8.6. 교착 상태 회피
스레드가 자원 요청을 할 때 미래에 발생 가능한 Deadlock이 있는지 확인한다.
이를 위해서는 자원이 어떻게 요청 되었는지에 대한 정보가 필요하다.
ex) R1, R2 2개의 자원을 갖는 시스템에서 스레드 P가 R1을 점유한 상태로 (R1→P) R2를 요청 (P→R2)하고, 스레드 Q는 R2를 점유한 상태로 (R2→Q) R1을 요청 (Q→R1)하는 상황
순환 구조가 발생하여 Deadlock이 발생할 위험이 있으므로 자원 요청을 거절 (reject)할 수 있다.
교착 상태 회피를 위한 필요한 사전 정보
필요한 자원의 최대 개수를 알면 “교착 회피 알고리즘”을 만들 수 있다.
“교착 회피 알고리즘”은 순환 대기 상황이 발생하지 않도록 자원 할당 상태를 검사한다.
→ 자원 할당 상태 : 사용 가능한(available) 자원의 수, 할당된(allocated) 자원의 수, 스레드들의 최대 요구 수(maximum demands)에 의해 정의된다.
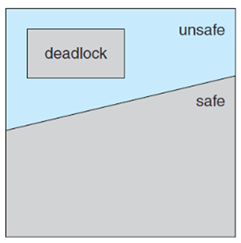
8.6.1. 안전 상태(Safe State)
시스템이 어떤 순서로든 스레드들이 요청하는 모든 자원을 DeadLock을 발생시키지 않고 차례로 모두 할당해줄 수 있는 것을 의미한다.
즉, 안전 순서(safe sequence)를 찾을 수 있다면 시스템은 안전하다.
→ <T1, T2, …, Tn> 스레드 순서가 안전하다는 것은
Ti가 요청하는 자원을 [시스템에 현재 남아있는 자원 + 수행을 마칠 모든 스레드] Tj들이 (j < i) 반납하는 자원들로 만족 시킬 수 있는 것이다.
- 안전 상태 → 데드락이 발생하지 않는다. [True]
- 데드락이 발생한다 → 불안전한 상태 [True]
- 불안전한 상태 → 데드락이 발생한다. [모름]
시스템이 안전 상태에 머무는 한 운영체제는 불안전상태 + Deadlock을 모두 회피할 수 있다.
Note:
-
회피 알고리즘은 시스템이 항상 안전 상태에 있도록 구현되어 Deadlock을 회피해야 한다.
-
시스템 초기에는 안전 상태에서 시작한다. (점유 대기를 수행하기 때문)
-
이후 자원 요청이 들어올 때마다 상태를 판단하여 자원을 할당할지, 할당하지 않을지 결정한다.
(시스템이 안전 상태에 있는 경우 자원 할당을 허용하고, 그렇지 않은 경우 요청을 거부한다.)
8.6.2. 자원 할당 그래프 알고리즘
Resource Type이 오직 1개의 인스턴스를 갖는다고 가정
예약 간선 (claim edge)
-
Ti → Rj : Pi가 미래에 자원 Rj를 요청할 것이라는 의미
-
간선의 방향은 요청 간선과 유사하지만 점선으로 표시한다.
-
예약 간선을 추가했을 때 순환구조가 없다면
→ 시스템은 안전 상태 이므로, 예약 간선을 요청간선으로 변환한다.
-
예약 간선을 추가했을 때 순환구조가 발생한다면
→ 시스템은 불안전 상태 이므로, 요청을 거부한다.
8.6.3. Banker’s Algorithm(은행원 알고리즘)
자원 할당 그래프(RAG)는 Resource Type에 여러 개의 인스턴스가 존재하면 사용할 수 없다.
은행원 알고리즘은 RAG에 비해 비효율이고 복잡하다.
Data Structure
n : 스레드의 개수, m : Resource Type의 개수
- Available[m]: 사용 가능한 자원을 나타내는 벡터 Available[j] == k -> Rj에서 k 개의 인스턴스가 사용 가능하다.
