10장 하둡 관리
HDFS
영속적인 데이터 구조
주 네임노드
주 네임 노드의 디렉토리 구조
${dfs.name.dir}/current/VERSION /edits /fsimage /fstime
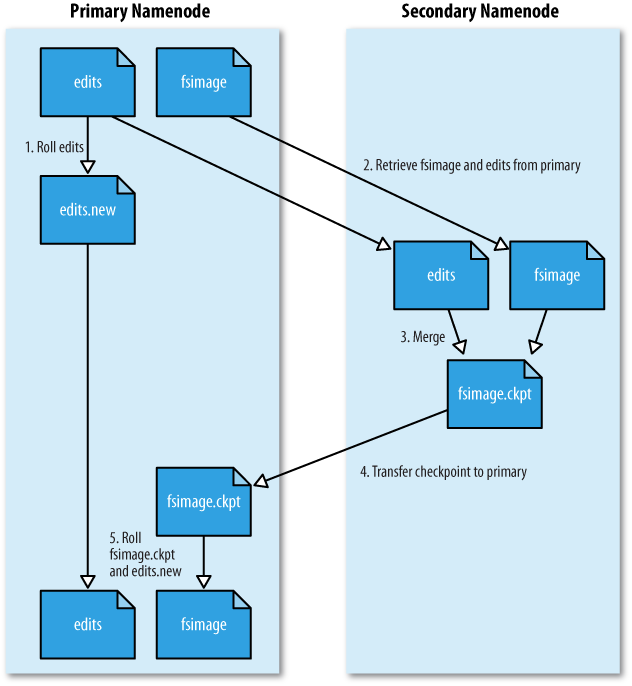
- 보조 네임노드는 주 네임노드에 edits 파일을 순환 사용하도록 요청한다. 그 때문에 새로운 edits 로그는 새로운 파일을 저장된다.
- 보노 네임노드는 HTTP GET을 이용해서 주 네임노드의 fsimage와 edits를 가져온다.
- 보조 네임노드는 fsimage를 메모리에 올리고 나서 editsdml 각 동작을 반영한다. 그리고 나서 새롭게 통합된 fsimage 파일을 생성한다.
- 보조 네임노드는 HTTP POST를 이용하여 새로운 fsimage 파일을 주 네임노드에 전송한다.
- 주 네임노드는 이전 이전 fsiamge를 보조 네임노드로부터 받은 새로운 이미지로 교체하며, 이전 파일을 1단계에서 시작한 새로운 edits로 교체한다. fstime 파일도 체크포인트가 발생한 시간을 기록하기 위해 변경된다.
보조 네임노드
보조 네임노드의 메모리
체크포인트 과정을 이해한다면, 왜 보노 네임노드의 메모리가 주 네임노드와 비슷한 메모리를 갖춰야 하는지 알 수 있다.
보조 네임 노드의 디렉토리 구조
${dfs.name.dir}/current/VERSION /edits /fsimage /fstime /previous.checkpoint/VERSION /edits /fsimage /fstime
체크포인팅을 수행후 보조 네임노드에는 previous.checkpoint 디렉토리에 부수적으로 저장된다. 만약 모든 데이타가 날아갔을 경우 네임노드가 시작될때 -imortCheckpoint 옵션으로 fs.checkpoint.dir 속성에 정의된 디렉토리에서 가장 최근의 메타데이타를 가져온다.
데이타 노드
데이터노드 디렉토리 구조
${dfs.data.dir}/current/VERSION /blk_<id_1> /blk_<id_1>.meta /blk_<id_2> /blk_<id_2>.meta /... /blk_<id_64> /blk_<id_64>.meta /subdir0/ /subdir1/ /... /subdir63/
- datanode.numblocks 속성에 의해 fan-out 형태로 저장되므로 디렉토리내 파일 갯수 제한 문제를 해결한다.
- dfs.data.dir으로 등록된 디렉토리 리스트에 라운드로빈방식으로 저장한다.
안전모드
네임노드는 시작직후 fsimage를 메모리에 적제하고 edits로그의 변경사항을 반영하고, 완전한 메타데이타가 재구성되면 새로운 fsimage와 빈 edit 로그를 생성한다. 그리고 안전모드로 들어간다. 읽기 전용의 RPC와 HTTP 요청이 수락된다. 그리고 데이타노드들로부터 블락정보를 넘겨받는다. 최소 복제 상태가 되도록 만들고 최소 복제 상태가 되면 30초후 안전모드가 해제된다.
