가우시안 프리미티브의 개수를 최소한으로 유지하면서도 저장 용량을 최소화하는 것에 초점을 맞추고 증여한 가우시안들을 골라내 국소 구분도(local distinctiveness) 지표를 도입하였고 희소한 가우시안들에 대해 불규칙성과 연속성을 활용해 더 효율적인 속성 표현 방식을 제안.
5MB이하의 저장 용량으로도 장면을 표한하면서 600FPS 이상의 랜더링 속도를 달성할 수 있다.
알고가야할 부분들
- 그래픽스 시간에 배운 가우시안 스플레팅이란?
[출처: https://happy-support.tistory.com/25]
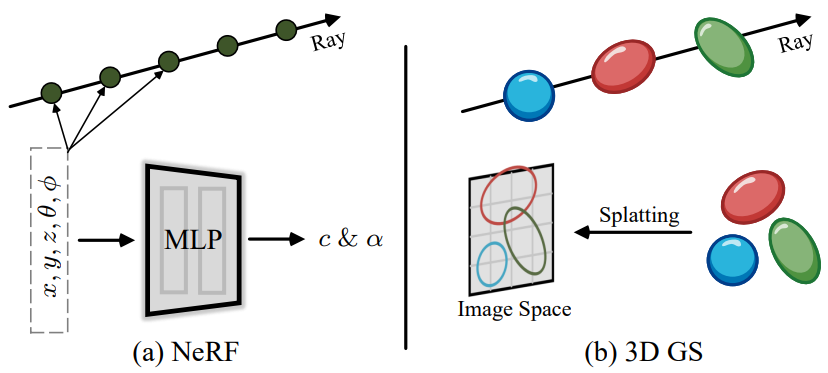
기존에는 NeRF기반으로 synthesis를 수행하곤 했는데 성능은 좋지만 연산량이 많고 실시간 렌더링에서의 활용은 어렵다.
그렇기에 소개된 개념이 바로 3D GS이다. 위 사진과 같이 타원을 이미지 상에 투영시키는 방법을 말한다.

전체적인 흐름은 위 figure와 같다.
카메라를 기준으로 초기 여러개의 점들을 생성하고 그 중점을 이라고 하자 그 가우시안들은 모두 제각각의 크기를 가질 것이고 를 그 크기라고하자. 또, 타원의 기울어진 정도가 있을테니 이를 이라고하자. 마지막으로 가우시안들이 색조를 가질테니 이 색상을 라고 하자.
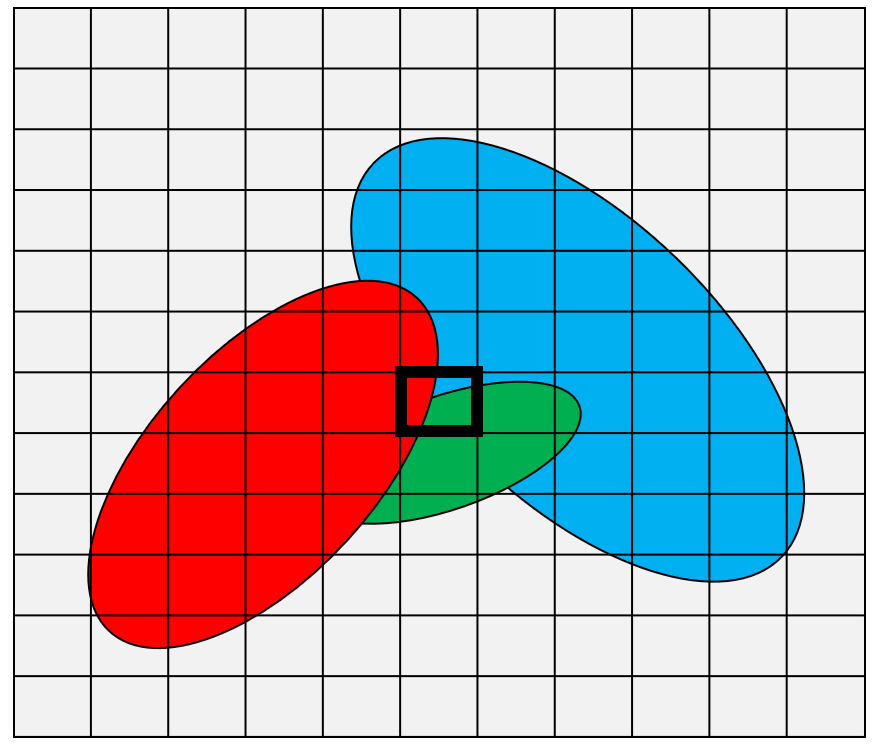
2D 공간상에 투영된 분포들을 이제 균일한 크기로 잘라 최종 Pixel값을 정하고 겹쳐지는 부분들에 대한 분포들이 가지는 불투명도를 라고 하자.

