MLOps란
- ML(Machine Learning, 머신 러닝)과 Ops(Operations, 운영)의 합성어
- 머신 러닝 모델을 안정적이고 효율적으로 배포 및 유지 관리하는 것을 목표
- 머신 러닝 프로그램의 개발, 배포, 관리 및 모니터링을 위한 연속적인 작업 프로세스
LLMOps란
- LLMOps는 "LLM"과 "Ops"의 합성어로 MLOps의 한 패러다임
- 프로덕션 환경에서 대규모 언어 모델을 배포하고 유지 관리하여 규모와 성능에 대한 기대치를 충족하는 데 중점을 둔다.
- 대규모 언어 모델을 효율적으로 배포, 모니터링 및 유지 관리할 수 있다.
MLOps Flow
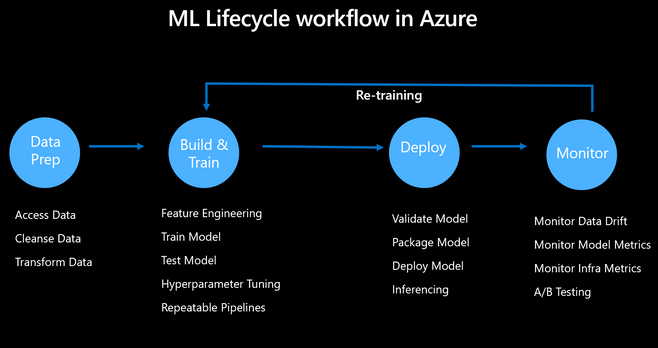
-
데이터 준비: 필요한 데이터를 수집하고 정리하여 머신러닝 알고리즘에 적합한 형식으로 변환
-
모델 구축 및 학습: 적합한 알고리즘을 선택하고 사전 처리된 데이터를 입력하여 패턴을 학습하고 예측할 수 있도록 하며 반복적인 하이퍼 파라미터 튜닝과 반복 가능한 파이프라인을 통해 모델의 정확도를 개선한다.
-
모델 배포: 모델을 API로 서빙
-
모델 관리 및 모니터링: 성능 메트릭을 모니터링하고, 데이터 및 모델 드리프트를 감지하고, 모델을 재교육하고, 이해 관계자에게 모델 성능을 전달
| Model Selection | Training / Fine-tuning data prep | Model Configuration | Monitoring training / fine-tuning process | Deploy the trained/ fine-tuned model | Maintain model in production(Monitor, upgrade, replace) |
|---|---|---|---|---|---|
| 모델 버전 평가 및 선택 | 데이터 수집, 랭글링, 정리 및 라벨링 | 하이퍼파라미터 튜닝을 포함한 파인 튜닝 프로세스 설정 | 메트릭 추적, 훈련 중 모델 성능 평가 | 학습된 모델 스테이징, 테스트 및 배포 | 모델 성능 모니터링측정된 성능에 기반하여 업그레이드 또는 교체 |
LLMOps Flow
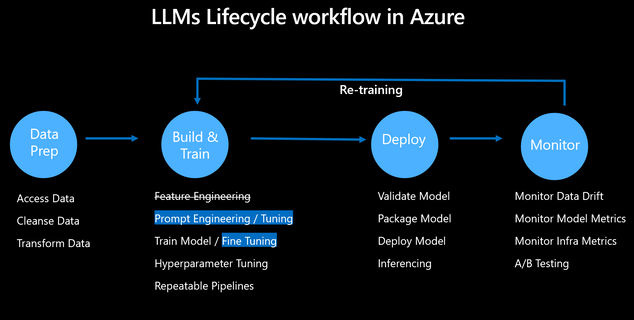
- ML 모델과 매우 유사하지만, 이미 사전 학습된 모델이기 때문에 값비싼 모델 학습을 거칠 필요가 없다.
- LLMOps는 실제 애플리케이션을 위한 대규모 언어 모델의 배포 및 관리를 간소화하는 데 중요한 역할을 한다.
| Model Selection | Training / Fine-tuning data prep | Model Configuration | Monitoring training / fine-tuning process | Deploy the trained/ fine-tuned model | Maintain model in production(Monitor, upgrade, replace) |
