SPJ

- 셔플은 네트워크를 통해 데이터를 이동시키므로 CPU와 네트워크 리소스를 많이 소모
- 셔플 과정에서 중간 파일을 디스크에 쓰게 되어, 디스크 I/O가 매우 많이 발생
- 즉, 성능 저하 + 비용 증가의 주범
- SPJ(Storage Partition Join) 최적화 기법을 이용하여 Data Source V2 기반의 파티셔닝 테이블끼리 셔플 없이 조인이 가능, 다만 일정 조건이 충족될 경우에만 적용
Requirements for SPJ
- 타겟, 소스 테이블 둘 다 Iceberg 테이블이어야 함
- 타겟, 소스 테이블 둘 다 동일한 파티션 방식을 사용해야 하며, 적어도 하나의 파티션 컬럼이 일치해야 함
- 반드시 파티션 컬럼을 포함한 조인 조건이어야 함
- SPJ 관련 Spark & Iceberg 설정이 활성화 되어 있어야 함
- Iceberg 1.2.0 이상, Spark 3.3.0 이상
Configure
set(spark.sql.sources.v2.bucketing.enabled, true)
set(spark.sql.sources.v2.bucketing.pushPartValues.enabled, true)
set(spark.sql.iceberg.planning.preserve-data-grouping, true)
set(spark.sql.requireAllClusterKeysForCoPartition, false)
set(spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled, true)SparkSession 초기화
from pyspark.sql import SparkSession, Row
# update here the required versions
SPARK_VERSION = "3.5"
ICEBERG_VERSION = "1.5.0"
CATALOG_NAME = "local"
# update this to your local path where you want tables to be created
DW_PATH = "/path/to/local/warehouse"
spark = SparkSession.builder \
.master("local[4]") \
.appName("spj-iceberg") \
.config("spark.sql.adaptive.enabled", "true")\
.config('spark.jars.packages', f'org.apache.iceberg:iceberg-spark-runtime-{SPARK_VERSION}_2.12:{ICEBERG_VERSION},org.apache.spark:spark-avro_2.12:3.5.0')\
.config('spark.sql.extensions','org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions')\
.config(f'spark.sql.catalog.{CATALOG_NAME}','org.apache.iceberg.spark.SparkCatalog') \
.config(f'spark.sql.catalog.{CATALOG_NAME}.type','hadoop') \
.config(f'spark.sql.catalog.{CATALOG_NAME}.warehouse',DW_PATH) \
.config('spark.sql.autoBroadcastJoinThreshold', '-1')\
.enableHiveSupport()\
.getOrCreate()- SPJ 구성 없이 Iceberg 관련 구성을 모두 사용하여 Spark 세션을 초기화
데이터 준비
pip install faker# Creating Mockup data for Customers and Orders table.
from pyspark.sql import Row
from faker import Faker
import random
# Initialize Faker
fake = Faker()
Faker.seed(42)
# Generate customer data
def generate_customer_data(num_customers=1000):
regions = ['North', 'South', 'East', 'West']
customers = []
for _ in range(num_customers):
signup_date = fake.date_time_between(start_date='-3y', end_date='now')
customers.append(Row(
customer_id=fake.unique.random_number(digits=6),
customer_name=fake.name(),
region=random.choice(regions),
signup_date=signup_date,
signup_year=signup_date.year # Additional column for partition evolution
))
return spark.createDataFrame(customers)
# Generate order data
def generate_order_data(customer_df, num_orders=5000):
customers = [row.customer_id for row in customer_df.select('customer_id').collect()]
orders = []
for _ in range(num_orders):
order_date = fake.date_time_between(start_date='-3y', end_date='now')
orders.append(Row(
order_id=fake.unique.random_number(digits=8),
customer_id=random.choice(customers),
order_date=order_date,
amount=round(random.uniform(10, 1000), 2),
region=random.choice(['North', 'South', 'East', 'West']),
order_year=order_date.year # Additional column for partition evolution
))
return spark.createDataFrame(orders)
# Generate the data
print("Generating sample data...")