가우시안 스플래팅을 소개하는 논문에서는 수도 코드를 다음과 같이 제시했다.
또, 초기점들에 대한 알고리즘은 SfM이라는 알고리즘이다. SfM은 여러 각도에서 찍은 사진들이 들어왔을때 point cloud를 생성하여 이미지를 구축하는 방법이고 이는 1992년
A Sequential Factorization Method for Recovering Shape and Motion from Image Streams 라는 논문에서 제안되었다.
한마디로 정리하자면 여러장의 사진에서 '특징'을 추출하고 이를 유사도 기반으로 이어붙인다로 정리할 수 있다.
Abstract
세줄 요약
1. 3DGS가 실시간 고성능 랜더링을 위한 표현방법으로 떠오르고 numerous explicit Gaussian primitives로 3D를 표현, 낭비 발생, 다른 논문들은 속성 압축에만 집중한다.
2. 가우시안의 개수는 계산 비용과 직접적으로 연관되어 있기에 저장용량 최적화보다는 가우시안 개수를 효과적으로 줄이는 것이 중요하다.
3. 본 논문에서 제시하는 OMG는 distinct 가우시안 선별, 프리미티브들 사이의 연속성과 불규칙성, 서브벡터 양자화까지 도입하여 용량을 감소시키고 랜더링 품질을 600fps까지 올린다.
I. Introduction
1) 3D Gaussian Splatting이 왜 중요한가
최근 3DGS는 빠르고 포토리얼한 3D 장면 재구성을 위해 많이 쓰이는 방법이다.
기존 NeRF는 하나의 신경망이 장면 전체를 표현하고, 각 픽셀마다 광선을 쏜 뒤 많은 샘플을 MLP에 통과시키는 방식이라 계산량이 크다.
3DGS는 아이디어가 다르다.
장면을 수많은 3D 가우시안(작은 반투명 구름 같은 점) 들로 표현한다.
카메라 시점에서 이 가우시안들을 화면에 스플랫(splat) 하듯이 찍어내면서 렌더링한다.
이 과정에서 타일 단위 병렬 처리(tile-based parallelism) 를 활용해 GPU에서 매우 빠르게 동작한다.
덕분에 3DGS는
-동적인 장면 재구성
-사람 아바타 렌더링
-생성 모델의 3D 표현
-도시 규모의 대형 장면 렌더링
같은 다양한 응용에서 많이 쓰이고 있다 한다.
2. 3DGS의 숨은 문제: 가우시안이 너무 많다
3DGS는 학습 과정에서 가우시안의 개수를 자동으로 조절한다.
-위치 기울기(gradient)가 큰 가우시안은 복제하거나 분할해서 더 세밀하게 만든다.
-불투명도가 낮아서 거의 기여하지 않는 가우시안은 제거한다.
하지만, 장점만 있는 것은 아니다 부작용이 존재하는데
최종적으로 한 장면에 300만 개가 넘는 가우시안이 남는 경우가 많다.
저장 용량이 커지고
메모리 사용량과 연산량이 크게 증가한다.
그래서 기존 연구들은 먼저 “가우시안 수를 줄이자”에 집중해왔다.
중요도가 낮은 가우시안을 렌더링 손실이나 중요도 점수로 잘라내는 pruning 기법
가우시안을 언제 늘리고 언제 줄일지 더 똑똑하게 설계하는 densification 전략
이런 연구들 덕분에 최근에는 가우시안 개수를 약 50만 개 정도까지 줄여도 화질을 유지하면서, 저사양 GPU에서도 실시간 렌더링이 가능해졌다 한다.
