
들어가며
Mysql의 기본 트렌잭션 격리수준은 Repeatable Read이다. 트랜잭션 격리수준을 공부하다보면 Repeatable Read는 Phantom Read가 발생한다고 하는데 특이하게 Mysql은 발생하지 않는다고 한다. 정말 그럴까?
결론
결론부터 말하면 Mysql의 스토리지 엔진인 InnoDB 덕분이다.
InnoDB는 MVCC, Next-Key Lock과 같은 기술을 사용하여 Phantom Read를 방지한다.
스토리지 엔진이 무엇인지, Mysql은 어떠한 스토리지 엔진을 사용하는지 살펴보며 어떻게 Phantom Read를 방지하는지 알아보도록 하자.
스토리지 엔진
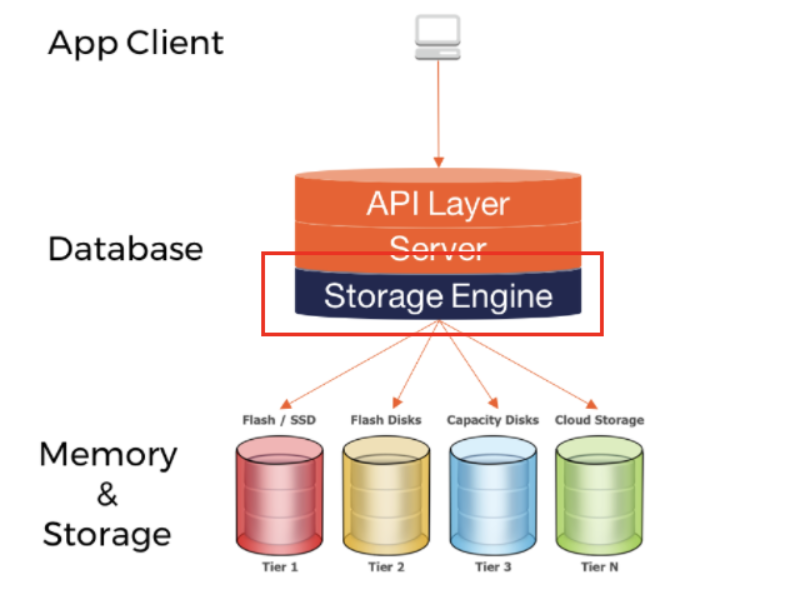
스토리지 엔진이란 서버 엔진이 필요한 물리적인 데이터를 가져오는 장치를 말한다. DBMS가 데이터베이스에 대해 데이터를 삽입, 추출, 업데이트 및 삭제하는 데 사용하는 기본 소프트웨어 컴포넌트이다.
Mysql에서 테이블을 생성하면 실제로 서버상에는 frm이라는 파일을 생성한다. 이 파일에 접근하는 속성을 설정하는 것이 바로 스토리지 엔진이다. 현대의 많은 DBMS가 동일한 DB 내에 다중 스토리지 엔진을 지원한다. 스토리지 엔진은 동일 DB내의 테이블마다 다르게 지정이 가능하다.
Mysql에서 사용되는 대표적인 스토리지 엔진으로는 MyIsam과 InnoDB가 있다. 간단하게 차이를 알아보자면,
MyIsam은 트랜잭션이 필요없고 읽기 작업이 많은 서비스일수록 효율적이다.
InnoDB는 트랜잭션이 필요하고 대용량 데이터를 다루는 서비스일수록 효율적이다.
그렇다면 이러한 스토리지 엔진은 어떠한 역할을 하는걸까?
역할
스토리지 엔진은 다음과 같은 역할을 하는 컴포넌트로 구성된다.
- 트랜젝션 매니저 : 트랜잭션을 스케줄링하고 데이터베이스 상태의 논리적 일관성을 보장한다.
- 잠금 매니저 : 트랜잭션에서 접근하는 데이터베이스에 대한 잠금을 제어하며, 데이터의 무결성을 지키는 역할을 한다.
- 액세스 메소드 : 디스크에 저장된 데이터에 대한 접근 및 저장 방식을 정의한다.
- 버퍼 매니저 : 데이터 페이지를 메모리케 캐시한다.
- 복구 매니저 : 로그를 관리하고 장애 발생 시 시스템을 복구한다.
이제 스토리지 엔진의 종류에 대해 알아보자. 아래에서 서술할 MyIsam, InnoDB를 제외하고도 Archive, Cluster, Federated가 있지만 이번 글에서는 MyIsam, InnoDB만 소개하도록 하겠다.