- Max[n x m] 스레드가 최대로 필요로 하는 자원의 개수를 나타내는 행렬 Max[i][j] == k -> 현재 스레드 Ti가 Rj에서 인스턴스를 최대 k개까지 요청할 수 있다.
- Allocation[n x m] 각 스레드에 현재 할당된 자원의 개수를 나타내는 행렬 Allocation[i][j] == k -> 현재 스레드 Ti가 Rj에서 인스턴스를 k개 사용 중이다.
- Need[n x m] 각 스레드가 향후 요청할 수 있는 자원의 개수를 나타내는 행렬 Need[i][j] == k -> 스레드 Ti가 향후 Rj에서 인스턴스를 k개까지 더 요청할 수 있다. Need[i][j] = Max[i][j] - Allocation[i][j]
8.6.3.1. 안전성 알고리즘(Safety Algorithm)
-
Work와 Finish는 크기가 m과 n인 벡터이다.
Work = Available로 초기 값을 준다.
i = 0, 1, …, n-1에 대해서 Finish[i] = false를 초기 값으로 준다.
-
아래 두 조건을 만족시키는 i 값을 찾는다.
- Finish[i] == false
- Need_i = Work
그러한 값을 찾을 수 없다면 step 4로 간다.
-
Work = Work + Allocation_i
Finish[i] = true
step 2로 간다.
-
모든 i 값에 대해 Finish[i] == true이면 이 시스템은 안전 상태에 있다.
→ 이 알고리즘으로 안전 여부를 알아내는 데에는 m x n**2개의 연산이 필요하다.
8.6.3.2. 자원 요청 알고리즘(Resource-Request Algorithm)
Request_i는 스레드 Ti의 요청 벡터이다.
Request_i[j] == k 라면 Ti가 Rj에서 인스턴스를 k개 요청하고 있음을 뜻한다.
-
Request_i ≤ Need_i이면 step 2로 간다.
아니면 스레드가 최대 요청 (maximum claim)을 넘어선 것이므로 오류로 처리한다. -
Request_i ≤ Available이면 Step 3 으로 간다.
아니면 요청한 자원이 당장은 없으므로 Ti는 기다려야 한다. -