안전 모드 속성
| 속성이름 | 유형 | 기본값 | 설명 |
|---|---|---|---|
| dfs.replication.min | 정소 | 1 | 쓰기 작업이 성공하기 위해서 쓰여져야 하는 복제본 수 |
| dfs.safemode.threshold.pct | 실수 | 0.999 | 네임노드가 안전모드에서 빠져나오기 위해서 dfs.replication.min에서 정의한 최소 복제 수준을 충족하는 시스템 내 블록들의 비율. 이 값을 0이나 그 이하로 설정하면 네임노드는 안전모드 없이 시작된다. 이 값을 1보다 크게 하면 네임노드는 안전모드 상태에서 벗어나지 않는다. |
| dfs.safemode.extension | 정수 | 30,000 | dfs.safemode.threshold에서 정의한 최소 복제 수준이 만족되고 나서, 안전 모드 상태를 얼마나 더 유지할지를 밀리 세컨드 단위로 정함. 작은 클러스터의 경우(수십대 이하)에는 0초도 설정가능 |
안전모드 인지 확인하기
% hadoop dfsadmin -safemode get Safe mode is ON
특정 명령이 실행되기전에 안전모드가 빠져 나오기를 기다리게 하기
% hadoop dfsadmin -safemode wait #파일읽기 쓰기 명령 모두 올 수 있음
안전 모드 진입
% hadoop dfsadmin -safemode enter Safe mode is ON
안전모드 빠져나오기
% hadoop dfsadmin -safemode leave Safe mode is OFF
감사 로깅
하둡은 log4j로 로깅한다. 기본 레벨이 WARN이고 INFO로 변경하면 모든 파일 시스템 접근 요청들을 기록할 수 있다.
도구
hadoop dfsadmin
- 파일 시스템 통계, 연결된 데이터 노드 정보
- 안전모드 관련
- 인-메모리 파일시스템 이미지를 새로운 fsimage 파일에 저장. edits 초기화
- 데이터노드의 집합 변경
- hdfs 업그레이드
- 버전 정보 삭제
- 디렉토리 쿼터 설정, 삭제
- 디렉토리의 공간 쿼터 설정, 삭제
- 네임노드에 대한 서비스 수준의 권한 reload
hadoop fsck
찾거나 고쳐준다.
- 과잉 복제된 블록
- 부족하게 복제된 블록
- 잘못 복제된 블록(한쪽 랙에 블록들이 몰리거나 했을 경우)
- 오염된 블록
- 없어진 복제본
- 해당 파일의 블록 위치
- 기본 504시간(dfs.datanode.scan.preiod.hours)마다 데이터 노드 블럭 스캐너가 작동한다.
밸런서
밸런서 시작하기
% start-balancer.sh
- 클러스터당 1개의 밸런서만 실행되며
- 균형상태가 될때까지 샐행된다.
- 혼자서 알아서 잘 실행된다.
- 밸런서가 사용하는 대역폭은 dfs.balance.bandwidthPerSec 를 바이트 단위로 조정할 수 있다.
모니터링
로깅
- 영속적인 로그레벨 변경시 log4j.properties 를 변경
- 아래 내용처럼 하면 잡트래커가 재시작될때 반영된다.
잡트래커가 재시작될때 로그레벨 변경하기
% hadoop daemonlog -setlevel jobtracker-host:50050 org.apache.hadoop.mared.JobTracker DEBUG
- http://jobtracker-host:5003/stacks 에 접속하면 잡트캐러의 스레드 덤프를 얻을 수 있다.
매트릭스
- 매트릭스는 카운터와 다르다. 매트릭스는 관리자를 위해 카운터를 사용자를 위해 존재한다.
- 하둡 데몬은 여러가지 컨텍스트(dfs, mapred, rpc, jvm)에 속하는 매트릭스들을 수집한다. 예를 들어 데이터 노드는 dfs, rpc, jvm 컨텍스트에 대한 매트릭스를 수집한다.
- conf/hadoopmetrics.properteis 에 매트릭스가 설정 된다.
- MetricsContext 인터페이스를 구현하거나 구현된 컨텍스트를 사용할 수 있다.
- FileContext - 생략
- GangiaContext - 규모가 큰 클러스터를 위한 오픈 소스 분산 모니터링 시스템
- NullContextWithUpdateThread - JMX류를 위해 구현. GraniaContext도 이와 같은 동작이 진행됨. 메트릭스가 기본 5초 주기로 갱신됨.
- CompositeContext - Context들을 여러개 같이 사용할때
자바 관리 익스텐션(JMX)
- NullContextWithUpdateThread 를 사용하면 JConsole로 JVM에 접속해 MBean의 최신 상태 값들을 확인 할 수 있다.
- 일반적으로 나지오스같은 경보 시스템과 갱글리아를 연계해서 하둡클러스터를 모니터링 한다.