3. 가우시안만 줄여서는 부족하다
가우시안 하나가 59개의 학습 파라미터로 표현된다.
즉, 위치, 크기, 모양(공분산), 색, 불투명도 등 여러 속성이 다 수치로 저장된다.
그래서 가우시안 개수를 많이 줄여도 저장 공간이 여전히 크다.
예를 들어, 논문에서 언급하는 한 설정에서는
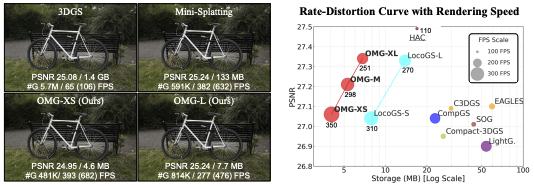
가우시안 수를 줄였음에도 133MB나 차지한다(그림 1 참조).
그래서 두 번째 방향의 연구가 등장한다.
벡터 양자화(Vector Quantization)
뉴럴 필드(Neural Field)를 이용한 속성 재표현
정렬(sorting)과 엔트로피 최적화 등 압축 기법
을 사용해서 “가우시안의 속성을 압축하자”는 방향이다.
이 덕분에 저장 용량을 꽤 줄이는 데 성공한 연구들이 많이 나왔다 한다.
-> 벡터 양자화란?
벡터 양자화 참고 자료 출처
벡터 양자화(Vector Quantization, VQ)는 고차원 벡터를 코드워드(code word) 또는 중심점(centroid)이라 불리는 제한된 대표 지점 집합에 매핑하여 데이터를 압축한다. VQ는 데이터의 기능을 유지하면서 크기를 최소화하여 더 쉽고 효율적으로 처리 및 저장할 수 있게 한다. 이 방식은 이미지 압축, 오디오 처리, 머신러닝, 근사 최근접 탐색(ANN search)에 이상적이다.
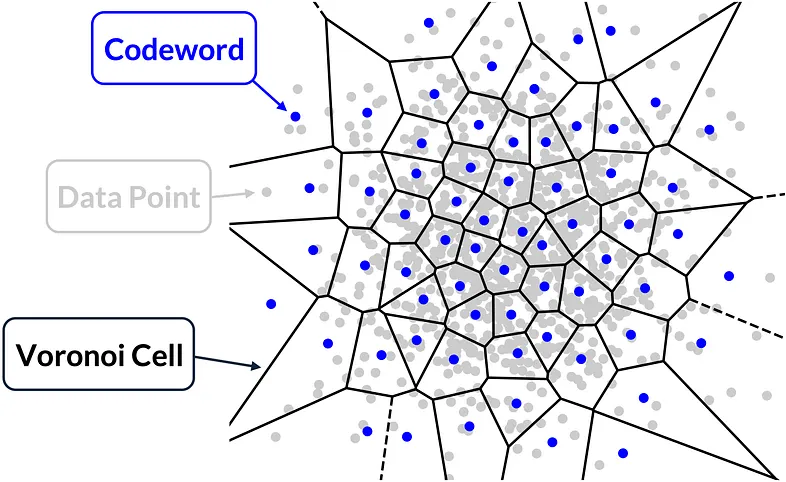
[출처: https://medium.com/data-science]
4. “적은 가우시안 + 압축”이 어려운 이유
하지만 기존 압축 연구들은 여전히 가우시안 개수가 100만 개 이상인 설정을 전제로 하는 경우가 많다.
왜냐하면, 가우시안 수를 극단적으로 줄이면 두 가지 큰 문제가 생기기 때문이다.
1.각 가우시안이 담당하는 영역이 너무 넓어진다.
•한 점이 더 많은 공간을 표현해야 하므로
•속성을 조금만 손실 압축해도 화질이 크게 깨지기 쉽다.
2.가우시안 사이 간격이 멀어지면서 공간적 근접성(spatial locality)이 깨진다.
•서로 이웃한 가우시안 사이의 속성이 비슷하다는 가정이 약해진다.
•그러면 엔트로피를 줄이거나 규칙성을 이용해 압축하기가 어려워진다.
하지만 연산 비용(학습 시간, 렌더링 속도)은 가우시안 개수에 거의 비례한다.
