초록
상태 공간 모델(State Space Models, SSM)—가장 두드러지게는 RNN—은 역사적으로 순차 모델링에서 중심적인 역할을 수행해 왔습니다. 비록 트랜스포머(Transformers)와 같은 어텐션 메커니즘이 전역적 컨텍스트를 모델링하는 능력 때문에 이후 우위를 점했지만, 그들의 이차 복잡도(quadratic complexity)와 제한된 확장성은 긴 시퀀스에는 덜 적합하게 만듭니다. 비디오 초해상도(VSR) 방법들은 전통적으로 프레임 간에 피처를 전파하기 위해 순환(recurrent) 아키텍처에 의존해 왔습니다. 그러나 이러한 접근 방식은 소실되는 기울기(vanishing gradients), 병렬 처리 부족, 느린 추론 속도와 같은 잘 알려진 문제들로 어려움을 겪습니다. Mamba와 같은 선택적 SSM의 최근 발전은 설득력 있는 대안을 제시합니다: 선형 시간 복잡도로 입력 의존적인 상태 전이(input-dependent state transitions)를 가능하게 함으로써, Mamba는 강력한 장거리 모델링 능력을 유지하면서 이러한 문제들을 완화합니다. 이러한 잠재력에도 불구하고, Mamba 단독으로는 그 인과적 특성(causal nature)과 명시적인 컨텍스트 통합의 부족으로 인해 미세한 공간 의존성을 포착하는 데 어려움을 겪습니다. 이러한 문제를 해결하기 위해, 우리는 공간 컨텍스트 통합을 위한 시프티드 윈도우 자기 주의(shifted window self-attention, SWSA)와 효율적인 시간적 전파를 위한 Mamba 기반 선택적 스캐닝을 결합한 하이브리드 아키텍처를 제안합니다. 더욱이, 우리는 Mamba 전파 전에 시간적 윈도우 내의 중앙 앵커 프레임(center anchor frame)을 향해 피처를 워핑하고, 그 후에 이를 다시 분산(scatter)시키는 정렬 인식(alignment-aware) 메커니즘인 Gather-Scatter Mamba (GSM)를 소개합니다. 이는 가려짐 아티팩트(occlusion artifacts)를 효과적으로 줄이고 통합된 정보가 모든 프레임에 걸쳐 효과적으로 재분배되도록 보장합니다.
MAMBA란?
Mamba의 메인 : State Space Models
제어이론에서의 상태공간 방정식을 동일하게 사용한다. 다만, 제어이론에서의 상태공간방정식의 경우 연속된 변수를 가정해서 사용하는 방정식인데 딥러닝의 경우 변수가 전부 이산형이기에 이산화를 거쳐야한다.
이상화 방법에는 총 3가지가 크게 사용되는데 오일러, ZOH, 이중선형방식이 있고 MAMBA는 ZOH방식을 사용한다.
수식은 다음과 같은데 가 커지면 커질수록 B와 C는 고정된 상태에서 A만 계속해서 곱해지는 경향이 발생한다.
특징1. selective mechanism
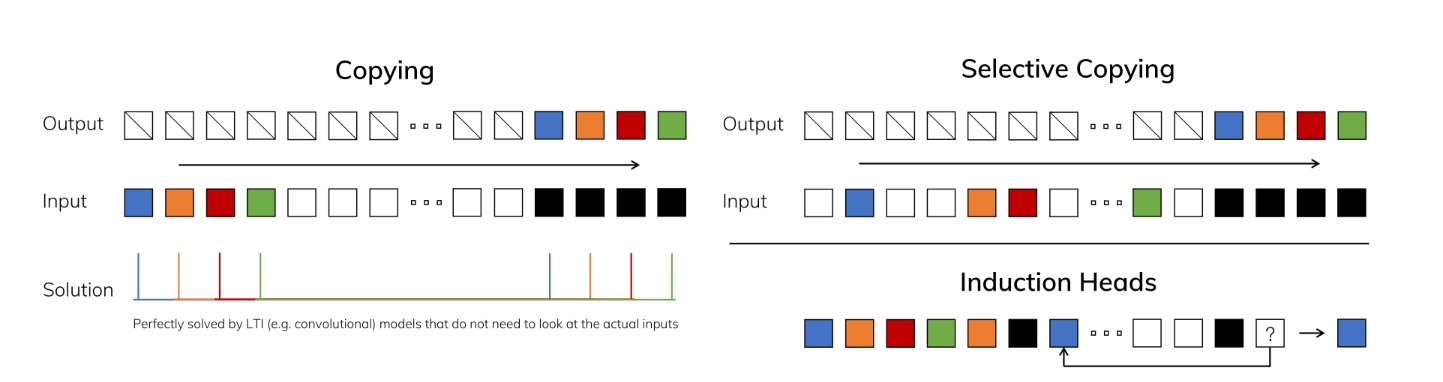
Mamba논문에서는 기존 SSM들은 과도하게 모든 토큰들을 계산하는 방식을 취하고 있기에 비효율적이라고 한다. 그래서 Mamba는 Delta값으로 제어할 수 있는 반경을 좁히는 방식을 선택했다.

