RL을 이용한 prefernce tuning을 안정적으로 성공시킨 연구, OpenAI가 작성한 2022년 논문TL;DR
- 기존 RLHF 논문에서 한 발짝 더 나아간 논문
- 기존 대비 데이터 공수에 더 노력, 한 번에 많은 데이터를 모아서 학습
- Reward에도 KL term을 넣고, value/actor function 간의 parameter sharing을 끊어버림
- RL 학습은 PPO (PPO 리뷰 블로그 읽으러가기)
1. Motivation
기존 요약 모델은 supervised learning으로 학습하고 있었다. 하지만 이렇게 되면 실제로 학습하는 것과 우리가 원하는 것에 간극이 존재한다.
- 실제로 학습하는 것: maxizing likelihood of human-written text
- 우리가 원하는 것: high quality output as determined by human
이런 misalignment는 몇 가지 심각한 문제를 지니고 있다.
- 모든 토큰의 오류를 동일하게 취급하여, Error의 중요도를 구분하지 못한다.
치명적인 오류 (=hallucination)와 사소한 오류 (=동의어 선택)를 구분하지 못함 - 저품질 데모까지 모방
MLE는 요약의 품질이 어떻든 다 모방함 - Sampling 과정의 distributional shift
학습이 끝난 모델은 의 분포를 가지고 있지만, 추론 시 sampling을 () 통해 토큰을 출력. 이 차이로 인해서, 한 번 실수하면 토큰 분포가 급격히 붕괴하여 품질이 악화. (실수한 순간부턴 가 아니기 때문.) - 평가 metric의 한계
ROUGE, BLEU 같은 점수는 인간이 느끼는 요약 품질과 상관이 낮아서, 종종 반복 혹은 undesirable 결과를 출력할 때가 있다.
그래서 이 논문은 human preference를 직접 최적화 하는 학습 프레임워크(RLHF)를 제안하며 아래 두 가지를 보인다.
1. RLHF로 학습한 모델이 기존 baseline 대비 성능이 뛰어남
2. Supervised 모델보다 새로운 도메인에 더 generalize를 잘함