MyIsam
MyISAM은 My Indexed Sequential Access Method의 약어로 웹, 데이터 웨어하우징 및 기타 분석 환경에서 자주 사용된다. 정적인 데이터를 저장하고 자주 읽기 작업이 일어나는 테이블에 적합하다.
-
Mysql 5.5 버전 이전의 기본 스토리지 엔진
-
구조가 단순해, 속도가 빠르다.
-
데이터 저장에 실제적인 제한이 없고 매우 효율적으로 저장한다.
→ 메모리 효율이 InnoDB보다 좋다.
-
테이블 작업시 특정 행을 수정하려고 하면 테이블 전체에 락이 걸려서 다른사람이 작업 할 수 없다. (Table-level Lock)
→ 갱신이 많은 용도로는 성능적으로 불리하여 동시성 작업이 많이 발생하는 서비스에 적합하지 않다.
→ row의 수가 커지면 커질수록 그만큼 테이블 전체에 락이 걸려 작업이 지연되기에 CRUD 속도가 매우 느려진다.
→멀티 스레드환경에서는 성능이 저하될 수 있다. -
트랜잭션에 대한 지원이 없기때문에 작업도중 문제가 생겨도 이미 DB안으로 데이터가 들어간다. DB 프로세스가 비정상 종료하면 테이블이 파손될 가능성이 높다.
→ 데이터 무결성이 보장되지 않는다. -
Full-text검색이 가능하다 -
주로
select작업이 많은 경우에 사용된다. 즉, 읽기작업에 효과적이다.
✅ InnoDB로 전환된 이유
MyISAM의 가장 부족한 점은 트랜잭션의 지원 부재였다. MySQL 5.5과 이후 버전은 참조 무결성 제한과 더 높은 동시성을 보장하기 위해 InnoDB 엔진으로 전환되었다.
InnoDB
InnoDB는 MySQL을 위한 데이터베이스 엔진이며, MySQL AB가 배포하는 모든 바이너리에 내장되어 있다. MySQL과 사용할 수있는 다른 데이터베이스 엔진에 대한 개선 사항으로 PostgreSQL을 닮은 ACID 호환 트랜잭션에 대응하고 있는 것이 있다. 또한 외래 키(FK)도 지원하고 있다. (이것을 선언적 참조 무결성이라 한다.)
-
데이터 입력 및 수정이 빈번한 높은 퍼포먼스를 요구하고 다중 사용자, 동시성이 높은 OLTP 애플리케이션에 적합하다.
-
Mysql, MariaDB의 기본 스토리지 엔진
-
MyISAM보다 데이터 저장비율이 낮고, 데이터 로드 속도가 느리다.
-
레코드 기반의 락(Lock)을 제공한다. 즉, 테이블 레벨이 아닌 ROW 레벨의 락을 지원한다. 이로 인해 높은 동시성 처리가 가능한 특징이 있고 안정적이다.
→ insert,update,delete에 대한 속도가 빠르다 -
외부키를 지원한다
-
자동 데드락 감지 : 감지 시 변경된 레코드가 가장 작은 트랜잭션을 롤백해버려서 데드락을 풀어준다.
-
자동 장애 복구 : 완료하지 못한 트랜잭션이나 일부만 기록되어 손상된 데이터 페이지 등을 자동 복구한다.
-
데이터 무결성 보장(트랜잭션, 외래키, 제약조건, 동시성 등) - ACID
-
Primary Key를 기준으로 클러스터링되어 저장된다. 즉, PK를 기준으로 순서대로 디스크에 저장되는 구조로 PK에 의한 Range Scan이 빠르다.
→ 데이터를 PK순서에 맞게 저장한다는 뜻이므로order by등 쿼리에 유리할 수 있다. -
인덱스와 더불어 데이터까지 버퍼풀에 저장하기 때문에 모든 데이터가 메모리에 있으면 디스크를 읽지 않아도 된다.
→ 데이터 접근 속도가 빠르다
→ 인덱스와 데이터 모두 메모리에 적재되므로 메모리 사용 효율에 좋지 않다.
→ 메모리 때문에 로그 수집에 대한 용도로 InnoDB를 사용하면 안된다.
✅ Data 압축
MySQL 서버에서 디스크에 저장된 데이터 파일의 크기는
1. 쿼리의 처리 성능
2. 백업 및 복구 시간
3. 저장 비용
과 밀접하게 연결된다. 이러한 문제를 해결하기 위해 Data 압축을 사용한다.
