LLM
1.[쉬운 리뷰] DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 제대로 이해하기
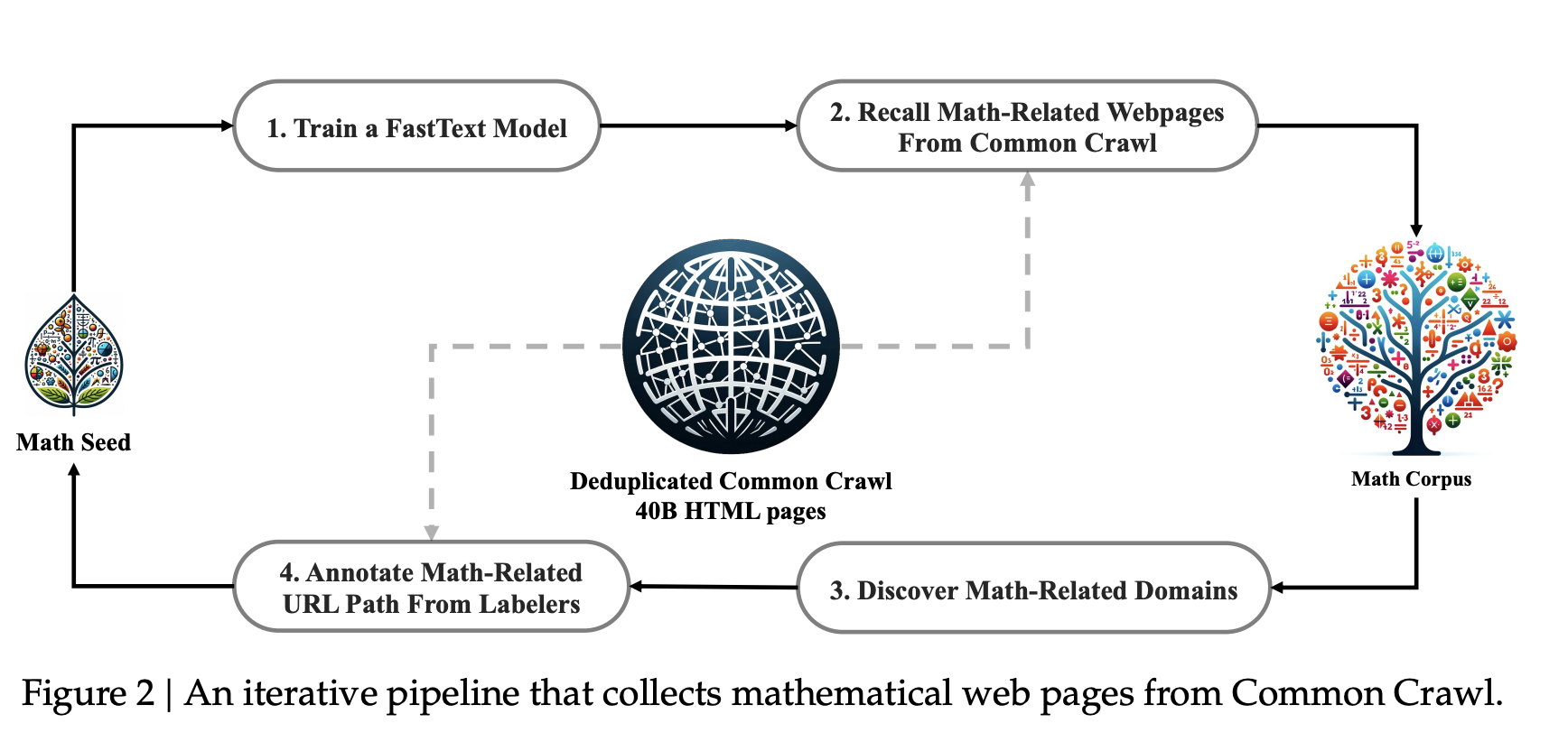
TL;DR 1. Motivation 수학적 추론은 LLM에서 가장 어려운 영역 중 하나 (multi-step reasoning, symbolic structure 등) GPT-4, Gemini 같은 상용 모델은 강력하지만 open-source 모델은 큰 성능 격차 존
2026년 2월 17일
2.[쉬운 리뷰] Direct Preference Optimization: Your Language Model is Secretly a Reward Model 제대로 이해하기
