LLM 오픈소스 진영의 한 줄기 빛 QwenTL;DR
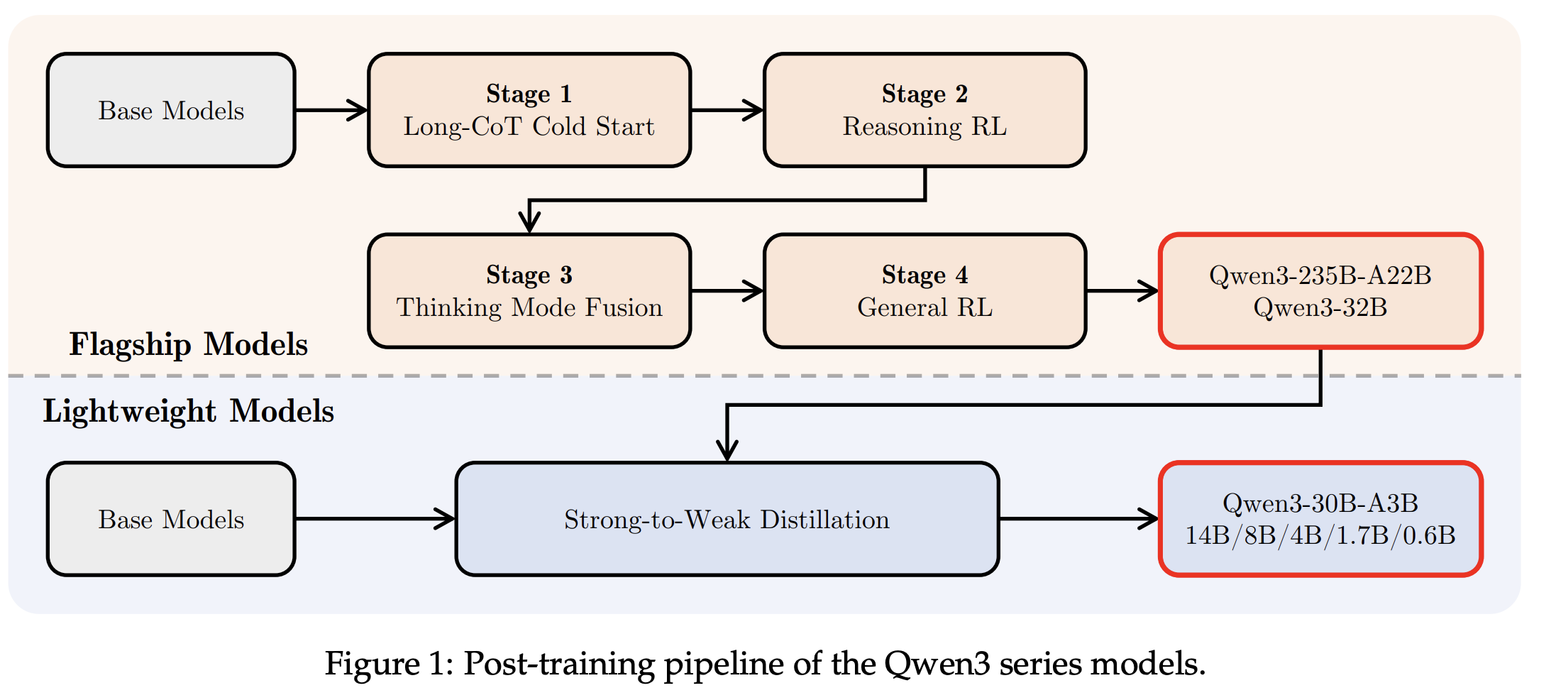
- Qwen3는 pretraining 단계에서부터 reasoning 친화적인 데이터를 설계하고, post-training에서 Long-CoT Cold Start → Reasoning RL → Thinking Mode Fusion → General RL의 단계적 학습을 통해 추론 능력을 구축한다.
- MoE 구조에서는 128개의 expert 중 8개만 활성화하며 Qwen2.5와 달리 shared expert를 제거하고 global-batch load balancing loss를 통해 expert 활용 균형과 specialization을 달성한다.
- 작은 모델은 동일한 RL 파이프라인을 반복하지 않고 teacher logits을 활용한 distillation으로 학습 (off-policy) 후 on-policy로 직접 RL tuning 한다.
1. Introduction
최근 LLM은 크게 두 방향으로 발전해왔다. 하나는 빠르고 실용적인 일반 instruct 모델이고, 다른 하나는 복잡한 문제 해결 능력을 갖춘 reasoning 모델이다. 전자는 응답 속도와 사용자 경험에서 강점을 가지지만 깊은 추론에서는 한계를 보이고, 후자는 높은 정확도를 보이지만 latency와 비용이 크게 증가한다.
