9장 하둡 클러스터 설정
클러스터 명세
- 비싼 하드웨어 필요 없음. 비싼 컴퓨터로 하드웨어 갯수를 줄일 수 있지만, 하드웨어 하나가 전체 클러스터에 미치는 영향은 늘어난다. 마치 주식의 리스크를 분산하는 것 처럼 리스크를 줄인다.
- 데이타 노드에 RAID 사용할 필요 없다. 네임노드는 사용할만 하다.
- 작은 클러스터에서는 네임노드와 잡트래커를 물리적인 하나의 하드웨어에서 구동해도 상관없다.
- 네임노드가 분리되어야 하는 주 요인은 물리 메모리다. hdsf의 파일수가 늘어나면 메타데이타가 늘어나므로 네임노드, 더 나아가 보조 네임노드 까지 분리 되어야 한다.
- 웬만하면 64Bit OS. 32Bit JVM의 힙 최대는 일반적으로 3GB 가량이다.
- "얼마나 클러스터가 커질 것인가?", 미래를 잘 예측해서 클러스터 수를 산정해라.
2010년 중순에 야후에서 사용했던 하드웨어 스펙
2쿼드 코어 2.25GHz CPUs
16~24GB ECC RAM
1TB SATA HDD X 4
Gigabit Ethernet
네트워크 위상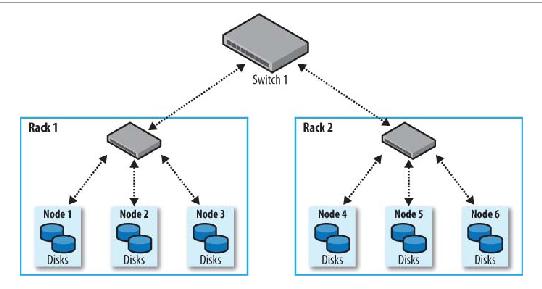
가능하면 같은 랙에 데이타를 access해야하고 복제본은 가능하면 다른 rack에 위치해야 한다.
따라서 그에따른 구성을 명시한다. 아래는 명시 할 수 있는 스크립트 예제.
참조 : http://wiki.apache.org/hadoop/topology_rack_awareness_scripts
topology.script.file.name 을 키로해서 core-site.xml 에 스크립트 이름을 기재
$HADOOP_HOME/src/core/core-default.xml
<!-- Rack Configuration --> <property> <name>topology.node.switch.mapping.impl</name> <value>org.apache.hadoop.net.ScriptBasedMapping</value> <description> The default implementation of the DNSToSwitchMapping. It invokes a script specified in topology.script.file.name to resolve node names. If the value for topology.script.file.name is not set, the default value of DEFAULT_RACK is returned for all node names. </description> </property> <property> <name>topology.script.file.name</name> <value></value> <description> The script name that should be invoked to resolve DNS names to NetworkTopology names. Example: the script would take host.foo.bar as an argument, and return /rack1 as the output. </description> </property>
Use ful
다보진 못했지만 이 자료 괜찮음! http://bradhedlund.com/2011/09/10/understanding-hadoop-clusters-and-the-network/
클러스터 설정 및 설치
- 하둡 전용 사용자를 생성해서 설치하는 것은 좋은 습관이다.
- 여러곳에 설치 해야 하므로 머리 잘 써서 설치하자. 자동으로 설치될 수 있는 부분이 많으니 잘 찾아보고 시간을 절약 하자.
SSH설정
- 하둡 제어 스크립트는 ssh를 사용하기 때문에 ssh 공개/개인 키를 사용하면 편하다.
하둡 환경 설정
주요 설정 파일
| 파일명 | 형식 | 설명 |
|---|---|---|
| hadoop-env.sh | bash | 하둡 환경변수 |
| core-site.xml | xml | hdfs, mapred 공통 설정 |
| hdfs-site.xml | xml | hsfs 설정 |
| mapred-site.xml | xml | mapred 설정 |
| masters | plain/text | 보조 네임노드 구동 컴퓨터 목록 |
| slaves | plain/text | 데이터노드, 태스크 트래커 구동 목록 |
| hadoop-metric.properties | java properties | 매트릭스 제어 |
| log4j.properties | java properties | 로그 설정 |
데몬은 --config 옵션으로 설정 디렉토리 변경 가능
설정 파일 관리
하둡은 모든 마스터와 워커가 같은 설정 파일 셋트를 사용 할 수 있도록 설계되어졌다.
하지만 하드웨어 스펙들이 다르거나 하는 이유등으로 여러개의 설정 파일 셋트를 다뤄야 하는 경우도 있다. 이럴땐 puppet, cfengine, bcfg2 같은 훌륭한 도구들이 존재하는 잘 활용하자.
하지만 굳이 같은 파일 셋트를 이용한다해도 이런 툴을 사용하는 잇점은 충분히 있다.
