- Spark 작업을 수행할 때 다음과 같은 상황이 자주 발생
- 여러 테이블의 데이터를 읽어서 통계나 레코드 수를 계산하는 작업
- 모든 작업이 서로 의존하지 않는 독립적인 쿼리일 경우, Spark는 이를 순차적으로 처리
- 즉, 병렬 처리를 제대로 활용하지 못하는 상황이 많음
멀티스레딩 없이 처리
# List of tables
TABLES = ['db1.table1', 'db1.table2',
'db2.table3', 'db2.table4',
'db3.table5', 'db3.table6']
# List to keep the dictionary of table_name and respective count
table_count = []
# function to get the table records count.
def get_count(table: str) -> dict:
count_dict = {}
count_dict['table_name'] = table
try:
count = spark.read.table(table).count()
count_dict['count'] = count
except Exception:
count_dict['count'] = 0
return count_dict
def main():
for table in TABLES:
table_count.append(get_count(table))
if __name__ == "__main__":
main()
# Creating dataframe from list
count_df = spark.createDataFrame(table_count)\
.withColumn("date", datetime.now().date())
# writing into the table
count_df.coalesce(1).write.insertInto("control_db.counts_table")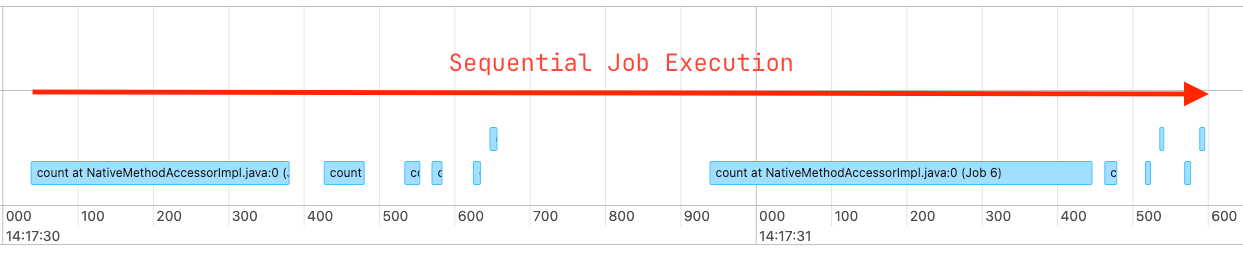
- 위 방식은 테이블을 하나씩 읽고 .count() 수행 → 완전히 순차적
- 테이블이 많을수록 전체 실행 시간이 느려짐
ThreadPoolExecutor로 병렬 처리
from concurrent.futures import ThreadPoolExecutor
# List of tables
TABLES = ['db1.table1', 'db1.table2',
'db2.table3', 'db2.table4',
'db3.table5', 'db3.table6']
# function to get the table records count.
def get_count(table: str) -> dict:
...
# same as before
return count_dict
# Code implementation using ThreadPoolExecutor
def main():
counts = []
with ThreadPoolExecutor(max_workers=6) as executor:
counts = executor.map(get_count, TABLES)
return counts
if __name__ == "__main__":
table_count = main()
# Creating dataframe from list
count_df = spark.createDataFrame(table_count)\
.withColumn("date", datetime.now().date())
# writing into the table
count_df.coalesce(1).write.insertInto("control_db.counts_table")
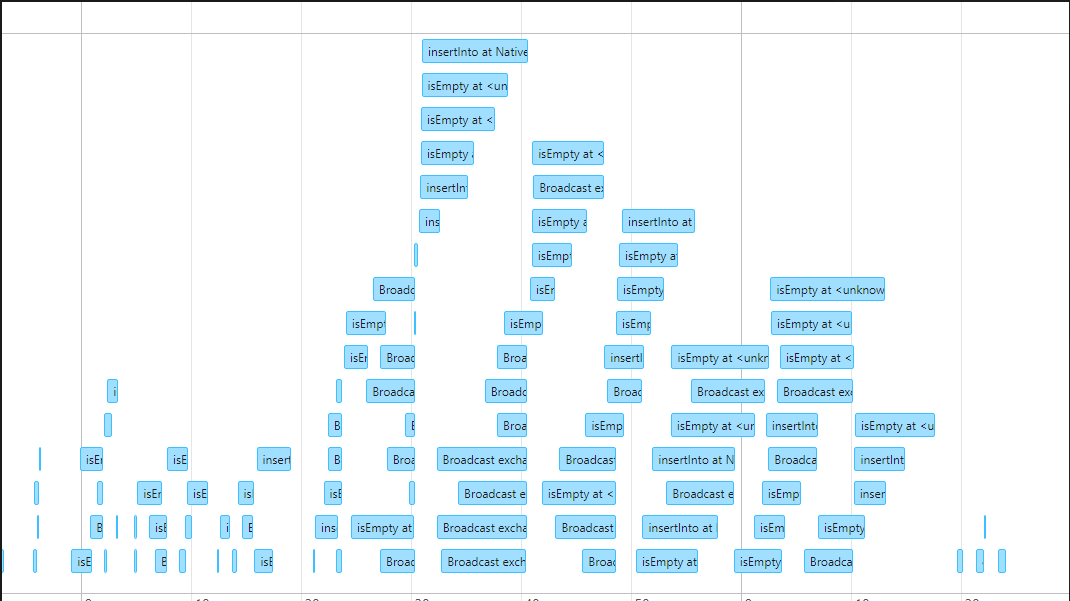
- 멀티스레딩을 통해 동시에 Spark 작업을 트리거하는 방식으로 성능을 개선
- concurrent.futures.ThreadPoolExecutor는 Python의 최신 멀티스레딩 API
- 사용법이 간단하고, 공식 문서에서도 권장됨
- 예전의 multiprocessing.pool.ThreadPool보다 코드가 간결하고 직관적
- 하지만 에러가 발생했을때 로그 추적이나 에러 분석이 어려움
에러 디버깅을 쉽게 하기 위해 ThreadPoolExecutor를 안전하게 사용하기 위한 최종 코드
# With exception hadling to make debugging easier
from concurrent.futures import ThreadPoolExecutor, as_compeleted
def main(TABLES: list) -> None:
"""Main method to submit count jobs in parallel.