시스템이 Ti에게 자원을 할당해준 것처럼 시스템 상태 정보를 아래처럼 바꾸어 본다.
Available = Available - Request_i
Allocation_i = Allocation_i + Request_i
Need_i = Need_i - Request_i
8.6.3.3. 예시(An illustrative Example)
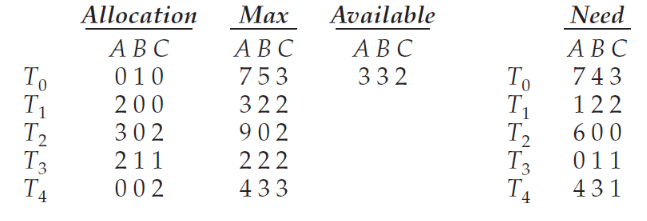
- 스레드 집합 : T = {T0, T1, T2, T3, T4}
- Resource Type의 집합 : R = {A, B, C}
- 인스턴스의 개수 : A = 10, B = 5, C = 7
- 현재 시스템 상태
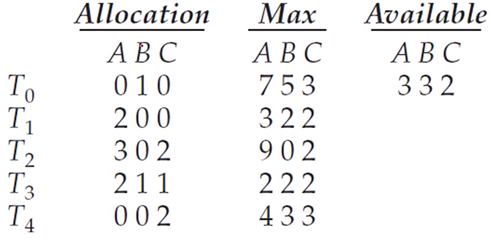
- Available = 인스턴스의 개수 - Allocation(할당)된 인스턴스의 개수 Allocation 상태를 확인했을 때 A의 합 = 7, B의 합 = 2, C의 합 = 5 이므로 Available한 인스턴스의 개수는 A : 10 - 7 = 3개, B : 5 - 2 = 3개, C : 7 - 5 = 2개
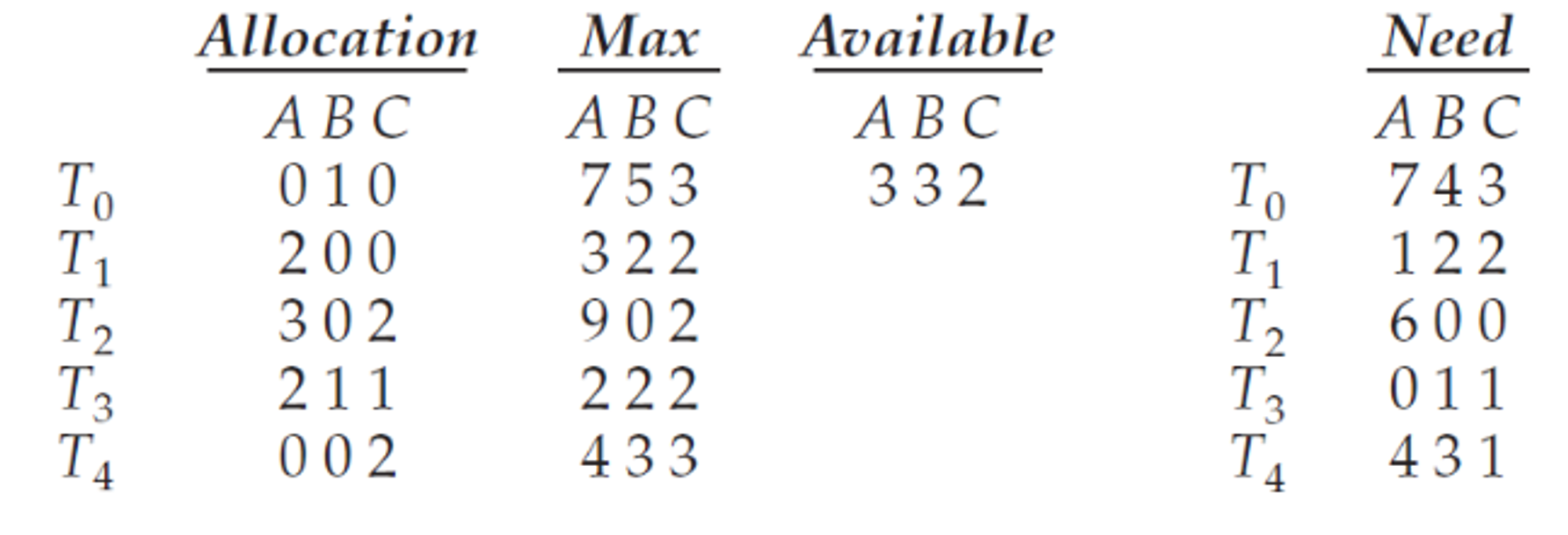
- Need = (Max - Allocation)
이제 Max는 필요 없으므로 아래의 표를 이용한다.
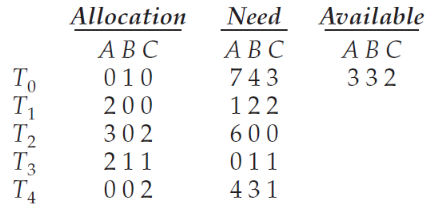
8.6.3.3. 예시(An illustrative Example) - 안전 알고리즘 수행
Work = Available = [3, 3, 2]
Finish(T0, T1, T2, T3, T4) =* [false, false, false, false, false ]
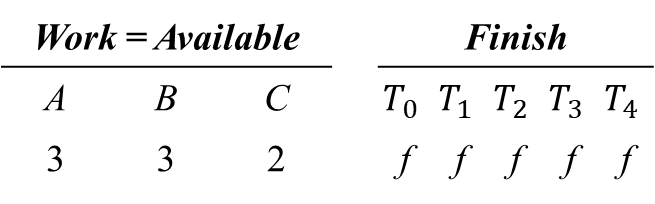
i = 0 ~ 4 범위 내에서 Finish[i] == false, Need_i ≤ Work인 i 값을 찾고
Work = Work + Allocation_i, Finish[i] = true 업데이트 후 재탐색
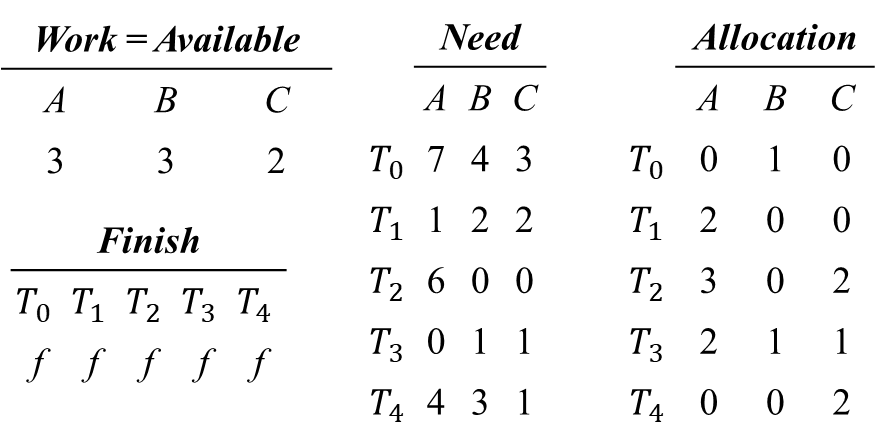
i = 0) Need_0 ≤ Work를 만족하지 않는다.