customer_df = generate_customer_data(1000)
order_df = generate_order_data(customer_df, 5000)
customer_df.show(5, truncate=False)
order_df.show(5, truncate=False)- Customers및 Orders 테이블 준비
Iceberg 테이블에 데이터 쓰기
customer_df.writeTo("local.db.customers") \
.tableProperty("format-version", "2") \
.partitionedBy("region") \
.create()
order_df.writeTo("local.db.orders") \
.tableProperty("format-version", "2") \
.partitionedBy("region") \
.create()- Customers, Orders Write
SPJ Config가 활성화 되지 않은 테이블 조인
CUSTOMERS_TABLE = 'local.db.customers'
ORDERS_TABLE = 'local.db.orders'
cust_df = spark.table(CUSTOMERS_TABLE)
order_df = spark.table(ORDERS_TABLE)
# Joining on region
joined_df = cust_df.join(order_df, on='region', how='left')
# Generated plan from
joined_df.explain("FORMATTED")
# triggering an action
joined_df.show(1)== Physical Plan ==
AdaptiveSparkPlan (9)
+- Project (8)
+- SortMergeJoin LeftOuter (7)
:- Sort (3)
: +- Exchange (2)
: +- BatchScan local.db.customers (1)
+- Sort (6)
+- Exchange (5)
+- BatchScan local.db.orders (4)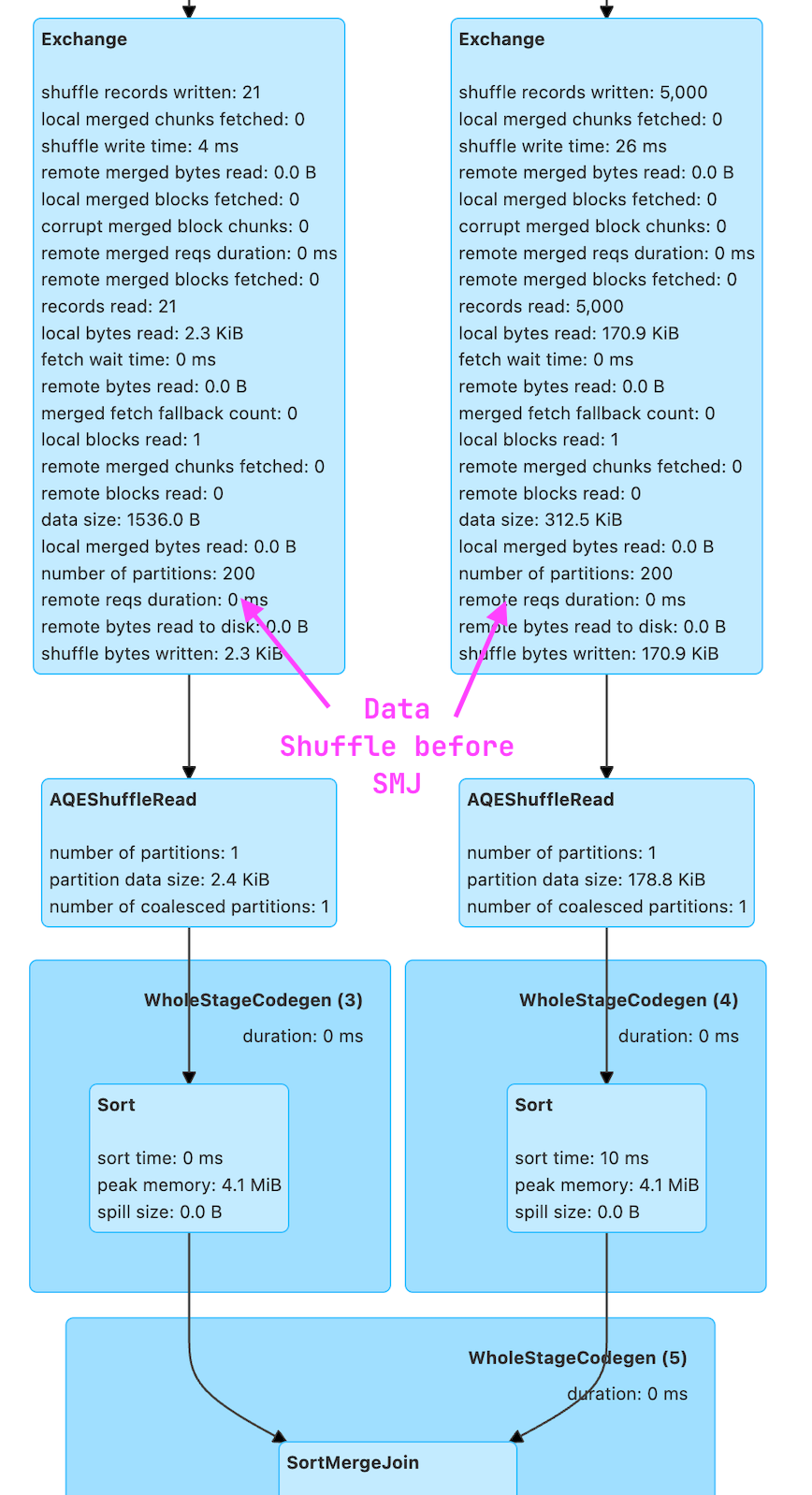
- explain에 Exchange가 포함되고 SMJ(정렬-병합 조인) 중 데이터 셔플이 발생
SPJ 활성화
# Setting SPJ related configs
spark.conf.set('spark.sql.sources.v2.bucketing.enabled','true')
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
spark.conf.set('spark.sql.iceberg.planning.preserve-data-grouping','true')
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
spark.conf.set('spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled','true')joined_df = cust_df.join(order_df, on='region', how='left')
joined_df.explain("FORMATTED")
joined_df.show()== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)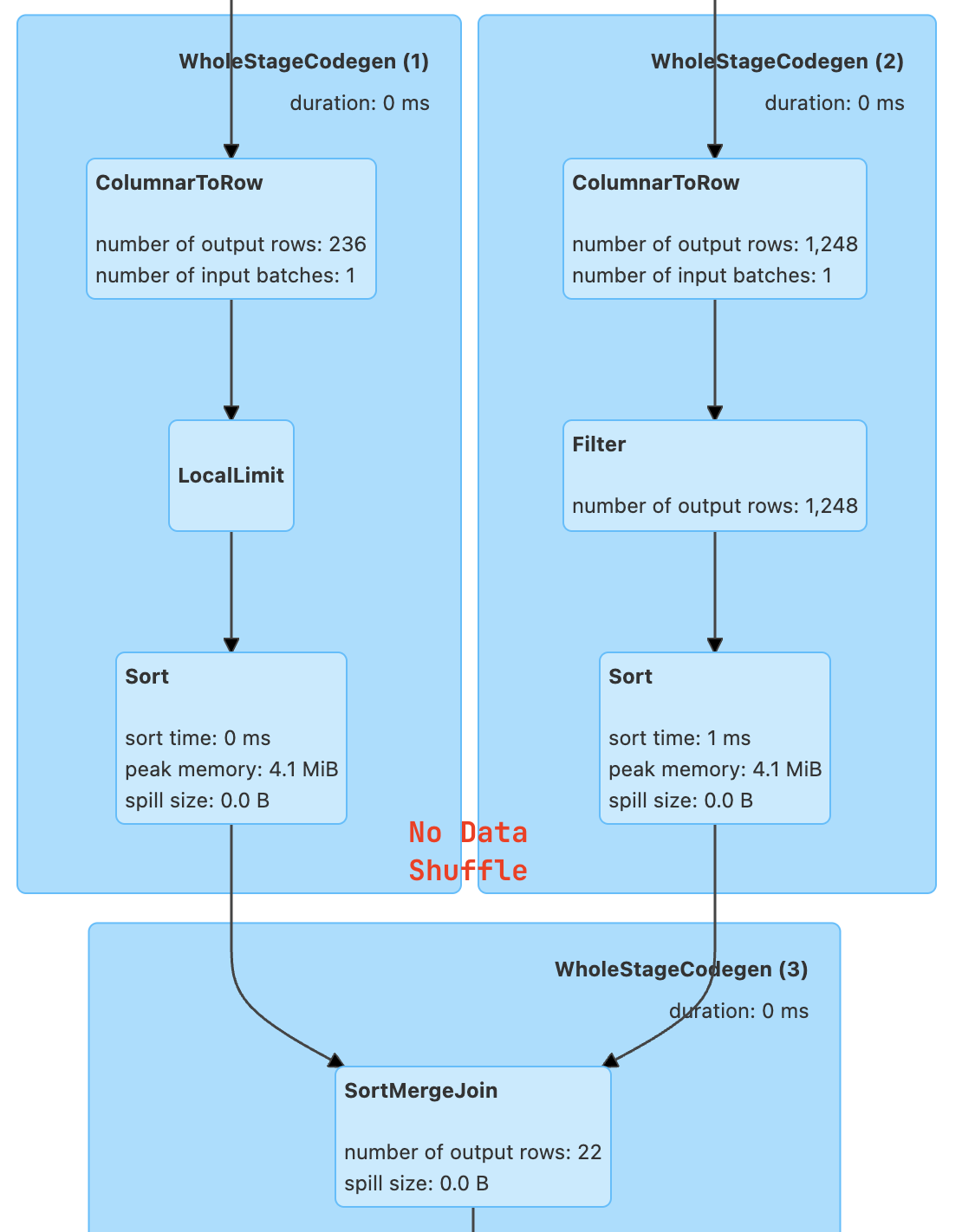
- explain에도 Exchange가 없으며 shuffle이 발생하지 않는다
SPJ Configuration 요소
spark.sql.iceberg.planning.preserve-data-grouping
- true이면, 쿼리 플래닝에서 파티셔닝 정보가 유지됨 -> 불필요한 재파티셔닝이 방지되고 실행 중에 셔플 비용이 줄어들어 성능이 최적화된다.
