I.Abstract: 핵심 요약
ExAvatar를 전신 파라메트릭 메쉬 모델(SMPL-X)과 3D Gaussian Splatting(3DGS)을 결합한 형태로 설계
1) 비디오 내 얼굴 표정과 포즈의 제한된 다양성과
2) 3D 스캔이나 RGBD 이미지와 같은 3D 관측값의 부재이다. 비디오의 제한된 다양성은 새로운 얼굴 표정과 포즈에 대한 애니메이션을 만드는 일을 어렵게 만든다.
더 나아가, 3D 관측값의 부재는 비디오에서 관측되지 않은 인체 부위들에 대해 상당한 모호성을 유발할 수 있으며, 이는 새로운 동작에서 눈에 띄는 아티팩트를 초래할 수 있다.
이를 해결하기 위해, 메쉬와 3D 가우시안의 하이브리드 표현을 도입한다. 하이브리드 표현에서는 각 3D 가우시안을 표면 상의 하나의 정점으로 취급하며, 이들 사이에 SMPL-X의 메쉬 토폴로지를 따르는 사전에 정의된 connectivity를 부여한다.
이 방식은 SMPL-X의 얼굴 표현 공간에 의해 구동(driven)됨으로써, ExAvatar가 새로운 얼굴 표정을 가진 애니메이션이 가능하도록 만든다. 추가로, connectivity-based regularizer를 사용함으로써, 새로운 얼굴 표정과 포즈에서 발생하는 아티팩트를 크게 줄인다.
II. Introduction
지금까지 whole-body 3D 인간 형상 모델들이 제안되어 왔다
그중 SMPL-X는 가장 널리 사용되는 모델로, 수많은 3D 전신 포즈 추정 방법들과 벤치마크를 촉발했다.
본 논문에서는 짧은 monocular 비디오로부터 생성 가능한, 표현력이 풍부한 전신 3D 인간 아바타 ExAvatar를 제안한다. ExAvatar는 전신 3D 파라메트릭 모델 SMPL-X와 3D Gaussian Splatting(3DGS)을 결합한 형태로 설계된다. ExAvatar는 SMPL-X의 전신 구동 가능성(whole-body drivability)과 3DGS의 포토리얼하고 효율적인 렌더링 능력을 모두 활용한다. 학습이 끝난 뒤에는, Fig. 1에 보이듯 SMPL-X의 새로운 얼굴 표정 코드와 3D 포즈로 애니메이션이 가능하다.

ExAvatar를 모델링하는 것은 다음 두 가지 이유로 결코 단순하지 않다.
(1) 비디오 내 얼굴 표정과 포즈 다양성이 제한적이며,
(2) 3D 스캔이나 RGBD 비디오와 같은 3D 관측치가 존재하지 않는다는 점이다.
비디오의 제한된 다양성 때문에, 새로운 얼굴 표정과 포즈에 대해 잘 구동되도록 만드는 것은 쉽지 않다. 더 나아가 3D 관측이 없으면, 비디오에서 가려져 관측되지 않은 인체 부위에 대해 모호성이 커지고, 이는 새로운 얼굴 표정과 포즈에서 눈에 띄는 아티팩트를 야기할 수 있다.
이러한 문제들을 해결하기 위해, ExAvatar 내에서 표면 메쉬와 3D 가우시안을 결합한 새로운 하이브리드 표현을 제안한다. 제안하는 하이브리드 표현에서는 각 3D 가우시안을 표면 상의 하나의 정점으로 취급하며, 이 정점들은 SMPL-X의 메쉬 토폴로지를 따르는 사전 정의된 연결 정보를 가진다. 기존의 볼류메트릭 아바타들은 정의상 이러한 연결성을 갖지 않는다. 또한 이전 3DGS 기반 연구들은 3D 가우시안 점들의 집합을, 정점들 간의 연결성을 고려하지 않는 포인트 클라우드로 취급한다.
