Initializing SparkSession with Iceberg
from pyspark.sql import SparkSession
from pyspark.sql.functions import rand, lit, array, rand, when, col
# Creating Spark Session
# Spark 3.5 with Iceberg 1.5.0
DW_PATH='/iceberg/spark/warehouse'
spark = SparkSession.builder \
.master("local[4]") \
.appName("iceberg-poc") \
.config('spark.jars.packages', 'org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.5.0')\
.config('spark.sql.extensions','org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')\
.config('spark.sql.catalog.local','org.apache.iceberg.spark.SparkCatalog') \
.config('spark.sql.catalog.local.type','hadoop') \
.config('spark.sql.catalog.local.warehouse',DW_PATH) \
.getOrCreate()Generating and Populating Data into Table
t1 = spark.range(30000).withColumn("year",
when(col("id") <= 10000, lit(2023))\
.when(col("id").between(10001, 15000), lit(2024))\
.otherwise(lit(2025))
)
t1 = t1.withColumn("business_vertical", array(
lit("Retail"),
lit("SME"),
lit("Cor"),
lit("Analytics")
).getItem((rand()*4).cast("int")))\
.withColumn("is_updated", lit(False))- id ,business_vertical 컬럼과 함께 2023 ~ 2025 데이터를 생성
# Creating a table to store employee's business vertical info
TGT_TBL = "local.db.emp_bv_details"
t1.coalesce(1).writeTo(TGT_TBL).partitionedBy('year').using('iceberg')\
.tableProperty('format-version','2')\
.tableProperty('write.delete.mode','merge-on-read')\
.tableProperty('write.update.mode','merge-on-read')\
.tableProperty('write.merge.mode','merge-on-read')\
.create()- merge-on-read로
emp_bv_details테이블 생성