제어 스크립트
- start-dfs.sh
- 로컬 컴퓨터 상에서 네임노드 실행
- slaves 파일에 열거된 각 컴퓨터 상에서 데이터 노드를 실행
- masters 파일에 열거된 각 컴퓨터 상에서 보조 네임노드를 실행
- start-mapred.sh
- 로컬 컴퓨터 상에 잡트캐러 실행
- slaves 파일에 열거된 각 컴퓨터에서 태스크 트래커 실행
- 다른 스크립트들도 있다!
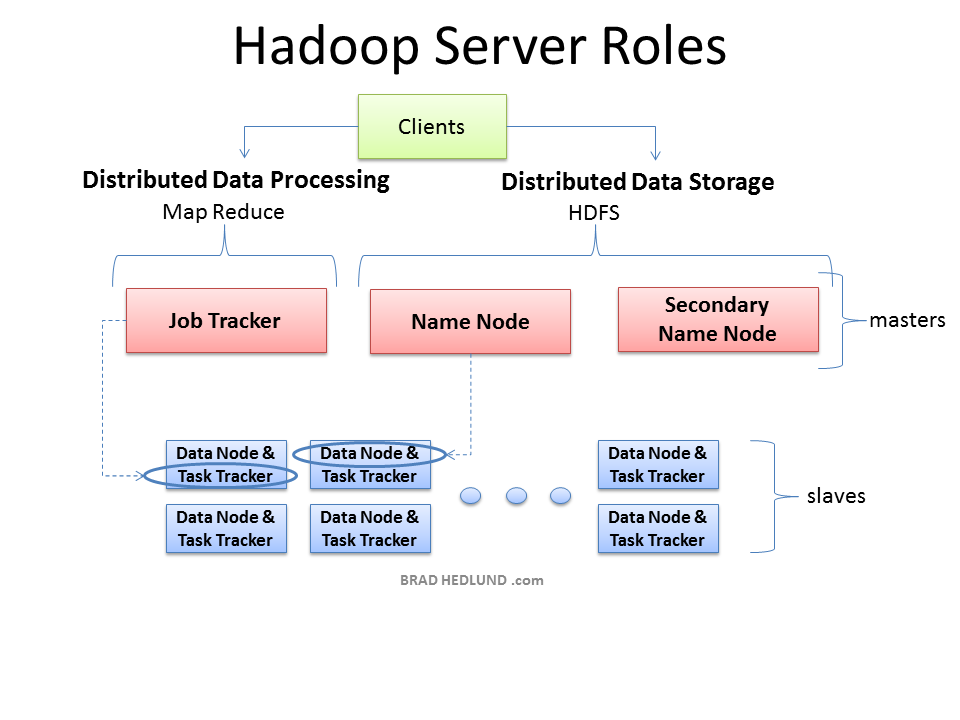
마스터노드 시나리오
마스터 데몬(네임노드, 보조 네임노드, 잡트래커) 작은 클러스터면 하나의 컴퓨터에서 실행되지만 대규모 클러스터로 가려면 모두 따로 작동
마스터 데몬이 하나 이상의 컴퓨터에서 동작할 경우 다음 유의
- 네임노드 서버에서 hdfs 제어 스크립트를 실행하라. 마스터 파일은 보조 네임노드의 주소를 포함해야 한다.
- 맵리듀스 제어 스크립트들은 잡트래커 서버에서 실행하라. 네임노드와 잡트래커가 다른 컴퓨터에서 구동될때, 이둘의 slaves 파일은 동기화 되어야 한다. 클러스터 내의 이 두서버에서 각각 데이터 노드와 태스크트래커를 구동할 수 있어야 하기 때문이다.
개발 환경 설정
- 데몬 힙 사이즈 hadoop-env.sh 의 HADOOP_HEAPSIZE 값에의해 제어, 기본 값은 1,000MB
- 태스크 트래커는 자식 프로세서를 생성해서 jvm을 실행 시킨다. 이것도 고려해서 heap 크기를 조절 해야 한다.
- mapred.tasktacker.map.tasks.maximum기본은 2개
- mapred.tasktacker.reduce.tasks.maximum도 2개
- 자식 jvm은 mapred.child.java.opts 를 통해서 변경 가능 기본은 -Xmx200m, 이곳에 기타 jvm 옵션을 줄 수 있다.
- 해당 머신에서 실행되는 기타 프로세스들을 고려해서 잘 설정하자. 스왑아웃은 피하자.
- 마스터 데몬(네임노드, 보조노드, 잡트래커) 기본 총 3GB를 사용한다.
- log4j 설정 파일로 로그가 관리된다.
- 로그 저장 위치는 hadoop-env.sh 의 HADOOP_LOG_DIR로 설정 할 수 있다.
- HADOOP_SSH_OPTS 환경 변수를 이용해서 ssh 옵션들을 이용할 수 있다.