Qwen3는 이 두 방향을 통합하려는 시도를 한다. 핵심 아이디어는 단순하다. 모델을 나누는 대신, 하나의 모델이 상황에 따라 reasoning을 수행하거나 생략하도록 만들 수 있다면 더 효율적이라는 것이다. 이를 위해 Qwen3는 thinking / non-thinking 모드를 하나의 모델 내부에 통합하고, 추가적으로 thinking budget을 통해 inference 단계에서 계산량과 성능을 직접 제어할 수 있도록 설계한다.
이 논문의 핵심은 단순한 성능 개선이 아니라, reasoning을 “별도의 모델”이 아닌 “제어 가능한 기능”으로 재정의한 데 있다.
2. Model Architecture
2.1) Overview
Qwen3는 Dense 모델과 MoE 모델 둘 다 release 했다. Dense 모델은 0.6B부터 32B까지 다양한 크기로 구성되며, MoE 모델은 30B-A3B와 235B-A22B 두 가지가 제공된다. 특히 235B 모델은 전체 파라미터는 매우 크지만, 실제로는 token당 22B만 활성화되기 때문에 효율성을 확보한다.
Dense 구조는 기존 Transformer 계열을 기반으로 하지만, 몇 가지 안정화 기법이 적용되어 있다. GQA, SwiGLU, RoPE, RMSNorm을 사용하며, QKV bias 제거와 QK-Norm 도입을 통해 attention 계산의 안정성을 개선한다. 이는 대규모 모델에서 학습 안정성과 성능을 동시에 확보하기 위한 선택으로 해석할 수 있다.
2.2) MoE
MoE 구조는 이 논문에서 특히 중요한 부분이다. Qwen3의 MoE는 128개의 expert를 두고, 각 token마다 8개의 expert만 활성화한다. 중요한 설계 선택은 shared expert를 제거했다는 점과 global-batch load balancing loss를 사용했다는 점이다. 이 loss는 아래처럼 생겼고, 왼쪽 항은 배치 내에서 expert_i가 선택된 비율이고 오른쪽 항은 실제로 모델이 준 평균적인 확률값이다. 이게 최소가 되려면 둘 다 uniform이어야한다.
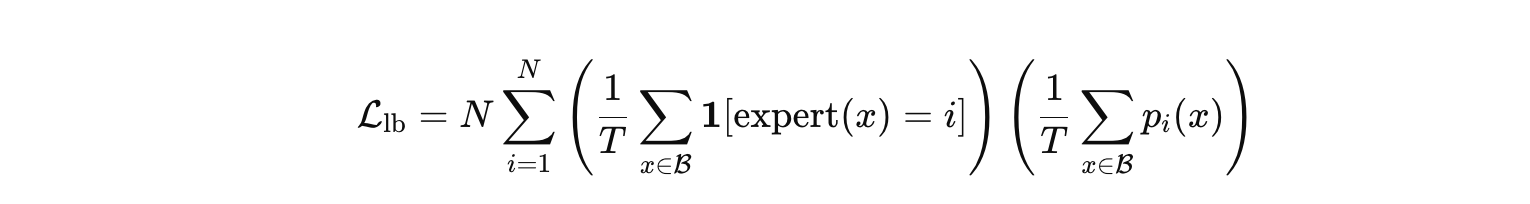
왜 이런 loss를 사용했을까? MoE의 일반적인 문제로 일부 expert로 routing이 몰리는 현상이 있다. 이 경우 특정 expert는 과부하 상태가 되고, 다른 expert는 거의 사용되지 않으면서 사실상 죽어버린다. Qwen3는 이를 해결하기 위해 batch 전체 수준에서 expert 사용을 균형 있게 유지하도록 하는 loss를 도입한다. 이 접근은 단순히 균형만 맞추는 것이 아니라, 각 expert가 특정 영역에 specialization되도록 유도한다. 결과적으로 MoE는 계산 효율뿐 아니라 representation 측면에서도 이점을 갖게 된다.
3. Pre-training Data
Qwen3의 reasoning 능력은 post-training에서 갑자기 생기는 것이 아니라, pretraining 단계에서부터 이미 설계된다. 전체 학습 데이터는 약 36T tokens 규모이며, 119개 이상의 언어와 다양한 도메인을 포함한다. 이 데이터는 단순한 웹 텍스트를 넘어 coding, STEM, reasoning task, books, multilingual text, 그리고 synthetic data까지 포함한다.
특히 주목할 점은 데이터 생성 방식이다. Qwen3는 PDF 형태의 문서를 활용하기 위해 Qwen2.5-VL을 사용해 텍스트를 추출하고, 이를 다시 Qwen2.5로 정제한다. 이를 통해 기존 웹 데이터보다 정보 밀도가 높은 문서를 대규모로 확보한다. 또한 Qwen2.5, Qwen2.5-Math, Qwen2.5-Coder를 활용해 textbook, QA, instruction, code 등 다양한 형태의 synthetic 데이터를 생성한다. 이 과정은 단순한 데이터 증강이 아니라, reasoning에 필요한 구조적 지식을 강화하는 역할을 한다.
개인적으로 LLM을 만들기 위해 LLM을 활용하는게 이질감이 들었다.4. Pre-training Stages
Qwen3의 pretraining은 세 단계로 나뉜다.