Updated Employee's Business Vertical Data
# New department created called Sales and 3000 employees switched in 2025
updated_records = spark.range(15000, 18001).withColumn("year", lit(2025)).withColumn("business_vertical", lit("Sales"))
STG_TBL = "local.db.emp_bv_updates"
updated_records.coalesce(1).writeTo(STG_TBL).partitionedBy('year').using('iceberg')\
.tableProperty('format-version','2')\
.create()- 3000명의 근로자가 2025년도에 부서를
Sales로 변경
Merge Staging Data into Target Table
spark.sql(f"""
MERGE INTO {TGT_TBL} as tgt
USING (Select *, False as is_updated from {STG_TBL}) as src
ON tgt.id = src.id
WHEN MATCHED AND src.business_vertical <> tgt.business_vertical AND tgt.year = src.year THEN
UPDATE SET tgt.is_updated = True, tgt.business_vertical = src.business_vertical
WHEN NOT MATCHED THEN
INSERT *
""")- Merge into로 데이터 업데이트
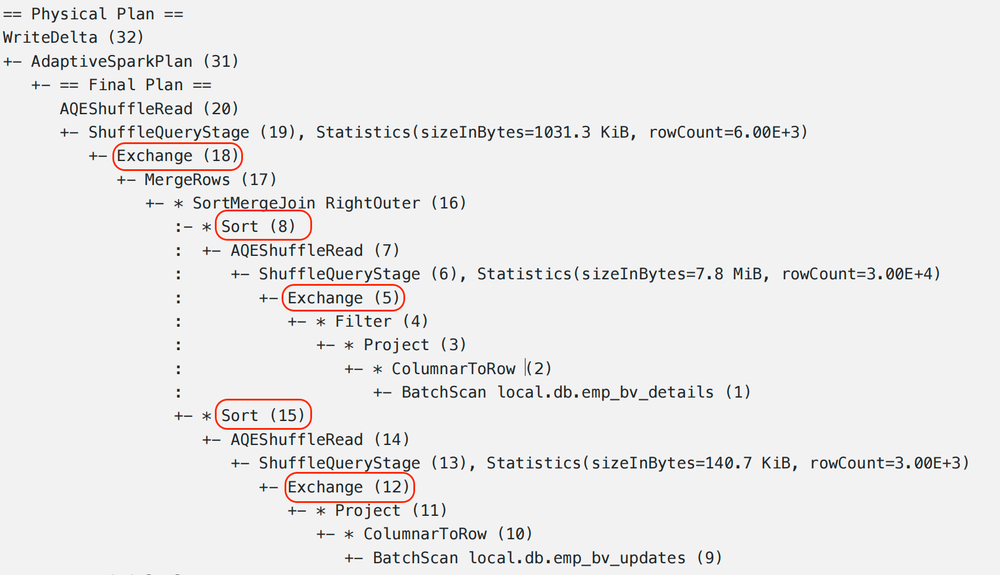
Merge Execution Plan
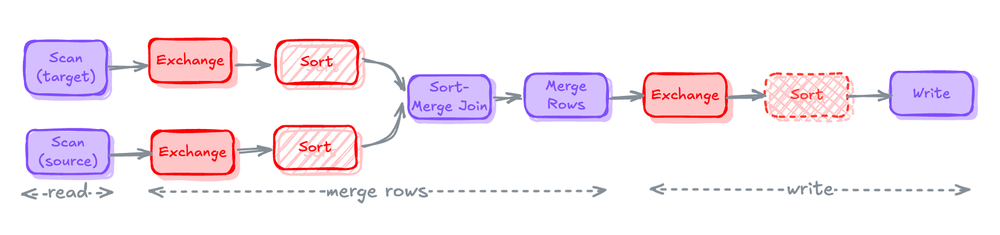
Read
- runtime filter로 source 및 target table을 scan
- 비용이 많이 드는 작업: pushdown filter가 없는 scan은 불필요한 데이터를 메모리로 가져온다.
Merge Rows
- 두 테이블을 Join하여 record를 merge하고 새로운 record를 create 하기 위해
WHEN MATCHED및WHEN NOT MATCHED절을 함께 적용하여 테이블의 새 상태를 계산 - 비용이 많이 드는 작업: sort merge join으로 shuffling과 sorting
Write
- record를 merge 한 후에는 대상 테이블에 다시 기록
- 비용이 많이 드는 작업: 테이블 파티셔닝 방식에 맞춰 쓰기 전에 데이터를 미리 shuffling, 테이블에 정렬 키가 정의된 경우 쓰기 전에 데이터를 미리 sorting
즉 셔플이 많은 비용이 든다.
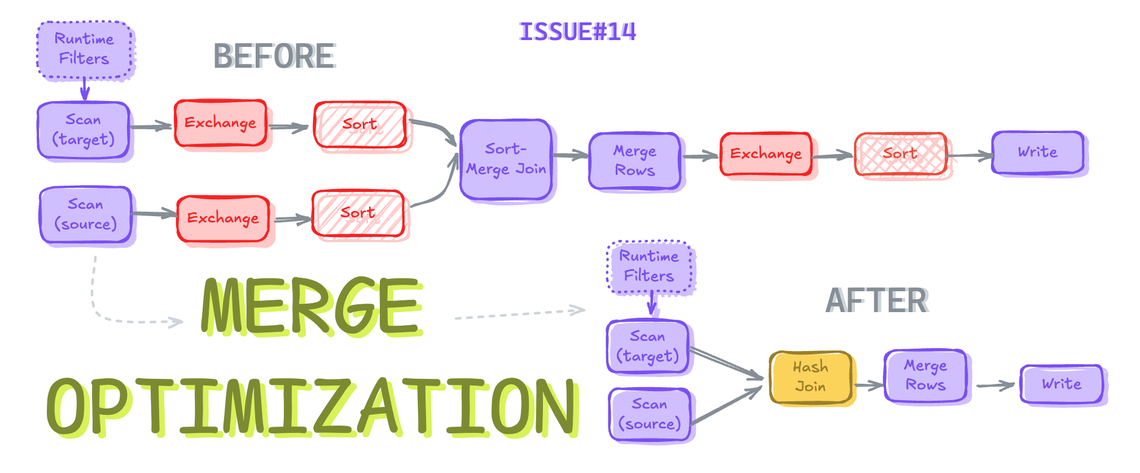
Merge 최적화
Push Down Filters
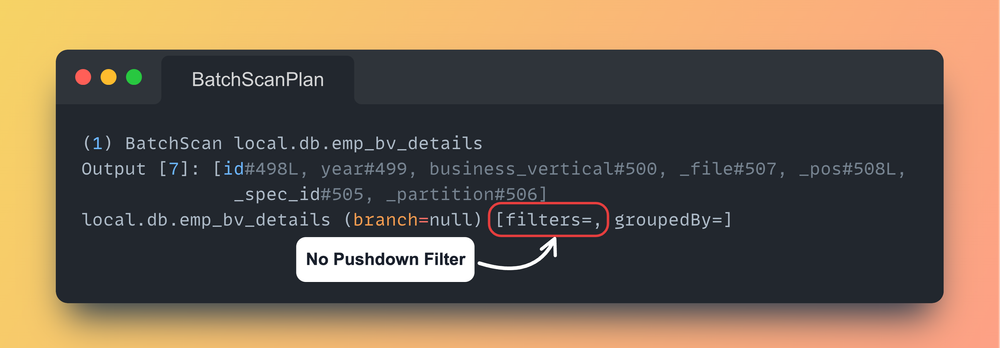
- 필터를 푸시다운하려면 반드시 MERGE 문장의 ON 절에 포함되어 있어야 한다.
