텍스트
논문 정보
Title: DiffExp: Efficient Exploration in Reward Fine-tuning for Text-to-Image Diffusion Models
Authors: Daewon Chae, June Suk Choi, Jinkyu Kim, Kimin Lee (Korea Univ & KAIST)
Conference: AAAI 2025
1. Abstract: 3줄 요약
- 문제 (Problem): T2I 모델을 Reward 기반으로 튜닝할 때, 모델이 다양한 샘플을 만들어보지 못해(Lack of Exploration) 수렴이 느리고 국소 최적해(Local Optima)에 빠지는 문제가 발생함.
- 해결책 (Method): DiffExp라는 새로운 탐색 전략을 제안. (1) 시간(Timestep)에 따라 CFG Scale을 동적으로 조절하고, (2) 프롬프트 내 단어의 가중치를 랜덤하게 증폭시켜 다양한 시도를 유도함.
- 결과 (Result): 기존 SOTA 방법론(DDPO, AlignProp) 대비 약 20% 적은 샘플로 더 높은 Reward를 달성했으며, 학습하지 않은 프롬프트나 SDXL 같은 최신 모델에서도 뛰어난 일반화 성능을 보임.
2. 논문을 읽기 전 알아야 할 필수 개념 (Prerequisites)
이 논문을 깊게 이해하기 위해선 Reward Fine-tuning의 딜레마와 CFG의 역할을 확실히 잡고 가야 합니다.
2.1. Reward Fine-tuning과 Exploration-Exploitation Dilemma
우리가 흔히 쓰는 Stable Diffusion 같은 모델은 기본적으로 데이터의 분포를 학습합니다. 하지만 "사람이 보기에 얼마나 예쁜가(Aesthetic)" 또는 "프롬프트 내용을 빠짐없이 다 그렸나(Alignment)" 같은 기준은 기본 학습만으론 만족시키기 어렵습니다.
그래서 강화학습(RL)의 개념을 빌려옵니다. 모델이 이미지를 생성하면 Reward Model이 점수를 매기고, 그 점수를 높이는 방향으로 모델을 업데이트하는 것이죠.
여기서 탐색(Exploration) vs 이용(Exploitation)의 문제가 발생합니다.
- Exploitation (이용): 모델이 현재 점수가 잘 나오는 방식(예: 돌고래만 크게 그리기)만 고수합니다. 점수는 안정적이지만 발전이 없습니다.
- Exploration (탐색): 점수가 낮게 나오더라도 새로운 시도(예: 돌고래 옆에 자전거 그려보기)를 해봅니다. 실패할 확률이 높지만, 성공하면 대박(Global Optima)을 터뜨릴 수 있습니다.
기존 방법론들은 Exploitation에 치우쳐 있어, 처음에 우연히라도 좋은 샘플을 못 만들면 영원히 발전하지 못하는 문제가 있었습니다.
2.2. Classifier-Free Guidance (CFG)
논문의 핵심 키워드인 CFG는 Diffusion 모델이 "프롬프트를 얼마나 강하게 따를 것인가"를 조절하는 계수입니다.
- 높은 CFG Scale: 프롬프트와 강하게 연결됨 이미지 품질(Fidelity)은 좋지만, 다양성이 사라지고 뻔한 그림만 나옴.
- 낮은 CFG Scale: 프롬프트 의존도가 낮음 이미지가 다양하게 생성되지만(Diversity), 퀄리티가 떨어지거나 엉뚱한 그림이 나옴.
💡 핵심 아이디어: 보통은 이 CFG 값을 고정해두고 쓰는데, 이 논문은 "학습 중에 이 값을 요리조리 바꿔보면 어떨까?"라는 질문에서 시작합니다.
3. Introduction: 왜 이 연구가 필요한가?
저자들은 기존 방법론(DDPO)의 한계를 보여주기 위해 "a dolphin riding a bike (자전거를 타는 돌고래)" 라는 프롬프트로 실험을 진행했습니다.

결과는 충격적이었습니다.
기존 모델은 학습이 끝날 때까지 자전거를 그리지 못했습니다. 모델이 초기에 돌고래만 그리는 쉬운 길을 택했고, 생성 과정에서 자전거가 등장하는 샘플을 한 번도 못 만들어봤기 때문에 Reward Model이 "자전거를 그리면 점수를 더 줄게!"라고 알려줄 기회조차 없었던 거죠.
