1. Transformer 전체 구조
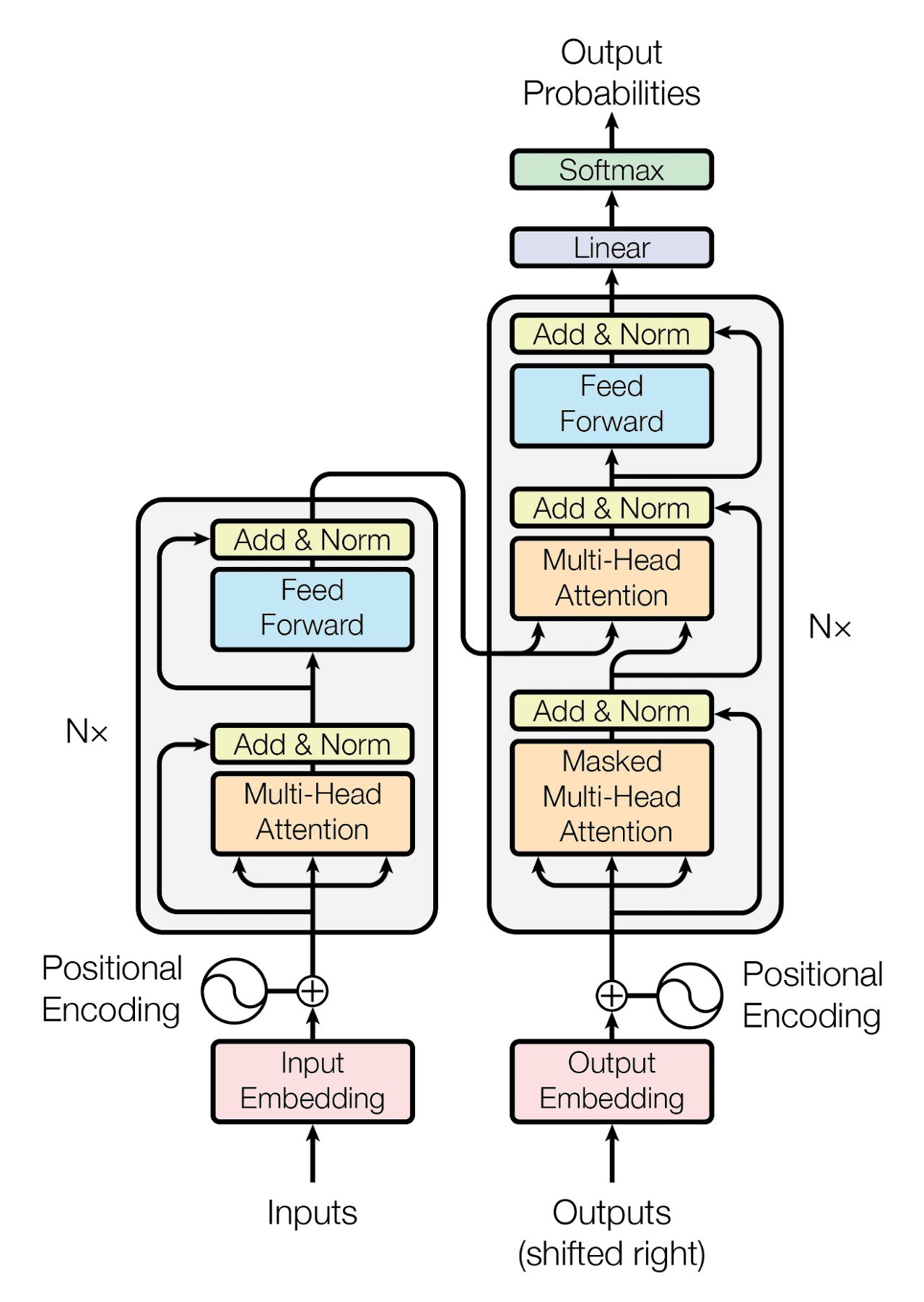
- Transformer = Encoder N개 + Decoder N개 (논문 기준 Nx=6).
- Encoder: 입력 문장을 representation vector로 변환.
