1. BeautifulSoup4 기본
- HTML과 XML 문서들의 구문을 분석하기 위한 파이썬 패키지
- 정적 HTML로부터 파싱된 페이지의 파스 트리를 만듦 (웹 스크래핑에 사용됨)
- 정적 HTML 파일만 불러오기 때문에 동적 콘텐츠에 사용할 수 없음
설치 및 주의사항
pip install beautifulsoup4
pip install lxml
※ lxml : 어떤 구문을 분석하는 파서
- 예제에서 사용하는 tag명들은 크롬 브라우저에서 f12(관리자 도구)를 통해서 확인한 것임
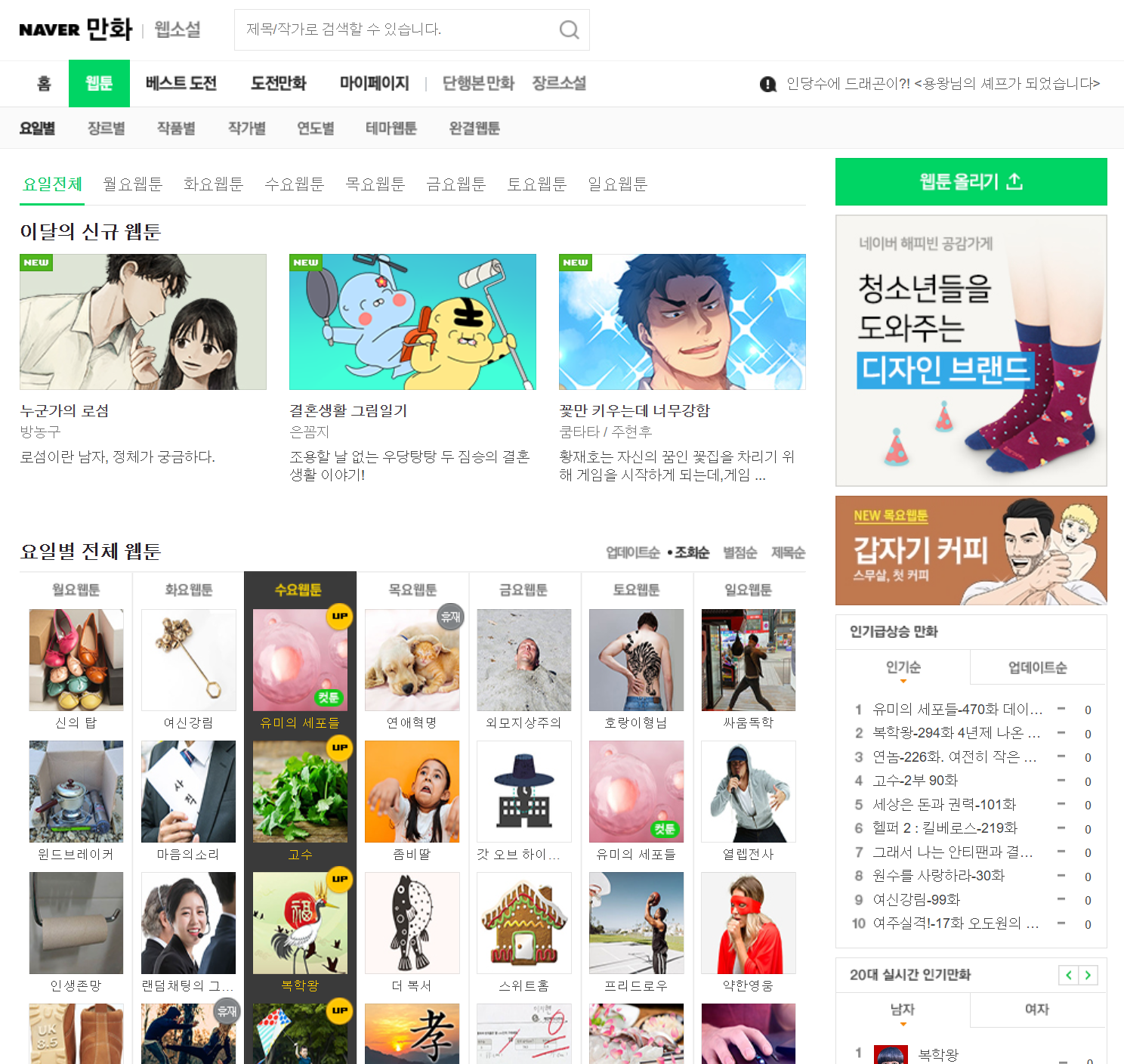
예제 (네이버 웹툰 I)
현재 네이버 웹툰은 JS 기반의 동적 사이트이기 때문에 웹 아카이빙을 이용하여 과거 버전의 네이버 웹툰으로 실습을 진행함
https://web.archive.org/web/20200401052025/https://comic.naver.com/webtoon/weekday.nhn
import requests
from bs4 import BeautifulSoup
url = "https://web.archive.org/web/20200401052025/https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
print(soup.title)
print(soup.title.get_text())
print(soup.a)
print(soup.a.attrs)
print(soup.a["href"])
rank3 = soup.find("li", attrs={"class": "rank03"})
print(rank3.a.get_text())
#rank4 = rank3.next_sibling.next_sibling
rank4 = rank3.find_next_sibling("li")
print(rank4.a.get_text())
#rank2 = rank3.previous_sibling.previous_sibling
rank2 = rank3.find_previous_sibling("li")