i = 1) Finish[1] = false, Need_1 ≤ Work를 만족하므로,
Work = Work + Allocation_1, Finish[1] = true 업데이트
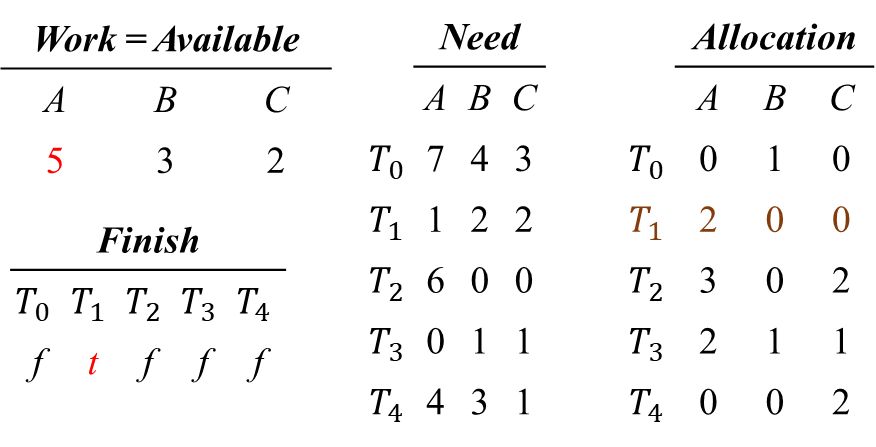
i = 2) Need_2 ≤ Work를 만족하지 않는다.
i = 3) Finish[3] = false, Need_3 ≤ Work를 만족하므로,
Work = Work + Allocation_3, Finish[3] = true 업데이트
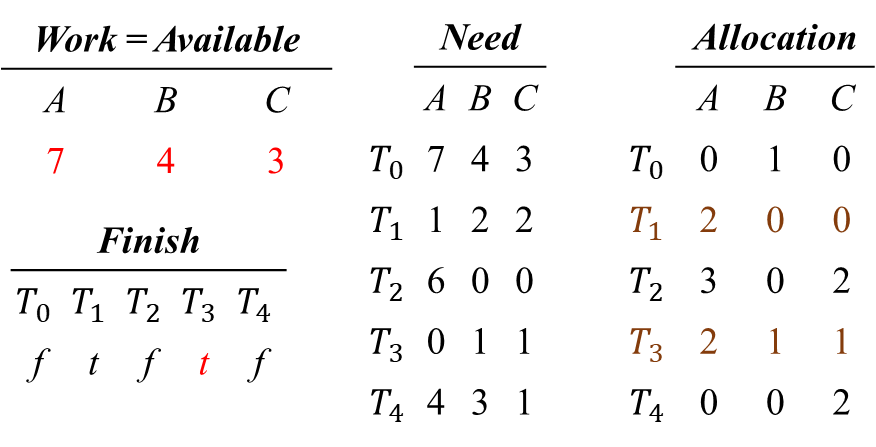
i = 4) Finish[4] = false, Need_4 ≤ Work를 만족하므로,
Work = Work + Allocation_4, Finish[4] = true 업데이트