MySQL 서버는 디스크에 저장하는 시점에 데이터 페이지가 압축되어 저장되고, 디스크에서 데이터 페이지를 읽어올 때 압축이 해제되는 방식이다. 버퍼 풀에 데이터 페이지가 한 번 적재되면, InnoDB 스토리지 엔진은 압축이 해제된 상태로만 데이터 페이지를 관리하고 MyISAM 는 압축형식을 취한다.
스토리지 엔진들의 특징들을 살펴보았는데, 그래서 InnoDB는 어떻게 팬텀 리드를 막는걸까?
Repeatable Read
InnoDB는 MVCC(Multi Version Concurrency Control)라는 매커니즘을 이용해 언두 영역에 이전 데이터를 백업해두고 실제 레코드 값을 변경한다.
MVCC
데이터베이스에서 동시성을 제어하기 위해 사용하는 방법으로 새로운 값을 업데이트하면 이전 값은 언두 영역에 관리함으로써 하나의 레코드에 대해 여러 개의 버전이 동시에 관리된다. MVCC의 가장 큰 목적은 잠금을 사용하지 않는 일관된 읽기를 제공하는 데 있다.
Repetable Read는 같은 트랜젝션 내에서 동일한 결과를 보장받을 수 있는 트랜젝션 격리수준으로 Mysql InnoDB의 기본적인 격리수준이다.
그럼 Repeatble Read는 어떻게 동일한 결과를 보장해줄까? 앞서 말했던 MVCC에 유의하며 아래 이미지를 보자.
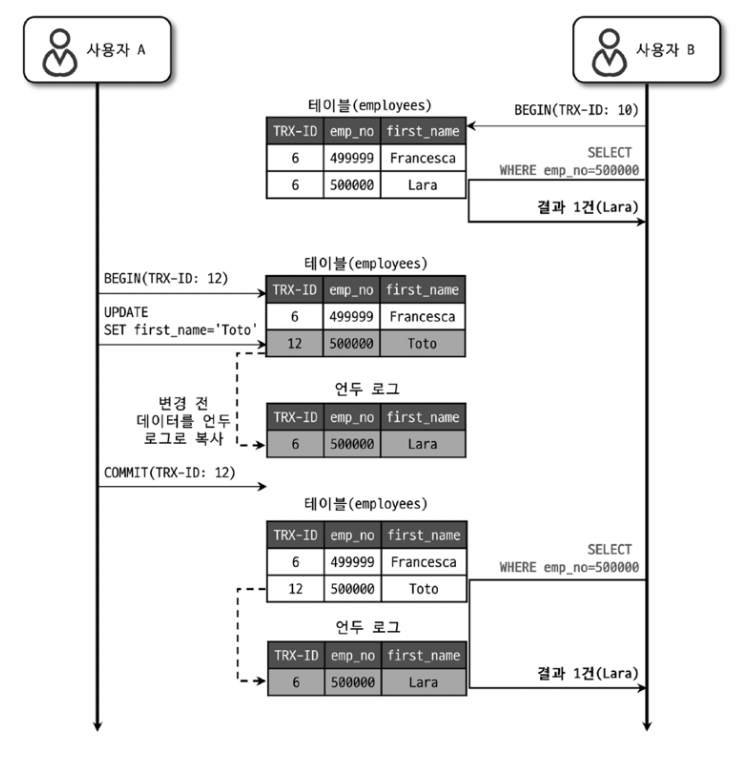
트랜잭션 ID 10사용자 B가 employees 테이블을 조회한다.트랜잭션 ID 12사용자 A가 employees 테이블을 수정한다. (first_name = Lara→first_name = Toto)- 언두 로그로 변경 전 데이터를 복사한다.
트랜잭션 ID 10사용자 B가 employees 테이블을 다시 조회할 때, 언두 로그에 있는Lara를 반환한다.
사용자 B가 4번에서 다시 테이블을 조회할 때, 트랜잭션 ID 12보다 늦게 시작되었기 때문에 본인의 트랜잭션 ID(10)보다 작은 값을 읽기에 언두 로그를 읽었다. 그렇다면, 반대의 경우는 어떨까?
