHF task. Reward function이 없으므로 GPT-4 win-rate를 사용한다.
Figure 2 (Right)에서 DPO가 PPO의 best temperature보다도 높은 win-rate 달성. sampling temperature 변화에도 더 robust하다.
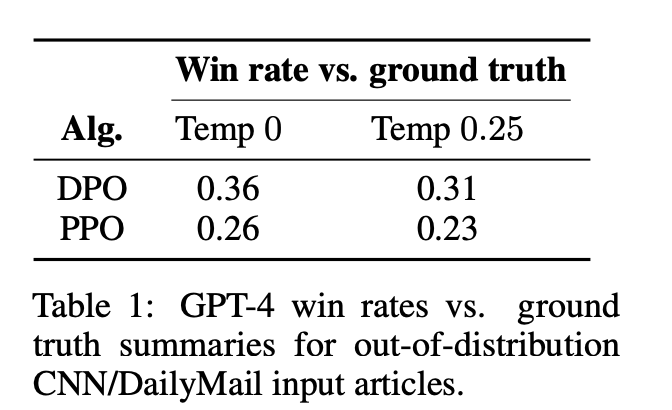
Distribution shift 실험 (CNN/DailyMail)
Reddit에서 학습한 policy를 뉴스 기사 요약(CNN/DM)으로 평가.
=> DPO가 PPO보다 더 잘 generalize함.
왜?
PPO는 on-policy sampling을 사용하기 때문에 PPO는 학습 중 계속 새 샘플을 뽑으며 policy가 점점 drift한다. 그러면 reward model이 본 적 없는 영역으로 가서 reward hacking, unstable updates이 발생하기 쉽다.
DPO는 purely offline likelihood optimization이다. DPO는 데이터 분포 밖으로 나가도 loss가 직접적으로 policy ratio로 정의되므로 critic 추정 없고, reward normalization 없다. 그래서 shift 상황에서 더 robust하게 나타난다.
In my opinion.. (개인적인 리뷰)
Strengths
- PPO 없이도 RLHF 수준 alignment 달성
- reward model + actor-critic loop 제거
- temperature 변화에 robust
- distribution shift에서도 성능 유지
Weakness
- GPT-4 평가 proxy는 완전한 human evaluation은 아님
- iterative deployment 상황에서 reference mismatch 문제는 미해결
- DPO가 reward hacking을 완전히 막는지는 추가 연구가 필요하지 않을까
Ref