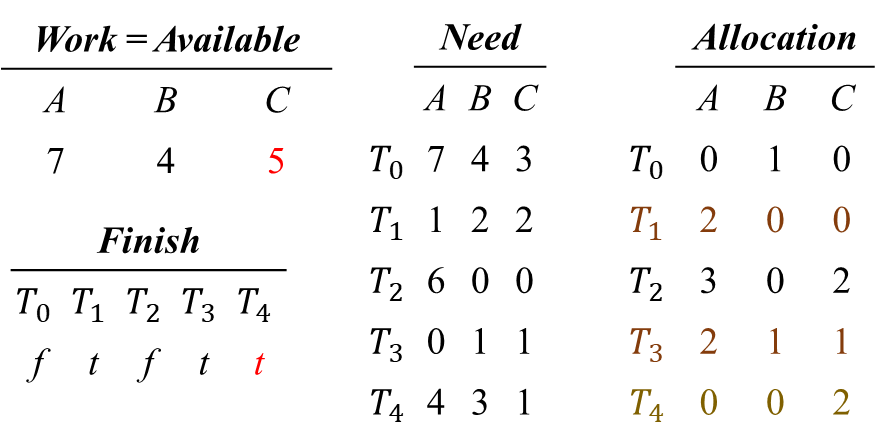
Finish가 false인 스레드를 다시 탐색한다.
i = 0) Finish[0] = false, Need_0 ≤ Work를 만족하므로,
Work = Work + Allocation_0, Finish[0] = true 업데이트
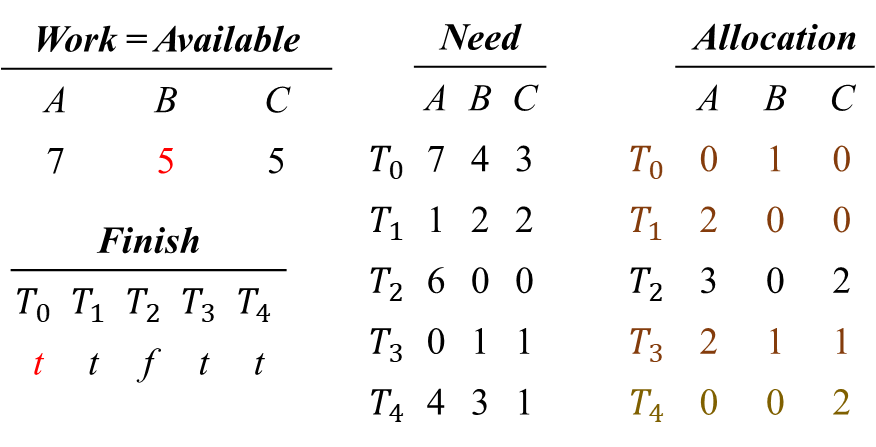
i = 2) Finish[2] = false, Need_2 ≤ Work를 만족하므로,
Work = Work + Allocation_2, Finish[2] = true 업데이트

최종적으로 Work = [10, 5, 7]
Finish(T0, T1, T2, T3, T4) = [true, true, true, true, true] 이므로
<T1 , T3, T4, T0, T2> 의 순서로 스레드를 실행하면 안전성이 보장된다.