하이브리드 표현을 사용하면, ExAvatar는 SMPL-X의 얼굴 표현 공간과 완전히 호환된다. 따라서, 다양한 얼굴 표정이 포함되어 있지 않은 짧은 monocular 비디오로부터 학습된 경우에도, SMPL-X의 임의의 얼굴 표정 코드로 ExAvatar를 구동할 수 있다.
3D 가우시안은 SMPL-X와 정확히 동일한 메쉬 토폴로지를 공유하므로, FLAME과 SMPL-X에서와 같이, 얼굴 표정에 따라 3D 가우시안 점들을 움직이기 위해 단순히 정점 오프셋을 3D 가우시안 위치에 더해주면 된다.
–3D 관측을 요구하지 않는 짧은 monocular 비디오로부터 생성 가능한, 표현력 있는 전신 3D 인간 아바타 ExAvatar를 제안한다.
–표면 메쉬와 3D 가우시안을 결합한 하이브리드 표현을 제안한다. 이 표현 덕분에, 다양한 얼굴 표정이 없는 짧은 monocular 비디오로부터 학습하더라도, SMPL-X의 임의의 새로운 얼굴 표정 코드로 ExAvatar를 애니메이션할 수 있다.
–3D 가우시안 사이의 연결성 정보를 활용함으로써, 특히 새로운 얼굴 표정과 포즈에서의 아티팩트를 크게 줄인다.
Related Works
-논문 내용의 2가지 개념과 3DGS 정리
3D human avatars
참조 논문 : A Survey on 3D Human Avatar Modeling - From Reconstruction to Generation
3D 인간 아바타(3D human avatar)라는 말을 들으면 보통 게임 캐릭터나 메타버스 아바타 정도를 떠올리지만, 논문에서 말하는 “아바타”는 조금 더 구체적이다.
“특정 사람의 3D 형상(geometry) + 외관(appearance)을 함께 표현하고,
새로운 포즈나 다른 카메라 뷰에서도 자연스럽게 렌더링할 수 있는 모델”
을 보통 3D 아바타라고 생각하면 된다.
[원본 비디오] → [3D Reconstruction] → [3D Avatar] → [새 포즈 / 새 뷰 렌더링]
초기 연구들은 대부분 메쉬 기반이었다. 예를 들어 SMPL 메쉬를 가져다가 정점별 오프셋을 더해서 개인별 체형, 옷주름 등을 표현하는 방식이 대표적이다.
이런 방식은 토폴로지가 고정된 깔끔한 메쉬 위에 디테일만 살짝살짝 올리는 느낌이다.
이후에는 NeRF 같은 볼류메트릭 / implicit 표현이 등장하면서,
“굳이 메쉬를 직접 쓰지 않고도 고품질 사람 아바타 만들 수 있지 않나?” 하는 흐름이 나왔다.
여러 대의 카메라로 촬영된 멀티뷰 영상 + 정확한 3D 포즈를 가지고 사람을 볼류메트릭하게 재구성하는 방법들
장면을 신경 복사장(NeRF)이나 Signed Distance Field로 표현해서 사진과 거의 구분이 안 가는 수준으로 렌더링하는 방법들
가장 큰 문제는 연구실 밖 구현이 힘들다는 거다.
문제1. 보통 사람은 16대 카메라가 달린 캡처 스튜디오에 들어가지 않는다.
문제2. 그냥 휴대폰으로 30초 정도 찍은 영상이 전부인 경우가 훨씬 많다.
문제3. 심지어 얼굴 표정도 다양하지 않고, 손도 제대로 안 보일 수 있다.