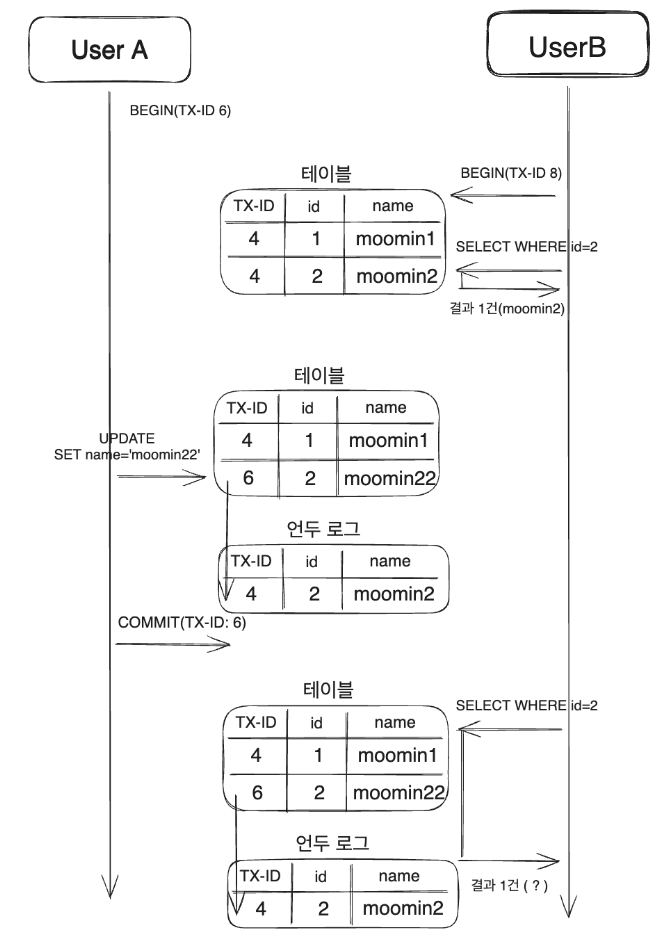
결과적으로는 동일한 name=moomin2를 반환하게 된다. 왜냐하면 위에서 설명한 MVCC덕분이다.
비록 낮은 트랜잭션에서 변경되었더라도 실제 트랜잭션 ID 8이 처음 조회된 시점의 스냅샷을 저장하기 때문에 트랜잭션의 처음부터 끝까지 일관된 데이터를 가지는 것이다. 이것이 mysql InnoDB가 Phantom Read를 방지하는 이유이다.
하지만 이러한 MVCC도 모든 상황에 대해 Phantom Read를 막지는 못한다.
✅ Phantom Read
Repeatable Read에서 새로운 레코드의 삽입까지는 막지 않기 때문에SELECT로 조회했을 때 다른 트랜잭션에 의해 추가된 데이터를 얻을 수 있는데 이를Phantom Read라 한다.
Select ... for Update
MVCC를 사용하면 일반적인 조회에서는 팬텀 리드가 발생하지 않는다.
select ~ for update의 경우, 읽기 쿼리지만 변경 쿼리와 같이 레코드에 exclusive lock을 건다. 언두 레코드에는 잠금을 걸 수 없기 때문에 잠금을 하고 조회하는 레코드의 경우 언두 영역의 변경 전 데이터를 가져오는 것이 아니라 현재 레코드의 값을 가져오게 된다. 이로 인해 데이터의 부정합이 일어나 팬텀 리드가 발생한다.
실제로 변경이 일어나는 레코드가 1건이더라도, where절에 걸린 레코드가 100건이라면 100건 모두 잠근다.
예를 들어, Orders라는 테이블이 있고 이 테이블에는 여러 주문 정보가 담겨 있다. 각 주문은 status라는 필드를 가지고 있으며, 이 필드의 값은 pending, completed 등이 있다고 가정해보자.
START TRANSACTION;
SELECT * FROM Orders WHERE status = 'pending' FOR UPDATE;
START TRANSACTION;
INSERT INTO Orders (order_id, status) VALUES (123, 'pending');
COMMIT;
// 팬텀 리드 발생
SELECT * FROM Orders WHERE status = 'pending' FOR UPDATE;- 트랜잭션 A가
status = pending주문에 잠금을 걸고 조회한다. - 트랜잭션 B가 새로운
status = pending주문을Orders테이블에 삽입한다. - 트랜잭션 A에서 다시
status = pending주문을 조회한다. - 첫 조회에서 볼 수 없던 트랜잭션 B의 값이 추가되어있다.
이를 방지하기 위해서 InnoDB는 Next-Key Lock을 통해 사용한다.
Next-Key Lock
넥스트 키 락이란 레코드 락과 갭 락을 합친 잠금으로, 갭 락과 함께 사용된다. 변경을 위해 검색하는 레코드에 넥스트 키 락 방식으로 잠금이 걸리면, 해당 레코드에 대해 잠금을 걸고 인접 레코드와의 간격에도 잠금을 걸게 된다.