|---|---|---|---|---|---|
| 사전 학습된 모델 평가 및 선택 | 다양성과 대표성에 중점을 둔 대규모 데이터 수집자동 라벨링 기법을 사용 | 프롬프트 디자인과 모델에 맞는 조정을 고려한LLM을 위한 파인튜닝 설정 | 파인튜닝 진행 상황 모니터링, 메트릭 추적, 문제 식별 및 조정 | 파인튜닝된 LLM을 배포 | 지속적인 모니터링, 필요한 업그레이드 식별진화하는 요구 사항과 발전에 따라 모델 교체 검토 |
MLOps 적용 사례 및 예상 LLM 적용 방안
SK텔레콤 에이닷
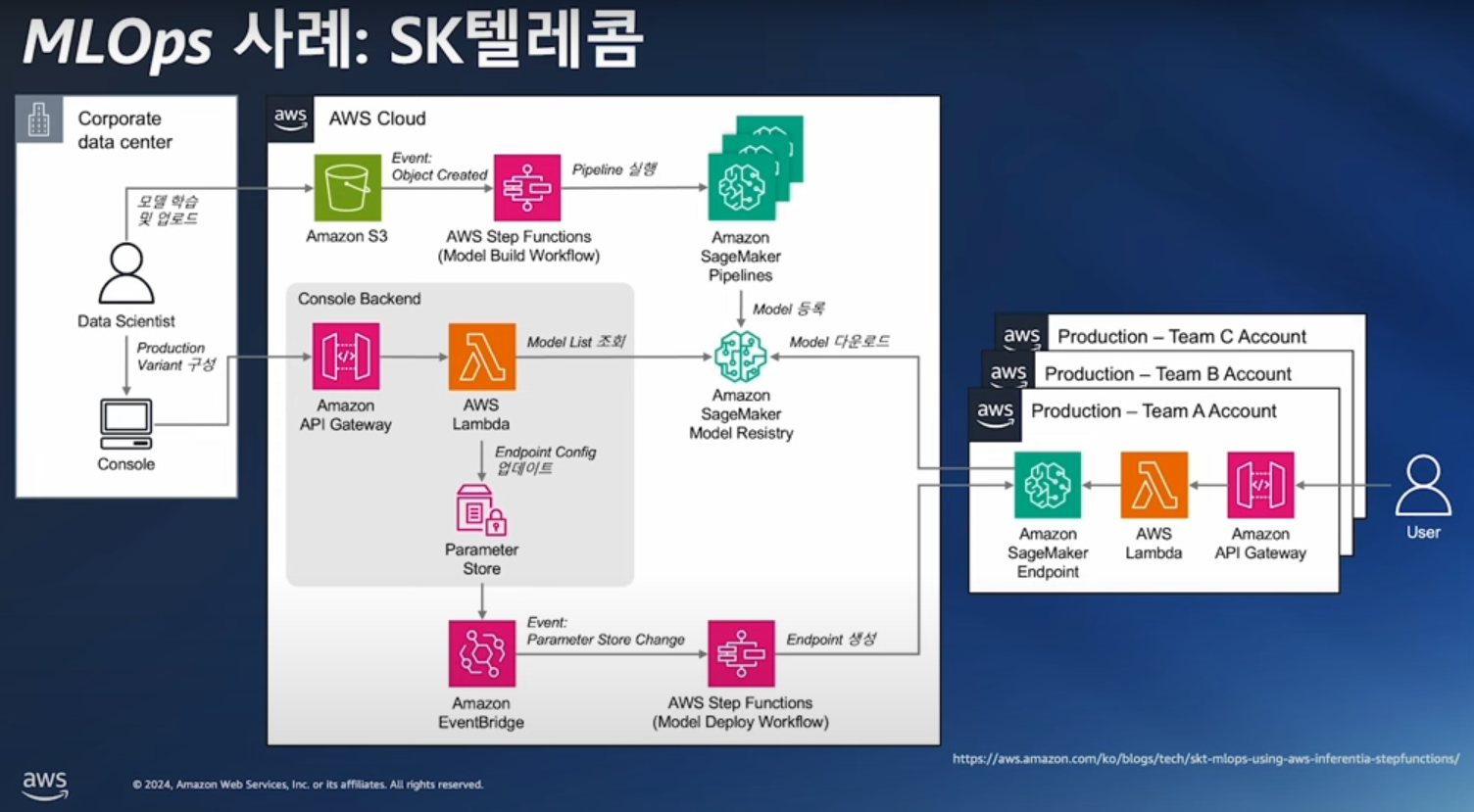
- 온프레미스 데이터 센터의 사용자에서 시작
- 데이터 사이언티스트가 학습한 모델 -> S3에 업로드
- 업로드된 모델은 AWS Step Funtions -> SageMaker Pipelines 통과
- 통과된 모델은 AWS Neuron SDK로 컴파일 후 -> SageMaker Model Resistry 적재
- 데이터 센터의 사용자는 Model Registry에 있는 모델 리스트를 확인하고 관리하며
- SageMaker Endpoint에서 Inferentia 기반의 인스턴스를 통해 Rest API로 실시간 추론을 시행
- SageMaker Endpoint 빌트인 추론 컨테이너로 고가용성, 다중 모델 로딩, A/B 테스트를 위한 인프라 환경이 사전 구축되어 있음
예상 LLMOps 변환
- 데이터 준비 및 모델 학습
- 온프레미스나 클라우드에서 대규모 언어 데이터를 수집, 정제
- 사전 학습된 LLM(OpenAI GPT, LLaMA 등)을 훈련
- 데이터 사이언티스트가 모델 학습 코드를 작성해 S3에 업로드
- 파이프라인 통과
- AWS Step Functions와 SageMaker Pipelines를 사용해 학습과 파인튜닝 과정을 자동화
- 언어 모델 특화된 LoRA(저랭크 적응)나 QLoRA 같은 기법을 활용해 대규모 모델을 효율적으로 튜닝
- 컴파일 및 Model Registry 등록
- AWS Neuron SDK 대신 Hugging Face Optimum이나 ONNX Runtime을 활용해 모델을 경량화 및 최적화.
- 학습된 모델을 SageMaker Model Registry에 등록하여 버전 관리
- 배포 및 추론
- SageMaker Endpoint를 통해 API로 대화형 LLM 제공
- 다중 모델 로딩(A/B 테스트, Canary 배포)과 고가용성 확보
- 추론 요청은 API Gateway를 통해 클라이언트와 연결
롯데ON (개인화 서비스 추천 시스템)
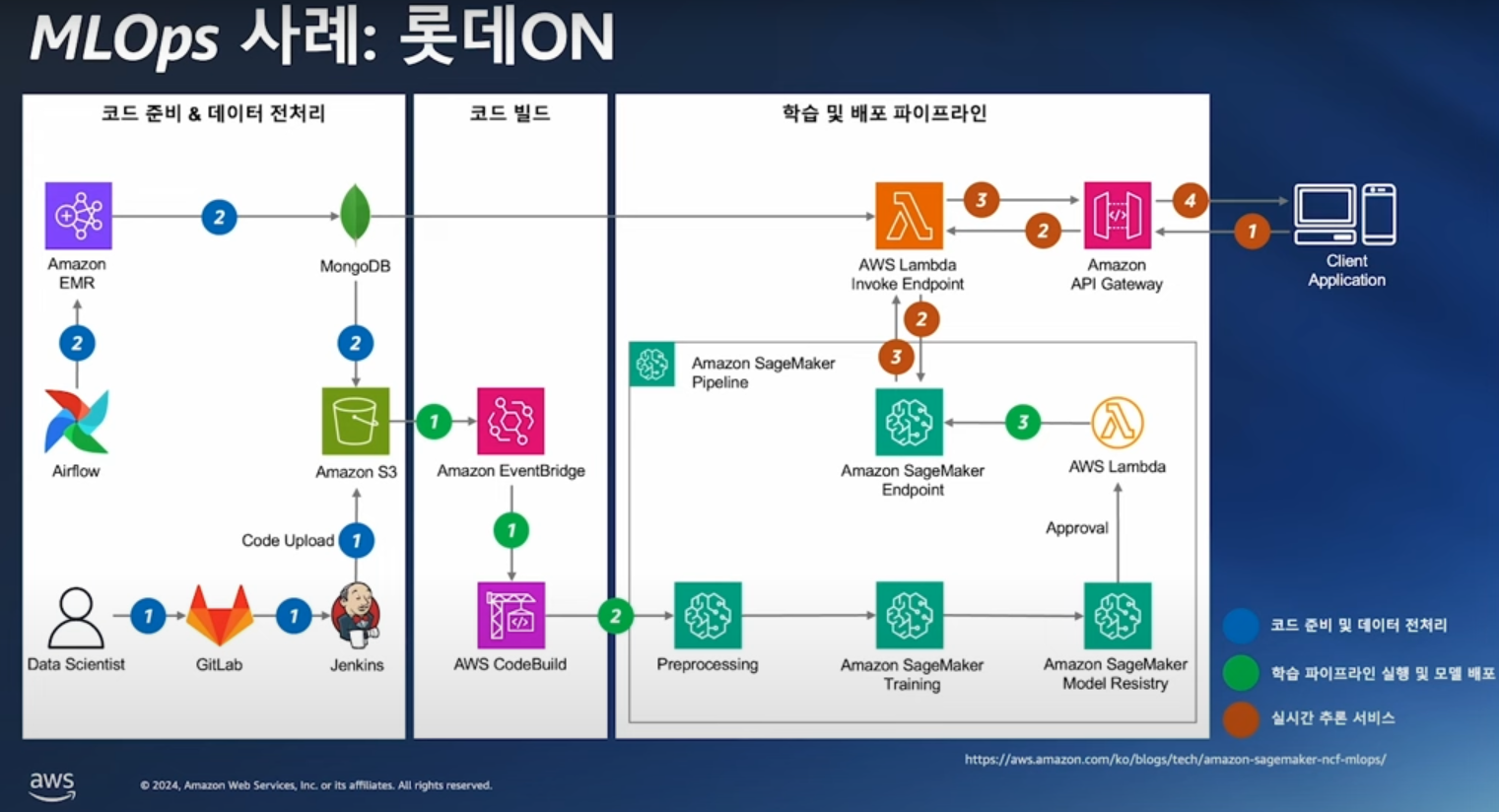
- 코드 준비 & 데이터 전처리 단계에서 데이터 사이언티스트가 모델, 학습 파이프라인이 포함된 배포 코드를 Gitlab에서 publish하면 Jenkins가 S3에 업로드