따라서 “속성만 잘 압축하자” 수준을 넘어,
“가우시안 개수 자체를 최대한 줄이면서도 압축 가능한 구조를 만드는 것”이 중요해진다.
이 지점에서 OMG가 등장한다.
5. OMG의 핵심 아이디어 1: 적은 가우시안에도 잘 맞는 속성 표현
OMG(Optimized Minimal Gaussians)는
“가우시안 개수를 최대한 줄이면서도 잘 압축되는 표현”을 목표로 한다.
핵심 아이디어는 다음과 같다.
5.1 per-Gaussian feature + 작은 뉴럴 필드
가우시안 수를 줄이면 국소적인 연속성은 떨어지지만,
그래도 “가우시안 위치가 비슷하면, 장면 구조도 어느 정도 비슷하다” 는 정보는 남아 있다.
OMG는 이 점을 활용한다.
1.먼저, 아주 가벼운 뉴럴 필드(neural field) 를 만든다.
입력: 가우시안의 위치
출력: 그 주변을 대표하는 거친(coarse) 공간 특징
파라미터 수가 매우 적어서 전체 모델 크기에 거의 영향을 주지 않는다.
2.그리고 각 가우시안마다 per-Gaussian feature 벡터를 하나씩 둔다.
3.최종 속성(색, 불투명도 등)은
“위치 기반 뉴럴 필드에서 나온 공간 특징”과
“per-Gaussian feature”를 합쳐서 표현하도록 설계한다.
이렇게 하면 원래 속성을 직접 다 저장하는 것보다 가우시안당 필요한 파라미터 수가 줄어든다.
즉, 더 컴팩트한 표현이 가능해진다.
6. OMG의 핵심 아이디어 2: Sub-Vector Quantization(SVQ)
per-Gaussian feature 자체도 결국은 벡터이기 때문에,
그냥 두면 저장 공간을 또 잡아먹게 된다.
OMG는 이를 위해 Sub-Vector Quantization(SVQ) 를 사용한다.
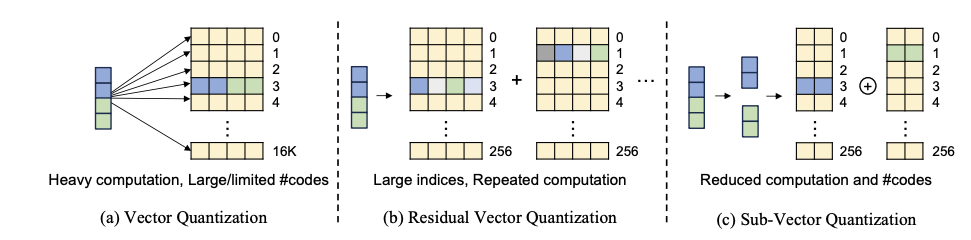
기존 벡터 양자화(VQ)는
긴 벡터 전체를 하나의 코드워드(codeword)에 매핑한다.벡터 차원이 크면 코드북이 너무 커져서 연산량도 많고, 저장도 부담된다.
잔차 벡터 양자화(RVQ)는 여러 단계의 코드북과 인덱스를 사용하므로 인덱스를 많이 저장해야 해서 또 다른 저장 부담이 생긴다.
SVQ는 다음과 같이 절충한다.
1.하나의 긴 벡터를 여러 개의 서브벡터로 나눈다.
2.각 서브벡터에 대해 별도의 작은 코드북을 사용하여 양자화를 수행한다.
이 방식은 큰 하나의 코드북을 쓰는 것보다 연산 오버헤드가 적고 여러 단계 인덱스를 저장하는 RVQ보다 저장 부담도 줄며 여전히 고정밀 표현을 유지할 수 있다.
즉, “연산량과 저장량 사이의 밸런스를 잘 맞춘 VQ 방식”이라고 볼 수 있다.
7. OMG의 핵심 아이디어 3: 정말 필요한 가우시안만 남기기
마지막 퍼즐 조각은 “어떤 가우시안만 남길 것인가” 이다.
OMG는 새로운 중요도 척도(importance metric) 를 제안한다. 각 가우시안이 주변 이웃들과 얼마나 다른지(local distinctiveness) 를 평가한다. 이 값이 큰 가우시안은 해당 위치에서 중요한 정보를 가지고 있다고 본다.