일반적으로 레코드 락은 테이블 레코드 자체를 잠그는 락을 의미한다. 갭락은 레코드가 아닌 레코드와 레코드 사이의 간격을 잠금으로써 레코드의 생성, 수정 및 삭제를 제어한다.
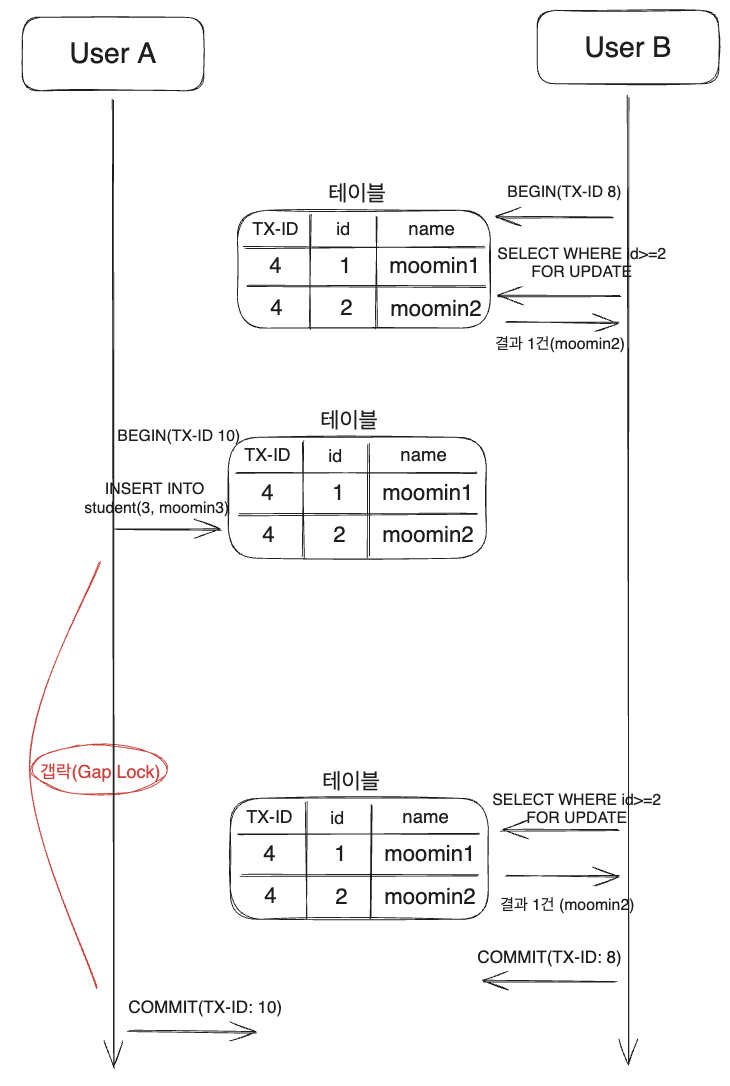
트랜잭션 ID 8은 Select For Update를 통해name=mommin2결과를 얻고 잠금을 건다.- 2번 레코드에 레코드 락과 2보다 큰 범위에는 갭락으로 넥스트 키 락이 걸리게 된다.
트랜잭션 Id 10은mommin3을Insert하려고 하지만 락으로 인해 대기한다.트랜잭션 ID 8은 Select For Update를 통해 조회를 한다. 언두 로그 대신 실제 테이블을 읽지만 락이 걸려있어 3번 결과가 아직insert되지 않았기 때문에 1번과 동일한 결과를 얻는다.트랜잭션 ID 8이 커밋되면 갭락이 해제되면서트랜잭션 ID 10의 작업이 재개된다. (Insert수행)
그런데, 공부하던 도중 Mysql은 Select → Insert → Select For Update의 경우는 유일하게 팬텀리드가 발생하게 된다는 것을 알게 되었다. 물론, 일반적인 RDBMS도 동일하게 팬텀리드가 발생한다.
우선 이미지부터 보자.