2. Background
가장 유사한 연구로 Fine-Tuning Language Models from Human Preferences를 짚는다. 이 논문은 2019년에 OpenAI가 작성한 논문으로, 이번 논문에서 짚은 가장 큰 한계점 & 차이점은 아래와 같다.
작은 batch, 빠른 online iteration으로 낮은 데이터 품질, 학습 안정성이 문제
-> 데이터 품질을 관리(큰 batch, 느린 iteration)하고, 알고리즘적으로 학습 안정성(value/policy network 분리 등)을 높이자.
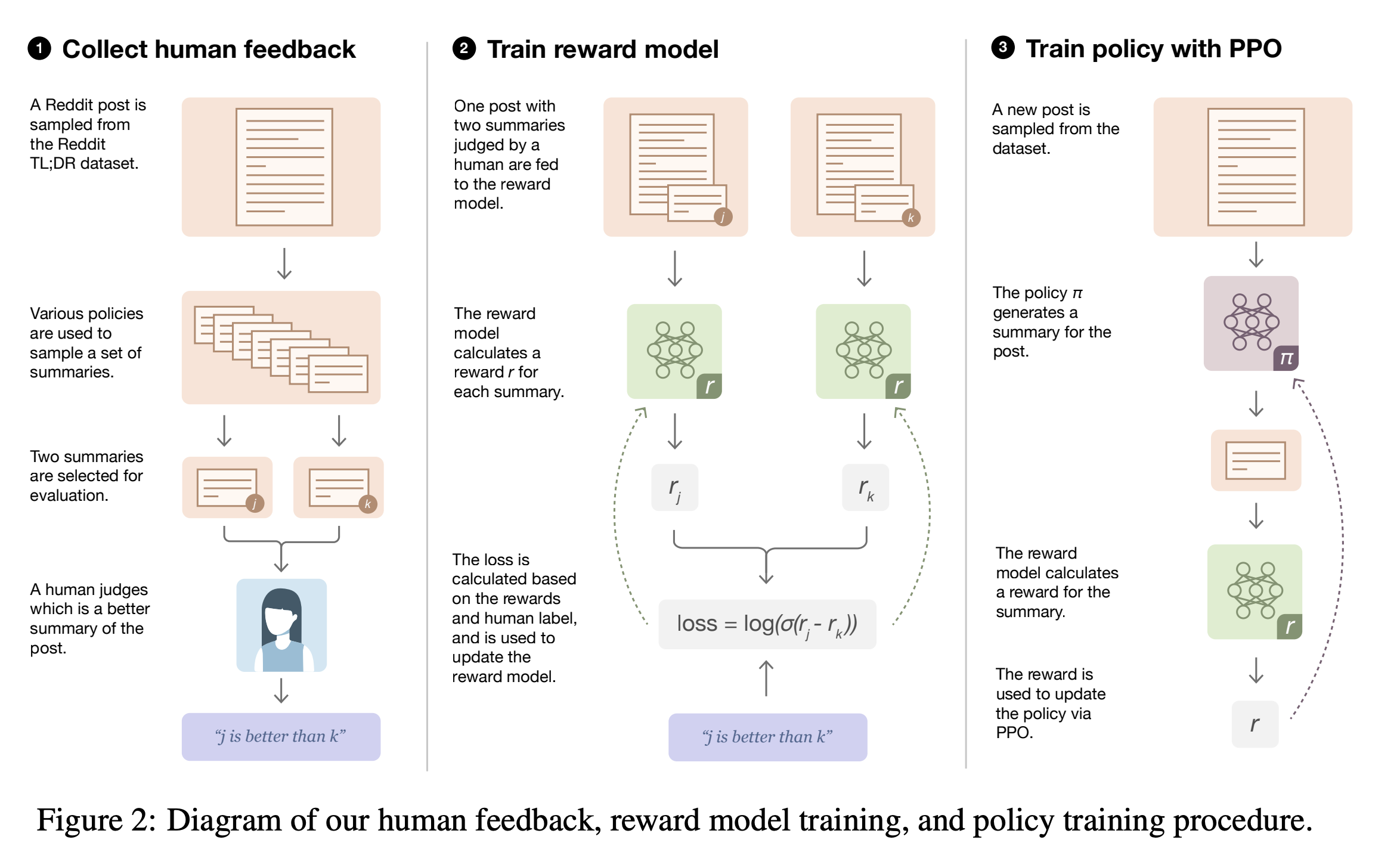
3. Method
3.1 Overview
대략적인 flow는 아래와 같다고 한다.
-
initial policy 학습
정제된 (post, summary) dataset으로 supervised learning으로 language model finetuning -
human feedback 수집
다양한 summary (initial, trained policy로부터 샘플링된, 혹은 human written 까지)를 labler에 전송하여 preference labeling -
reward model 학습
좋은 샘플과 나쁜 샘플의 logit의 상대적인 차이를 키우도록 학습 -
PPO 학습
post 가져와서 summarize -> reward 측정 -> Policy Gradient Objective maximize
3.2 Dataset
-
원 데이터: Reddit의 TL;DR 요약 데이터(약 300만 post, 다양한 게시판)
-
일반인이 이해 가능한 게시판만 사용
-
사람 작성 TL;DR 요약 길이가 24–48 tokens인 post만 남김
요약 품질을 사람에게 비교시키면 “더 길면 정보가 더 많아 보여서” 선호하는 경향이 경험적으로 보여졌기 때문. 모델이 “품질”이 아니라 길이 늘리기로 reward를 먹는 confound(혼입 요인) 가 커지는 것을 방지하기 위해서
=> 최종 데이터: 123,169 posts, 약 5% validation holdout.