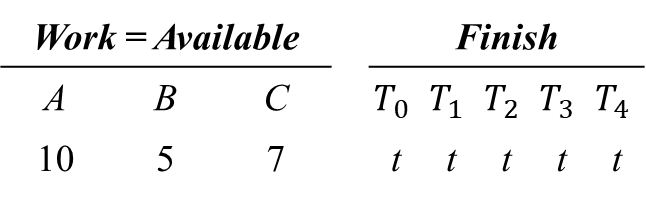
8.6.3.3. 예시(An illustrative Example) - 자원 요청 수
스레드 T1이 A자원 1개, C자원 2개를 추가로 요청
Request_1 = (1, 0, 2)
-
Request_i (1, 0, 2)≤ Need_i (0, 2, 0)
-
Request_i (1, 0, 2)≤ Available (2, 3, 0)
-
Allocation_i = Allocation_i + Request_i = (2,0,0) + (1,0,2) = (3, 0, 2)
Need_i = Need_i - Request_i = (1, 2, 2) - (1, 0, 2) = (0, 2, 0)
Available = Available - Request_i = (3, 3, 2) - (1, 0, 2) = (2, 3, 0)
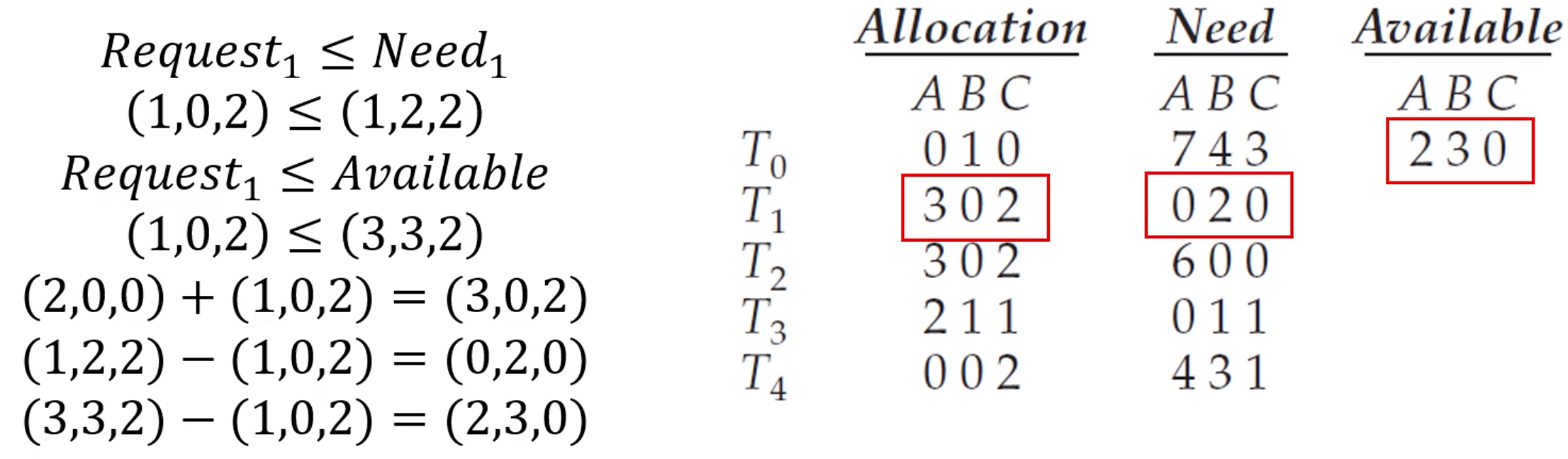
다시 정의된 상태가 안전한지 여부를 살펴보기 위해 안전성 알고리즘을 돌려보면
<T1, T3, T4, T0, T2>가 안전성 조건을 만족시킬 수 있다.
따라서, T1의 요청을 즉시 들어줄 수 있다.
8.7. Deadlock Detection(교착 상태 탐지)
Deadlock 방 or 회피 알고리즘을 사용하지 않는다면 Deadlock이 발생할 수 있다.
데드락 방지는 문제가 많고, 데드락 회피는 자원 요청이 들어올 때마다 수행하기에는 시스템 입장에서 부담스럽다.
(자원 요청을 수행했을 때 시스템 안전 상태일 지라도, 안전성 알고리즘을 무조건 수행해야하기 때문에 정말 중요한 시스템이 아니면 이용하지 않는다.)
따라서 데드락 발생을 허용하되, 지속적인 모니터링을 통해 데드락이 발생하면 즉시 시스템을 복구하는 알고리즘을 사용한다.
Resource Type의 인스턴스가 한개씩 있는 경우
자원할당 그래프의 변형인 대기 그래프(wait-for graph)를 이용한다.
Ti → Rq → Tj 를 포함하는 경우 간선을 대기 그래프에 작성한다.