spark.sql.sources.v2.bucketing.enabled
- true이면, 호환되는 V2 데이터 소스의 파티셔닝을 사용하여 셔플을 제거하려고 시도함
Scenario 1: Joining keys가 Partitioning keys와 동일한 경우
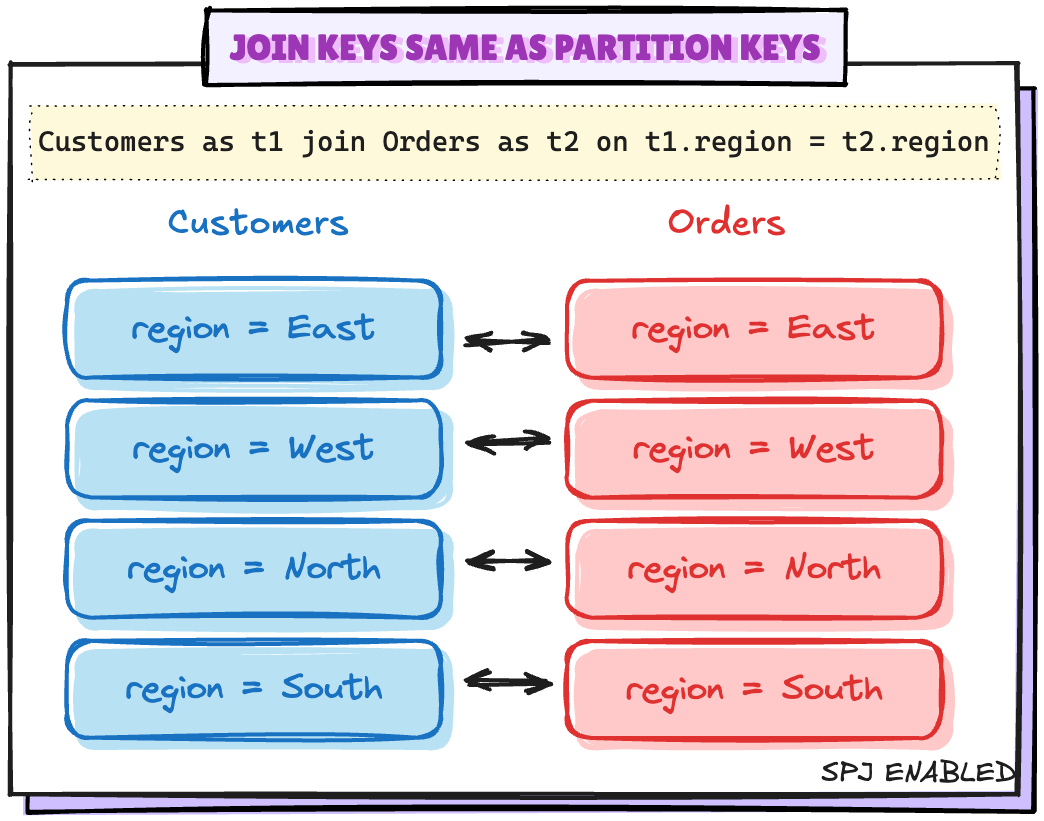
# Setting up the minimum configuration for SPJ
spark.conf.set("spark.sql.sources.v2.bucketing.enabled", "true")
spark.conf.set("spark.sql.iceberg.planning.preserve-data-grouping", "true")
joined_df = cust_df.join(order_df, on="region", how="left")
joined_df.explain("FORMATTED")== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)- explain에 Exchange가 없으며 최소로 작동
Scenario 2: 양쪽의 파티션이 일치하지 않음
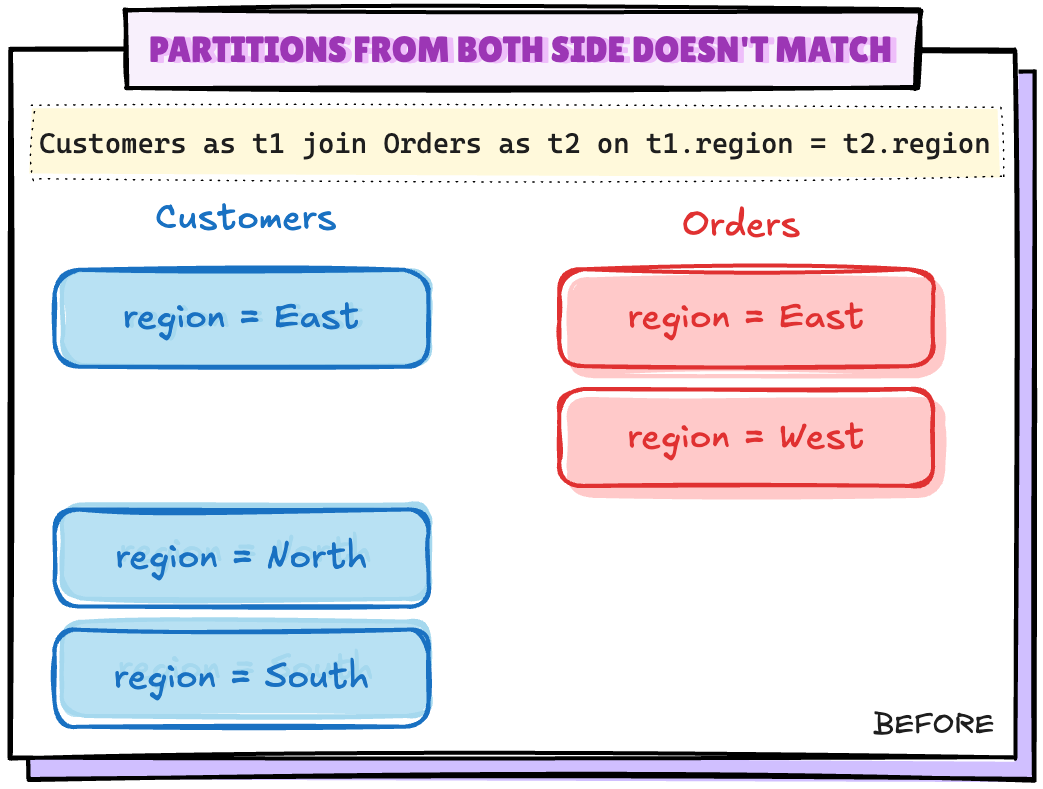
# Deleting all the records for a region
spark.sql("DELETE FROM {ORDERS_TABLE} where region='West'")