3.3 Models
- 사용한 모든 모델은 GPT-3 계열과 동일한 Transformer decoder 구조
- 인간 피드백 기반 요약 실험은 1.3B 및 6.7B 파라미터
Pretrained models
대규모 텍스트 코퍼스에서 autoregressive next-token prediction으로 사전학습된 언어모델을 baseline으로 시작
- 이 pretrained 모델은 요약 태스크에 대해 별도의 fine-tuning 없이도 사용할 수 있음
- 이후 평가 시 zero-shot baseline을 사용할 때는 타 모델과의 형평성을 위해 입력 컨텍스트에 데이터셋 내 고품질 요약 예시를 padding하여 in-context 방식으로 평가
Supervised baselines (SFT)
- 입력: Reddit post
- 출력: human-written TL;DR summary
이 되도록 학습. 즉, supervised objective =
이 supervised 모델은 3.1에서 이야기한 initial policy이며 아래와 같은 역할을 한다:
- human feedback 수집 위한 초기 요약 샘플 생성
- policy 및 reward model 초기화
- evaluation baseline 제공 (zero-shot baseline)
최종 human evaluation에서는 sampling temperature를 으로 고정 (nucleus sampling이나 높은 temperature보다 더 좋은 성능을 보였기 때문)
Reward models (RM)
Reward model은 인간 선호를 예측하는 스칼라 함수
-
inital policy 로드
-
randomly initialized linear head를 추가하여 summary quality score를 출력
-
Reward model은 post 와 두 개의 요약 후보 가 주어졌을 때,
사람이 더 선호한 요약을 맞추도록 학습
() -
학습이 끝난 후 reference summaries의 score가 평균적으로 0이 되도록 normalize
수치적 안정성을 위해서라고 한다.
사견; 4번이 practical한 킥인 것 같다.
Human feedback policies (RL policy)
Reward model을 이용해, 인간이 더 선호하는 요약을 생성하는 policy를 학습한다.
- reward model output을 요약 전체에 대한 reward로 간주
- 이를 최대화하도록 PPO 알고리즘으로 정책을 최적화
- time step은 BPE token 단위
KL Term
이때 Reward model만 최적화하면 policy가 RM의 분포 밖으로 drift하거나 exploit할 위험이 있다. 따라서 논문은 supervised baseline policy 와의 KL divergence penalty를 reward에 포함한다.
최종 reward는
이 KL 항은 두 가지 목적을 가진다:
- Entropy bonus처럼 작동하여 탐색을 유도하고 mode collapse를 방지
- Policy가 reward model이 학습된 분포에서 과도하게 벗어나지 않도록 제한
Value function
PPO에서 value function은 policy와 완전히 분리된 별도의 Transformer로 학습한다.
- policy/value 파라미터 공유 없음
- value 업데이트가 pretrained policy를 초기에 파괴하는 것을 방지
Value network는 reward model의 파라미터로 초기화된다.
최종 정리
- Reward model 점수 는 summary 전체가 생성된 뒤 terminal reward로 한 번만 주어지며, intermediate step에서는 KL penalty가 per-token shaping reward처럼 누적된다. 구체적으로,
-
Value function은 각 token step에서 return target을 맞추도록 MSE regression으로 학습된다.
-
이때, reward에 들어가는 KL term은 PPO optimize 할 때 사용되는 adaptive KL penalty와는 별도로 존재하는 term이다.
4. Evaluation
4.1 Summarizing Reddit Posts from Human Feedback
Human Feedback + PPO는 Supervised Fine-tuning보다 훨씬 우수
-
인간 선호 기반 RL(PPO)로 학습한 요약 모델은 supervised fine-tuning 모델보다 더 좋은 요약을 생성함.