즉, Reward Fine-tuning이 성공하려면 Online Sample Generation 과정에서 "좋은 Reward Signal을 가진 다양한 샘플"을 찾아내는 탐색(Exploration) 능력이 필수적입니다. 이 논문의 제안하는 DiffExp는 바로 이 탐색 능력을 극대화하는 기법입니다.
4. Preliminaries: 수식으로 이해하기
Diffusion 모델의 수식이 복잡해 보이지만, 핵심만 짚어보겠습니다.
4.1. Training Objective
Text-to-Image 모델은 노이즈 을 예측하도록 학습됩니다.
여기서 는 텍스트 조건 가 주어졌을 때 모델이 예측한 노이즈입니다.
4.2. CFG Equation
가장 중요한 식입니다. CFG를 적용한 노이즈 예측 는 다음과 같이 계산됩니다.
- : 텍스트 없이 예측한 노이즈 (Unconditional)
- : 텍스트를 보고 예측한 노이즈 (Conditional)
- : Guidance Scale (CFG Scale)
이 식은 "프롬프트 없는 그림에서 프롬프트 있는 그림 쪽으로 만큼 더 세게 밀어붙여라"라는 의미입니다.
5. Method: DiffExp (DiffusionExplore)
저자들은 모델이 (1) 다양성을 확보하면서도 (2) 높은 품질을 유지하도록 하기 위해 두 가지의 간단하지만 강력한 전략을 제안합니다.
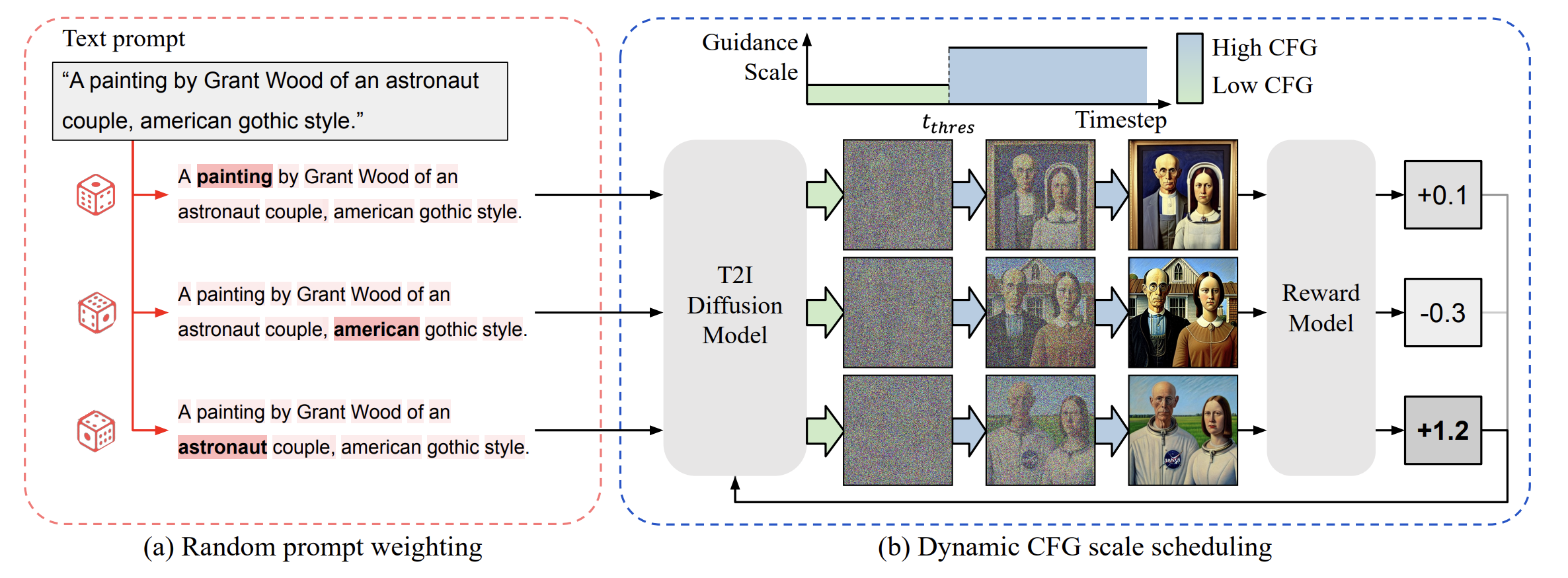
(그림 설명: DiffExp의 전체 개요. (a) 랜덤 프롬프트 가중치 조절과 (b) 동적 CFG 스케줄링 과정을 보여줍니다.)