이 척도는 기존 연구에서 쓰이던 학습 뷰에서의 블렌딩 가중치 기반 중요도 점수와 함께 사용된다.
이를 통해
장면 품질을 유지하면서도, 진짜로 의미 있는 가우시안만 남기고 나머지는 더 과감히 제거할 수 있다.
Method & Experiment
1. 전체 아이디어 다시 정리
“가우시안 개수도 줄이고, 각 가우시안이 쓰는 메모리도 줄여서,
저장 용량·연산량 둘 다 줄이자” 이다.
2.1 무엇을 그대로 두고, 무엇을 바꾸는가
OMG는 geometry와 appearance를 다르게 취급한다. geometry(위치, 스케일, 회전)는 기존 3DGS처럼 가우시안마다 직접 학습한다. 희소한 설정에서는 가우시안 하나가 담당하는 공간이 넓어서, 위치나 모양까지 신경망으로 뭉개 버리면 품질이 많이 깨질 수 있기 때문이다. 반면 appearance(색과 불투명도)는 “per-Gaussian feature + 작은 neural field(MLP)” 구조로 바꾼다.
2.2 per-Gaussian feature와 위치 기반 neural field
OMG에서는 가우시안마다 두 가지 feature를 둔다. 첫째, 뷰와 상관없는 정적 색·불투명도용 feature . 둘째, 뷰 의존적인 색 변화를 표현하는 feature . 여기에 위치 을 positional encoding한 뒤, 아주 작은 MLP에 넣어 공간 feature 을 얻는다. 그런 다음 을 입력으로 하는 MLP에서 정적 SH 계수와 opacity를 출력하고, 을 입력으로 하는 다른 MLP에서 view-dependent SH 계수를 출력한다. 요약하면 은 각 가우시안만의 “불규칙한 디테일”, 은 위치 기반 “연속적인 패턴”을 담당한다. 이 구조 덕분에 가우시안마다 완전한 SH 계수를 직접 저장하지 않아도 되고, 더 짧은 feature + 작은 MLP로 appearance를 표현할 수 있다.
2.3 Sub-Vector Quantization(SVQ)로 feature 압축
그냥 feature를 두면 여전히 메모리가 크다. 그래서 OMG는 Sub-Vector Quantization(SVQ)라는 변형된 벡터 양자화를 사용한다. 기존 VQ는 차원 D짜리 벡터 전체를 하나의 큰 코드북에서 가장 가까운 코드워드로 치환한다. 고품질을 위해 코드북 크기를 키우면 K-means 초기화와 검색이 무거워지고, 메모리도 많이 쓴다. Residual VQ(RVQ)는 여러 단계의 코드북으로 잔차를 순차 보정하지만, 단계마다 인덱스를 저장해야 해서 저장량이 늘어난다. SVQ는 여기서 절충을 한다. feature 벡터 를 길이 짜리 서브벡터 개로 쪼개고, 각 서브벡터 마다 코드북 를 따로 둔다. 그다음 각 서브벡터는 자기 코드북 안에서 가장 가까운 코드워드 하나를 고르고, 이렇게 선택된 코드워드들을 이어 붙여 최종 양자화 벡터 를 만든다. 이렇게 하면 한 코드북이 처리하는 차원이 작아서 코드북 크기를 과하게 키울 필요가 적고, RVQ처럼 단계 인덱스가 누적되지도 않는다. OMG에서는 geometry 쪽의 스케일 , 회전 에도 SVQ를 적용하고, appearance 쪽에서는 과 을 이어 붙인 feature에 SVQ를 적용한 뒤 다시 으로 분리해서 쓴다. 학습은 끝까지 end-to-end로 돌리지 않고, 마지막 일정 단계에서만 한다는 점도 중요하다. 대략 마지막 step 정도를 남겨두고 현재 feature들에 대해 K-means로 코드북과 인덱스를 초기화한 뒤, 이후 구간에서는 인덱스는 고정하고 코드북만 렌더링 loss로 미세 조정한다. 코드북이 작아서 K-means도 금방 끝나고, 마지막 구간만 추가로 도는 구조라 전체 학습 시간 증가가 아주 작다.