첫 번째 General Stage에서는 약 30T 이상의 토큰을 사용하여 일반적인 언어 능력과 세계 지식을 학습한다. sequence length는 4096으로 설정되며, foundation model의 기본 능력을 형성하는 단계다.
두 번째 Reasoning Stage는 이름 때문에 instruction tuning처럼 보일 수 있지만, 실제로는 continuation pretraining이다. 이 단계에서는 약 5T의 고품질 토큰을 추가로 학습하며, STEM, coding, reasoning, synthetic 데이터의 비중을 의도적으로 높인다. 즉, 모델이 더 많은 추론 관련 분포를 보도록 하여 내부 prior를 reasoning 방향으로 이동시키는 것이 목적이다. 이는 supervised instruction tuning이 아니라 여전히 next-token prediction 기반 학습이다.
세 번째 Long Context Stage에서는 sequence length를 32K까지 확장한다. RoPE scaling, ABF, YaRN, Dual Chunk Attention과 같은 기법을 사용해 긴 문맥에서도 안정적으로 동작하도록 만든다. 이 단계는 단순히 context 길이를 늘리는 것이 아니라, 실제로 long-context reasoning이 가능하도록 모델을 조정하는 단계다.
5. Post-training Overview
Post-training은 Qwen3의 핵심이다. 이 단계는 reasoning 능력을 실제로 강화하고, 이를 하나의 모델로 통합하며, 최종적으로 실용적인 모델로 만드는 과정이다.
전체 흐름은 Long-CoT Cold Start, Reasoning RL, Thinking Mode Fusion, General RL의 네 단계로 구성된다. 이후 작은 모델은 distillation을 통해 효율적으로 학습된다.
5-1. Long-CoT Cold Start
이 단계의 목적은 reasoning 성능을 최대화하는 것이 아니라, 모델에 기본적인 reasoning 패턴을 심는 것이다. 데이터는 수학, 코드, 논리 문제 등 검증 가능한 문제들로 구성되며, 각 문제에는 reference answer나 test case가 포함된다.
데이터 필터링이 매우 중요한데, 검증이 어려운 문제, 너무 쉬운 문제, reasoning이 필요 없는 문제는 제거된다. 특히 “CoT 없이도 쉽게 풀리는 문제”를 제거하는 것이 핵심이다. 이는 모델이 shortcut에 의존하지 않도록 하기 위함이다.
또한 response도 필터링된다. 잘못된 답, 반복적인 출력, reasoning이 없는 답, 불일치한 설명 등은 제거된다. 이 과정을 통해 고품질 long-CoT 데이터만 남기고, 이를 기반으로 초기 SFT를 수행한다.
이 단계에서 중요한 점은 학습을 과하게 하지 않는 것이다. 목적은 최종 성능이 아니라 RL을 위한 좋은 초기 정책을 만드는 것이기 때문이다.
5-2. Reasoning RL
이 단계에서는 실제로 reasoning 능력을 크게 끌어올린다. 약 3,995개의 query-verifier pair가 사용되며, 각 문제는 충분히 어렵고 다양한 domain을 포함하도록 구성된다.
학습은 GRPO 기반으로 진행되며, 중요한 특징은 large batch, high rollout, off-policy training이다. 하나의 query에 대해 여러 개의 reasoning path를 생성하고, verifier를 통해 평가한 뒤 policy를 업데이트한다. 또한 entropy를 조절하여 exploration과 exploitation의 균형을 유지한다.
이 단계는 단순히 정답을 맞추는 것이 아니라, 다양한 reasoning 경로를 탐색하고 더 나은 추론 전략을 학습하는 과정이다.
5-3. Thinking Mode Fusion
Reasoning RL 이후의 모델은 reasoning은 잘하지만 일반적인 대화나 빠른 응답에는 적합하지 않다. Thinking Mode Fusion은 이 모델을 하나의 통합 모델로 만드는 단계다.
이 과정에서는 다시 supervised learning이 수행되며, 여기서 중요한 특징이 나타난다. Thinking 데이터는 외부에서 가져오는 것이 아니라, Stage 2 모델이 생성한 결과를 다시 사용한다. 구체적으로는 Stage 1 query에 대해 Stage 2 모델이 여러 답을 생성하고, 이를 rejection sampling으로 필터링한 뒤 supervised 데이터로 사용한다. 이는 reasoning 성능이 SFT 과정에서 망가지지 않도록 하기 위한 설계다.
반면 non-thinking 데이터는 coding, 수학, instruction following, multilingual, writing, QA, role-play 등 다양한 작업을 포함하는 별도의 curated 데이터셋으로 구성된다. 이 데이터는 모델이 빠르게 답변하는 능력과 일반적인 사용성을 학습하도록 만든다.
이 단계에서 /think와 /no think라는 명시적 제어 토큰이 도입되며, 모델은 두 모드를 모두 학습한다. 특히 non-thinking 모드에서도 <think></think> 블록을 유지하는 설계는 내부 구조를 일관되게 유지하면서 reasoning을 비활성화하기 위한 장치다.