Mamba는 S6방법론을 채택했다. 기존 있던 S4 -> 즉 SSM과 차이점은 파라미터로 존재했던 B,C를 x에 대한 output feature가 N인 선형함수로 치환한다.
GSM 구조 한눈에 보기
이 논문에서 제안하는 GSM(Gather-Scatter Mamba)는 비디오 초해상도(VSR)에 Mamba를 제대로 쓰기 위한 아키텍처라 한다. 저자들은 단순히 “기존 RNN을 Mamba로 바꿔 끼우는 것”이 아니라, Mamba의 특성을 고려한 공간·시간 분리 구조 + 정렬(align) 인지 메커니즘을 함께 설계한다. 전체 파이프라인은 대략 다음과 같이 구성된다.
먼저 입력 저해상도 비디오 에 대해, 한 프레임 단위로 시프티드 윈도우 자기주의(SWSA)를 적용해 공간(Spatial) 디테일을 보정한다. Swin Transformer처럼 윈도우를 기준으로 자기주의를 수행하되, 한 번은 원래 윈도우, 한 번은 shift된 윈도우를 사용해 로컬 컨텍스트를 잘 모으는 구조다. 여기까지는 프레임별 2D 처리 단계라 한다.
그 다음 단계가 이 논문의 핵심인 Window Propagation Module(WPM)이다. WPM은 일정 길이 의 시간 윈도우(예: 과거 2프레임, 현재 프레임, 미래 2프레임)를 잡고, 이 안에서 GSM 블록을 사용해 시간 방향 전파(Temporal propagation)를 수행한다. GSM 블록 내부에서는
1. Gather 단계에서 이웃 프레임들을 앵커 프레임(중앙 프레임)으로 optical flow로 워핑해 정렬시키고,
2. 정렬된 피처들을 시간축 우선 순서로 펼쳐서(temporal-first flatten) Mamba(SS2D)를 통과시킨 뒤,
3. Scatter 단계에서 Mamba 출력으로 얻은 residual을 각 프레임 위치로 다시 워핑해 되돌려준다.
이 과정을 윈도우를 슬라이딩시키며 앞 방향, 뒤 방향 두 번 반복해서 전체 시퀀스에 대해 양방향 전파를 수행한다. 위에서 공간 복원(SWSA)을 한 뒤, WPM을 통해 시간 정보를 모으고 퍼뜨리는 구조라서, “공간은 attention, 시간은 Mamba” 식의 역할 분담이 명확하게 이루어진다고 볼 수 있다.
Gather-Scatter의 핵심 아이디어
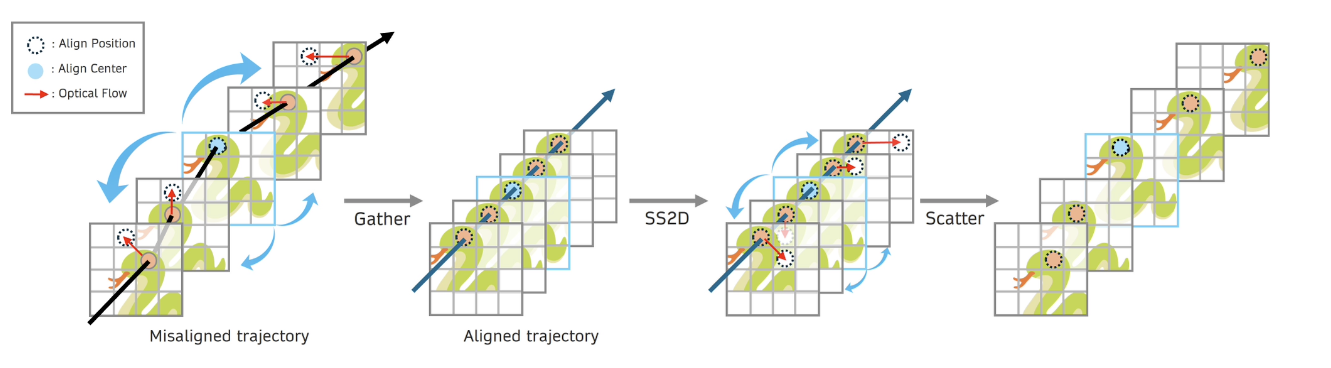
기존 VSR 모델들은 대부분 “한 프레임을 기준(anchor)으로 과거 프레임들을 워핑해서 가져오고, 그 기준 프레임만 업데이트하는 방식”을 많이 사용한다. 이 논문에서는 이를 forward-anchored propagation이라고 부르고, 이에 비해 center-anchored + scatter 방식이 더 유리하다고 주장한다.
