문제 발생
from pyspark.sql import Row
from pyspark.sql.functions import lit, col
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# 더미 데이터프레임 생성
df = spark.createDataFrame([Row(id=1, name='abc'), Row(id=2, name='xyz')])
# 추가할 열 목록
dummy_col_list = ['foo1', 'foo2', 'foo3', 'foo4', 'foo5']
# for 루프를 사용하여 열 추가
for col_name in dummy_col_list:
df = df.withColumn(col_name, lit(None).cast('string'))- 데이터프레임에 여러 개의 열을 추가하거나 형변환해야 하는 상황에서, 일반적으로
.withColumn()메서드를 for문과 같은 문법을 이용하여 반복적으로 사용하는 방법을 선택한다. - 이 방법은 코드를 간결하게 작성하는 것이 가능하지만
.withColumn()메서드를 과도하게 사용하면 성능 저하가 유발된다.
df.explain("extended")== Analyzed Logical Plan ==
id: bigint, name: string, foo1: string, foo2: string, foo3: string, foo4: string, foo5: string
Project [id#47L, name#48, foo1#51, foo2#55, foo3#60, foo4#66, cast(null as string) AS foo5#73]
+- Project [id#47L, name#48, foo1#51, foo2#55, foo3#60, cast(null as string) AS foo4#66]
+- Project [id#47L, name#48, foo1#51, foo2#55, cast(null as string) AS foo3#60]
+- Project [id#47L, name#48, foo1#51, cast(null as string) AS foo2#55]
+- Project [id#47L, name#48, cast(null as string) AS foo1#51]
+- LogicalRDD [id#47L, name#48], false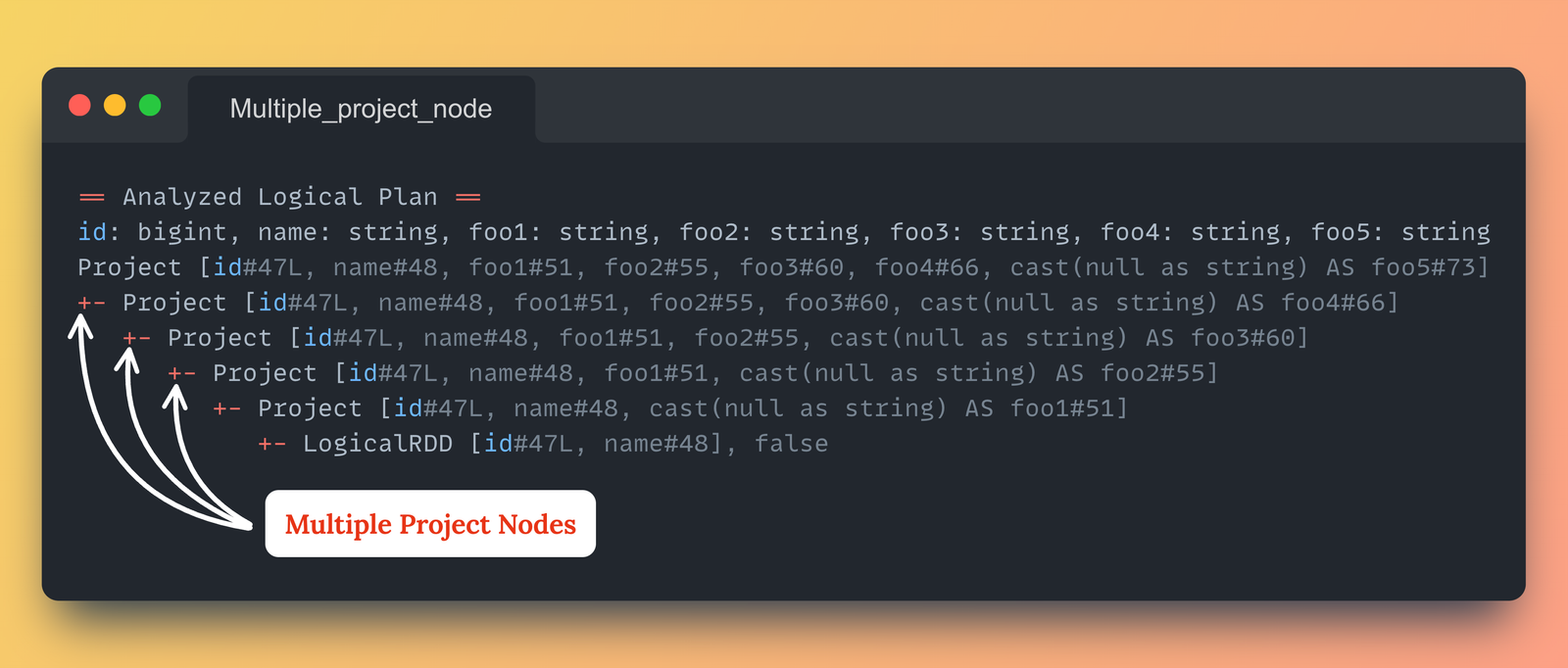
- Spark의 Logical Plan을 확인해보면 Project 노드가 재귀적으로 누적되며, 플랜의 깊이(=중첩 정도)가 깊어진다.
- 따라서 Catalyst 옵티마이저가 매번 전체 계획을 재평가하게 만들어 성능 저하를 유발하게된다.
해결책
Spark 3.3 이상의 .withColumns() 메서드 사용
# 더미 데이터프레임 생성
df = spark.createDataFrame([Row(id=1, name='abc'), Row(id=2, name='xyz')])
# 추가할 열과 값의 딕셔너리 생성
dummy_col_val_map = {
'foo1': lit(None).cast('string'),
'foo2': lit(None).cast('string'),
'foo3': lit(None).cast('string'),
'foo4': lit(None).cast('string'),