이 과정을 통해 모델은 “생각하는 방식”과 “생각하지 않는 방식”을 언제/어떻게 사용해야할지 학습하게 되며, 결과적으로 inference 단계에서 thinking budget을 적용할 수 있는 기반이 형성된다.
5-4. Thinking Budget
Thinking Mode Fusion 이후 모델은 reasoning을 부분적으로 수행하다가 중단하고 답을 생성할 수 있는 능력을 갖게 된다. 이를 활용해 thinking budget이 구현된다.
동작 방식은 단순하다. reasoning token이 일정 길이에 도달하면, 시스템이 강제로 thinking을 종료하고 현재까지의 정보를 기반으로 답을 생성하도록 한다. 이런 식으로 강제로 주입한다고 한다.
Considering the limited time by the user, I have to give the
solution based on the thinking directly now.\n</think>.\n\n중요한 점은 이 과정이 단순한 truncation이 아니라, 모델이 중간 상태에서도 의미 있는 답을 생성할 수 있도록 학습되어 있다는 것이다. 즉, thinking budget은 단순한 계산 제한이 아니라, 부분적 reasoning 상태에서도 안정적으로 답을 생성하는 능력 위에 구축된 기능이다.
5-5. General RL
Reasoning RL 이후에도 추가적인 RL이 수행된다. 이 단계의 목적은 reasoning이 아닌, 실제 서비스에서 필요한 다양한 능력을 강화하는 것이다.
여기서 중요한 점은 “20개 task”가 별도로 순차 학습된 것이 아니라, 하나의 multi-task RL setting에서 동시에 학습된다는 것이다. 각 task는 서로 다른 데이터셋이라기보다는, 서로 다른 reward function으로 정의된다.
즉, 하나의 batch 안에는 다양한 task의 샘플이 섞여 있으며, 각 샘플은 해당 task에 맞는 reward function으로 평가된다. reward는 rule-based 방식, reference 기반 모델 평가, 그리고 human preference 기반 reward model을 통해 계산된다.
이 구조는 하나의 policy가 여러 reward distribution을 동시에 최적화하는 형태이며, sequential training에서 발생할 수 있는 catastrophic forgetting을 방지한다.
6. Distillation
작은 모델은 동일한 RL 파이프라인을 반복하지 않는다. 대신 distillation을 통해 학습된다.
첫 번째 단계인 off-policy distillation에서는 teacher 모델이 생성한 /think와 /no think 출력을 사용해 student 모델을 학습시킨다. 이를 통해 reasoning과 mode control 능력을 동시에 전달한다.
두 번째 단계인 on-policy distillation에서는 student가 직접 생성한 output을 teacher의 logits에 맞추도록 KL divergence를 최소화한다. 이 방식은 단순 imitation보다 더 높은 성능을 낼 수 있으며, RL보다 훨씬 적은 계산 비용으로 학습이 가능하다.
7. Experimental Results
많은 실험이 있었지만, 개인적으로 흥미있었던 실험만 정리했다.Qwen3는 단순히 구조적으로 흥미로운 모델이 아니라, 실제 benchmark에서도 매우 강력한 성능을 보인다. 특히 이 논문의 핵심은 특정 task에서의 최고 점수라기보다는, reasoning, coding, multilingual, 그리고 general capability까지 전반적인 영역에서 균형 있게 성능을 끌어올렸다는 점에 있다.
먼저 reasoning 성능을 보면, Qwen3의 개선이 가장 뚜렷하게 나타난다. AIME, MATH, Codeforces, GPQA와 같은 고난도 추론 벤치마크에서 모델은 기존 대비 큰 폭의 향상을 보인다. 이러한 결과는 논문의 Table 11 (thinking mode) 및 Table 12 (non-thinking mode)에서 확인할 수 있으며, Qwen3-235B-A22B 모델이 DeepSeek-R1 등 강력한 baseline을 다수의 benchmark에서 능가한다.