WHEN MATCHED나WHEN NOT MATCHED에 있는 필터는 푸시다운되지 않는다.
-- Adding filter condition that will be pushed down
MERGE INTO TARGET_TABLE tgt
USING STAGE_TABLE stg
ON tgt.id = stg.id
AND tgt.year = 2025 -- All filters in ON Clause are pushed down.
WHEN MATCHED ...
WHEN NOT MATCHED ...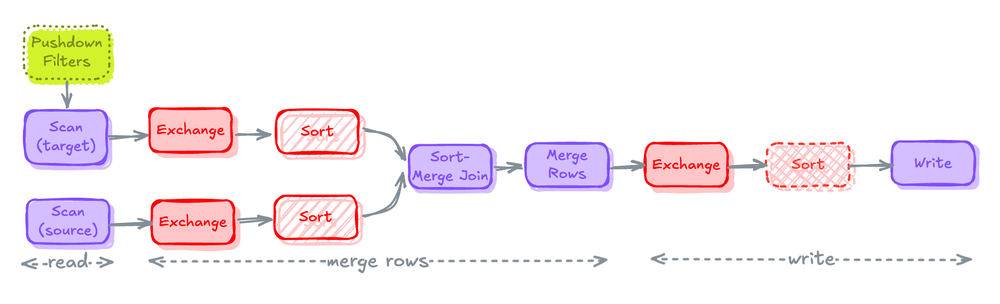
Sort-Merge Joins to Hash Joins (if possible)
spark.conf.set("spark.sql.join.preferSortMergeJoin", "false")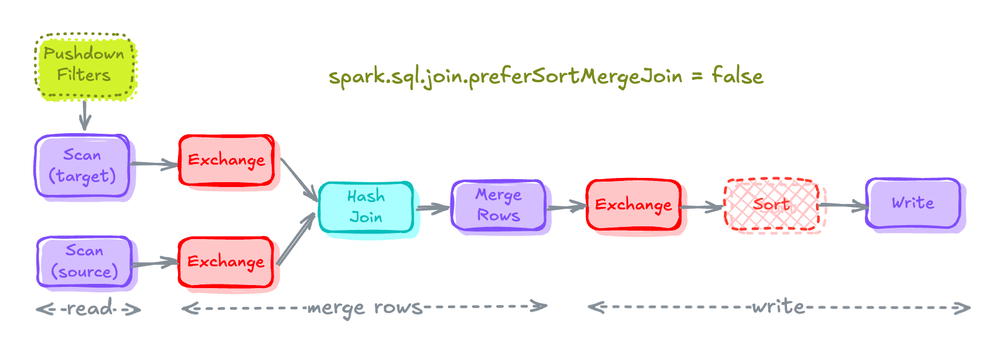
- spark는 기본적으로 Hash Join보다 Sort Merge Join을 선호하는데 이는 확장성이 좋기 때문
- 이 값은
spark.sql.join.preferSortMergeJoin설정값에 의해 제어되며 기본값은 true - 이 값을 false로 설정하면 Sort Merge Join 대신 Shuffle Hash Join을 선택한다.