print(rank2.a.get_text())
print(rank3.find_next_siblings("li"))
print(soup.find("a", text="연놈-226화. 여전히 작은 아이 (희망)"))
print(rank3.parent)- BeautifulSoup(텍스트, 파셔) : BeautifulSoup 객체를 생성
- 객체.element : 객체에서 처음으로 발견되는 element를 가지고 옴
- 객체.element.get_text() : element에서 텍스트만 추출 함
- 객체.element.attrs : element의 속성 정보를 반환함
- 객체.element[속성] : element의 특정 속성 값만 추출함
- 객체.find(element, attrs={"tag" : "값"}) : 특정 tag의 값을 가진 element를 찾음
- find_next_sibling(tag) : 다음 형제 태그를 찾음 (= next_sibling.next_sibling)
- fine_previous_sibling(tag) : 이전 형제 태그를 찾음 (= previous_sibling.previous_sibling)
- parent : 부모 태그로 이동함
2. BeautifulSoup4 활용 I
예제 (네이버 웹툰 II)
1. 당시 네이버 웹툰에서 연재하던 전체 웹툰 이름을 가져오기
import requests
from bs4 import BeautifulSoup
url = "https://web.archive.org/web/20200401052025/https://comic.naver.com/webtoon/weekday.nhn"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
cartoons = soup.find_all("a", attrs={"class":"title"})
for cartoon in cartoons:
print(cartoon.get_text())▶ class 속성이 title인 모든 "a" element들을 찾는 방식(find_all(element, attrs={"tag" : "값"}))으로 가져옴