Strategy 1: Dynamic CFG Scale Scheduling
기존에는 를 상수로 고정했지만, DiffExp는 Denoising Step(시간 )에 따라 를 변화시킵니다.
(주의: 논문의 수식 (7)과 설명맥락을 고려할 때, Diffusion은 으로 진행되므로, 가 큰 초기 단계(Early Step)에서 낮은 가중치, 가 작은 후기 단계(Late Step)에서 높은 가중치를 적용합니다.)
- 초기 단계 (Early Steps): 를 매우 낮게() 설정합니다.
- 이유: 이미지 생성 초반은 전체적인 구도(Layout)와 개념을 잡는 시기입니다. 이때 를 낮춰 모델의 구속을 풀어주면, 평소에 안 그리던 객체(예: 자전거)를 배치하는 다양한 시도(Diversity)를 하게 됩니다.
- 후기 단계 (Later Steps): 를 높게() 설정합니다.
- 이유: 구도가 잡힌 후에는 디테일을 다듬어야 합니다. 이때는 CFG를 높여서 이미지의 품질(Fidelity)을 보장하고 텍스트와의 정합성을 높입니다.
이 "치고 빠지는" 전략을 통해 다양성과 품질이라는 두 마리 토끼를 다 잡습니다.
Strategy 2: Random Prompt Weighting
모델이 특정 단어(예: "Dolphin")에만 집중하고 어려운 단어(예: "Bike")를 무시하는 현상을 막기 위한 기법입니다.
- 프롬프트 에서 랜덤한 단어(Token) 하나를 선택합니다.
- 해당 단어의 임베딩 가중치를 범위에서 랜덤하게 증폭시킵니다.
이렇게 하면 모델이 "어? 갑자기 Bike가 중요해졌네?" 하고 평소에 무시하던 자전거를 그릴 확률이 높아집니다. 이렇게 우연히 자전거를 그려서 높은 Reward를 받게 되면, 그 경험을 학습하여 나중에는 가중치 조절 없이도 자전거를 잘 그리게 됩니다.
6. Experiments: 성능 검증
저자들은 대표적인 Reward Fine-tuning 방법론인 DDPO와 AlignProp에 DiffExp를 적용하여 성능을 비교했습니다.
6.1. Sample Efficiency (샘플 효율성)
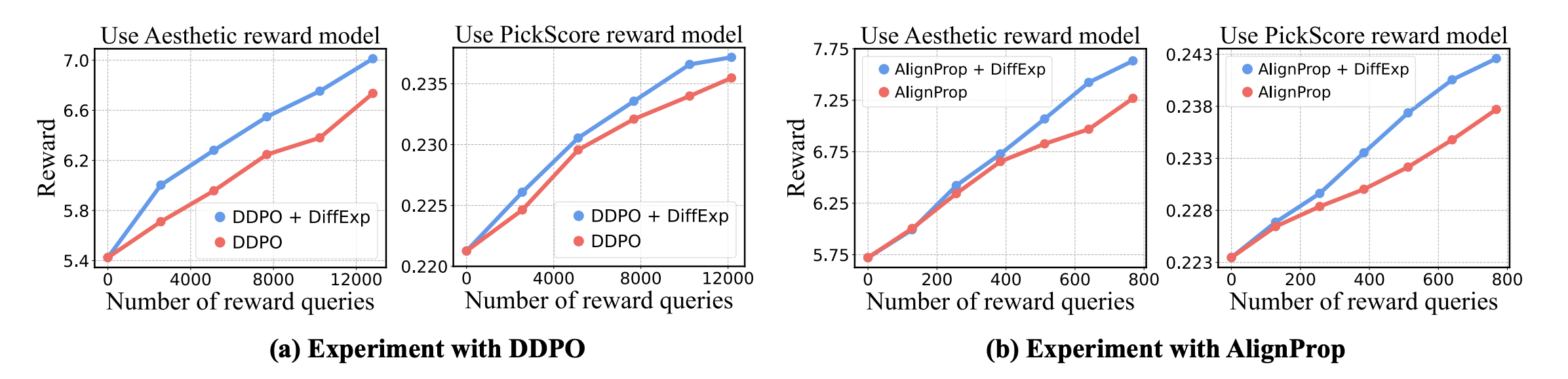
(그림 설명: 학습 진행에 따른 Reward 상승 곡선. 파란색(DiffExp)이 빨간색(Baseline)보다 훨씬 빠르게 상승합니다.)