Spark Fanout Writers
# Setting Table Property to enable fanout-writers
spark.sql(f"""ALTER TABLE {TGT_TBL} SET TBLPROPERTIES (
'write.spark.fanout.enabled'='true'
)""")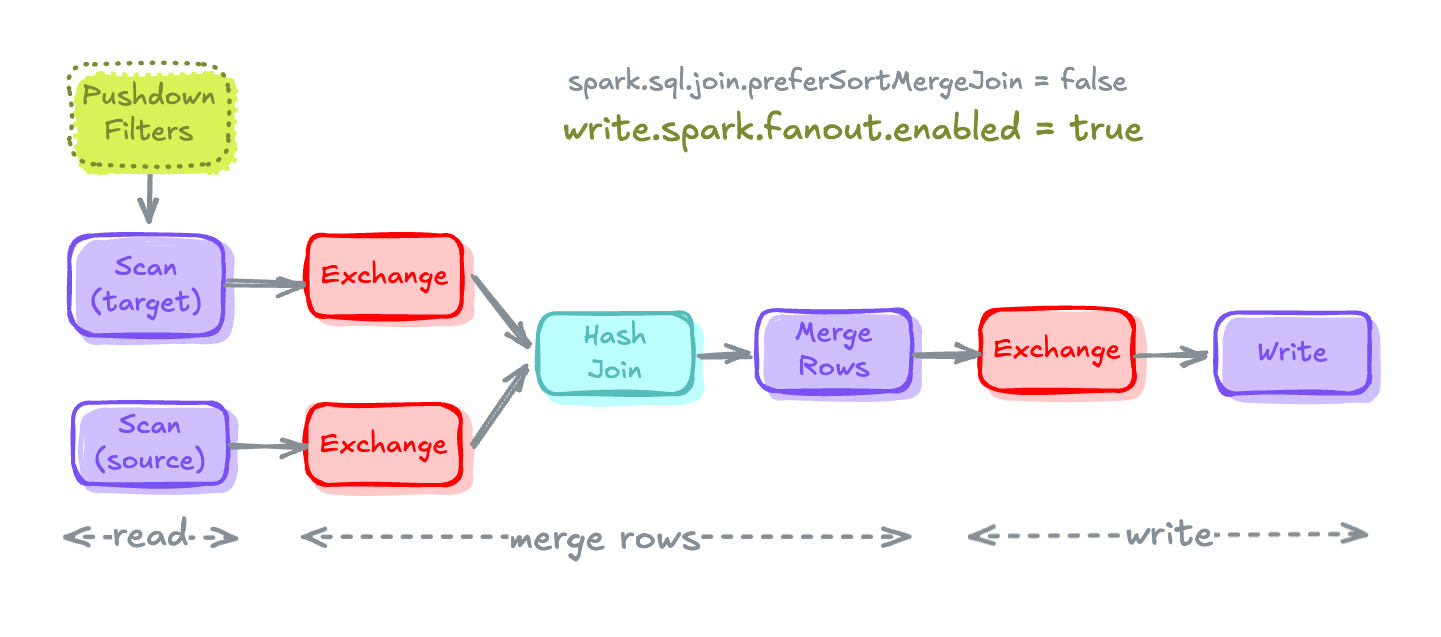
- Fanout Writer는 데이터를 쓸 때 각 파티션 값별로 파일을 열고, 해당 쓰기 작업이 끝날 때까지 파일을 닫지 않고 유지하는 방식
- 이 방식은 로컬 정렬(local sort) 과정을 회피할 수 있어서 성능 최적화에 도움을 줌
로컬 정렬(Local Sorting)이란?
Spark에서 데이터를 쓰기 전에 같은 파티션 값끼리 묶기 위해 로컬 정렬을 수행
- 배치(Batch) 작업에서는 비교적 영향이 적지만
- 스트리밍(Streaming) 작업에서는 지연(latency)을 유발한다.