- Decoder: 이 representation vector + 정답 문장(label)을 활용해 번역 결과 생성.
- 마지막 Decoder의 출력이 최종 번역 문장.
- 모든 Decoder는 마지막 Encoder의 출력을 공유해서 입력받음.
2. Encoder
구성 요소
- Input Embedding
- 각 단어를 dense vector로 변환한 것
- 예: “I”, “love”, “AI” → 각각 4차원 벡터로 표현
- Positional Encoding
- 단어의 순서를 표현하는 벡터
- (예: 위치 1,2,3 → 사인/코사인 기반 값)
- Multi-Head Attention
- 앞서 설명한 Self-Attention.
- 문장 내부 단어들 사이 관계 학습.
- Self-Attention
- Input Embedding + Postitional Encoding의 값을 Linear 연산을 거쳐 Q,K,V 각각 차원을 줄여 병렬 연산에 적합한 구조를 만듬
- 이렇게 얻은 Q, K, V 에서 Q, K 를 내적하여 Attention Score를 얻음 (얼마나 서로 유사한가 점수)
- 마지막으로 Attention Score와 Value 값을 내적하여 Self-Attention Value를 구하게 되면서 Self-Attention 과정 마무리
- 왜 굳이 Transformer는 Self-Attention을 병렬로 h번 학습시키는 Multi-Head Attention 구조로 이루어져 있을까?
- 그 이유는 Multi-Head를 사용하여 여러 부분에 동시에 Attention을 가할 수 있어서 모델이 입력간 다양한 종속성을 포착하고 동시에 다양한 소스의 정보를 결합할 수 있게 된다.
- Add & Norm (Residual Connection + Layer Norm)
- 입력 + Attention 결과 → 더해줌 (Residual)
- Layer Normalization으로 안정화.
- Feed Forward Network
- Dense Layer 2개 + ReLU.
- 단순한 비선형 변환.
3. Positional Encoding

필요성
- RNN은 순환 구조로 단어 순서를 자연스럽게 반영.
- Transformer는 병렬 처리 구조라 입력 시 단어 순서 정보가 사라짐.
- 따라서 위치 정보(Positional Encoding)를 별도로 추가.
방식
- 논문에서는 Sinusoidal Function 사용:
- pos = 단어 위치, i = 임베딩 차원 인덱스.
- 짝수 index → sin, 홀수 index → cos.
- 위치 인코딩 행렬 + 임베딩 행렬 = 최종 입력.
- 이렇게 하면 모델이 단어 위치 간의 상대적 거리와 순서를 학습할 수 있음.
Concatenate (연결)
- Input Embedding과 Positional Encoding 두 벡터를 옆으로 이어붙이는 방식
- 예:
- Concatenate 결과 (차원 8차원으로 증가):
- 장점: 정보가 손실 없이 보존됨. (정보가 뒤섞이는 혼란을 피할 수 있지만 메모리, 파라미터, 런타임 관련 비용이 발생)
- 단점: 차원이 커져서 연산량 증가 (embedding 512차원 + position 512차원 → 1024차원)
Summation (덧셈)
- Input Embedding과 Positional Encoding 두 벡터를 같은 차원끼리 더하는 방식
- 예:
- 결과 (여전히 4차원):
- 장점: 차원이 그대로 유지되어 모델 구조 단순, 계산 효율 ↑.
- 단점: 단어 의미 벡터와 위치 벡터가 섞여버려 개별적으로 분리하기 힘듦.
Transformer는 왜 Summation을 선택했을까?
- 차원 수를 고정(예: 512)해야 연산이 안정적이고 효율적임.
- Concatenate 하면 차원이 두 배가 되어 학습 파라미터 수, 연산량이 급증.
- Summation은 단순하지만 “단어 의미 + 위치 정보”가 잘 합쳐져서 충분히 성능이 좋음.
4. Decoder
첫 번째 입력
- Label 문장 (정답 번역 문장)이 Embedding + Positional Encoding 되어 입력.
Masked Multi-Head Attention
- Decoder는 문장을 병렬 입력받기 때문에 미래 단어까지 볼 수 있는 문제 발생.
- 예: “나는”을 예측할 때 “로봇이다”까지 본다면 학습이 잘못됨.