-
1.3B human-feedback 모델이 10배 큰 supervised 모델보다 더 선호됨
-
6.7B human-feedback 모델은 더 강력하며, 인간 reference summary보다도 더 선호됨
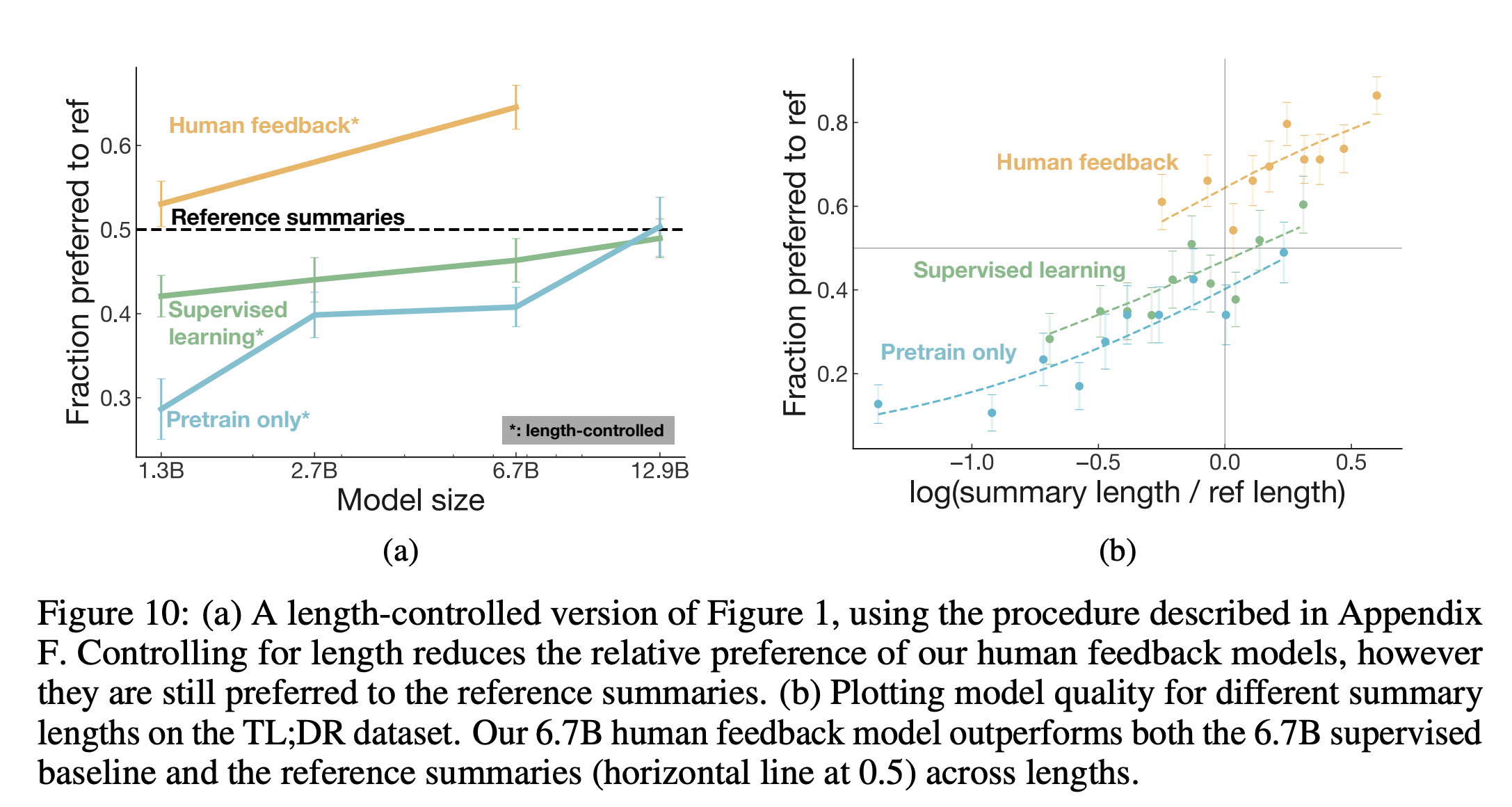
Length confound 통제 후에도 효과 유지
- PPO 모델은 더 긴 요약을 생성하는 경향이 있어 length bias 가능성이 있음