'foo5': lit(None).cast('string')
}
# withColumns를 사용하여 열 추가
df = df.withColumns(dummy_col_val_map)== Analyzed Logical Plan ==
id: bigint, name: string, foo1: string, foo2: string, foo3: string, foo4: string, foo5: string
Project [id#13L, name#14, cast(null as string) AS foo1#157, cast(null as string) AS foo2#158, cast(null as string) AS foo3#159, cast(null as string) AS foo4#160, cast(null as string) AS foo5#161]
+- LogicalRDD [id#13L, name#14], false- Spark 3.3부터는 단일 Project 노드로 여러 열을 한번에 추가하여 성능 저하를 방지 할 수 있는
.withColumns()메서드 도입
.select() 또는 .selectExpr() 메서드 활용
from pyspark.sql.functions import lit
# .select()와 alias() 사용
df = df.select("*", *[lit(None).cast('string').alias(cname) for cname in dummy_col_list])
df.explain("extended")== Analyzed Logical Plan ==
id: bigint, name: string, foo1: string, foo2: string, foo3: string, foo4: string, foo5: string
Project [id#184L, name#185, cast(null as string) AS foo1#197, cast(null as string) AS foo2#198, cast(null as string) AS foo3#199, cast(null as string) AS foo4#200, cast(null as string) AS foo5#201]
+- LogicalRDD [id#184L, name#185], falsefrom pyspark.sql.functions import lit
# .selectExpr() 사용
df = df.selectExpr("*", *[f"NULL as {cname}" for cname in dummy_col_list])
df.explain("extended")== Analyzed Logical Plan ==
id: bigint, name: string, foo1: void, foo2: void, foo3: void, foo4: void, foo5: void
Project [id#13L, name#14, null AS foo1#145, null AS foo2#146, null AS foo3#147, null AS foo4#148, null AS foo5#149]
+- LogicalRDD [id#13L, name#14], false- 여러 열을 추가해야 하는 경우, .select() 메서드와 alias()를 함께 사용하거나 .selectExpr() 메서드를 활용하여 단일 Project 노드로 처리할 수 있다.
참고

Data Engineer