Whole-body 3D Human Modeling: SMPL에서 SMPL-X
참고 논문: https://arxiv.org/abs/1904.05866
[SMPL] : 몸 + 다리 + 팔 중심
[SMPL-X] : 몸 + 다리 + 팔 + 얼굴 표정 + 손가락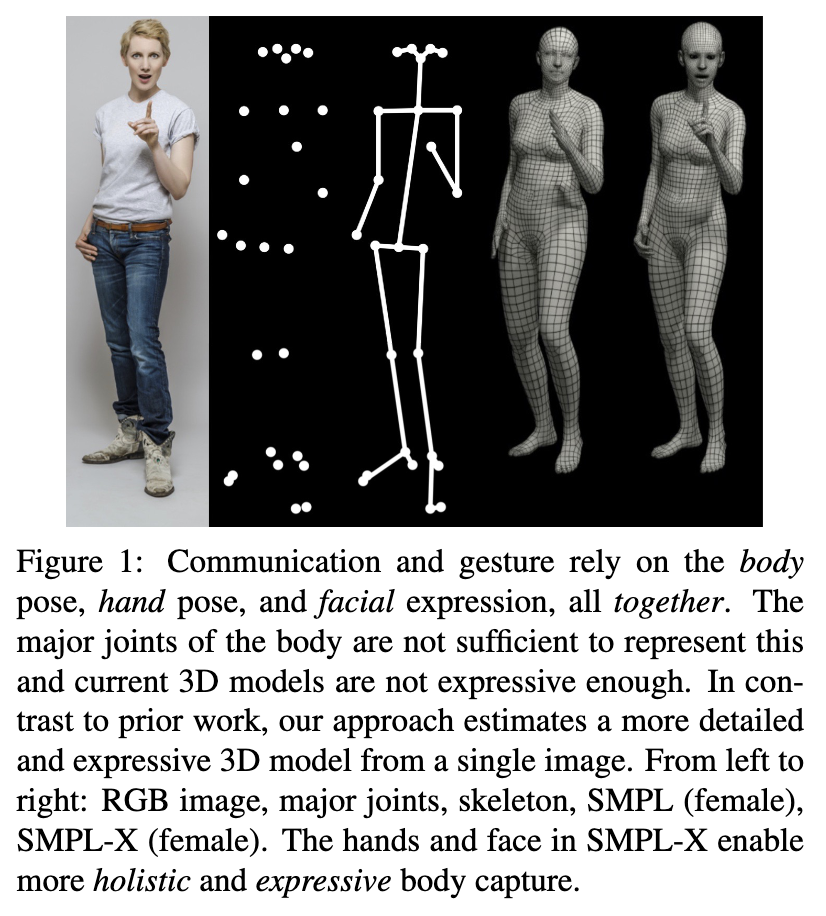
“SMPL은 몸 중심, SMPL-X는 얼굴과 손이 포함된 전신 모델이다.
ExAvatar는 이 SMPL-X를 기반으로 얼굴·손까지 움직일 수 있는 아바타를 만든다.”
간단히 정리하면:
SMPL
사람의 몸을 포즈(관절 회전) + 체형(shape) 파라미터로 표현하는 파라메트릭 메쉬 모델.
θ (pose), β (shape)를 넣으면 3D 메쉬가 나오는 형태.
SMPL-X
SMPL을 확장해서 몸 + 손 + 얼굴 표정까지 한 번에 표현하는 모델.
여기에 손가락 관절, 얼굴 표정용 blendshape, 눈·입 주변까지 다 들어간다.
연구 입장에서 SMPL-X가 중요한 이유는 단순하다.
“전신 포즈 + 손 제스처 + 얼굴 표정을
하나의 일관된 파라미터 공간에서 다룰 수 있게 해준다.”
그래서 요즘 전신 인체 이해/생성/아바타 분야 논문들에서
“우리는 SMPL-X를 사용했다”는 문장은 거의 기본 세팅처럼 따라붙는다.
3D Gaussian Splatting(3DGS): NeRF 이후의 새로운 엔진
3DGS는 사실 다른 논문을 리뷰할때도 많이 본 개념이라 가볍게 정리하고만 넘어가자
[NeRF] : 공간 전체를 MLP로 표현, 레이를 따라 샘플링
[3DGS] : 장면을 3D Gaussian 점들의 집합으로 표현, 점들을 화면에 splatNeRF
“연속 공간 + MLP + 레이 샘플링”
3DGS
“점 구름 + Gaussian 커널 + 가속된 splatting”
이라고 보는 느낌이다.