- 길이를 통제하면 preference가 약 5% 감소
- 그래도 여전히 reference보다 약 65% 선호됨
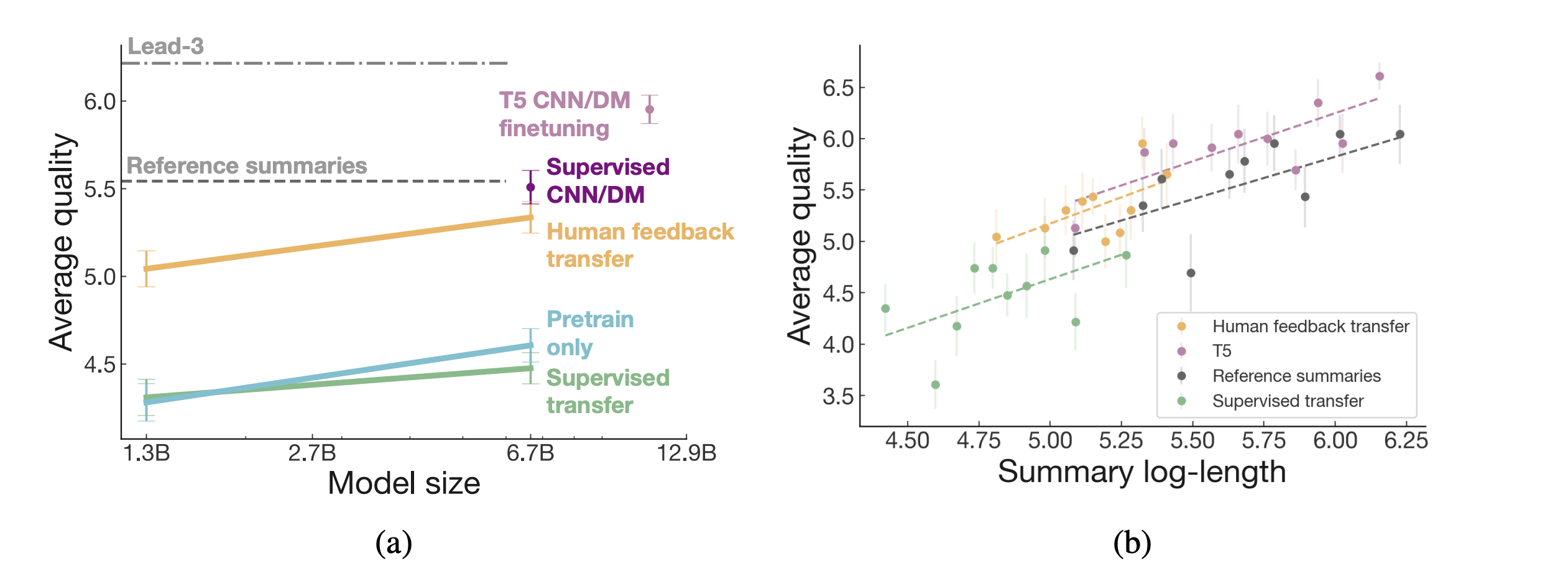
4.2 Transfer to Summarizing News Articles (CNN/DailyMail)
- Reddit TL;DR로 학습한 human-feedback 모델이 CNN/DM 뉴스 요약에서도 매우 잘 작동함.