- 해결: 마스킹(Masking) → 미래 단어를 -∞ (실제로는 -1e9) 처리해 Softmax 후 확률=0.
- 즉, 현재 시점에서 자신 이전 단어까지만 참조 가능.
Encoder-Decoder Attention
- Decoder 두 번째 Attention Layer.
- Q = Decoder 출력, K,V = Encoder 출력.
- 생성 중인 단어와 입력 문장의 단어들 사이 유사도 계산.
- 예: “남자(번역)” → Encoder 입력 “boy”와 높은 Attention 값.
Feed Forward + Add & Norm
- Encoder와 동일하게 FFN + Residual + Layer Norm.
최종 Linear + Softmax
- Decoder의 마지막 출력 → Linear Layer → Softmax.
- Vocabulary에서 가장 확률 높은 단어 선택.
5. 예시
Encoder
1) 입력 (Embedding + Positional Encoding)
- 문장을 토큰 단위로 나눔 → [“강아지”, “밥”, “먹는다”]
- 각 단어를 숫자 벡터(Embedding)로 변환 → “강아지” = [0.8, 0.1, …] 같은 벡터
- 하지만 Transformer는 단어 순서를 모름 → 그래서 Positional Encoding을 더해줌
- 예: “강아지”는 첫 번째 단어니까 [+sin(1), +cos(1)…] 같은 위치 정보 추가
- 이렇게 하면 모델이 “강아지가 1번째, 밥이 2번째”라는 순서를 알 수 있음
- 결과: 입력 문장이 “의미 + 순서” 정보를 가진 벡터 행렬로 바뀜
2) Self-Attention (자기 자신을 바라보는 단계)
이제 문장 속 단어들이 서로를 참고해서 의미를 업데이트한다.
- “강아지” 벡터가 “밥”과 “먹는다”를 바라보면서,
- “나는 ‘먹는다’와 관련이 크네” → “먹는다”에 높은 가중치
- “밥도 나랑 관련 있네” → “밥”에도 조금 가중치
- “밥”은 “먹는다”와 관계가 크니까 거기에 더 주목
- “먹는다”는 “강아지”와 “밥”을 둘 다 참고
- 결과: 각 단어 벡터가 문맥(Context)을 반영한 새로운 벡터로 업데이트됨
- 즉, “강아지”라는 벡터는 이제 “밥”과 “먹는다”의 의미도 함께 포함하게 됨
3) Residual Connection + Normalization ( Add & Norm 안정화 장치)
- 원래 입력 벡터와 Self-Attention의 출력을 더해줌
- “기존 정보는 잃지 말고, 새로운 정보는 보강하자”라는 의미
- 입력: “강아지” → [0.9, 0.1, 0.2]
- Self-Attention 출력: [0.3, 0.8, 0.5]
- 그냥 출력만 쓰면, 원래 “강아지” 정보가 완전히 바뀔 수 있음, 그래서 입력 + 출력을 더해줌 → [1.2, 0.9, 0.7]
- 즉, 모델이 너무 깊어져도 “초기 정보”가 계속 유지돼서 gradient vanishing(기울기 소실) 문제를 줄여준다.
- 그리고 Layer Normalization으로 값의 분포를 정리
- 너무 크거나 작은 값이 생기지 않도록 안정화
- LayerNorm은 벡터의 평균과 분산을 맞춰서 값이 일정한 분포를 가지게 해준다. (학습이 안정적이고, 학습 속도도 빨라지게 됨)
- 이렇게 하면 학습이 잘 안 되는 문제(gradient 소실 등)를 막아줌
4) Feed Forward Network (간단한 작은 뇌)
- 각 단어(토큰) 벡터를 독립적으로 변환하는 작은 신경망
- Self-Attention은 “단어 간 관계(문맥)”를 학습하는 단계인데 이걸로는 단어 자체의 복잡한 특징을 충분히 표현하기 어렵다 따라서 FFN이 각 단어 벡터를 더 비선형적으로 바꿔줘서
- 예: “강아지” → “동물” 특징을 강화
- “밥” → “음식” 특징 강화
- “먹는다” → “행동/동사” 특징 강화
- 처럼 단어별 벡터가 더 추상적이고 의미 있는 표현을 만드는 과정
5) 또 Residual Connection + Normalization
- Feed Forward의 출력과 입력을 더해줌
- 다시 Normalization으로 안정화
Decoder
1) 입력 (Embedding + Positional Encoding)
Decoder는 “번역 결과 문장”을 만들어내야 함.