# Validating if the partition is dropped
orders_df.groupBy("region").count().show()+------+-----+
|region|count|
+------+-----+
| East| 1243|
| North| 1267|
| South| 1196|
+------+-----+- Orders테이블 에서 하나의 파티션을 삭제하여 동일한 시나리오 구성
joined_df = cust_df.join(order_df, on="region", how="left")
joined_df.explain("FORMATTED")== Physical Plan ==
AdaptiveSparkPlan (9)
+- Project (8)
+- SortMergeJoin LeftOuter (7)
:- Sort (3)
: +- Exchange (2)
: +- BatchScan local.db.customers (1)
+- Sort (6)
+- Exchange (5)
+- BatchScan local.db.orders (4)- 동일한 결합 조건에 대한 계획을 확인
- Exchange(셔플)가 발생
spark.sql.sources.v2.bucketing.pushPartValues.enabled
- 이 기능을 활성화하면 조인의 한 쪽에서 다른 쪽의 파티션 값이 누락된 경우 셔플을 제거
# Enabling config when there are missing partition values
spark.conf.set('spark.sql.sources.v2.bucketing.pushPartValues.enabled','true')
joined_df = cust_df.join(order_df, on='region', how='left')
joined_df.explain("FORMATTED")== Physical Plan ==
AdaptiveSparkPlan (7)
+- Project (6)
+- SortMergeJoin LeftOuter (5)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (4)
+- BatchScan local.db.orders (3)- shuffle이 제거 된 것 확인
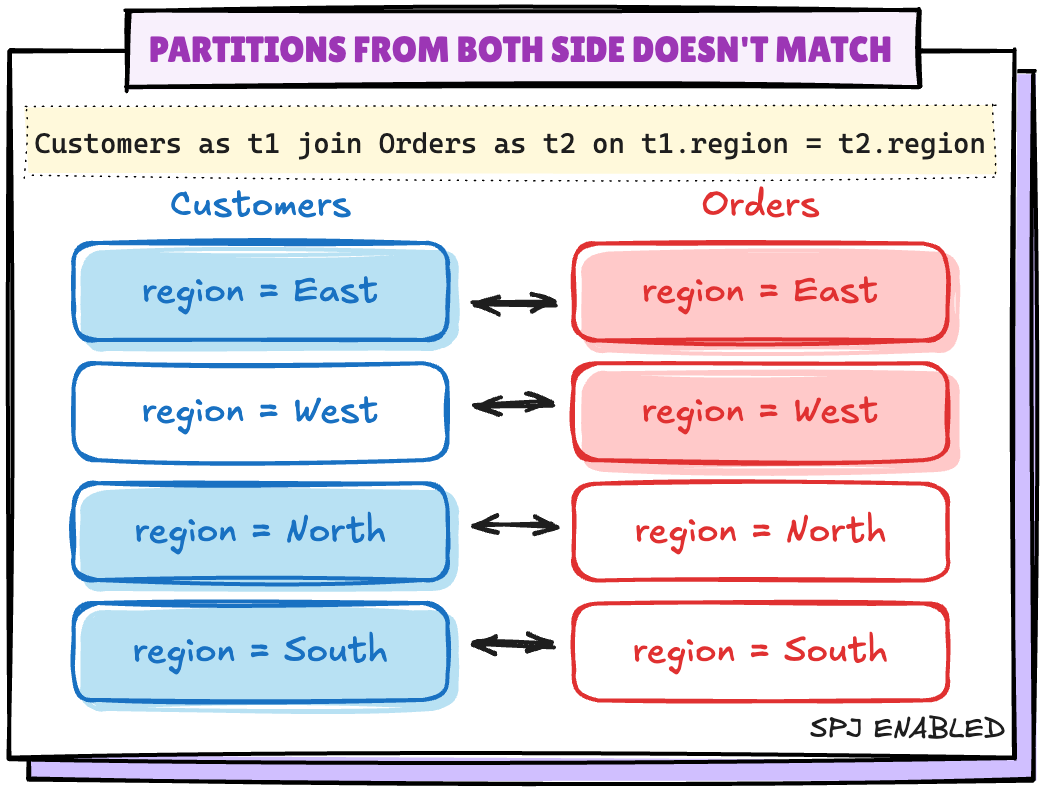
Scenario 3: 조인 키가 파티션 키와 일치하지 않음
Select * from Customers as t1
join
Orders as t2
on t1.region = t2.region
and
t1.customer_id = t2.customer_id -- additional column `customer_id`- Spark에서 셔플을 제거하려면 모든 파티션 키가 동일해야 한다. 이때 아래의 옵션으로 끌 수 있다.
spark.sql.requireAllClusterKeysForCoPartition
- 조인 또는 MERGE 시 클러스터링 키(= 조인 키)와 파티션 키의 정렬 및 순서를 엄격하게 동일하게 맞춰야만 shuffle을 피할 수 있도록 강제하는 옵션으로 기본 값은
true이며 이 것을false로 변경 시켜 셔플을 피한다.