3. Experiments: 성능과 분석
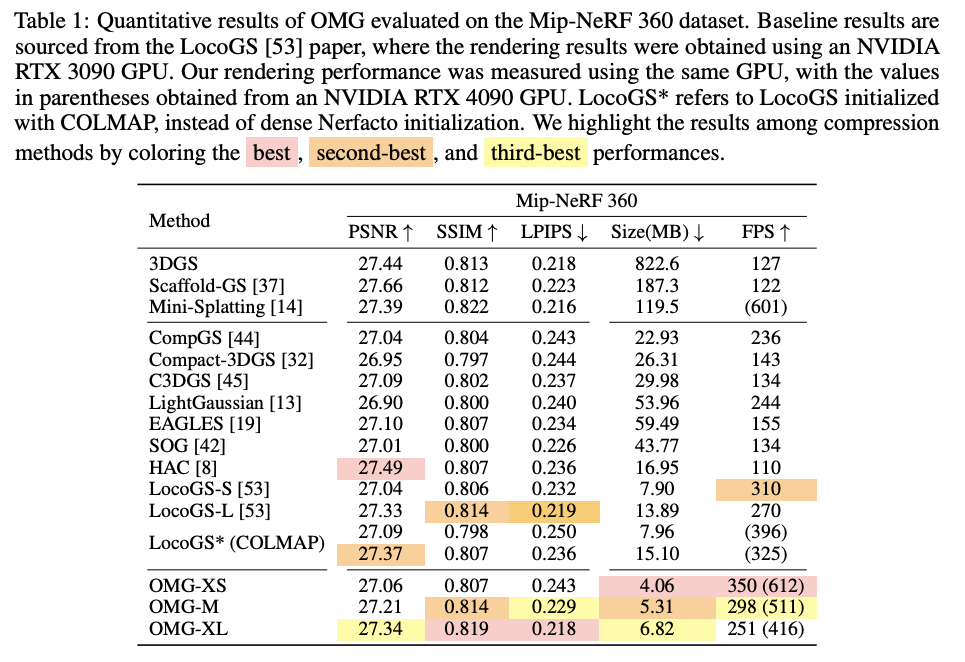
실험은 Mip-NeRF 360, Tanks & Temples, Deep Blending 등 대표적인 3DGS 벤치마크에서 진행하며, 3DGS 원본, Mini-Splatting, Scaffold-GS, CompGS, Compact-3DGS, LightGaussian, EAGLES, HAC, LocoGS 같은 기존 압축 기법들과 비교한다. OMG는 중요도 threshold 값만 바꾼 OMG-XS, M, XL 등의 여러 버전으로 평가한다.
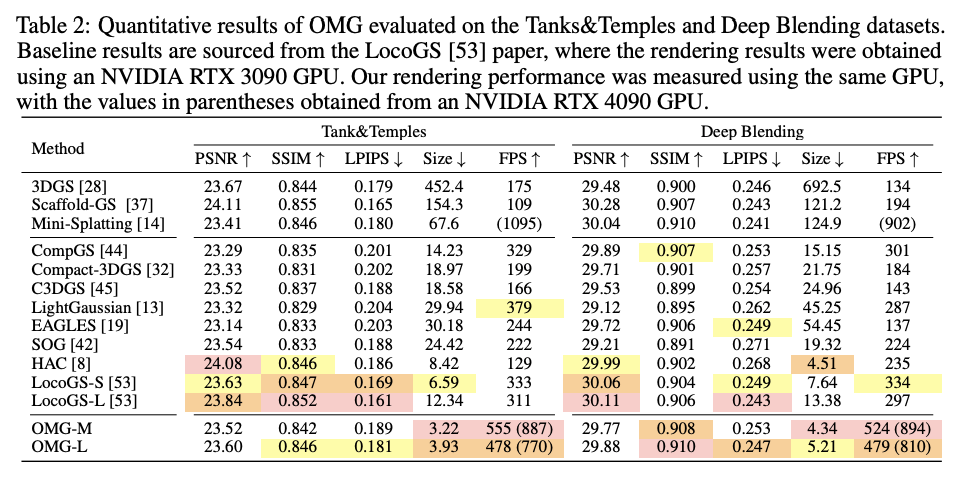
결과를 요약하면, OMG는 이전 SOTA와 거의 같은 화질을 유지하면서도 저장 용량을 대략 절반 수준까지 줄인다고 볼 수 있다. 예를 들어 Mip-NeRF 360에서 LocoGS와 비교했을 때, PSNR은 거의 같거나 약간 더 높으면서도, 모델 크기는 기존 방법보다 크게 줄어든다. 다른 데이터셋(Tanks & Temples, Deep Blending)에서도 OMG-M, OMG-L은 가장 작거나 그에 가까운 용량을 가지면서 PSNR, SSIM, LPIPS에서 기존 방법과 비슷하거나 더 좋은 값을 보여준다.