- Airflow로 EMR에서 전처리 배치 실행 -> 데이터가 S3와 feature store (MongoDB)에 적재
- S3에 학습 데이터가 업로드되면 AWS EventBridge가 AWS CodeBuild를 통해 SageMaker Pipeline 실행
- SageMaker Pipeline은 프로비저닝을 포함한 전처리, 모델 학습, 모델 등록 등의 과정을 순차적으로 실행 -> Model Registry에 적재
- AWS Lambda를 통해 학습 후 배포된 모델 -> SageMaker Endpoint에 업데이트
- 클라이언트의 추론 요청을 AWS API Gateway가 받고 -> AWS API Gateway는 Lambda를 통해 SageMaker Endpoint에 등록된 모델에게 추천 리스트를 요청하는 추론 요청을 보냄
- 추천 리스트는 다시 역순으로 Lambda -> API Gateway를 통하여 클라이언트에 보냄
예상 LLMOps 변환
- 데이터 준비 및 전처리
- 기존의 Airflow와 EMR은 대규모 언어 데이터 준비에 그대로 사용
- 전처리된 데이터는 S3와 함께 VectorDB 에도 적재
- 모델 학습 및 파이프라인
- 데이터 사이언티스트가 작성한 LLM 학습 파이프라인 코드를 GitLab에 게시
- Jenkins가 파이프라인을 트리거 → SageMaker Pipeline으로 학습, 파인튜닝, 최적화를 자동화
- 모델은 학습 후 SageMaker Model Registry에 등록
- RAG 통합
- MongoDB 대신 VectorDB를 활용해 Retrieval-Augmented Generation(RAG) 구성
- LLM이 실시간으로 외부 데이터를 검색하여 추론의 맥락을 강화
- 배포 및 추론
- AWS Lambda를 활용하여 SageMaker Endpoint에 저장된 모델로 실시간 추론
- 추론 요청은 API Gateway → Lambda → SageMaker Endpoint의 경로로 처리
- API 응답에는 LLM의 생성 결과와 검색된 추가 정보가 포함될 수 있음
Foundation Models
- 위의 구조를 간소화 시킬 수 있는 서비스를 제공 (AWS SageMaker Jumpstart, Bedrock)
- AWS SageMaker Jumpstart: 다양한 오픈소스로 공개된 Foundation model 모델을 활용하며 auto scaling를 적용하여 배포가 가능하며 오픈소스 모델을 파인튜닝을 하여 재학습도 가능
- AWS Bedrock: Foundation model의 대한 튜닝 및 인프라적인 관리 없이 바로 API 형태로 사용 가능
Bedrock과 Kendra를 사용한 RAG 구조
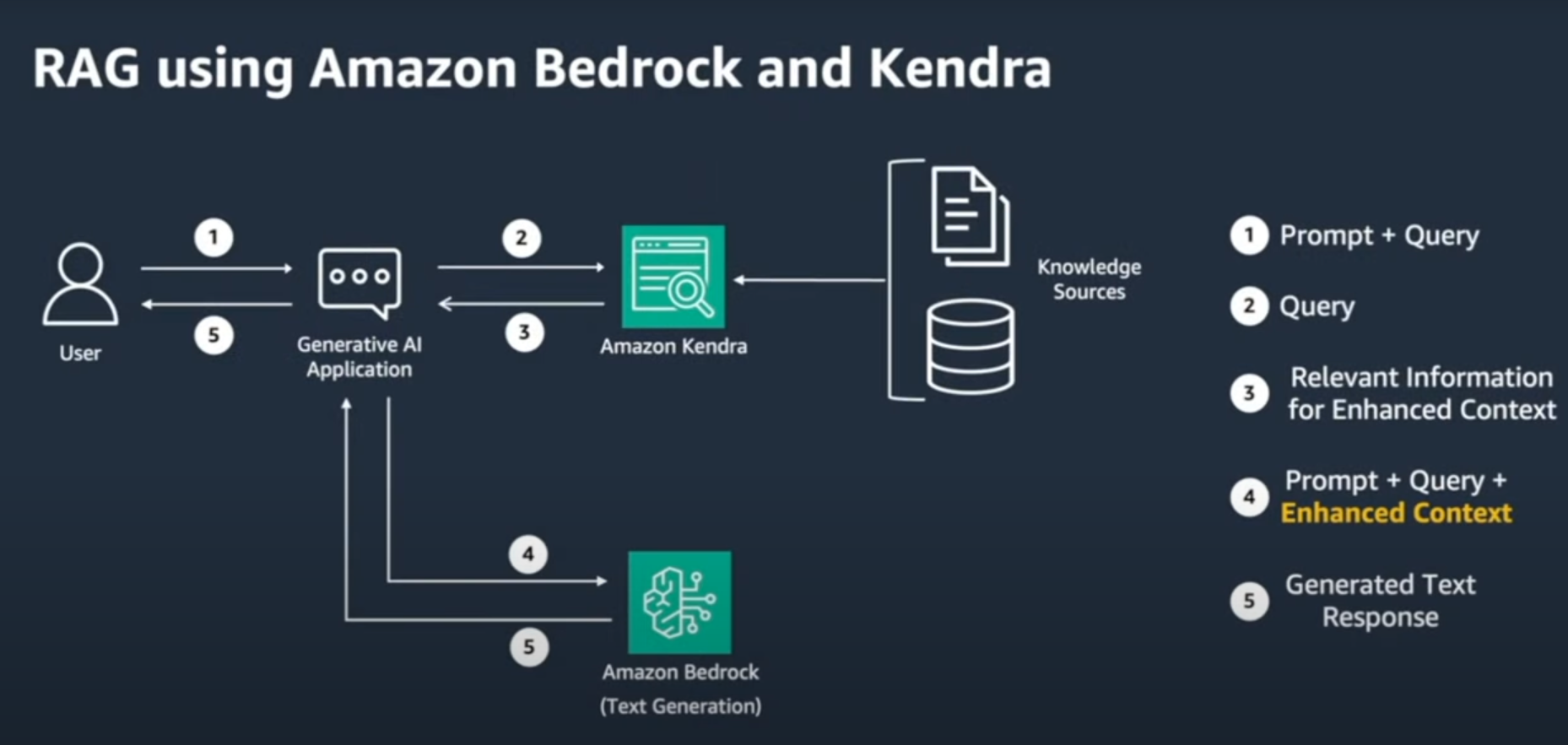
- 데이터(Knowledge Source)를 쪼개지 않고 full text 검색을 할때 사용되는 구조
- 사용자가 질문(Prompt)을 입력
- 예: “최근 AWS의 발표 내용을 요약해줘.”