ExAvatar를 위 개념들로 논문의 문맥으로 보자면 이렇다
[입력: 짧은 monocular 비디오]
↓
[SMPL-X 피팅 / 포즈·표정 추정]
↓
[SMPL-X 메쉬 정점 위에 3D Gaussian 최적화]
↓
[학습 완료된 ExAvatar]
↓
[임의의 SMPL-X 포즈·표정 코드 입력 → 전신 3DGS 렌더링]III. ExAvatar
3.1 Accurate co-registration of SMPL-X
한줄요약
짧은 in-the-wild 비디오에서, 몸·손·얼굴이 모두 잘 맞는 SMPL-X 파라미터를 만들기 위해 joint offset, face offset 두 가지를 같이 최적화한다.

"핵심 아이디어"
먼저 모든 프레임에 대해 SMPL-X regressor로 초기 SMPL-X 파라미터 추정 2D pose estimator로 2D 키포인트 추정 각 프레임마다 2D 키포인트에 맞게 θ, ψ, t를 다시 피팅하고, shape β는 전 프레임 공유
전신에서 가장 어려운 부분인 손·얼굴 정합을 위해 관절 위치를 보정하는 joint offset ΔJ
얼굴 정점 위치를 보정하는 face offset ΔV_face 두 개를 ID-dependent 파라미터로 도입 얼굴은 FLAME + DECA로 따로 고퀄 정합해 놓고, 그 결과를 SMPL-X 얼굴 메쉬에 투영해서 ΔV_face로 가져옴
왜 중요한가
짧은 비디오에서는 손, 얼굴이 자주 작게 나오거나 모션이 복잡해서 기본 SMPL-X만으로는 registration이 틀어지기 쉽다.
joint offset / face offset을 통해 skeleton과 표면을 사람별로 정교하게 맞춰 놓으면
→ 이후 Gaussian 아바타 학습의 기준 좌표계가 훨씬 깔끔해짐
→ 최종 아바타에서 손/얼굴이 ‘깨지는’ 현상 감소
3.2 ExAvatar 아키텍처
한 줄 요약
→ SMPL-X에서 뽑은 canonical 메쉬 + 트라이플레인 + MLP들을 조합해서, 각 정점에 대응되는 3D Gaussian의 geometry·color를 회귀하는 구조.
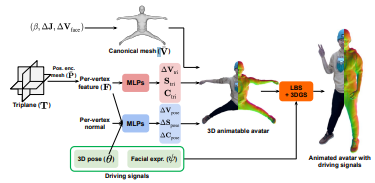
Canonical mesh V̄
SMPL-X(β, ΔJ, ΔV_face, 大-pose)를 거쳐 얻은 메쉬를
PyTorch3D subdivision으로 upsample (167K verts, 335K faces)
Triplane 기반 feature 추출
1.학습 가능한 T ∈ ℝ³ˣᶜˣᴴˣᵂ (C=32, H=W=128)
2.중립 포즈 positional mesh P̄를 동일 topology로 업샘플
3.P̄를 각 평면에 투영 + bilinear interpolation → 정점별 feature
4.얼굴은 해상도·디테일이 중요해서 face 전용 triplane 하나 더 사용
Gaussian 자산 회귀 (pose-independent)
1.F(정점 feature)를 입력으로
MLP①: ΔV_tri, S_tri (geometry)
MLP②: C_tri (color)
2.Gaussian은 등방성으로 제한(스케일 1D, 회전/opacity 고정)
Pose-dependent 보정
추가 MLP 두 개
기본 Gaussian은 ID+환경을 표현하고, pose MLP는 작은 보정 역할만 수행
3.3 애니메이션 & 렌더링
한 줄 요약
→ canonical 상태의 Gaussian 포인트들을 SMPL-X 포즈/표정으로 옮긴 뒤,
3DGS 렌더러로 이미지를 뽑는다.