Iceberg Distribution Modes
# Setting Distribution mode in SparkSession.
# This overwrites the Distribution mode mentioned in TBLPROPERTIES
spark.conf.set("spark.sql.iceberg.distribution-mode", "None")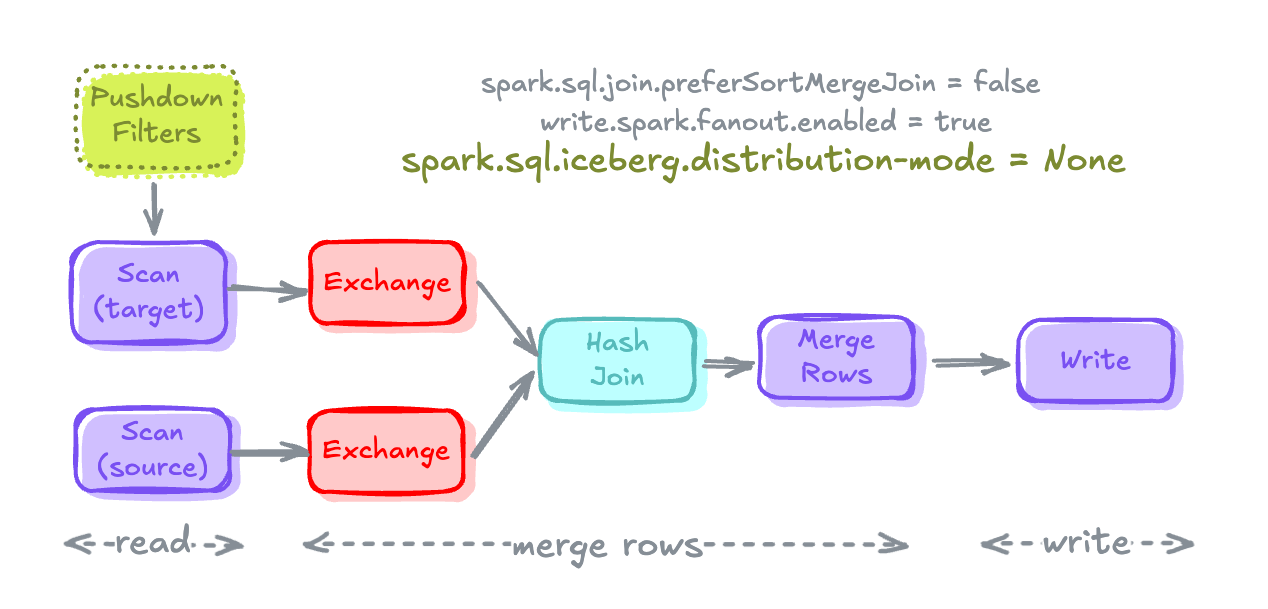
- Iceberg에서 데이터를 테이블에 쓰기 전에 어떻게 분산(Shuffle) 할지를 결정하는 설정
- IcebergWriter가 데이터를 테이블에 쓰기 전에 Spark에게 요청하는 분산 전략
- None으로 설정하면 Exchange가 제거되어 성능이 빨라진다.
None: 분산 요청 없이 Spark가 받은 그대로 데이터를 씀
- 가장 빠름
- 작은 파일이 많이 생길 수 있음
hash: Hash 기반으로 Shuffle 후 작성
- 보통
- 균형 잡힌 파일
range: Range 기반으로 정렬 후 Shuffle 후 작성
- 가장 느림
- 정렬된 큰 파일 생성 가능
Trade-offs/Balancing between Write and Read Performance
-
테이블에 데이터를 쓸 때 Exchange 노드를 제거하는 것은 단순한 최적화가 아닌,
쓰기 성능과 읽기 성능 사이의 균형(trade-off) 을 고려한 결정 -
distribution-mode = none
- Spark가 데이터 Write 전 Shuffle이나 Sort 없이 바로 Write
- 쓰기 성능(Write Performance) 은 매우 빨라짐
- 하지만 많은 작은 파일(small files) 이 생기므로, 읽기 성능(Read Performance) 은 저하
-
MOR 테이블에서는 더 심각해짐
- MOR(Merge-On-Read) 방식은 Delete 파일과 Data 파일을 병합해야 읽을 수 있음
- 작은 파일이 많아지면 Spark는 많은 파일을 읽고 병합 처리를 반복
- 이로 인해 읽기 속도는 심각하게 느려질 수 있음
-
none 모드가 유용한 상황
-
한 파티션만 쓰는 경우
- 예: year=2025와 같은 고정된 파티션에만 데이터가 들어올 때.