- 사용자 입력을 받아 질문을 처리하고 적합한 정보를 검색(Query)
- AWS Kendra를 사용하여 정보 검색, 사용자의 쿼리에 가장 관련성 높은 문서를 반환하여 컨텍스트를 제공
- Amazon Bedrock에서는 Kendra에서 반환된 정보를 포함한 입력(Prompt + Enhanced Context)을 사용하여 최종 텍스트 응답을 생성
Vector embedding을 사용한 RAG 구조
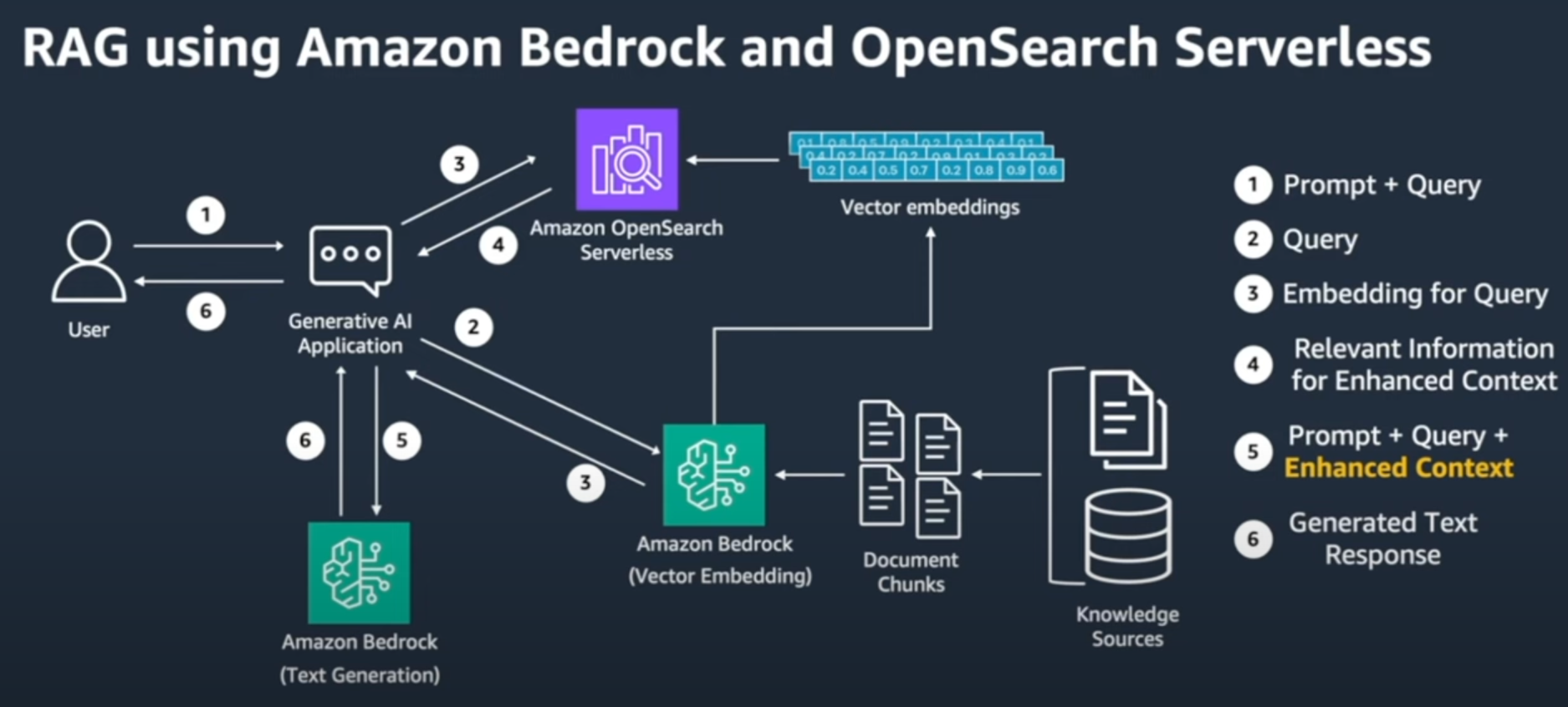
- 데이터(Knowledge Source) -> AWS Bedrock에서 제공하는 Text Embedding 모델을 이용하여 embedding 값 추출 -> AWS OpenSearch에 저장
- AWS Bedrock에서 최종 텍스트 응답 생성
Knowledge Bases for Amazon Bedrock
- 위와 같은 개발 및 운영에 대한 부담을 더욱 덜어주기 위하여 만들어졌으며