- 나지오스는 JMX를 접속할 수 있도록 권한,과 원격접속 활성화등의 설정을 해주어야 한다. 책 참조.
관리
일상적인 관리 절차
- 메타데이터는 보조 네임노드의 previous.checkpoint 하위 디렉토리를 스크립트로 주기적으로 단계별로 원격 백업해라.
- 데이터노드의 백업은 전체 데이타의 량이 많으므로 우선순위를 정해 중요한 순서로 백업한다. 100% 안전하다고 생각하지말아라. distcp 명령이 병렬복사를 하므로 유용하다.
- fsck, 밸런서를 주기적으로 활용해라.
노드 위임과 해제
- 방화벽아래라도 안전하다고 방식하지마라. 데이타 노드는 명식적으로 관리해야한다. 외계인 노드가 침입할 수 있다!
- 네임노드에 연결이 허용된 데이타 노드는 dfs.hosts로 지정한 파일에 한줄씩 기재한다. 이파일은 네임노드와 같은 로컬 파일 시스템이다.
- 잡트래커에 연결될 태스크 트래커의 노드는 mapred.hosts로 지정한 파일에 한줄씩 기재한다. 보통 데이타 노드와 태스크 트래커는 같은 머신에 존재하므로 dfs.hosts = mapred.hosts
- slaves 파일은 클러스터가 시작될때만 사용된다. 하둡데몬은 slaves를 참조하지 않는다.
추가하기
- 인클루드 파일에 새 노드의 네트워크 주소를 추가
- 아래 명령어를 이용해 네임노드에 허가된 데이터 노드 집합 반영
% hadoop dfsadmin -refreshNodes - 새 노드가 하둡 제어 스크립트에 의해 클러스터에서 사용될 수 있게 slaves 파일 갱신
- 새 데이터노드 시작
- 맵리듀스 클러스터를 재시작 (mapred.jobtracker.restart.recover=true 로 설정하면 재시작시 실행되던 잡들이 복구됨)
- 새로운 새로운 데이터노드와 태스크트래커가 웹 UI에 나타나는지 확인
해제하기
- 해제할 노드의 네트워크 주소를 exclude 파일에 추가. include 파일은 그대로
- 해제할 노드의 태스크트래커를 중지하기 위해 맵리듀스 클러스터를 재시작
- 허가된 새로운 데이터노드를 가지고 네임노드를 갱신
% hadoop dfsadmin -refreshNodes - 웹 UI에 접속해서 해제할 데이터노드들의 관리 상태가 'Decommisioning in Progress'로 변했는지 확인
- 모든 데이터노드가 블록 복사를 완료하면 관리 상태가 'Decommeissioned'
- 해제된 노드 중단
- include 파일에서 해당 노드 삭제 후
% hadoop dfsadmin -refreshNodes - slaves 파일에서 해당 노드 삭제
업그레이드
- 작은 클러스터에서 데이트 해보고 진행하라.
- 모두 케이스 바이 케이스다. 잘 찾아보고 해라.
- 업그레이드전 fsck 결과물과 후의 결과물을 비교해 보라.
- 파일 시스템 레이아웃을 변경하는 업그레이드는 위험하니 잘해라.
파일 시스템 레이아웃을 변경하지 않는 업그레이드
- HDFS와 맵 리듀스의 새버전 설치
- 환경 설정 수정
- 새 데몬 구동
- 사용자가 새로운 라이브러리를 사용
- 클러스터에서 오래된 설치 및 설정 파일 삭제
- 코드와 설정에서 발생하는 디프리케이션 경고 수정
파일 시스템 레이아웃을 변경하는 경우
- 최종 승인 하기전에 롤백할 수 있다. 승인후에는 롤백 할 수 없다. 하드링크를 이용해 롤백 가능하게 한다.
- VERSION 파일의 layoutVErsion=-n
- 먼저 진행한 업그레이드가 모두 완료 되었는지를 확인하고 나서 다른 업그레이드 진행
- 맵 리듀스 종료, 대스크트캐러의 좀비 프로세스나, 스레드 종료
- HDFS 종료. 네이몬드 디렉토리 백업.
- 클러스터와 클라이언트들에 새 하둡 HDFS와 맵 리듀스 버전 설치
- -upgrade 옵션으로 HDFS 구동
- 끝날때까지 대기
- HDFS에서 새너티 체크
- 맵리듀스 시작
- 롤백 or 업그레이드 최종 확인
% $NEW_HADOOP_INSTALL/bin/haddop dfsadmin -finalizeUpgrade
% $NEW_HADOOP_INSTALL/bin/haddop dfsadmin -upgradeProgress status
There are no upgrades in progress.
참조

Data Engineer