- TL;DR supervised 모델보다 훨씬 뛰어나고, CNN/DM 전용 fine-tuning 모델(T5)과 거의 비슷한 수준
- 이때 완전히 이기진 못한 이유는 (b)에서 나오는데, summary length를 짧게 하기 때문이라고 함
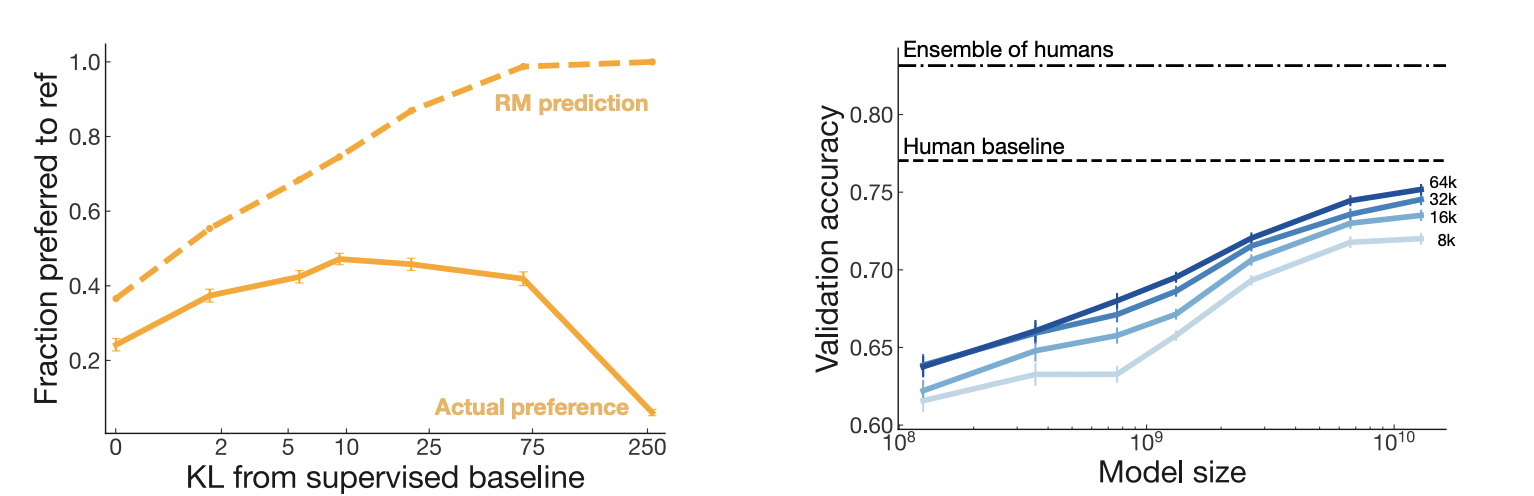
4.3 Understanding the Reward Model
Reward Model을 너무 최적화하면 Over-optimization 발생
-
Reward Model(RM)을 PPO로 최대화하면 처음에는 실제 요약 품질이 개선됨
→ 인간 선호도도 함께 상승 -
그러나 optimization strength를 계속 키우면(= KL penalty β를 약하게 하면):
- RM 점수는 계속 올라가지만
- 인간이 평가하는 실제 품질은 오히려 떨어지기 시작함
-
결국 policy는 “좋은 요약”을 만드는 대신 Reward Model의 허점을 exploit하는 방향(reward hacking) 으로 학습하게 됨
-
Figure 5에서 관찰되는 현상:
- 약한 최적화 구간: 인간 선호 ↑
- 강한 최적화 구간: 인간 선호 ↓
- 심하면 RM 예측과 인간 선호가 반대로 가는 anti-correlation 발생
-
논문은 이 문제가 learned reward만의 한계가 아니라
ROUGE 같은 자동 metric 최적화에서도 동일하게 나타난다고 지적함
(metric을 직접 maximize하면 결국 metric gaming이 발생)