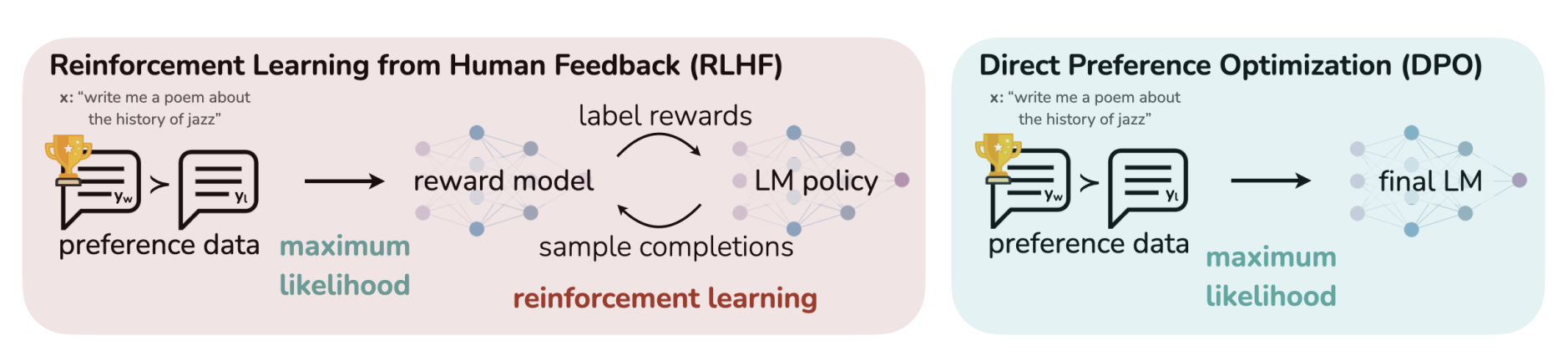
23년 Neurips에 publish된 논문 Direct Preference Optimization (a.k.a DPO)DPO는 RLHF의 핵심 objective를 그대로 유지하면서도 복잡했던 reward model 학습, PPO rollout loop 제거, 단순 B
2026년 1월 31일
3.[쉬운 리뷰] Learning to summarize from human feedback 제대로 이해하기
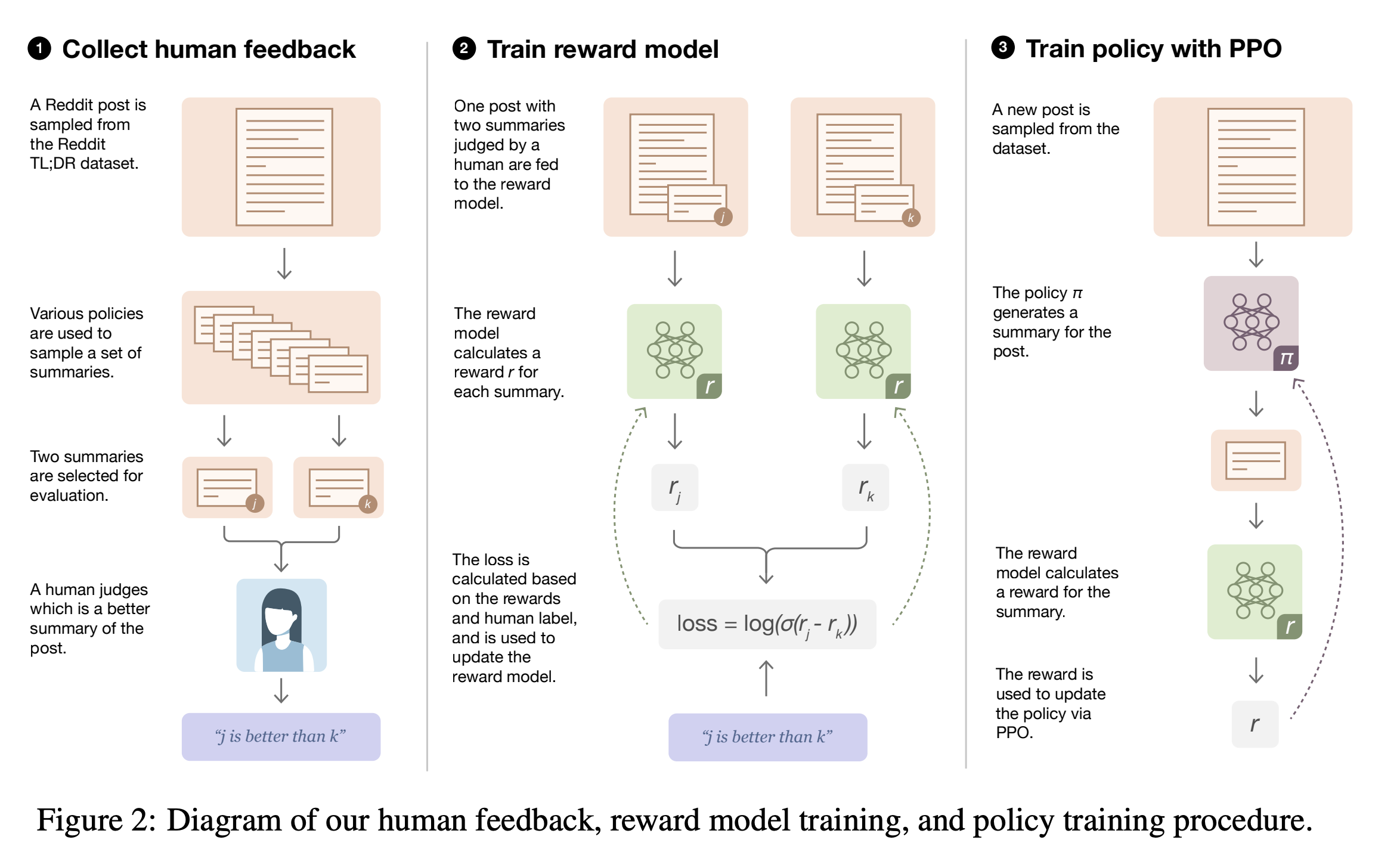