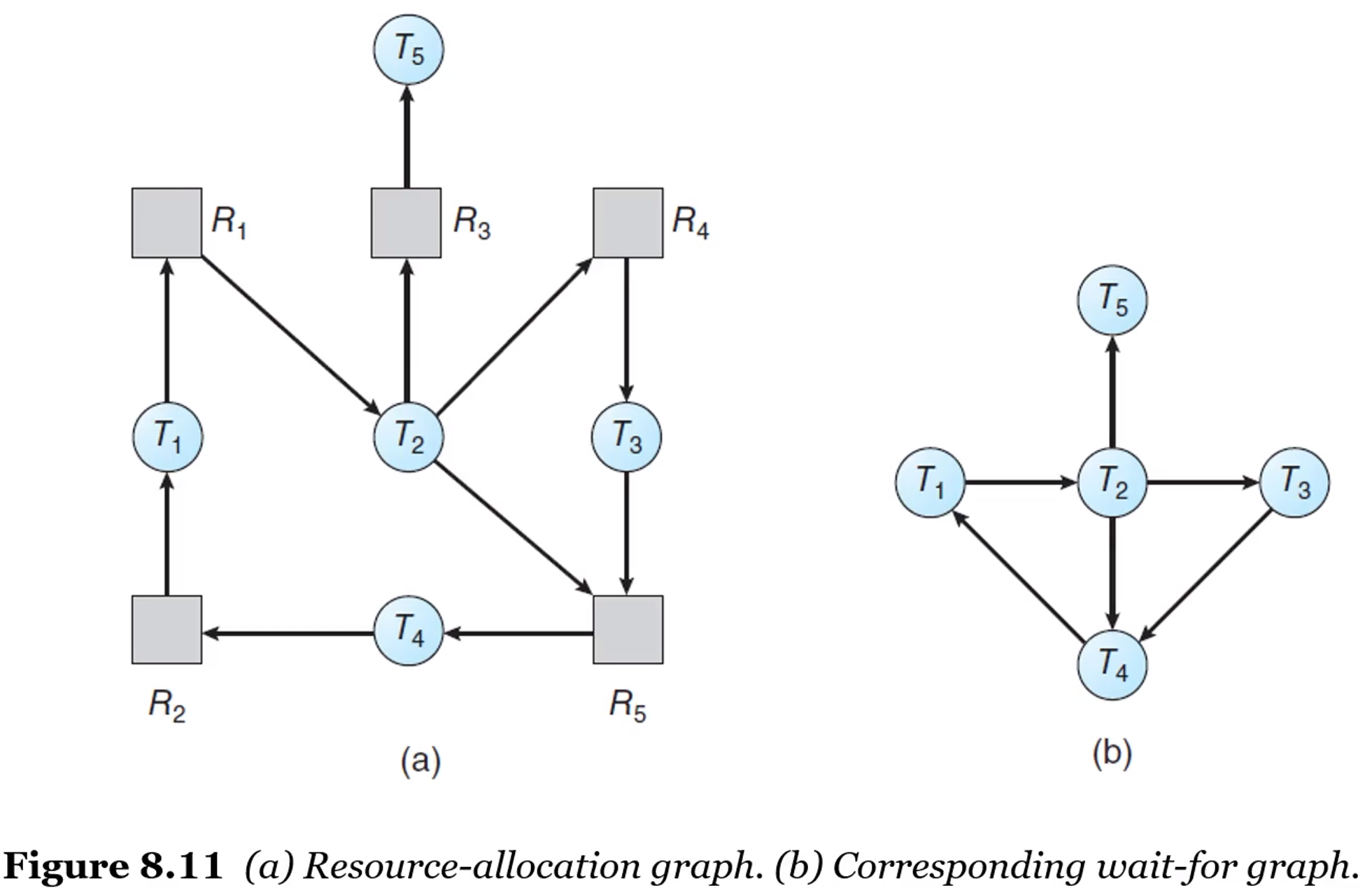
대기 그래프가 사이클을 포함하는 경우에만 시스템에 Deadlock이 발생한다.
주기적으로 그래프에서 사이클을 탐지하는 알고리즘을 호출한다.