- AWS Bedrock의 Foundation model과 VetorDB를 연동시켜 좀 더 쉽게 VectorDB에 데이터를 넣을 수 있으며 이 후에 VectorDB를 조회를 하여 프롬프트 엔지니어링을 자동으로 해줄 수 있는 RAG를 좀 더 쉽게 구현할 수 있도록 도와주는 서비스
일반적인 RAG Workflow
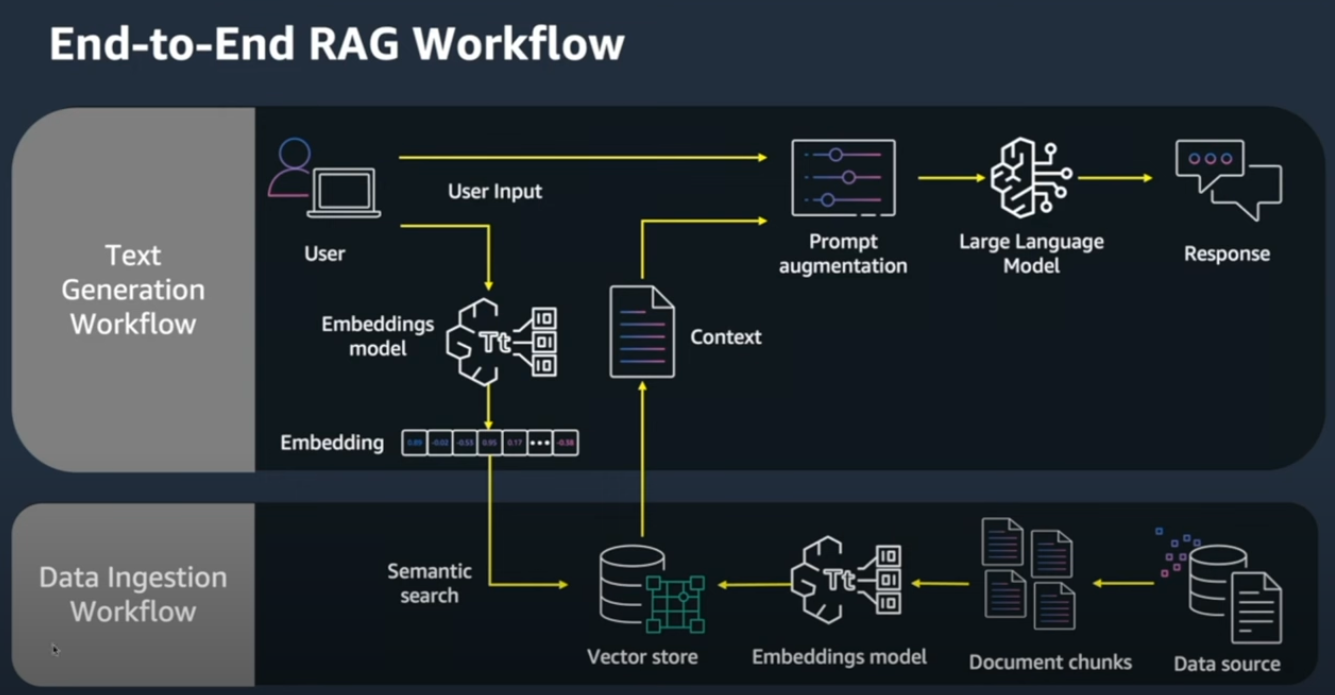
- 데이터(Knowledge Source)를 Chunks로 만들고 Embedding model을 통과시켜 -> Vector Store 저장
- 사용자에게 Prompt를 입력 받았을때 동일한 Embedding model을 사용하여 Embedding 값을 Semantic search로 VectorDB에서 검색
- 검색결과로 가져온 Context를 Prompt와 결합하여 LLM을 통한 Response를 노출
Data Ingestion Workflow
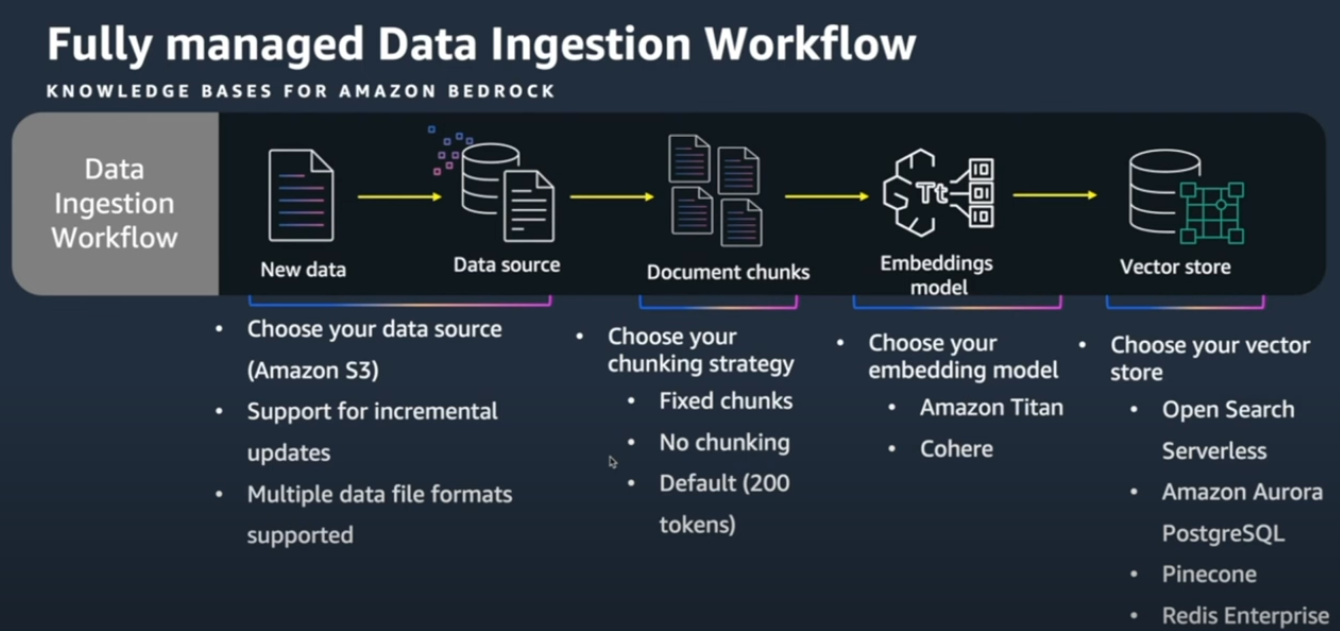
- Knowledge Bases for Amazon Bedrock를 사용하면 이 Data Ingestion 부분을 자동화를 시켜줌