기존 요약 모델은 supervised learning으로 학습하고 있었다. 하지만 이렇게 되면 실제로 학습하는 것과 우리가 원하는 것에 간극이 존재한다. 실제로 학습하는 것: maxizing likelihood of human-written text 우리가 원하는
2026년 1월 31일
4.[쉬운 리뷰] Qwen3 Technical Report 제대로 이해하기
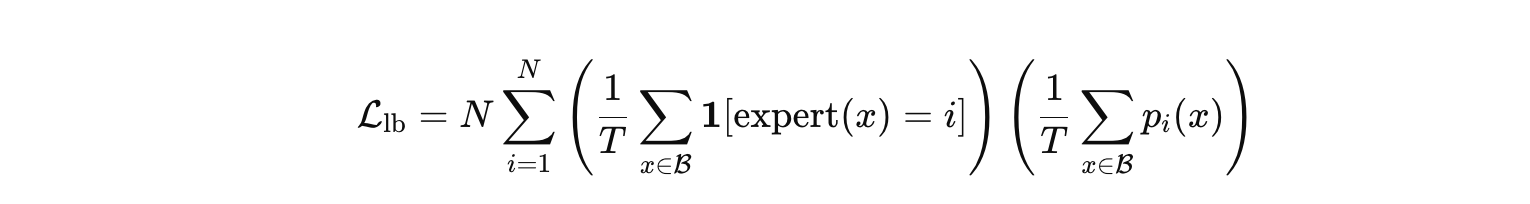
Qwen3는 pretraining 단계에서부터 reasoning 친화적인 데이터를 설계하고, post-training에서 Long-CoT Cold Start → Reasoning RL → Thinking Mode Fusion → General RL의 단계적 학습을 통해
2026년 3월 21일