Args:
TABLES (list): list of table name.
Raises:
e: Exception in case of any failures
"""
with ThreadPoolExecutor(max_workers=6) as executor:
to_do_map = {}
for table in TABLES:
# Submitting jobs in parallel
future = executor.submit(get_count, table)
print(f"scheduled for {table}: {future}")
to_do_map[future] = table
done_iter = as_completed(to_do_map)
for future in done_iter:
try:
count = future.result()
print("result: ", count)
count_list.append(count)
except Exception as e:
raise eexecutor.submit(func, arg)func(arg) 작업을 백그라운드에서 실행하도록 예약하고 Future 객체를 반환Future아직 실행이 끝나지 않은, 나중에 결과가 생길 객체, result()로 결과를 얻을 수 있음as_completed()작업이 완료된 순서대로 Future 객체들을 iterable로 반환future.result()작업 결과를 꺼냄, 이 시점에서 Exception이 터지면 캐치 가능
Spark에서 GIL(Global Interpreter Lock)은 영향을 줄까? NO
이유 1: Spark는 JVM에서 실행되기 때문에 Python GIL과 직접적인 관련이 없다
- Spark 자체는 JVM 기반의 분산 컴퓨팅 엔진
- Python에서 사용하는 PySpark는 JVM과 통신하는 Wrapper일 뿐
- 따라서 Spark 작업은 결국 JVM 프로세스 안에서 실행되고, GIL의 영향을 받지 않는다.
이유 2: PySpark는 작업 실행 시 Python 워커 프로세스를 생성하며, 이때 os.fork()를 사용
- PySpark가 Python 코드를 클러스터에서 실행하려고 할 때, JVM이 Python 워커 프로세스를 생성
- 이때 사용하는 방식은 Linux에서 흔히 사용하는 os.fork()이며, 이는 완전히 별도의 프로세스를 생성
- 각각의 프로세스는 자신만의 GIL을 가지기 때문에, 서로 영향을 주지 않는다.
즉, Spark가 Python 작업을 실행할 때는 멀티스레드가 아닌 멀티프로세스 구조이기 때문에 GIL의 영향을 받지 않는다.
daemon.py는 언제 실행될까?
Spark에서 action (예: .collect(), .count())이 실행되면 다음 과정이 일어남
- Spark Driver가 작업을 정의
- daemon.py가 각 워커 노드에서 Python 프로세스를 생성
- 해당 프로세스들이 Python 코드 실행 및 데이터 처리 담당
실무 적용 예시
- Data Pipeline에 들어가기전 잘못된 레코드들을 필터링 하는 데이터 품질(DQ) 체크 프레임워크 개발
- DQ 테이블에 저장되는 쿼리들은 여러 데이터 소스와 수백 개의 쿼리로 구성되어 있으며 개발자들은 필요에 따라 더 많은 쿼리를 추가하는 중
기존 방식: for 루프 순차 실행
- 수백 개의 쿼리를 for loop로 하나씩 실행함.
- 실행 시간: 약 20분 소요.

개선 방식: ThreadPoolExecutor 멀티스레딩
- ThreadPoolExecutor를 사용해 쿼리를 병렬로 실행.
- 실행 시간: 약 3분으로 단축.
주의할 점 (Common Pitfalls)
1. Client 모드에서 max_executors 조심
- Spark가 Client 모드로 실행되면 드라이버가 로컬 머신에서 실행
- max_executors 값을 과하게 설정하면, 드라이버가 과도한 리소스를 사용
- 클러스터가 여러 팀과 공유된다면, 서로의 작업에 영향을 줄 수 있음
2. 동시 Job 제출 시, 드라이버 메모리 사용량 증가
- 너무 많은 job을 동시에 제출하면, 드라이버의 메모리 사용량이 증가
- Spark 드라이버 OOM(out of memory) 문제로 이어질 수 있음
3. 예외 처리 매우 중요
- 병렬 작업에서는 future.result() 호출 시 예외가 발생할 수 있음
- try-catch 없이 그냥 쓰면 어디서 실패했는지 디버깅이 매우 어려움
- as_completed() + try: future.result() 조합으로 정확한 실패 위치 추적 가능
4. 병렬로 테이블에 쓰는 경우 주의
- 테이블에 동시에 데이터를 쓰면 ConcurrentModificationException 발생 가능
- 특히 partitionOverwriteMode = dynamic인 경우, 동일 파티션에 여러 작업이 덮어쓰면 충돌 발생
- 병렬 쓰기를 하려면 테이블 파티셔닝 구조를 잘 이해하고 설계해야 함
참고

Data Engineer