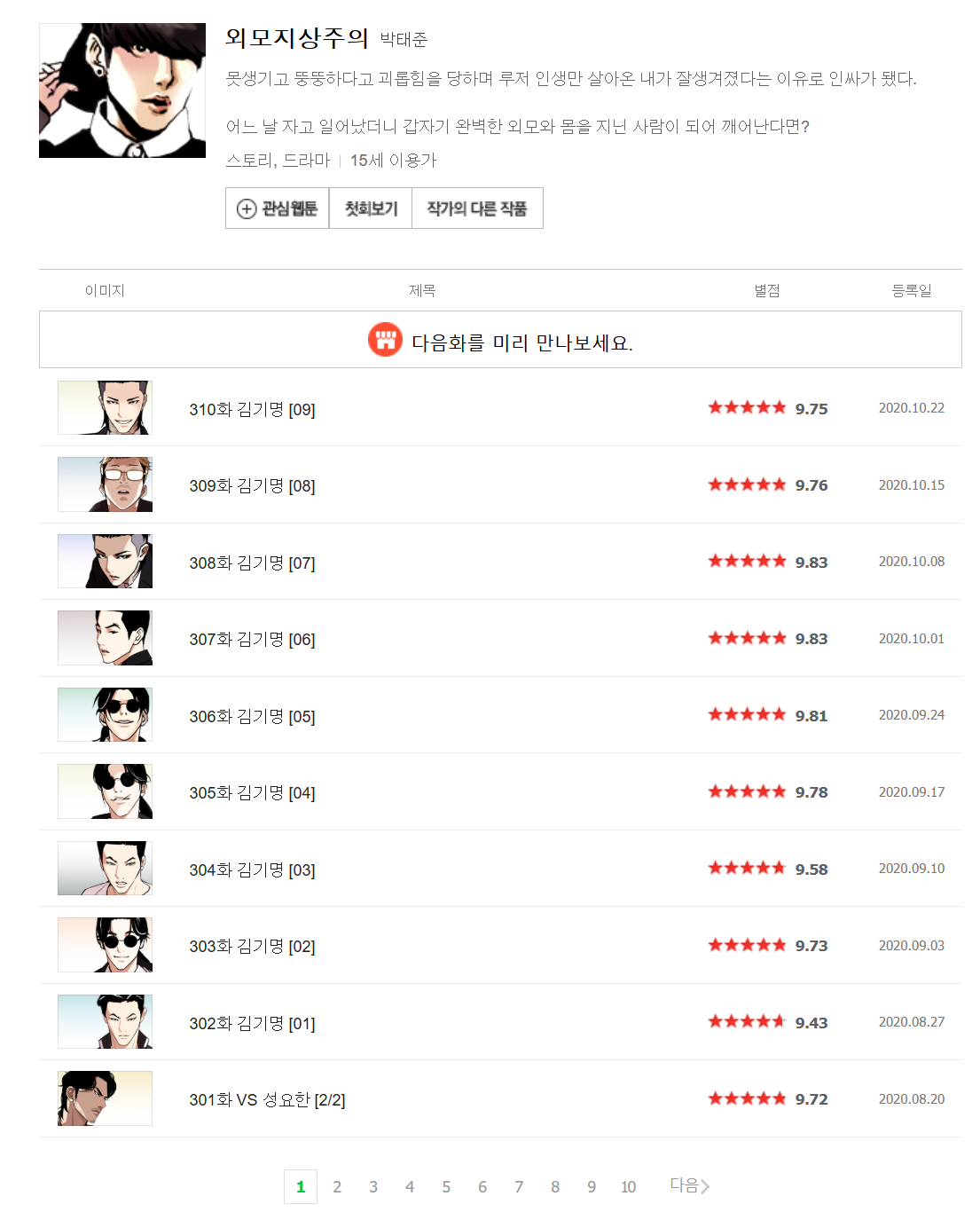
2. 웹툰의 해당 페이지에 있는 모든 화 제목과 링크를 가져오기
참고 : 2025.02.04일 기준 무료회차에 해당 되는 부분임
import requests
from bs4 import BeautifulSoup
url = "https://web.archive.org/web/20201028205420/https://comic.naver.com/webtoon/list.nhn?titleId=641253&weekday=fri"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
cartoons = soup.find_all("td", attrs={"class":"title"})
for cartoon in cartoons:
title = cartoon.a.get_text()
link = (cartoon.a["href"])[20:]
print(title, link)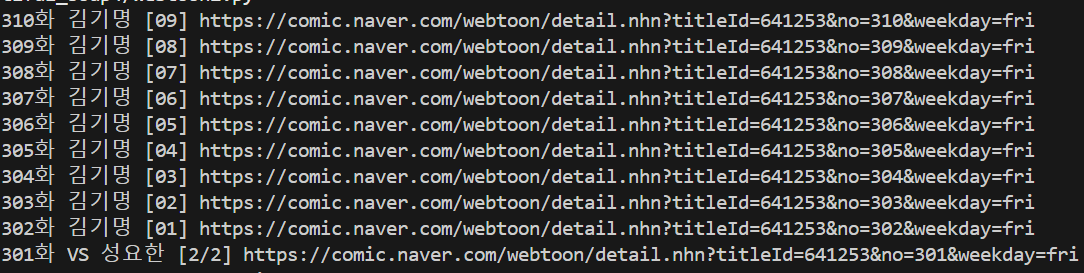
3. 웹툰의 해당 페이지에 있는 모든 화 평점의 평균 구하기
import requests
from bs4 import BeautifulSoup
url = "https://web.archive.org/web/20201028205420/https://comic.naver.com/webtoon/list.nhn?titleId=641253&weekday=fri"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
cartoons = soup.find_all("div", attrs={"class" : "rating_type"})
sum, cnt = 0, 0
for cartoon in cartoons:
rate = float(cartoon.strong.get_text())
sum+=rate
cnt+=1
print(f"평균 평점 : {sum/cnt}")
3. CSV 기본