| Thinking mode | Non-thinking mode |
|---|---|
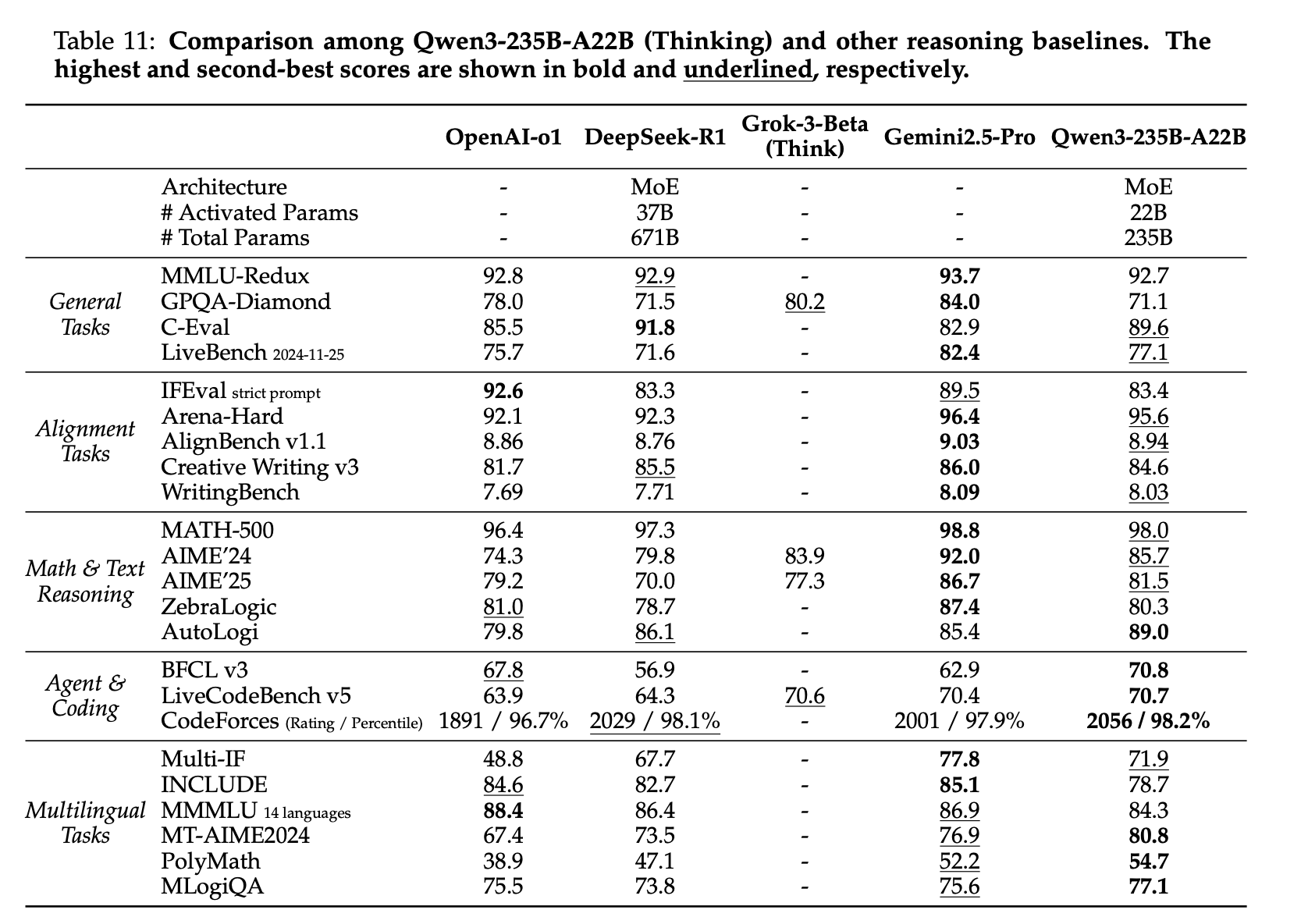 | 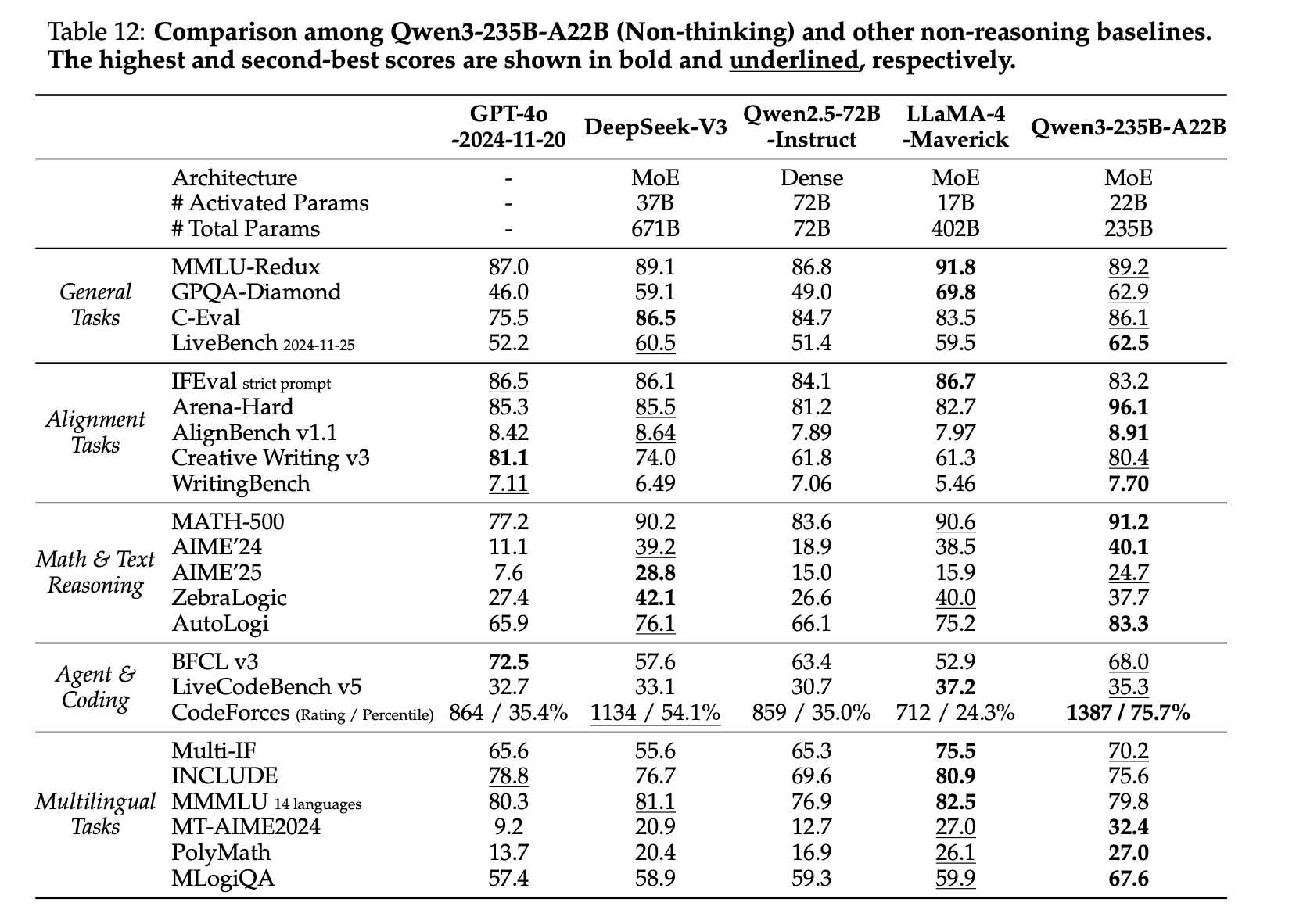 |
또한 reasoning RL의 효과는 학습 곡선에서도 명확하게 드러난다. 논문의 Figure 2에서는 thinking budget을 증가시킬수록 성능이 지속적으로 향상되는 scaling behavior를 확인할 수 있다. 