3.4 손실 함수 & 정규화
Image loss
대상: I_tri, I_pose vs 입력 이미지
항목: L1 + (1 - SSIM) + LPIPS
사람 영역만 crop해서 계산 → 연산량 절감
Face loss (mesh 기반)
FLAME 기반 얼굴 UV 텍스처 평균을 고정해 놓고,differentiable mesh renderer로 뽑은 얼굴 이미지를 GT와 L1로 비교
이때 텍스처는 고정, Gaussian 위치만 움직이면서 loss 감소
목적:
geometry–texture의 일관성(입술, 눈썹 등)
새로운 표정/턱 포즈에서도 얼굴이 자연스럽게 움직이도록
Connectivity-based regularizers (Laplacian)
V̄_tri, V̄_pose vs canonical mesh V̄의 Laplacian 차이 최소화
효과:
관측되지 않은 부위(가려진 등에 있는 Gaussian들)가
이상하게 튀는 것(floating Gaussian) 방지
SMPL-X 얼굴 geometry와의 형상 일치 유지
L2로 단순히 “메쉬에서 멀어지지 마라”만 하는 기존 방식보다
지역 구조를 유지하는 데 훨씬 유리
IV.Experiment
4.1 데이터셋
NeuMan – 진짜 현실 세계에 가까운 monocular 비디오
NeuMan 데이터셋은 실외에서 촬영된 짧은 단일 카메라 비디오들로 구성되어 있다. 한 영상에 한 명의 사람이 나오고, 약 15초 정도 걸어 다니거나 움직이는 장면이 담긴다. 배경에는 자전거, 나무, 건물 등 온갖 것들이 등장하고, 카메라 흔들림이나 조명 변화도 당연히 존재한다. 논문에서는 bike, citron, jogging, seattle처럼 인체가 잘 보이고 블러가 적은 시퀀스를 골라 실험에 사용한다.
여기서 중요한 포인트는 아주 단순하다.
3D 스캔도, 깊이 맵도, 멀티뷰도 없다.
그냥 우리가 평소에 휴대폰으로 찍는 것과 비슷한, RGB monocular 비디오 한 줄이 전부다.
X-Humans – 스튜디오, RGBD, 표정·손이 더 풍부한 데이터
반대로 X-Humans는 스튜디오 환경에서 촬영된 고급 데이터셋이다. 여러 피사체에 대해 3D 스캔과 RGBD 비디오를 제공, 특히 얼굴 표정과 손 포즈가 훨씬 다양하게 담겨 있다. 원래 X-Avatar 논문이 이 데이터셋을 기반으로 전신 아바타 SOTA를 찍었던 바로 그 세트다.
X-Humans에는 두 가지 실험 프로토콜이 있다는 점이다. 스캔을 사용하는 경우, 그리고 RGBD 비디오를 사용하는 경우. X-Avatar는 RGBD와 정밀한 SMPL-X registration을 활용해서 전신 아바타를 학습한다.
0028, 0034, 0087 같은 특정 피사체를 골라놓고, 깊이 없이 RGB monocular 비디오만 사용해서 아바타를 만들고 X-Avatar와 성능을 비교한다.