- 데이터 소스는 S3에 저장
- 데이터 소스의 chunk 전략을 설정
- 고정길이
- chunk x
- 오버래핑 비율
- Embedding model 선택
- AWS Titan
- Cohere
- Vector Store 선택
- Open Search Serverless
- AWS Aurora PostgreSQL
- Pinecone
- Redis Enterprice
Retrieval and Generate
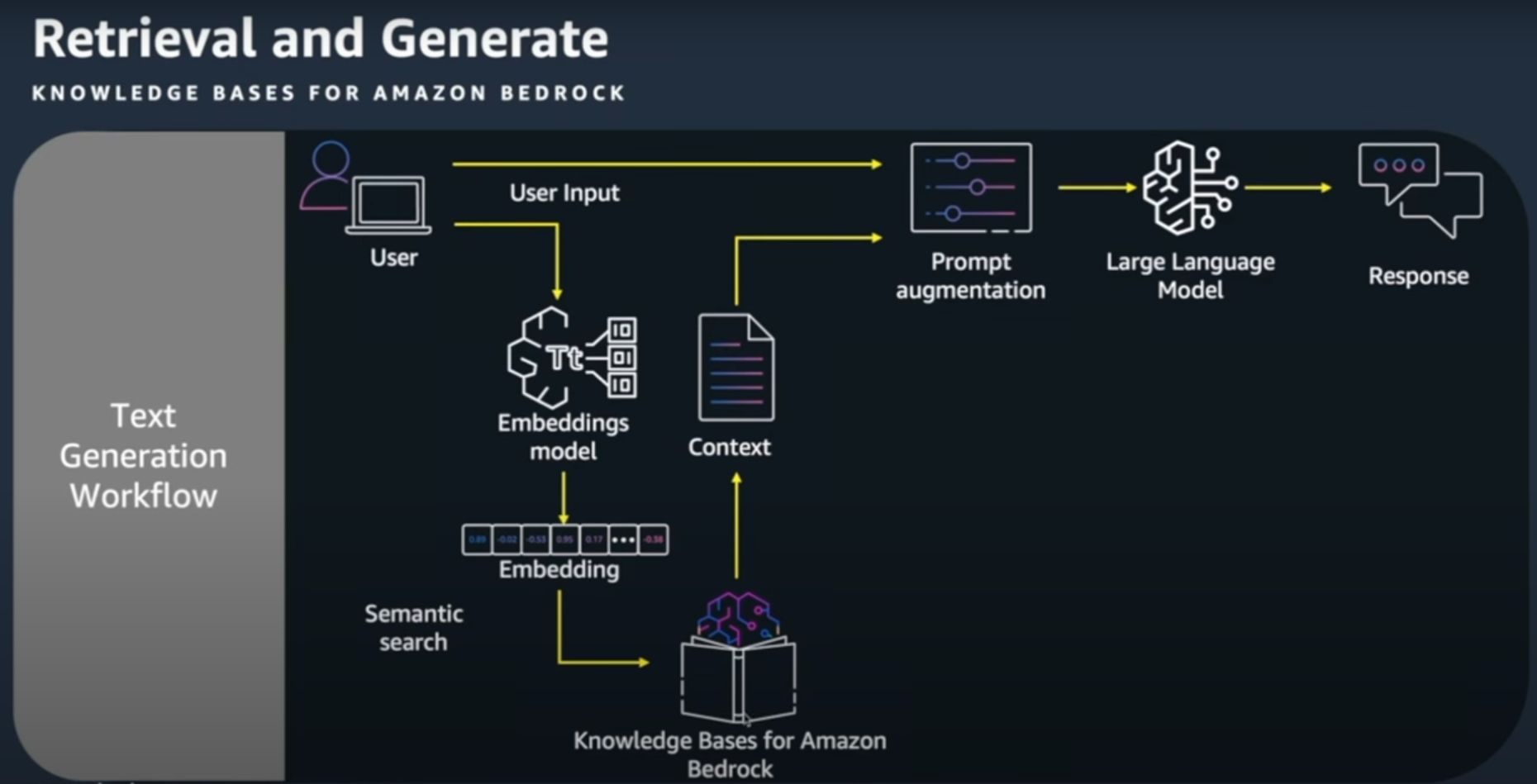
- 결국 Knowledge Bases for Amazon Bedrock에서는 클릭 몇번으로 Data Ingestion Workflow 부분을 쉽게 구성가능
Retrieval and Generate API
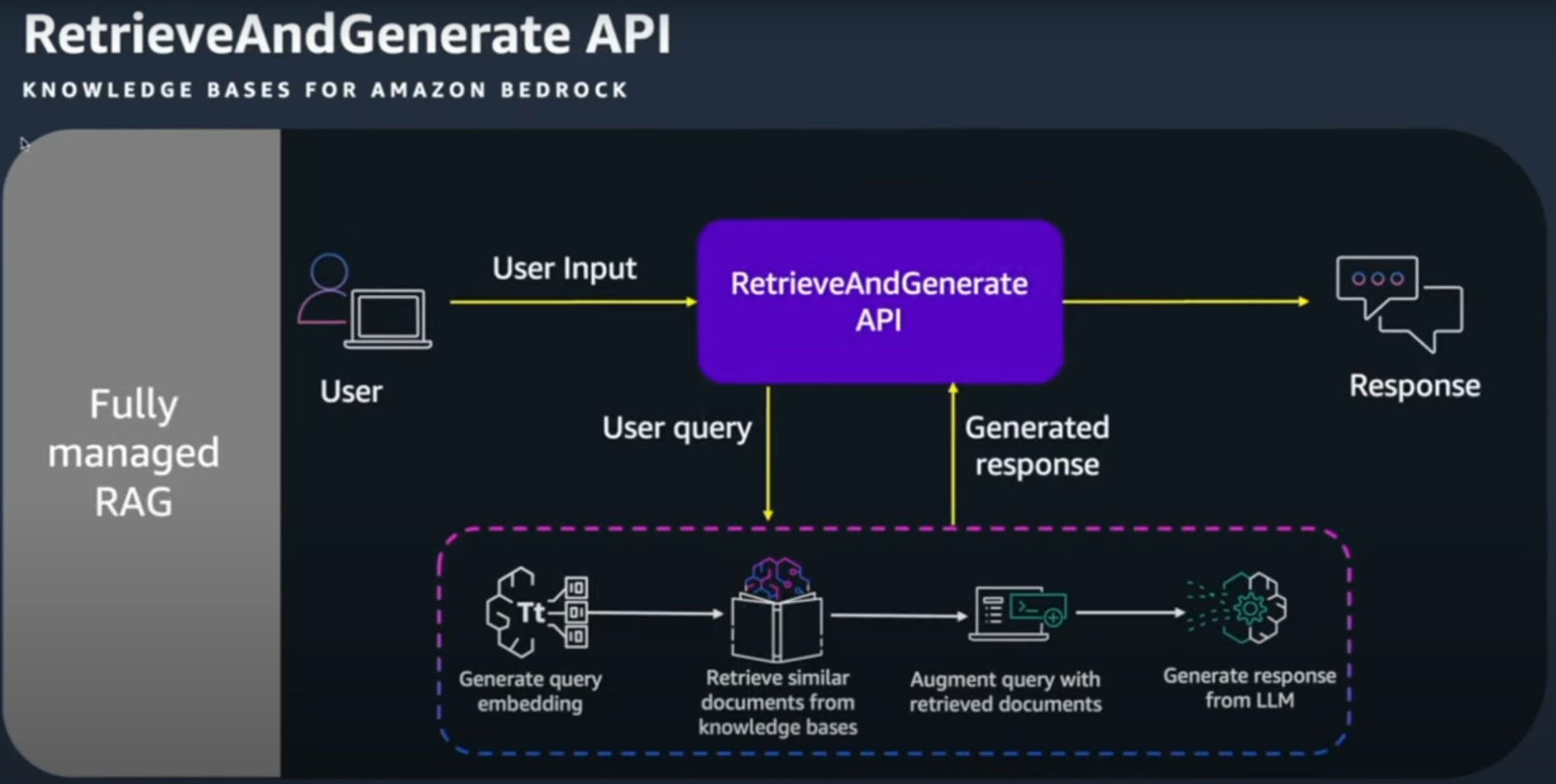
- 또한 Retrieval and Generate API를 사용하여 Text Generation Workflow도 쉽게 구성이 가능하다.