먼저 forward-anchored 방식에서는 윈도우의 끝 프레임을 앵커로 잡고, 그 이전 프레임들을 모두 그쪽으로 워핑한다. 이때 먼 과거 프레임일수록 모션 경로가 길어지고, occlusion이 많이 발생하여 정렬이 틀어지기 쉽다. 그리고 정렬된 피처들은 “현재 앵커 프레임만” 업데이트하는 데 쓰이고, 나머지 지원 프레임(supporting frames)은 버려진다. 계산해 놓은 피처를 제대로 재활용하지 못한다는 뜻이다.
GSM은 이를 중앙 앵커(center anchor)와 scatter 단계로 해결한다. Gather 단계에서는 윈도우 가운데 프레임을 앵커로 두고, 양옆의 과거·미래 프레임들을 모두 중앙으로 워핑한다. 이렇게 하면 각 프레임이 앵커까지 이동하는 경로가 짧아져서 occlusion과 워핑 오차가 줄어든다. 이 상태에서 Mamba로 시간축을 스캔하여 긴 범위의 시간 정보를 모은 뒤, Scatter 단계에서는 그 결과 residual을 다시 각 프레임 위치로 역워핑해서 되돌린다.
즉, “모든 프레임 → 앵커로 모으기(Gather) → Mamba로 처리 → 다시 각 프레임으로 흩뿌리기(Scatter)” 흐름을 통해 윈도우 안에 있는 모든 프레임을 동시에 향상시키는 구조를 만든다. 이 덕분에
1. 각 프레임이 미래·과거 정보를 대칭적으로 공유할 수 있고,
2. 한 번 계산한 피처가 여러 번 재사용되며,
3. Mamba의 1D 시퀀스 스캔이 “정렬된 상태”에서 진행되기 때문에 공간 misalignment에 덜 취약해진다.
GSM 이론 메소드 정리
위에서 전체 구조를 개념적으로 봤으니, 이제 GSM이 내부에서 어떤 수식/연산 흐름을 갖는지 간단히 정리해보면 다음과 같다.
먼저 backbone(인코더)을 통과한 저해상도 피처를 라고 두고, 시간 윈도우 길이를 라고 하면 윈도우는
와 같이 정의된다. 여기서 가운데 프레임 가 center anchor 역할을 한다.
1단계: Gather (정렬 + 시퀀스화)
각 프레임 에 대해, optical flow 를 이용해 피처를 앵커 프레임으로 워핑한다.
\tilde{F}{i \rightarrow t}(x) = F_i(x + u{i \rightarrow t}(x))
여기서 x는 공간 좌표이고, flow를 통해 “프레임 i에서 앵커 프레임 t로” 픽셀 위치를 맞춰준다. 이렇게 하면 윈도우 안의 모든 프레임이 공간적으로 정렬된 기준 좌표계(앵커 좌표) 위로 모이는 효과가 생긴다.
그 다음, 정렬된 피처들을 시간축 우선으로 펼쳐서 시퀀스를 만든다.
여기서 각 는 를 공간 차원에서 flatten한 벡터라고 보면 된다. 논문에서는 이때 temporal-first scanning을 쓴다. 즉, (시간 → 공간) 순서로 토큰을 나열해서 “같은 공간 위치의 여러 프레임 정보”가 Mamba가 보기에 연속적으로 오도록 만든다.