##
속도 측면에서도 이득이 크다. 고성능 GPU 기준으로 OMG-XS는 수백 FPS, 최대 600FPS 이상의 렌더링 속도를 달성하면서, LocoGS보다 더 빠른 경우가 많다. 학습 시간도 Mini-Splatting과 비슷한 수준이라, 별도로 큰 학습 비용을 치르지 않고도 압축과 속도 개선을 동시에 얻는 구조라고 볼 수 있다.
Ablation 실험에서는 제안한 구성요소들이 실제로 도움이 되는지 확인한다. Local Distinctiveness(LD)를 사용하면 같은 가우시안 수에서 화질이 더 좋아지고, 같은 화질 기준으로 가우시안 수를 더 줄일 수 있다. 위치 기반 공간 feature F_n를 제거하면 PSNR, SSIM, LPIPS가 전반적으로 떨어져, 희소한 가우시안 설정에서 작은 MLP가 연속성을 보완하는 역할을 한다는 점을 보여준다. 또한 SVQ를 일반 VQ나 RVQ로 바꿔보면, 학습 시간과 저장 용량, 화질을 모두 고려했을 때 SVQ가 가장 균형 잡힌 선택이라는 것도 확인한다.
마지막으로, OMG는 특정 구현에만 붙는 트릭이 아니라, 여러 3DGS 변형 위에 “압축 레이어”처럼 얹어서 쓸 수 있는 일반적인 프레임워크라는 점도 보여준다. 예를 들어 densification에 특화된 3DGS-MCMC에 OMG를 적용했을 때, 가우시안 개수는 그대로 유지하면서도 모델 용량을 수십 배 줄이고, 화질은 아주 조금만 감소하는 수준으로 유지할 수 있다.
4. Conclusion
OMG는 3D Gaussian Splatting에서 “가우시안 수를 줄이면 압축이 어려워지고, 압축을 세게 하면 화질이 무너지는” 기존 딜레마를 구조적으로 해결하려는 시도를 한다. 기하 정보는 그대로 per-Gaussian 파라미터로 두고, 색과 불투명도는 per-Gaussian feature와 위치 기반 경량 neural field를 조합해 표현함으로써, 희소한 가우시안 설정에서도 연속성과 세밀한 표현을 동시에 잡으려 한다. 여기에 Sub-Vector Quantization을 적용해 feature를 효율적으로 양자화하고, Local Distinctiveness 기반 중요도 점수로 중복된 가우시안을 정리함으로써, 저장 용량과 연산량을 함께 줄이는 설계를 완성한다.
실험 결과를 보면, OMG는 Mip-NeRF 360을 포함한 여러 데이터셋에서 기존 SOTA와 비슷하거나 더 나은 화질을 유지하면서도 모델 크기를 대략 절반 수준까지 줄이고, 수백 FPS 이상의 실시간 렌더링 속도를 달성한다. 또 3DGS-MCMC처럼 다른 변형에도 자연스럽게 붙일 수 있어, 특정 구현에 종속되지 않는 “범용 압축 모듈”에 가깝다는 점도 확인된다.
정리하면, OMG는 3DGS를 연구하거나 실제 시스템에 적용할 때 “저장 용량 + 실시간성”을 동시에 고민하는 상황에서 유력한 선택지가 되는 방법이라 할 수 있다. 앞으로 내 연구나 프로젝트에서 3DGS 기반 표현을 사용할 때, 단순히 NeRF 대체 재현 성능만 볼 것이 아니라, OMG와 같은 압축 기법을 함께 고려해 전체 시스템 리소스를 어떻게 설계할지까지 같이 고민하는 것이 중요하다고 느끼게 하는 논문이다.