그래프에서 사이클을 탐지하는 알고리즘은 O(n^2)의 연산을 요구한다. (n : 정점의 수)
Resource Type의 인스턴스가 여러 개 있는 경우
Banker’s Algorithm과 유사하지만 Need_i 대신 Request_i를 이용한다.
-
Work와 Finish는 크기가 m과 n인 벡터이다.
Work = Available로 초기 값을 준다.
i = 0, 1, …, n-1에 대해서 Allocation_i ≠ 0이면 Finish[i] = false를 초기 값으로 주고, Allocation_i = 0이면 Finish[i] = true를 초기값으로 준다.
(각 스레드에 현재 할당된 인스턴스가 0개이면 Deadlock을 일으키지 않는다.)
-
아래 두 조건을 만족시키는 i 값을 찾는다.
- Finish[i] == false
- Request_i = Work
그러한 값을 찾을 수 없다면 step 4로 간다.
-
Work = Work + Allocation_i
Finish[i] = truestep 2로 간다.
-
어떠한 i 값에 대해 Finish[i] == false이면 이 시스템은 Deadlock이 발생했다는 것이고, Ti에 Deadlock이 발생했다는 것이다.
탐지 알고리즘 사용
Deadlock이 발생한 스레드로부터 자원을 회수하기 전 까지는 그 자원들은 아무도 못 쓰는 자원으로 Deadlock 기간 내내 묶이게 된다.
따라서 Deadlock이 자주 발생한다면 탐지 알고리즘도 자주 돌려야한다.
Deadlock이 발생하는 시점은 어떤 스레드가 자원을 요청했는데 그것이 즉시 만족되지 못하는 시점이다.
상황에 따라서 여러개의 스레드가 연속적으로 Deadlock이 발생할 수 있다.
자원을 요청할 때마다 탐지 알고리즘을 호출하면 오버헤드가 너무 크게 된다.
→ 지정된 시간 간격으로 탐지 알고리즘을 이용한다.
ex) 한 시간에 한 번 or CPU의 이용율이 40% 이하로 떨어질 때 탐지 알고리즘 호출
8.8. Recovery from Deadlock(교착 상태로부터 회복)
Deadlock 탐지 결과 데드락이 발생했다면, 상황을 알려주기만 할 수도 있고,
중요한 시스템인 경우 회복을 진행할 수 있다.
Process and Thread Termination(프로세스와 스레드의 종료)
두 방법 모두, 종료된 프로세스에게 할당되었던 모든 자원을 시스템이 회수한다.
-
Deadlock 상태 프로세스를 모두 중지
가장 확실한 방법이지만 비용이 크다.
(오랫동안 연산한 결과들을 반드시 폐기 후 다시 계산을 해야한다.) -
Deadlock이 제거될 때 까지 한 프로세스씩 중지
각 프로세스가 중지될 때 마다 Deadlock 탐지 알고리즘을 호출해서 확인해야하므로 상당한 오버헤드를 유발한다.
- 프로세스의 우선순위가 무엇인지
- 프로세스가 수행된 시간과 지정된 일을 종료하는 데 더 필요한 시간
- 프로세스가 사용한 Resource type과 수
- 프로세스 종료를 위해 더 필요한 자원의 수
- 얼마나 많은 수의 프로세스가 종료되어야 하는지
→ 여러 경제적 요소를 고려해 중지할 프로세스를 선정한다.
Resource Preemption(자원 선점)
Deadlock이 없어질 때 까지 프로세스로부터 자원을 계속 선점해 이들을 다른 프로세스에 주어야 한다.
총 세 가지 사항을 고려해야 한다.
-
희생자 선택(selection of a victim)
비용을 최소화하기 위해 선점의 순서를 결정해야한다.
-
후퇴(rollback)
프로세스를 안전한 상태로 후퇴시키고, 그 상태로부터 다시 시작한다.
-
기아(starvation)
특정 자원들이 항상 희생자로 선택될 수 있다.
→ 특정 프로세스는 자신의 task를 완료 하지 못하는 기아상태에 빠진다.비용 요소에 후퇴(rollback)의 횟수를 포함해 문제를 해결한다.
참고 :
Silberschatz et al. 『Operating System Concepts』. WILEY, 2020.