이는 Qwen3가 reasoning depth를 통해 성능을 조절할 수 있음을 보여준다.
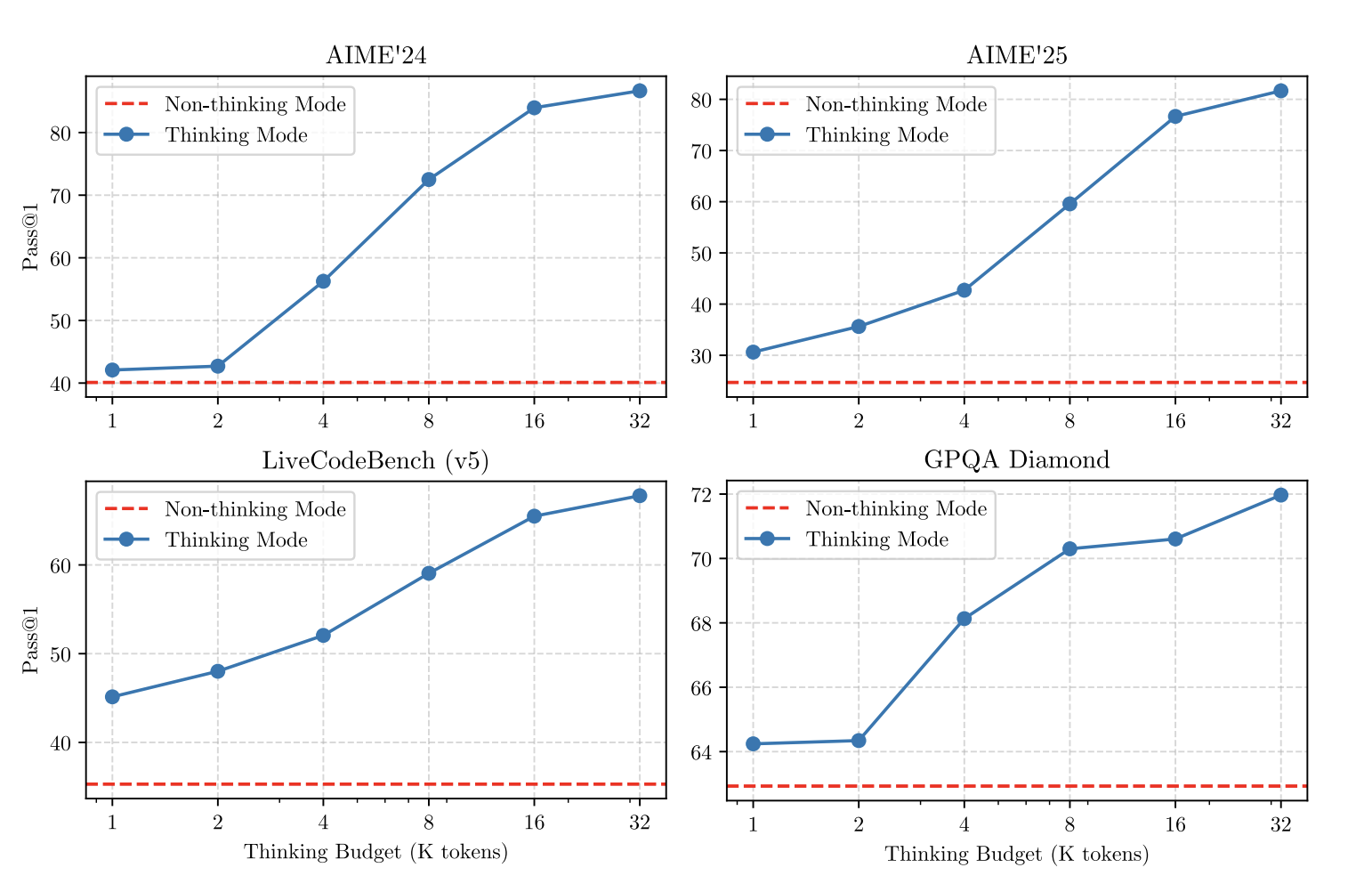
마지막으로 distillation의 효과는 small model에서 확인된다. Qwen3-8B 및 4B 모델의 결과는 Table 17 및 Table 18, Qwen3-1.7B 및 0.6B 모델의 결과는 Table 19 및 Table 20에 제시되어 있다. 