- → Shuffle이 불필요하므로 매우 효과적.
-
Compaction을 자주 수행할 수 있을 때
- 작은 파일을 주기적으로 합치면, 읽기 성능 저하를 어느 정도 상쇄 가능
-
쓰기 성능이 더 중요한 경우
- 분석보다는 실시간 적재가 중요한 상황 등.
-
Enabling Storage Partitioned Join
# Enabling SPJ
spark.conf.set('spark.sql.sources.v2.bucketing.enabled','true')
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
spark.conf.set('spark.sql.iceberg.planning.preserve-data-grouping','true')
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
spark.conf.set('spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled','true')MERGE INTO TARGET_TABLE tgt
USING STAGE_TABLE stg
ON tgt.id = stg.id
AND tgt.year = 2025
AND tgt.year = src.year -- joining on partition columns to enable SPJ
WHEN MATCHED ...
WHEN NOT MATCHED ...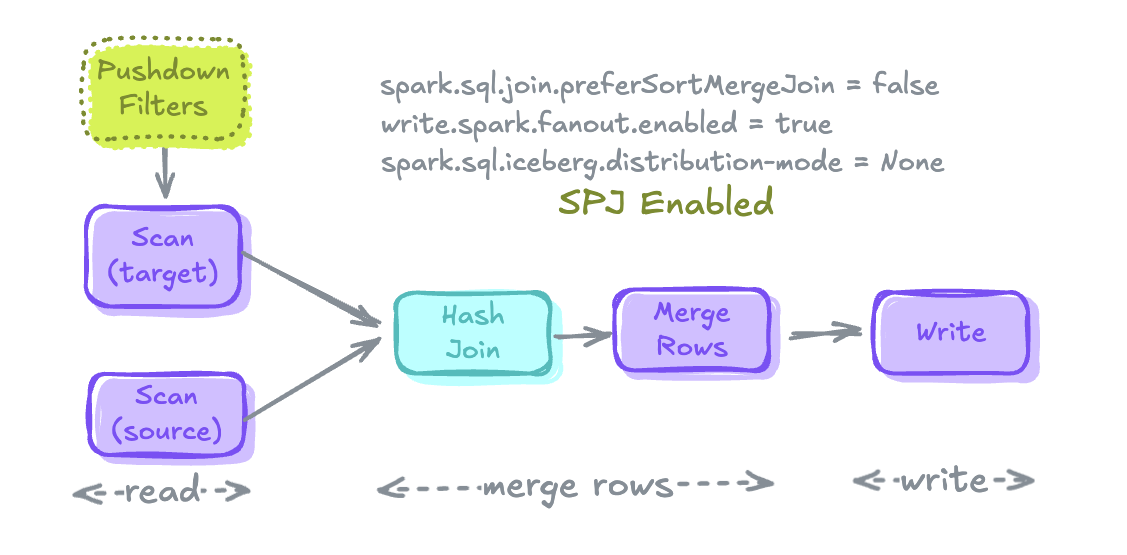
Optimized Merge
# Updating some employees departments after setting some configs for optimization
updated_records = spark.range(28000, 35001)\
.withColumn("year", lit(2025))\
.withColumn("business_vertical", lit("DataEngineering"))
updated_records.coalesce(1).writeTo(STG_TBL).overwritePartitions()- 조직이 새로운 business_vertical로 Data Engineers 부서를 도입했다고 가정
- 기존에 다른 부서에 있던 일부 직원들이 Data Engineers 부서로 이동
- 새로운 Data Engineers 인력을 채용
Setting all the required configurations
# To avoid sort due to Sort Merge Join by prefering Hash Join if possible.
spark.conf.set('spark.sql.join.preferSortMergeJoin', 'false')