# Setting up another config to support SPJ for these cases
spark.conf.set('spark.sql.requireAllClusterKeysForCoPartition','false')
joined_df = cust_df.join(order_df, on=['region','customer_id'], how='left')
joined_df.explain("FORMATTED")== Physical Plan ==
AdaptiveSparkPlan (8)
+- Project (7)
+- SortMergeJoin LeftOuter (6)
:- Sort (2)
: +- BatchScan local.db.customers (1)
+- Sort (5)
+- Filter (4)
+- BatchScan local.db.orders (3)Scenario 4: 파티션 데이터 Skew
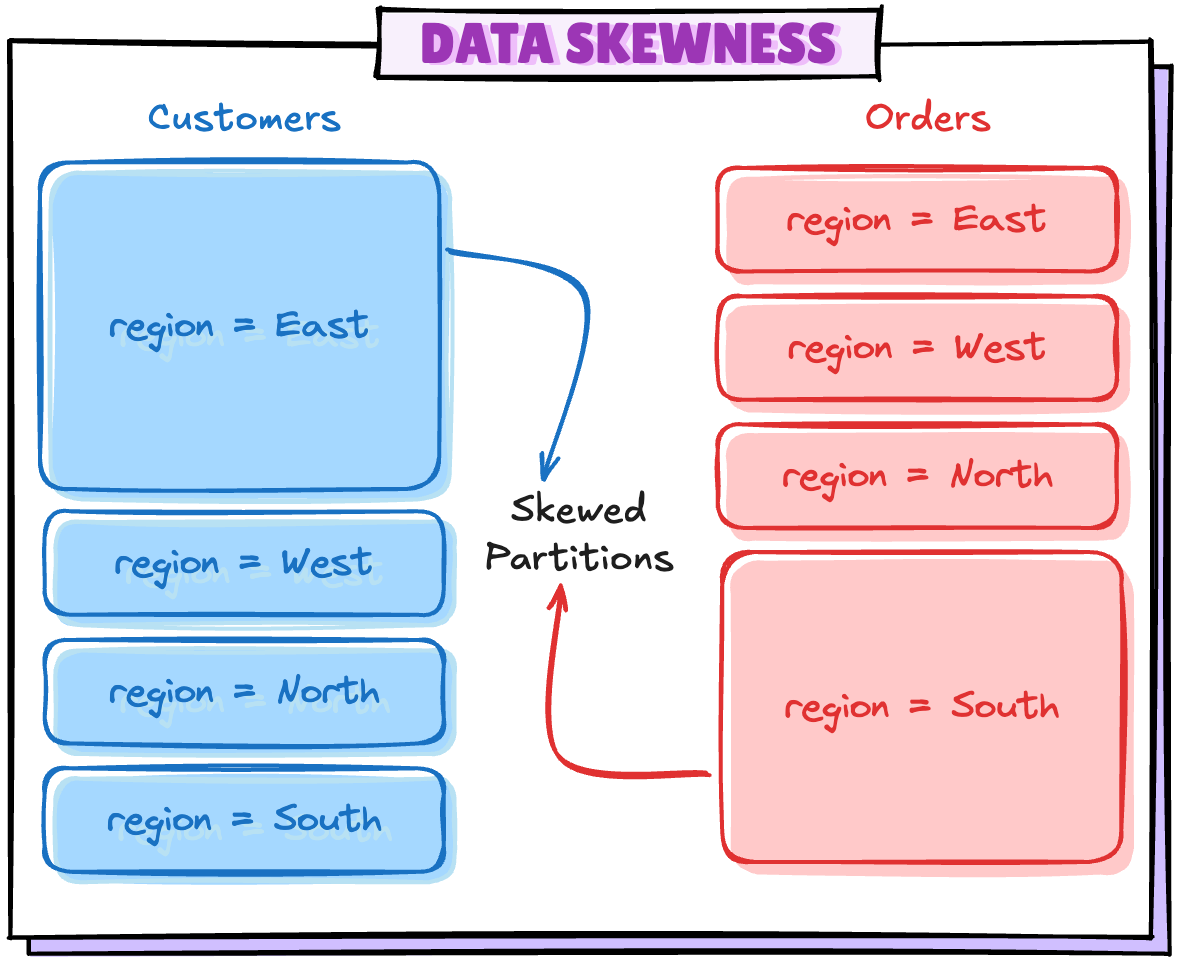
spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled
- true이면, 조인이 Full Outer Join이 아닐 때 파티션 간 데이터 분포 불균형(skew)을 최적화해서 shuffle 없이도 성능 좋게 조인할 수 있도록 도와준다.