- 결과: DiffExp를 적용한 경우(파란 선)가 기존 방법(빨간 선)보다 훨씬 가파르게 보상 점수가 오릅니다.
- 해석: 약 20% 더 적은 샘플(Query)만으로도 동일하거나 더 높은 성능에 도달했습니다. GPU 리소스가 부족한 대학원생 입장에서 학습 속도가 빠르다는 건 엄청난 장점이죠.
6.2. Qualitative Results (정성적 평가)
실제 생성된 이미지를 비교해보면 차이가 확연합니다.
- Prompt: "A butterfly playing chess (체스 두는 나비)"
- Baseline (AlignProp): '체스'라는 단어에 편향되어 체스 두는 사람을 그립니다. 나비는 없습니다.
- Ours (DiffExp): 놀랍게도 체스 말 위에 앉은 나비를 정확하게 그려냅니다. Random Prompt Weighting 덕분에 "Butterfly"의 존재감이 살아난 것이죠.

(그림 설명: Baseline과 DiffExp의 생성 이미지 비교. DiffExp가 프롬프트의 복합적인 요소를 훨씬 잘 반영합니다.)
6.3. Generalization & Scalability (일반화 성능)
- Unseen Prompts: 학습 때 보지 못한 프롬프트에 대해서도 DiffExp가 더 높은 점수를 기록했습니다. 이는 모델이 특정 프롬프트만 외운(Overfitting/Reward Hacking) 게 아니라, 전반적인 생성 능력이 향상되었음을 의미합니다.
- SDXL 적용: 최신 모델인 Stable Diffusion XL에도 적용했을 때 성능 향상이 뚜렷했습니다. 모델 사이즈가 커져도 이 탐색 전략이 유효하다는 뜻입니다.
7. Conclusion & Insight
논문의 결론
이 논문은 Text-to-Image 모델의 Reward Fine-tuning에서 Exploration(탐색)이 얼마나 중요한지를 증명했습니다. DiffExp는 Dynamic CFG와 Random Prompt Weighting이라는, 구현하기 쉽지만 강력한 두 가지 도구로 기존 모델들의 "창의력 부족" 문제를 해결했습니다.
🎓 대학생의 시선으로 본 Review
개인적으로 이 논문이 매력적이었던 이유는 "Simple is Best"를 보여주었기 때문입니다.
- 복잡한 Loss 설계 불필요: 새로운 목적 함수를 유도하거나 복잡한 수식을 추가하지 않았습니다.
- Inference 단계의 통찰: 학습 과정 중 샘플링(Inference) 단계에서
timesteps와guidance scale의 관계를 파악하여 성능을 올렸습니다. 이는 엔지니어링 관점에서도 적용하기 매우 좋습니다. - 높은 호환성: DDPO든 AlignProp이든, 혹은 미래에 나올 어떤 RL 기반 튜닝 방법론에도
Plug-and-Play로 갖다 붙일 수 있는 범용적인 모듈입니다.
References
- The Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI-25)
- DiffExp: Efficient Exploration in Reward Fine-tuning for Text-to-Image Diffusion Models
- Black et al., Training Diffusion Models with Reinforcement Learning (DDPO), ICLR 2024
- Prabhudesai et al., Aligning text-to-image diffusion models with reward backpropagation (AlignProp), arXiv 2023
- Ho and Salimans, Classifier-free diffusion guidance, arXiv 2022