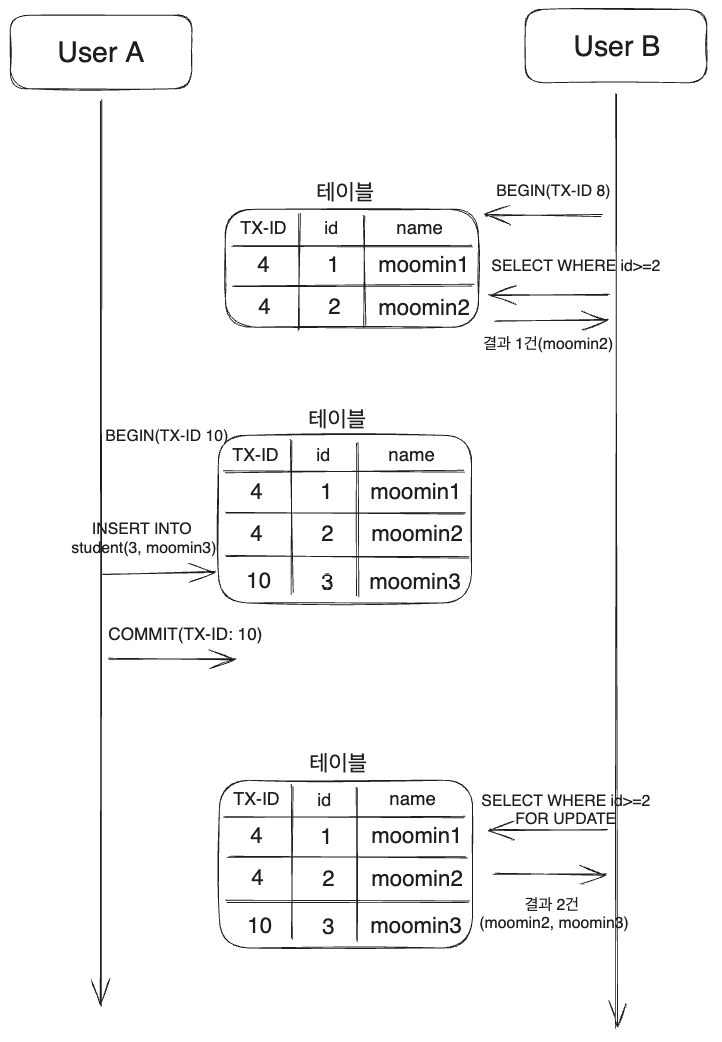
트랜잭션 ID 8은 아무 잠금없이 조회하여name=moomin2결과를 얻는다.트랜잭션 ID 10은 잠금이 없기 때문에 정상적으로Insert된다.트랜잭션 ID 8Select For Update로 조회하기 때문에 해당 행에 대한 가장 최근에 커밋된 정보를 가져온다. 즉, 2번의 결과도 가져오게 되어 2건이 조회되고 잠금이 걸린다.
직접 쿼리문으로 작성한 예제는 다음과 같다.
mysql> begin; // 트랜잭션 A 시작
Query OK, 0 rows affected (0.00 sec)
mysql> select * from Category;
+------------+--------------+
| CategoryNo | CategoryName |
+------------+--------------+
| 1 | Novel |
| 2 | Science |
+------------+--------------+
2 rows in set (0.00 sec)
mysql> insert into Category values (3, 'ho'); // 트랜잭션 B 첫 select 이후 실행
// Category 테이블에 CategoryNo = 3, CategoryName = ho 추가함
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
--------------------------------------------------
mysql> begin; // 트랜잭션 B 시작
Query OK, 0 rows affected (0.00 sec)
mysql> select * from Category; // Category 조회
+------------+--------------+
| CategoryNo | CategoryName |
+------------+--------------+
| 1 | Novel |
| 2 | Science |
+------------+--------------+
2 rows in set (0.00 sec)
mysql> select * from Category for update; // 첫 조회에선 보이지 않는 CategoryNo = 3, CategoryName = ho 조회. 팬텀리드 발생!
+------------+--------------+
| CategoryNo | CategoryName |
+------------+--------------+
| 1 | Novel |
| 2 | Science |
| 3 | ho |
+------------+--------------+
3 rows in set (0.00 sec)
✅ Select For Update
데이터 수정을 위해Select한다는 뜻이다. 해당 구문이 실행되면 동시성 제어를 위해 특정 Row에 대해 베타적 락을 걸게 된다. 해당 세션이Update쿼리 후,Commit을 하기 전까지는 다른 세션은 해당Row를 수정할 수 없다. 이 구문 실행 시, 해당 행에 대해 가장 최근 커밋된 버전을 잠금 상태로 만든다.
마치며
Mysql이 개발자에게 편의성을 많이 제공해주는 것 같다. 특히, 글을 작성하며 Dirty Read와 Unrepeatable Read가 조금 헷갈렸는데 확실히 알게 되었다.