이 결과는 distillation을 통해 작은 모델에서도 높은 성능을 유지할 수 있음을 보여준다.
| Table 17 | Table 18 |
|---|---|
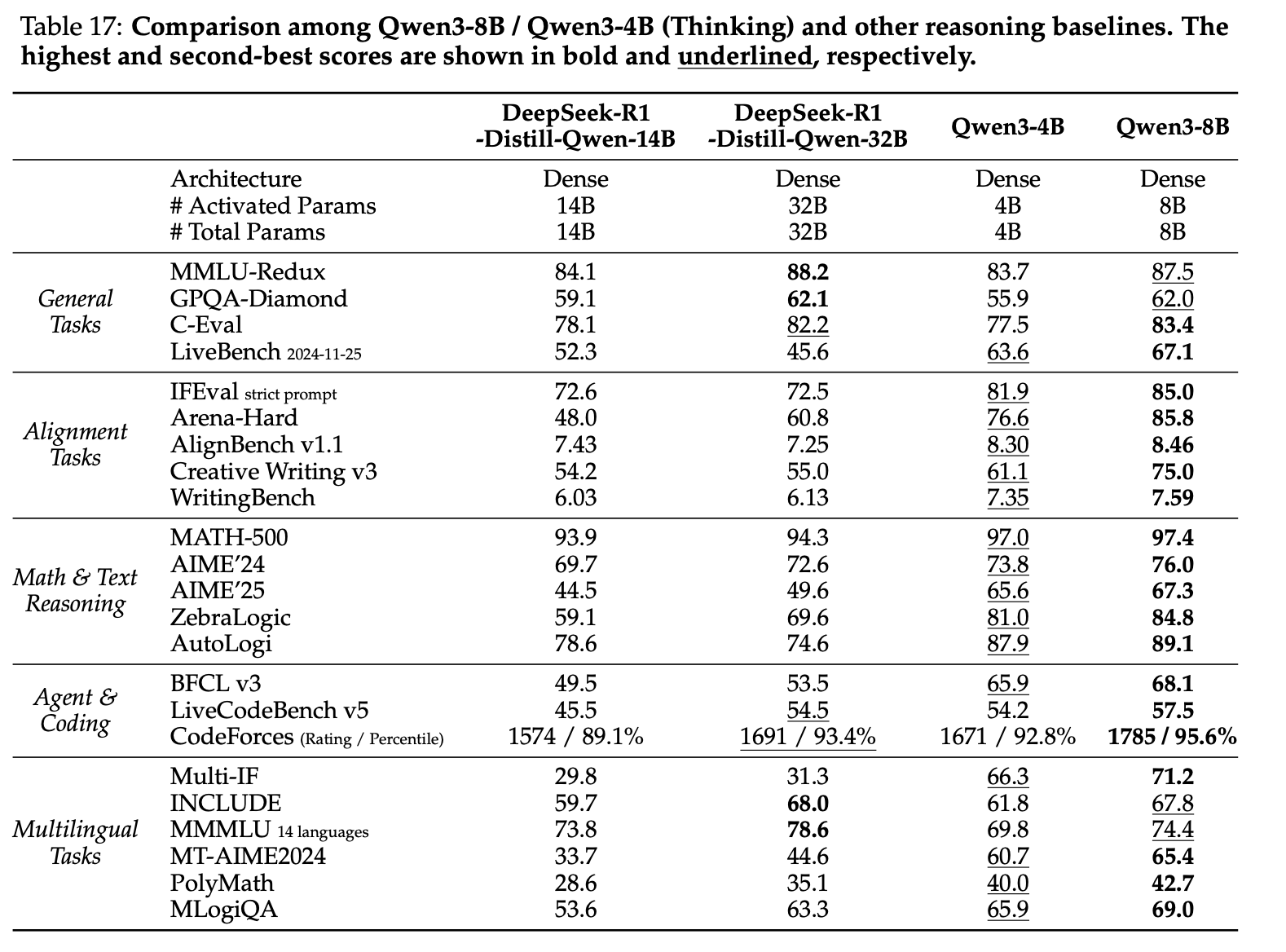 | 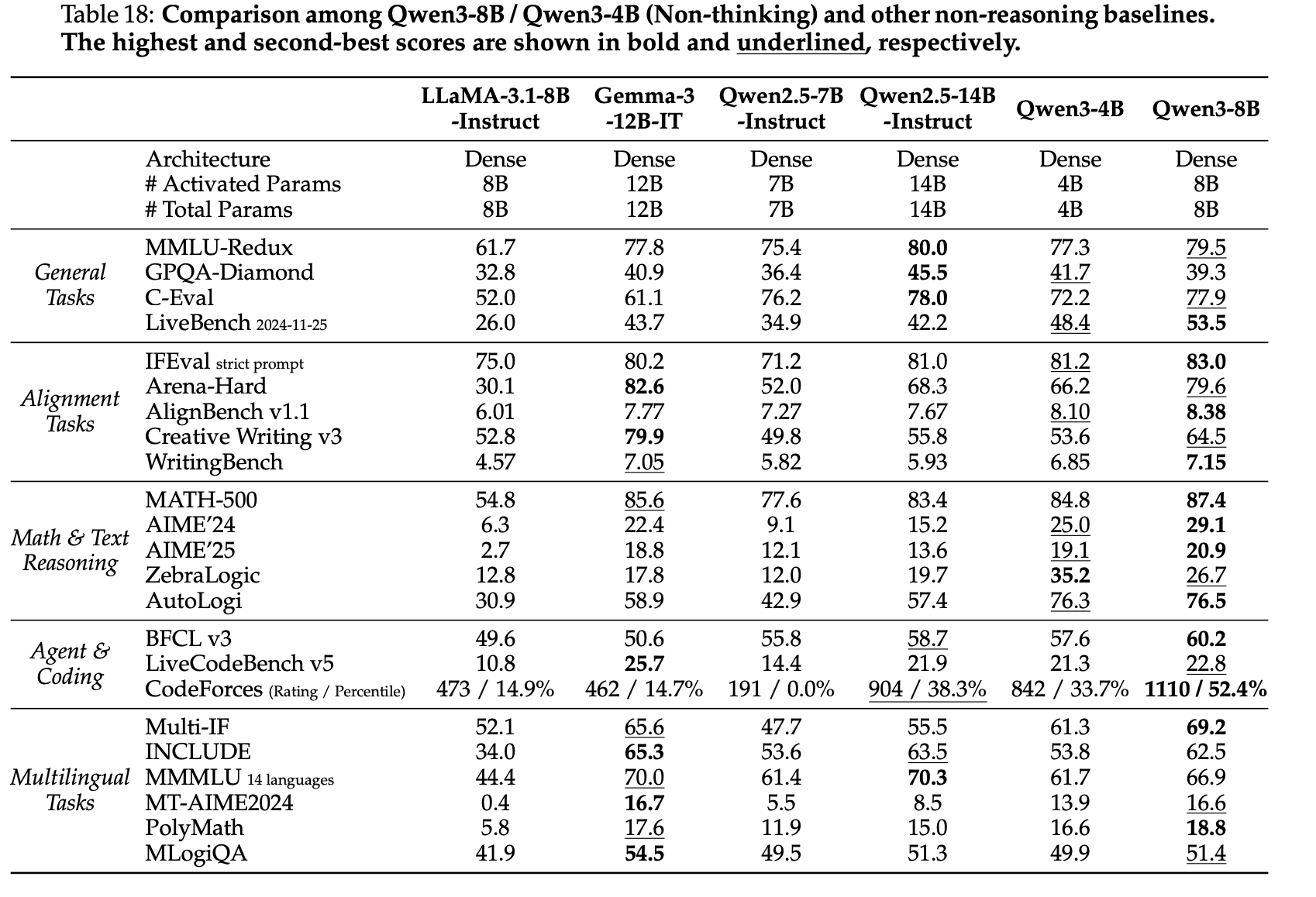 |
9. Conclusion
Qwen3는 단순히 성능이 좋은 모델이 아니라, reasoning 모델을 어떻게 설계하고 확장할 것인지에 대한 하나의 시스템을 제시한다. pretraining 단계에서 reasoning-friendly 분포를 형성하고, post-training에서 단계적으로 reasoning을 강화하며, 이를 하나의 모델로 통합한 뒤, distillation을 통해 효율적으로 확장한다. 결과적으로 Qwen3는 reasoning을 별도의 모델이 아닌, 제어 가능한 기능으로 전환한 모델이라고 볼 수 있다.