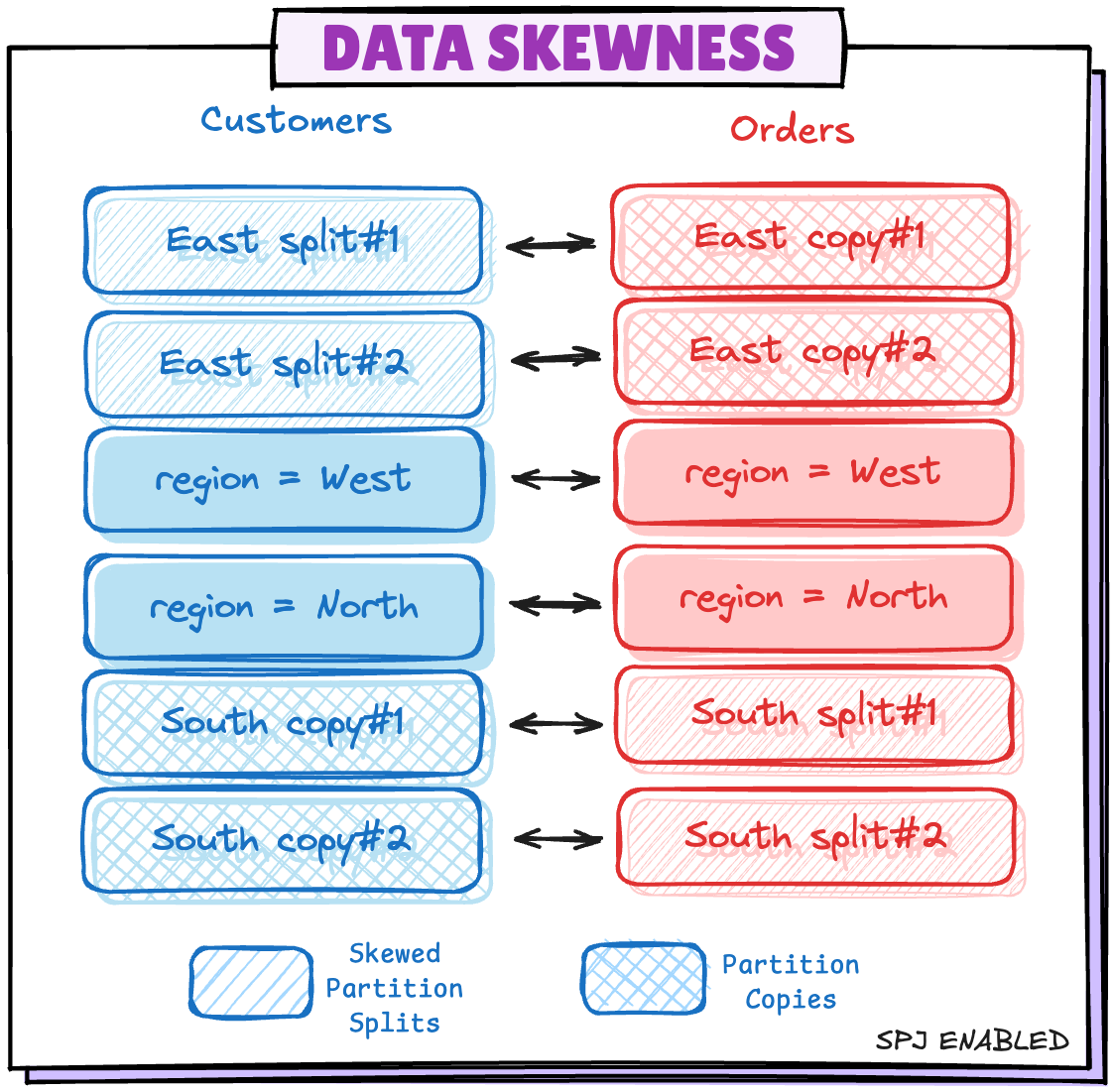
region=East의 기울어진 파티션이 2개의 작은 파티션으로 분할, 테이블 쪽에 2개의 복사본이 생성된다.
참고

Data Engineer