Customize RAG workflows using Retrieve API
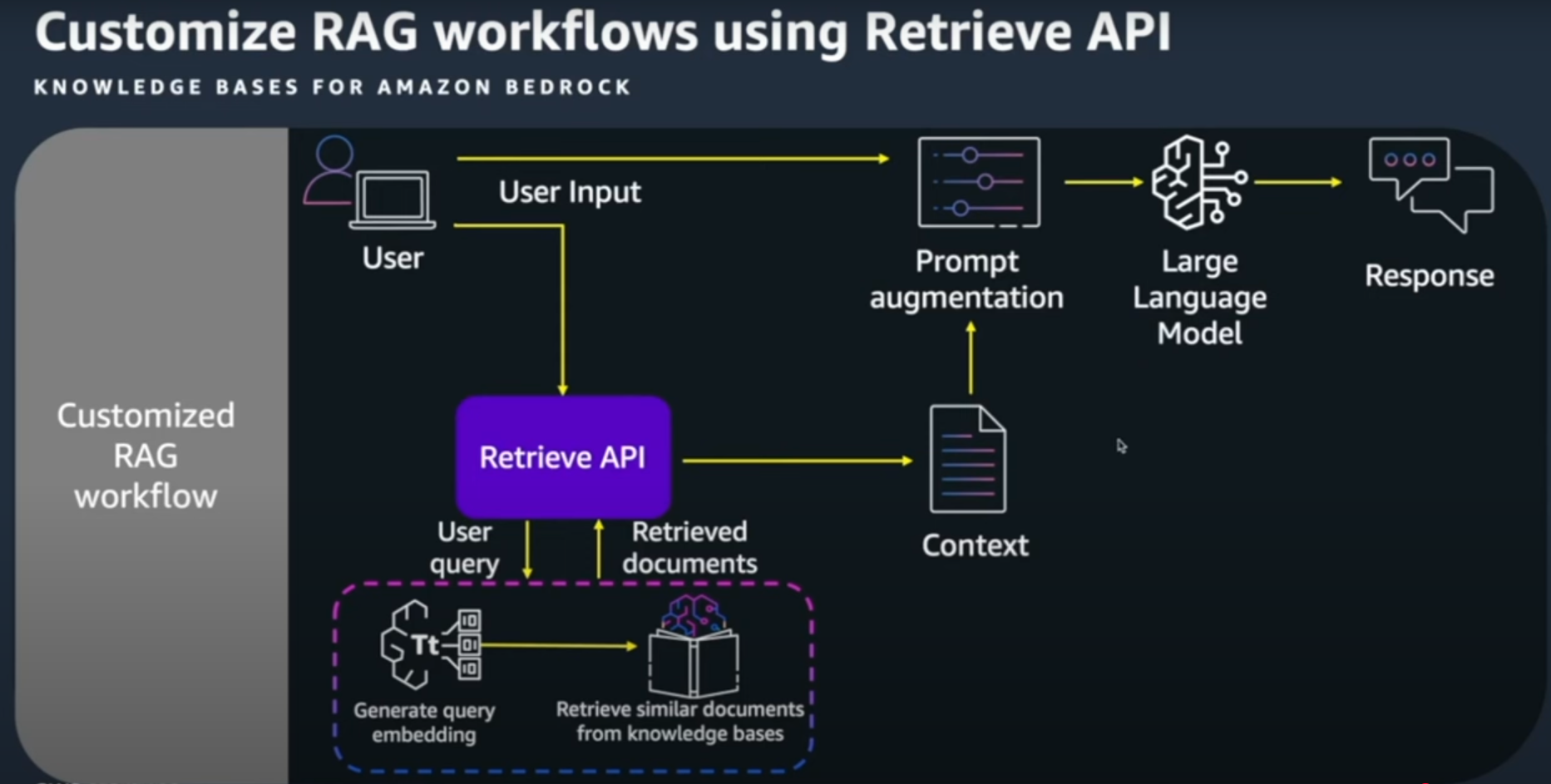
- 만약 Data Ingestion Workflow만 자동화 하고 가져온 데이터로 Prompt를 재구성이 하고 싶을때는 Retrieve API를 사용하여 Context를 추출 후 Prompt와 합쳐 LLM 모델을 이용하여 Reponse를 추출하는 작업을 할 수 있다.
