1. Transformer와 Attention
Transformer 개요
- Transformer는 현재 딥러닝의 backbone 아키텍처.
- 시작: NLP의 기계 번역(Seq2Seq의 한계 극복)
- 현재: NLP뿐만 아니라 Vision, Graph, Generative Model까지 확장.
- 첫 논문: Attention is all you need (NeurIPS 2017).
- 핵심: RNN의 순환 구조를 완전히 대체한 Attention Mechanism.
2. Attention 직관
예시 문장
- “강아지가 책상 위에 있는 음식을 먹었는데 그가 그것을 먹은 이유는 배고팠기 때문이다.”
- “그” → “강아지”
- “그것” → “음식”
- 사람은 문맥을 통해 쉽게 연결하지만, 모델은 단어 간 연관성(Dependency)을 학습해야 함.
- Attention은 “중요한 단어와는 강하게 연결, 중요하지 않은 단어와는 약하게 연결”하도록 학습하는 메커니즘.
3. Self-Attention 연산 과정
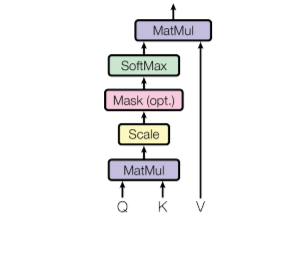
(1) 입력: 단어 임베딩
- 각 단어 → 임베딩 벡터 (예: 차원=100)
- 문장 길이 = 12라면, 임베딩 행렬 크기: .
(2) Q, K, V 행렬 생성
- 가중치 행렬 를 곱해 각각 Query, Key, Value 행렬 생성.
- 예: 크기 =
(3) 유사도 계산
- 각 단어 Query vs 다른 단어 Key 내적 → 유사도 점수
(4) 스케일링
- : Key 차원 (예: 49라면 ).
- 스케일링으로 안정적 학습.
(5) Softmax
- 각 행 = 해당 단어와 모든 단어의 연관 확률.
- 성분 0~1, 합=1.
- 예: Score 행렬 1행 = 단어 “강아지”와 모든 단어의 유사도.
(6) 가중합
- Value 벡터들의 가중합(Weighted Sum)
- 단어 표현이 문맥 기반으로 업데이트됨.
- 이것이 Self-Attention 결과 (Z)
4. Multi-Head Attention
- Self-Attention을 단일 Head로 하지 않고, 여러 개 병렬로 수행.
- 예: Head=6 → Attention 결과 6개 Z_1, Z_2, …, Z_6.
- 이들을 Concatenate 후, 가중치 행렬 로 선형 변환.
- Multi-head = 서로 다른 “관점(Attention pattern)”을 학습해 더 풍부한 문맥 표현

Data Engineer