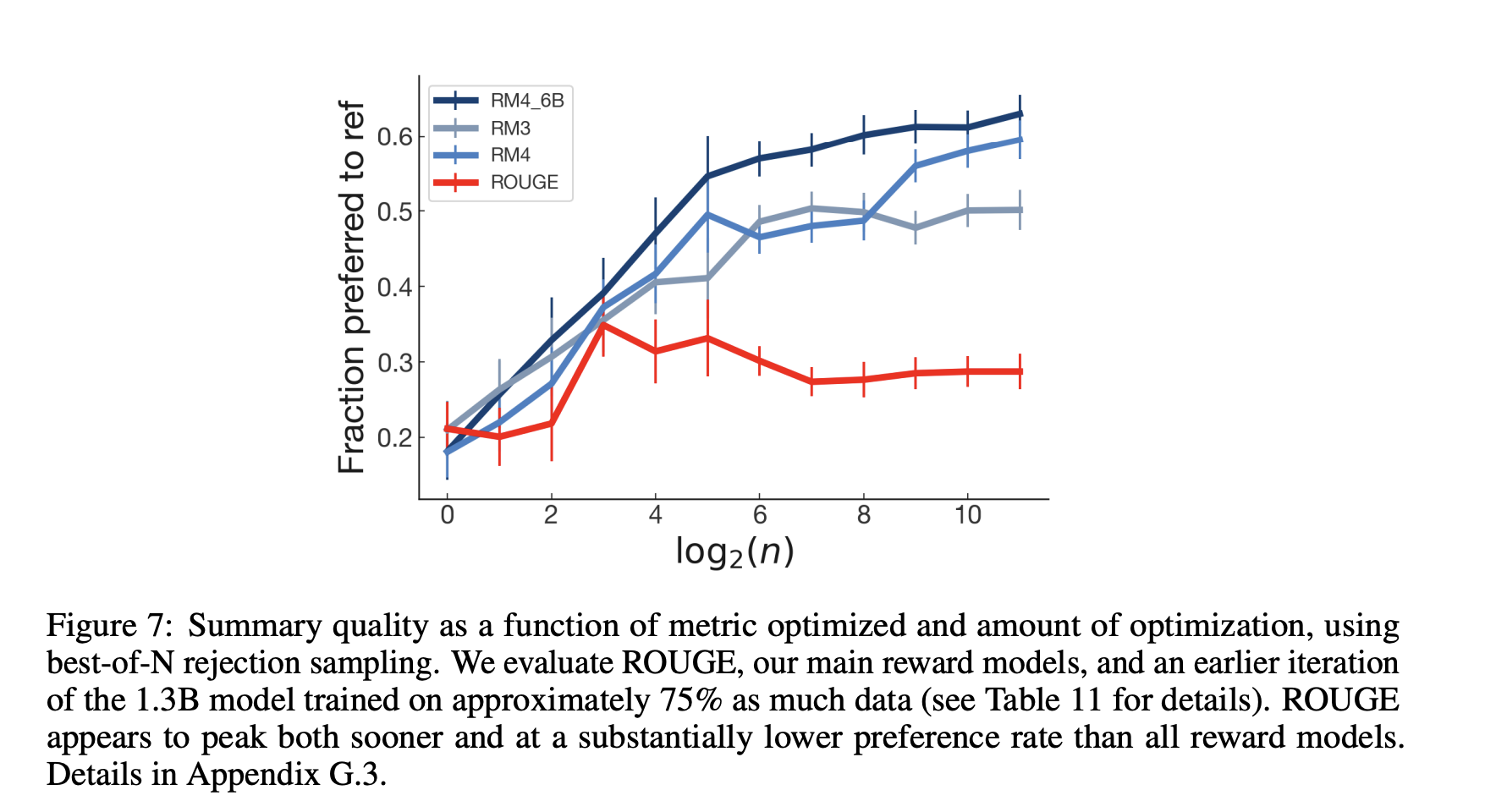
4.4 Analyzing Automatic Metrics for Summarization
Reward Model이 ROUGE보다 인간 선호를 훨씬 잘 예측함
비교한 metric들:
- ROUGE, Length, Copying ratio, Log-probability under supervised model, Reward Model score
결론: ROUGE 최적화는 quality를 올리지 못함
- Reward Model이 항상 인간 판단과 가장 잘 일치
- ROUGE는 policy가 좋아질수록 correlation이 깨짐
- quality가 일정 지점에서 peak 후 하락
반면 reward model 최적화는 더 높은 quality까지 유지됨
사견; 논문의 motive 중 하나였던 automatic metric의 한계를 잘 보완한 점이 돋보임
Evaluation 정리
- PPO + Human Feedback는 supervised summarization을 크게 능가함
- 인간 reference summary보다도 더 선호되는 요약 가능
- Reward Model은 강력하지만 과최적화하면 reward hacking 발생
- ROUGE 같은 자동 metric은 인간 품질을 제대로 반영하지 못함
- Reward modeling은 scaling 가능하며 transfer도 잘 됨
Ref