최종 RAG 구성
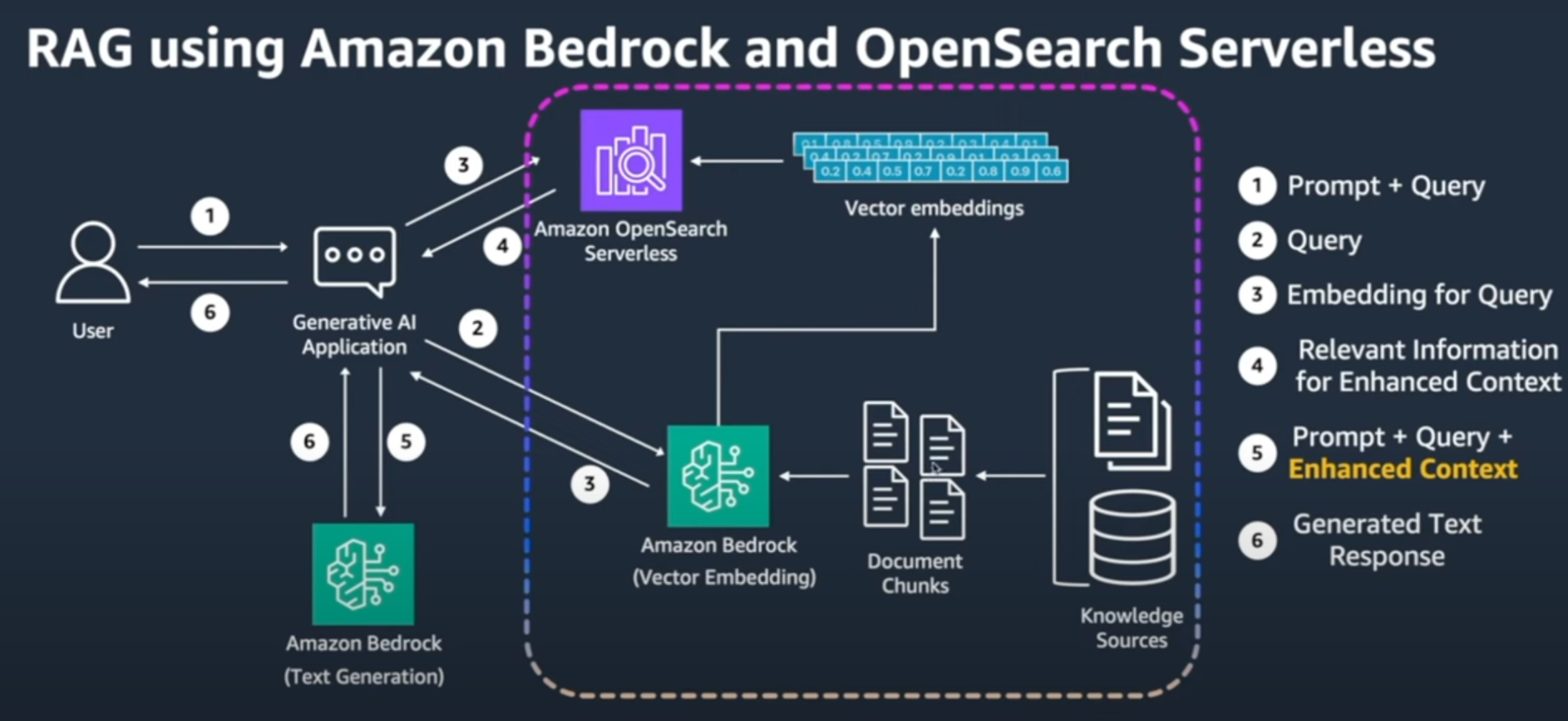
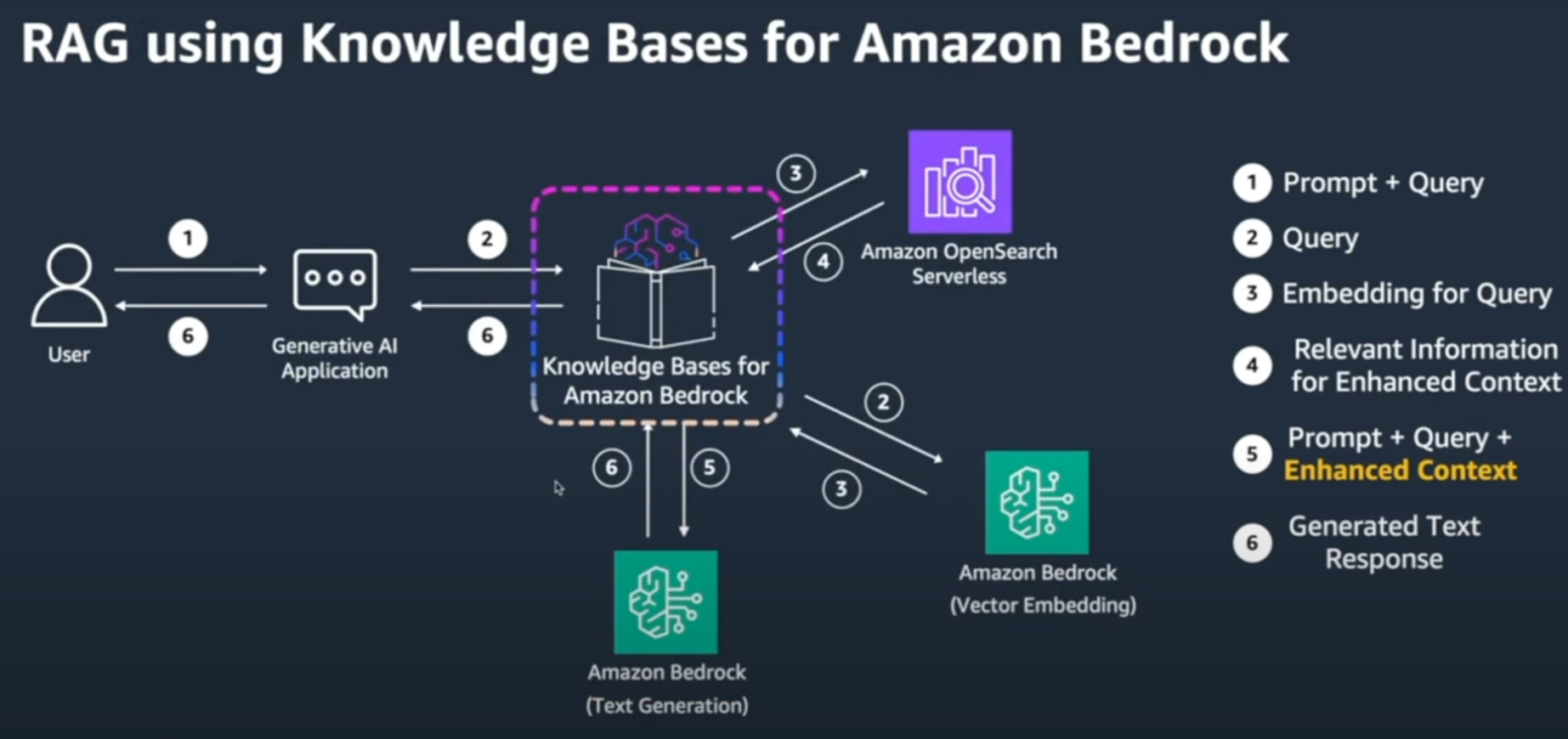
- Knowledge Bases for Amazon Bedrock 를 이용하면 사용자 쿼리에 대한 Prompt 생성, OpenSearch에 데이터 저장, AWS Bedrock 사용이 훨씬 단순화해진다.
참고 자료

Data Engineer