4.2 성능비교
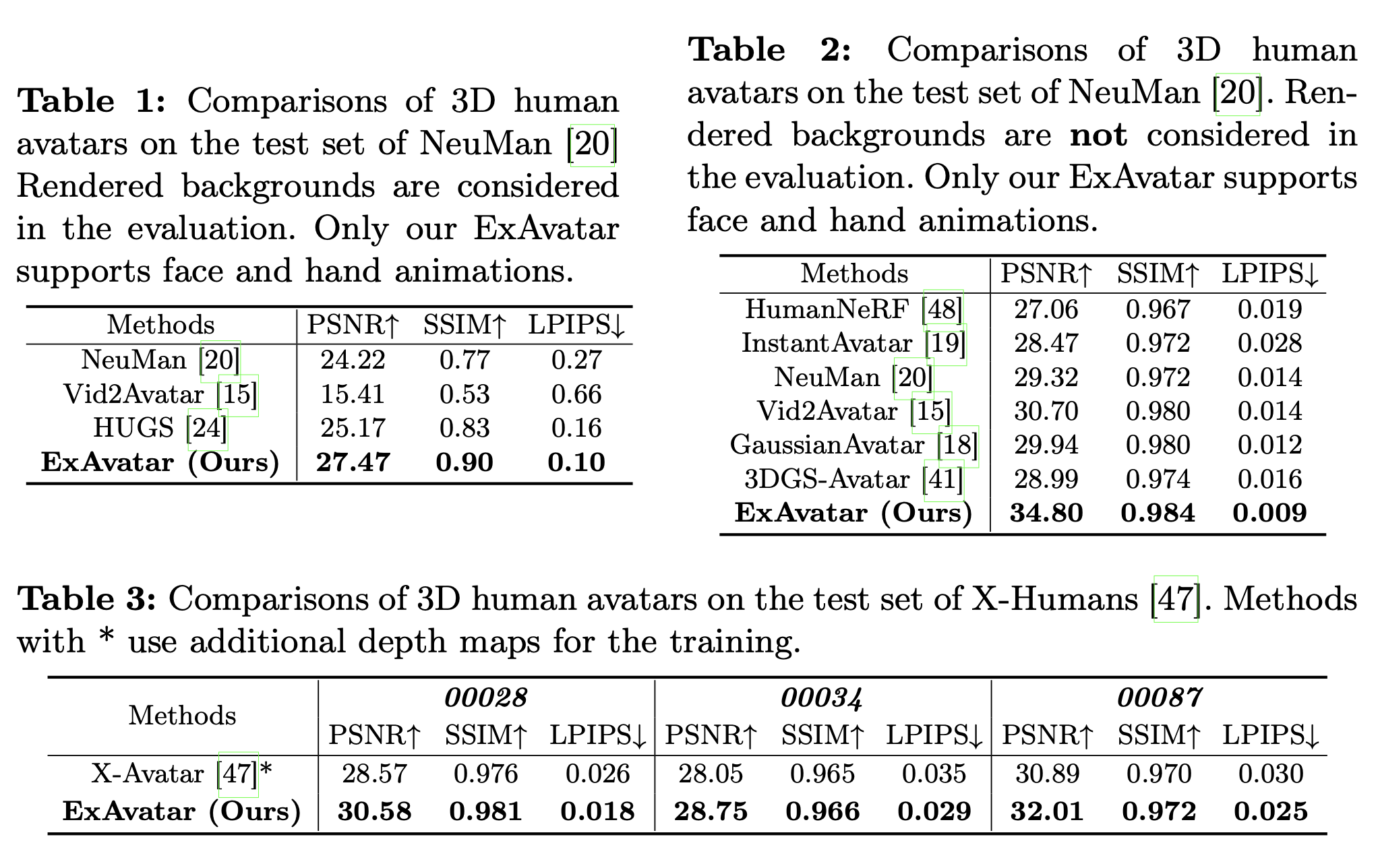
NeuMan에서의 비교 – 배경 포함 vs 인체만
먼저 NeuMan 데이터셋에서는 두 가지 방식으로 평가를 진행한다.
하나는 렌더링된 배경까지 포함해서 전체 이미지를 평가하는 방법, 다른 하나는 사람 영역만 남기고 배경 픽셀을 제거한 뒤 인체 부분만 평가하는 방법이다.
배경까지 포함해서 볼 때는 NeuMan, Vid2Avatar, HUGS 같은 방법들과 ExAvatar를 비교한다. 여기서는 단순히 “얼마나 똑같이 이미지를 복원하느냐”뿐 아니라, 사람과 배경의 조합 전체를 얼마나 잘 재현하느냐도 같이 본다. 이 설정에서도 ExAvatar는 PSNR과 SSIM이 가장 높고 LPIPS가 가장 낮다. 즉, 수치상으로도 가장 GT에 가깝고 perceptual 차이도 적다는 의미다. 게다가 이 중에서 실제로 얼굴과 손을 독립적으로 애니메이션할 수 있는 모델은 ExAvatar뿐이다.