2단계: Mamba 기반 선택적 스캔
이렇게 얻은 시퀀스 Z는 Mamba(SS2D) 블록으로 들어간다. 내부적으로는
형태의 상태공간 갱신을 수행한다. 여기서 은 앞에서 설명한 것처럼 입력 에 따라 달라지는 선택적(selective) 파라미터이다. 이 덕분에, 어떤 시간 위치/공간 위치의 토큰은 더 강하게, 어떤 토큰은 약하게 상태에 반영되도록 조절할 수 있다.
이 과정을 거치면, 중심 프레임 기준으로 모인 윈도우 내 정보가 Mamba를 통해 장거리(과거·미래)까지 섞인 상태의 출력 시퀀스 로 바뀐다. 이걸 다시 공간 차원으로 reshape하면 앵커 좌표계에서의 강화된 피처 를 얻는다.
3단계: Scatter (다시 각 프레임으로 분산)
이제 이 정보를 각 프레임으로 되돌려줘야 한다. 이를 위해, Gather 때 썼던 optical flow의 반대 방향 를 사용해 Mamba 출력의 residual을 각 프레임 위치로 warp한다.
,
이 식은 “원래 프레임 피처 + 앵커에서 모은 정보를 역워핑해서 더해준 residual” 구조로 이해하면 된다. 이렇게 하면 윈도우 안 모든 프레임이 한 번 모였다가(aggregate), 다시 흩어지는(redistribute) 과정에서 서로의 정보를 공유하게 되고, occlusion이 있던 영역도 다른 프레임 정보로 보완할 수 있게 된다.
실제 네트워크에서는 이 GSM 블록을 앞 방향(시간 증가) 스캔, 뒤 방향(시간 감소) 스캔 두 번 적용해서,
forward GSM에서 얻은 피처,
backward GSM에서 얻은 피처
를 concat하거나 더해서 최종 시간 피처로 사용한다. 이렇게 하면 RNN에서 흔히 쓰던 양방향(bi-directional) 구조처럼 과거·미래 컨텍스트를 동시에 활용하는 효과를 얻게 된다.

실험 결과
실험은 REDS, Vimeo-90K, Vid4 세 가지 대표 VSR 벤치마크에서 진행한다. REDS와 Vimeo-90K로 학습을 진행하고, REDS4, Vimeo-90K-T, Vid4에 대해 정량·정성 평가를 수행한다. 비교 대상은 TOFlow, EDVR 같은 전통적인 VSR부터 BasicVSR, BasicVSR++, VRT, RVRT, IART 같은 최신 강력한 방법까지 폭넓게 포함한다.
정량 결과를 보면, GSM은 Vimeo-90K-T에서 SOTA 혹은 그에 준하는 최고 수준의 PSNR, SSIM을 기록하고, REDS4와 Vid4에서도 기존 강력한 방법들과 비슷한 범위의 성능을 낸다. 특히 흥미로운 점은, GSM이 파라미터 수와 FLOPs 면에서 RVRT, IART 같은 Transformer 기반 모델들보다 더 가볍거나 비슷한 수준인데도, 성능은 거의 뒤처지지 않거나 일부 데이터셋에서 더 좋게 나온다는 점이다. 즉 “Transformer만이 고성능 VSR을 할 수 있는 것은 아니다”라는 메시지를 실험으로 보여준다고 볼 수 있다.
모델 효율성 측면에서도 GSM은 장점을 가진다. 저자들은 RTX 3090 기준으로 실행 시간을 측정했는데, GSM이 비슷한 성능의 VRT, IART에 비해 적은 파라미터와 FLOPs로 더 짧은 추론 시간을 달성함을 보고한다. 이는 Mamba의 선형 시간 복잡도와 window 기반 설계 덕분에 긴 시퀀스를 다루면서도 연산량을 일정 수준 이하로 유지할 수 있음을 보여준다.