중요한 하둡 데몬 속성
- comma seperate로 구분, 책에는 따옴표로? 샘플은 콤마로..
- dfs.name.dir 네임노드의 메타데이타가 저장된다. nfs로 마운트된 디렉토리를 포함시켜 네임노드 전체가 장애라도 복구 할 수 있도록 한다. 지정한 디렉토리에는 복사본들이 저장된다.
- fs.checkpoint.dir 보조 네임노드에 체크포인트된 파일 시스템 이미지가 저장 된다. dfs.name.dir 처럼 여러 복사본들이 각 디렉토리마다 저장된다.
- dfs.data.dir 데이타노드 디렉토리는 각 물리 디스크마다 지정해 주는 것이 좋다. 복사본들이 저장 되지 않는다. 각 물리 디스크에서 동시에 읽을 수 있다. 쓰기는 라운드 로빈방식으로 저장한다.
- 맵 리듀스중에 임시 파일들이 생성되므로 충분한 공간 확보. mapred.local.dir 여러개의 디렉토리 지정해서 부하 분산.
- mapred.system.dir 맵리듀스 프로그램이 공유될 수 있도록 보통 hdfs 사용
- cpu 코어에 맞게 mapred.tasktracker.map.tasks.mximum, mapred.tasktracker.reduce.tasks.mximum 설정
하둡 데몬 주소와 포트
- 네트워크 상황에 맞게 잘 설정
다른 하둡 속성
- 버퍼가 보수적인 수치로 4KB설정되어 있다. core-site.xml 의 io.file.buffer.size 속성으로 튜닝 하자.
- 데이터 노드나 태스크 트래커로 클러스터에 참여하거나 참여하지 않게 지정 할 수 있다. dfs.hosts, mapred.hosts, dfs.hosts,exclude, mapred.hosts.exclude에 해당 호스트들이 기재된 파일을 지정한다.
- hdfs-site.xml 의 dfs.blick.size 속성으로 hdfs를 설정한다. 크기가 증가하면 네임노드의 메모리 부담이 줄어 든다. 기본은 64MB
- dfs.datanode.du.reserved 속성을 bytes 단위로 지정해서 데이터 노드가 모든 하드디스크를 사용하는것을 방지 할 수 있다.
- 휴지통 기능있다. 보관기간은 core-site.xml 의 fs.trash.interval
- 잘못된 맵리듀스 프로그램의 메모리 누수를 걱정한다면, mapred.child.ulimit 속성으로 태스크트래커의 자식들의 메모리 제한을 한다. Kbytes단위이고 mapred.child.java.opts 속성에서 지정한 메모리 크기보다 커야한다. 아니면 os의 limit 기능을 이용한다. ulimit.
사용자 계정 생성
- 하둡 사용자 별로 하둡파일시스템상에 사용자별 홈디렉토리, 권한, 사용 크기를 제한해 준다.
보안
커버로스와 하둡
하둡파일시스템이나 맵/리듀스에 보안이 필요하다면 커버로스 인증을 고려하라.
커버로스 서버 셋팅은?
$HADOOP_HOME/conf/core-site.xml
<property> <name>hadoop.security.authentication</name> <value>kerberos</value> <!-- A value of "simple" would disable security. --> </property> <property> <name>hadoop.security.authorization</name> <value>true</value> </property>
참고
https://ccp.cloudera.com/display/CDHDOC/Configuring+Hadoop+Security+in+CDH3
hadoop-policy.xml 에서 권한 편집
위임 토큰들
- 커버로스 키 분배 센터(KDC)에서 인증받은 후 네임노드가 위임 토큰을 발급해서 이후 KDC에 접근하지 않고 접근 가능.
- dfs.block.access.token.enable 를 true로 활성시키면 heartbeat 메세지속에 인증검증에 필요한 비밀키를 실어서 보낸다. 네임노드는 비밀키를 데이타 노드와 공유하며 클라이언트는 네임노드에게 발급 받은 토큰으로 데이타 노드에게 인증 받는다. 맵리듀스 잡이 실행되면 이 위임 토큰은 잡트래커와 태스크트래커가 사용한다. 잡이 끝나면 위임 토큰을 무효화 된다.
다른 보안 강화 사항
- 책 참조.
- 하둡 공식 사이트에서 계속 확인
하둡 클러스터 벤치마킹
테스트와 예제 프로그램이 같이 배포된다. 이를 이용해 클러스터를 튜닝한다. 클러스터를 증설할때도 이를 이용해 성능을 비교 할 수 있다.
하둡 클라우드
- whirr 프로젝트는 크라우드 서비스를 위해 사용 될 수 있는 라이브러리들을 제공한다.(아마존 EC2, 랙스페이스 크라우드서버) cassandra, hadoop, zookeeper, hbas, elasticsearch, voldemorot, hama
- 2007년 시작, 2011년 8월 인큐베이터에서 아파치 탑레벨 프로젝트로 승격됨
참조