# To avoid Shuffle before writing into table.
spark.conf.set("spark.sql.iceberg.distribution-mode", "None")
# Enabling SPJ
spark.conf.set('spark.sql.sources.v2.bucketing.enabled','true')
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
spark.conf.set('spark.sql.iceberg.planning.preserve-data-grouping','true')
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
spark.conf.set('spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled','true')# To avoid Pre-Sorting before writing into table
spark.sql(f"""ALTER TABLE {TGT_TBL} SET TBLPROPERTIES (
'write.spark.fanout.enabled'='true'
)""")Rewriting Merge Statement
spark.sql(f"""
MERGE INTO {TGT_TBL} as tgt
USING (SELECT *, False as is_updated from {STG_TBL}) as src
ON tgt.id = src.id AND tgt.year = src.year AND tgt.year = 2025
WHEN MATCHED AND
tgt.business_vertical <> src.business_vertical
THEN
UPDATE SET tgt.is_updated = True, tgt.business_vertical = src.business_vertical
WHEN NOT MATCHED THEN
INSERT *
""")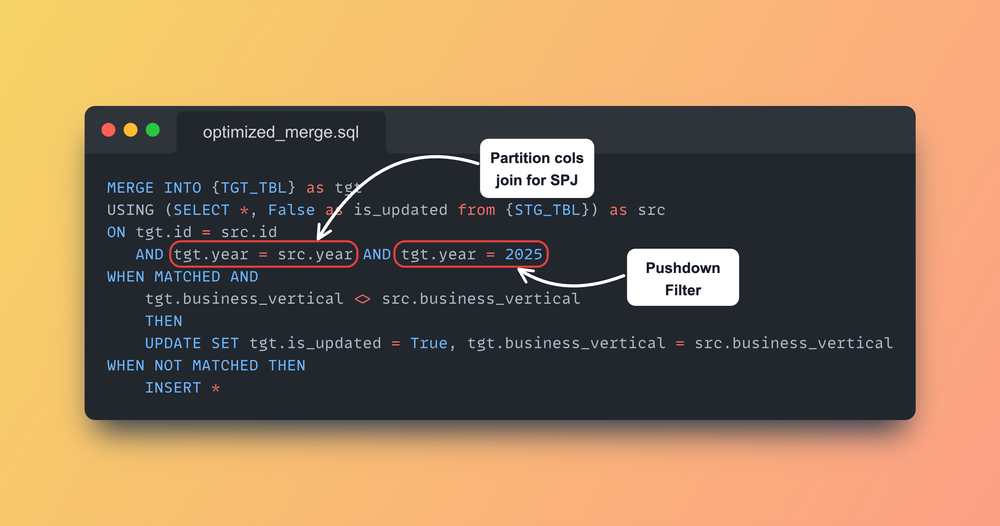
year = 2025로 push down filter 추가year파티션 컬럼을 SPJ를 위해 join에 추가
Final Results
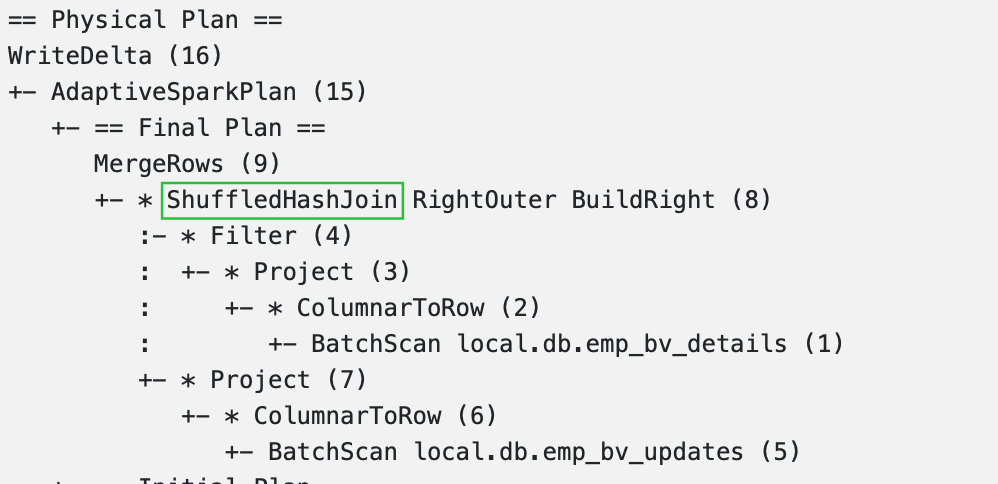
- Sort Merge Join이 Shuffle Hash Join으로 변경되었으며
Exchange와Sort도 사라진 것 확인
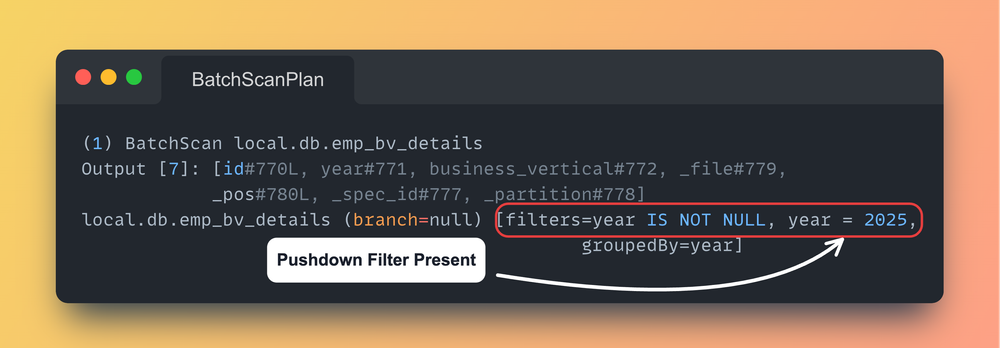
- Push Down이 Filter에 추가 된 것을 확인
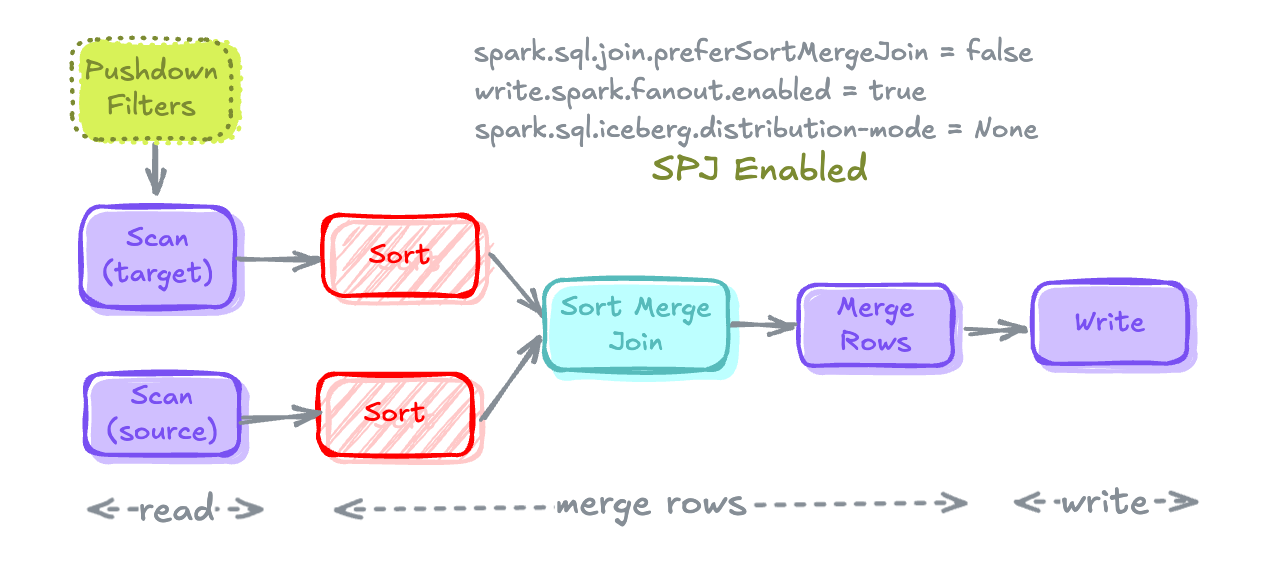
- 만약 Shuffle Hash Join이 불가능한 경우 Spark의 Merge 실행 계획은 위와 같음
참조

Data Engineer