- 훈련(Train) 때는 정답 문장(Label)을 입력으로 준다.
- 추론(Test) 때는 지금까지 번역한 단어들을 입력으로 사용한다.
예: 영어 → 한국어 번역
- 입력 문장: “I eat rice”
- Decoder 입력(Label): “나는 밥을 먹는다”
이 Label 문장도 Encoder와 똑같이 Embedding + Positional Encoding 과정을 거친다.
2) Masked Multi-Head Attention (미래 단어 못 보게 막기)
- Encoder에서는 그냥 Self-Attention을 썼는데,
- Decoder는 Masked Self-Attention을 쓴다.
- 그 이유는 Decoder는 한 단어씩 순서대로 번역해야 하는데, 병렬 입력 시 “뒤 단어”까지 미리 볼 수 있으면 학습이 잘못된다.
예:
- “나는 ___”을 예측해야 하는데, 뒤에 “밥”까지 보게 되면 치팅이 된다.
- 그래서 미래 단어 Attention 값은 -∞ (mask) 처리해서 softmax 후 확률이 0이 되게 막는다.
3) Encoder–Decoder Attention
이제 Decoder가 Encoder 출력(Context Vector)를 참고할 차례이다.
- Query(Q) = Decoder의 출력 (지금까지 생성된 문장)
- Key(K), Value(V) = Encoder의 출력 (입력 문장의 문맥 표현)
- 이렇게 하면, Decoder가 생성하려는 단어와 입력 문장의 단어들 간 관계를 학습할 수 있다.
예:
- Decoder가 “밥(rice)”을 생성하려 할 때 → Encoder 입력 “rice”와 Attention 값이 크게 연결됨.
- Decoder가 “먹는다(eat)”를 생성하려 할 때 → Encoder 입력 “eat”과 강하게 연결됨.
4) Feed Forward Network (FFN)
- Encoder와 똑같이 FFN을 통과한다.
- 각 단어 벡터를 개별적으로 더 추상화.
- “나는” → 주어 강조
- “밥” → 목적어 강조
- “먹는다” → 동사 강조
5) 최종 Linear + Softmax
- 마지막 Decoder 블록 출력 → Linear Layer + Softmax
- Linear: 벡터를 “어휘집 크기” 차원으로 변환 (예: 단어 사전이 10,000개라면 10,000차원)
- Softmax: 각 단어가 될 확률 계산
- 예
- “나는” 예측 시
- “나는” = 0.75
- “너는” = 0.10
- “그는” = 0.05
- …
→ 확률이 가장 높은 “나는” 출력.
6. 요약
Transformer Encoder 흐름
입력 문장 (토큰들)
→ Embedding + Positional Encoding (단어 의미 + 위치 정보)
→ [Encoder Block 1]
- Multi-Head Self-Attention (여러 Head 병렬)
- Residual + Norm
- Feed Forward Network
- Residual + Norm
→ [Encoder Block 2] (동일 구조 반복)
→ … (총 N개, 논문 기준 N=6)
→ 최종 Encoder Output (문장 전체 의미 표현)Transformer Decoder 흐름
출력 문장 (정답/이전까지 생성된 단어)
→ Embedding + Positional Encoding
→ [Decoder Block 1]
- Masked Multi-Head Self-Attention (미래 단어 가림, 여러 Head 병렬)
- Residual + Norm
- Encoder–Decoder Multi-Head Attention (출력 ↔ 입력 연결, 여러 Head 병렬)
- Residual + Norm
- Feed Forward Network
- Residual + Norm
→ [Decoder Block 2] (동일 구조 반복)
→ … (총 N개, 논문 기준 N=6)
→ Linear + Softmax (다음 단어 확률 분포 예측)
→ 최종 번역 문장 생성