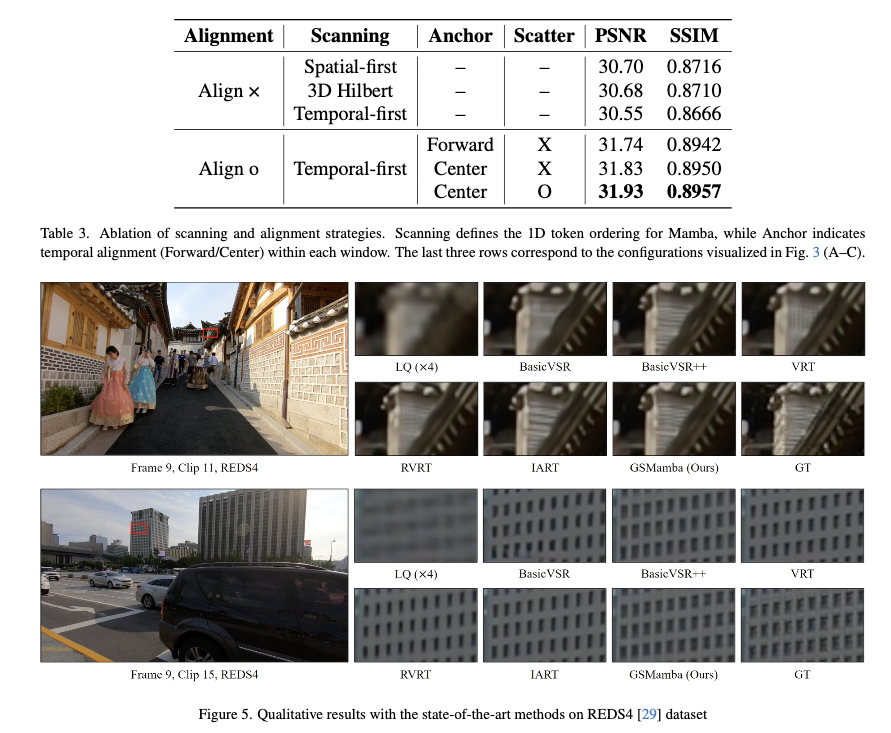
Ablation 실험에서는 세 가지 포인트를 확인한다. 첫째, Mamba를 쓸 때 temporal-first scanning이 spatial-first나 3D Hilbert 스캔보다 VSR에서 더 잘 작동한다는 것을 보인다. 단, 이 경우 반드시 Gather로 정렬을 먼저 해줘야 Mamba가 오동작하지 않는다. 둘째, Scatter를 끄고 anchor 프레임만 업데이트하는 설정과 비교했을 때, Scatter를 켜면 PSNR, SSIM이 추가로 올라가며, 윈도우 안 모든 프레임을 같이 업데이트하는 것이 temporal consistency에 도움이 된다는 점이 확인된다. 셋째, 앵커를 forward(미래 끝 프레임) 대신 center에 놓는 것이 occlusion 감소와 워핑 오차 감소 측면에서 유리하며, 실제로 center-anchored 설정이 항상 더 높은 성능을 낸다는 것도 실험으로 보여준다.
결론 및 코멘트
이 논문은 “비디오 초해상도에서 RNN 대신 Mamba를 쓰면 어떻게 설계해야 하는가”라는 질문에 대해 꽤 명확한 답안을 제시한다고 볼 수 있다. 단순히 SSM 블록을 하나 끼워 넣는 것이 아니라,
1) 공간 정보는 shifted window self-attention으로 맡기고,
2) 시간 정보는 Mamba를 중심으로 한 Gather-Scatter 구조로 설계하며,
3) 앵커 위치와 윈도우 설계를 세심하게 튜닝함으로써 기존 Transformer 기반 VSR과 경쟁 가능한 수준의 성능과 효율을 동시에 달성한다.
학부생 입장에서 이 논문을 읽으면서 느끼는 포인트는 두 가지 정도로 정리된다.
첫째, Mamba 같은 SSM 계열 모델을 비전 문제에 쓸 때는 “어디에 붙일 것인가”보다 “어떤 순서로 토큰을 스캔하고, 어떤 정렬 정보를 제공할 것인가”가 훨씬 중요하다는 점이다.
둘째, 비디오 복원 문제에서는 한 프레임만 잘 복원하는 것보다, 여러 프레임을 창(window) 단위로 함께 업데이트하고, 계산한 피처를 최대한 재사용하는 설계가 성능과 효율 모두에서 유리하다는 점이다.
나중에 Mamba 계열 모델을 다른 시퀀스 비전 문제(예: 비디오 디노이징, 3DGS 시간 전파, 영상 기반 3D 재구성 등)에 적용해 보고 싶다면, 이 논문에서 제안하는 Gather-Scatter + center-anchored 윈도우 + temporal-first 스캔 패턴을 기본 템플릿으로 삼고, 도메인에 맞게 alignment 모듈이나 윈도우 크기만 조절해보는 접근이 꽤 실용적인 출발점이 될 것이라 생각한다.