배경을 떼어내고 인체만 평가하는 실험에서는 HumanNeRF, InstantAvatar, NeuMan, Vid2Avatar, GaussianAvatar, 3DGS-Avatar 등 다양한 최신 아바타/NeRF 계열과 비교한다. 이때는 이미지를 사람 마스크로 잘라낸 뒤 그 부분만 가지고 지표를 계산한다. 여기서도 ExAvatar가 PSNR, SSIM, LPIPS 모두에서 SOTA를 찍는다. “배경 포함 전체”로 보나, “사람만 떼 놓고” 보나 둘 다 가장 우수하다.
참고로 배경 마스크를 얻기 위해서는 GaussianAvatar와 동일하게 기성 segmentation 네트워크를 사용하고, 평가 시에는 기존 연구들처럼 테스트 프레임에 대해 SMPL-X 파라미터만 조금 미세 조정하고 나머지 파라미터는 고정해 두는 세팅을 따른다.
X-Humans vs X-Avatar – RGBD를 이기는 RGB monocular
다음은 X-Humans 데이터셋에서의 비교다. 여기서는 사실상 “이 논문의 하이라이트”에 가까운 결과가 나온다.
X-Avatar는 RGBD 비디오와 정확한 3D registration을 전제로 설계된 모델이다. 반면 ExAvatar는 깊이를 전혀 쓰지 않고, RGB monocular 비디오만 쓴다. 그럼에도 불구하고, 여러 subject에 대해 PSNR, SSIM, LPIPS를 비교해 보면 ExAvatar가 전반적으로 더 좋은 수치를 기록한다. 시각적 결과를 보면 얼굴의 입술, 눈 주변, 코, 이마 음영뿐 아니라 손 모양이나 손가락 디테일까지 더 자연스럽게 표현되는 경우가 많다.
표면 메쉬와 3D Gaussian을 결합한 하이브리드 표현, SMPL-X co-registration에서의 joint/face offset, 그리고 뒤에서 설명할 Laplacian 정규화와 face loss까지 포함한 전체 설계가, 더 좋은 설계를 만든 것 같다.
V. Conclusion
요약하자면
짧은 monocular 비디오 하나만으로, 얼굴·손까지 움직이는 전신 3D Gaussian 아바타를 만들 수 있고,
그걸 가능하게 만든 핵심은 “메쉬 + 3D Gaussian 하이브리드 표현”이다.
ExAvatar는 SMPL-X라는 전신 파라메트릭 모델과 3D Gaussian Splatting을 묶어서,
3D 스캔이나 RGBD 같은 3D 관측 없이도 전신 아바타를 만든다. 이 하이브리드 표현 덕분에 두 가지 문제가 동시에 해결된다.
첫째, 짧은 영상이라 얼굴 표정·포즈가 다양하지 않다는 문제.
둘째, 깊이/스캔이 없기 때문에 가려진 부위(입 안, 손바닥, 몸 뒤쪽 등)가 애매하게 남는 문제.
Gaussian을 그냥 뜬금없는 점구름으로 쓰지 말고,
SMPL-X 메쉬의 정점으로 취급하자.
이렇게 하면 Gaussian들이 SMPL-X와 같은 connectivity를 공유하게 되고, SMPL-X의 얼굴 표정 공간을 그대로 드라이버로 쓸 수 있고, Laplacian 같은 메쉬 기반 정규화도 바로 먹일 수 있다. 이게 결국, 새로운 표정·포즈에서 아바타가 덜 깨지고 더 자연스럽게 동작하는 이유라고 정리한다.
실험에서 보여준 것처럼,깊이까지 쓰는 X-Avatar보다, 깊이 없이 RGB monocular만 쓰는 ExAvatar가 더 좋은 수치와 시각 결과를 낸다는 게 이들의 최종 결론.
ExAvatar의 한계
첫 번째는 보이지 않는 부위는 결국 “그럴듯하게 상상”할 수밖에 없다는 점이다.
두 번째는 동적인 옷이다.