- CSV : 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
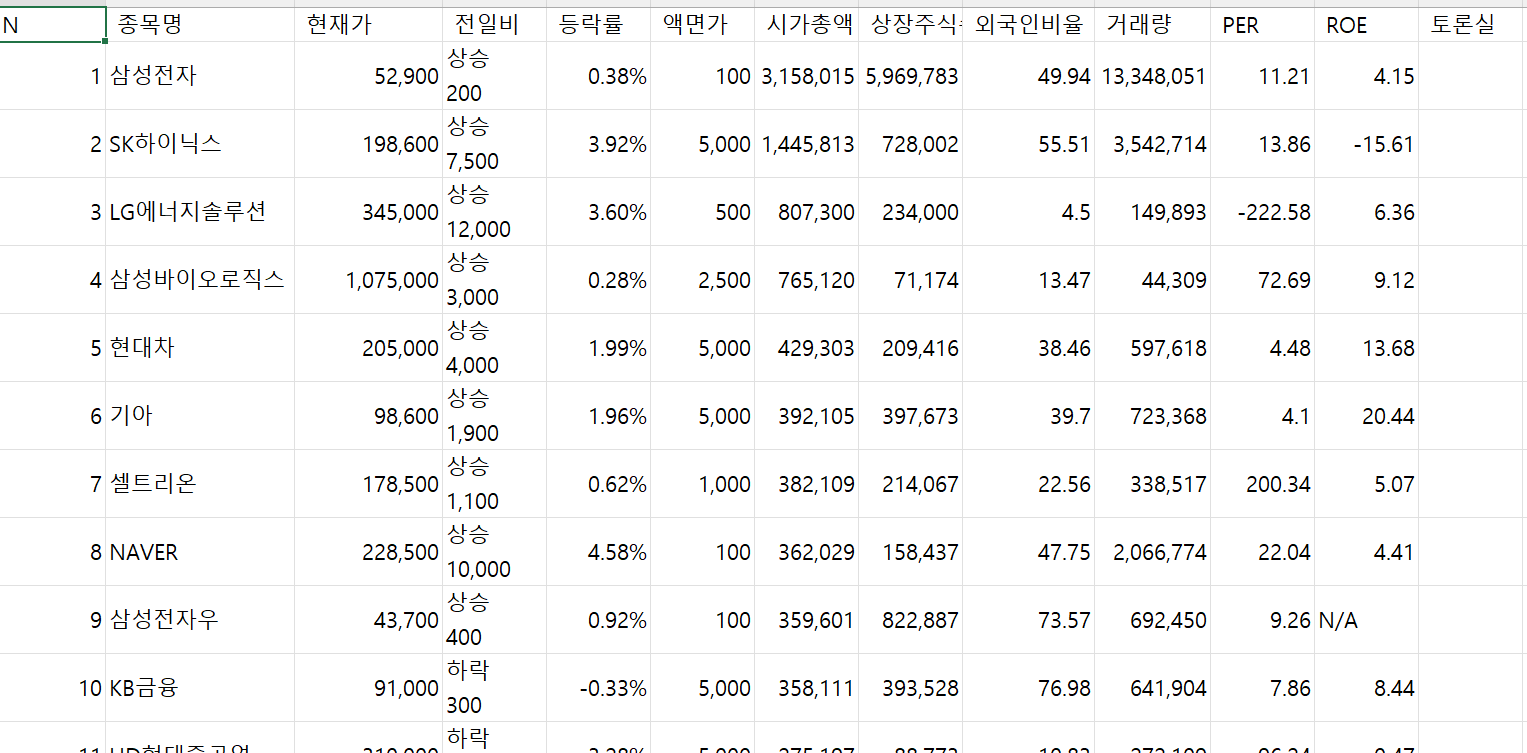
예제 (N Pay 증권)
사용
import csv
- csv.writer(파일명) : 작성을 할 csv 파일을 지정
- writerow(내용) : 특정 내용을 csv 파일에 행으로 작성함
1. 시가총액 1위에서 200위까지를 CSV 파일로 만드시오
import csv
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/sise/sise_market_sum.nhn?sosok=0&page="
filename = "시가총액_1~200.csv"
f = open(filename, "w", encoding="utf-8-sig", newline="")
writer = csv.writer(f)
title = "N, 종목명, 현재가, 전일비, 등락률, 액면가, 시가총액, 상장주식수, 외국인비율, 거래량, PER, ROE, 토론실".split(',')
writer.writerow(title)
for page in range(1, 5):
res = requests.get(url + str(page))
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
date_rows = soup.find("table", attrs={"class":"type_2"}).find("tbody").find_all("tr")
for row in date_rows:
columns = row.find_all("td")
if len(columns) <= 1:
continue
data = [column.get_text().strip() for column in columns]
writer.writerow(data)- 또한 의미 없는 부분을 제거하기 위해서 해당 되는 부분들의 길이가 1보다 작기 때문에 열 수가 1보다 작으면 csv파일에 작성하지 않도록 함
- 빈 문자열 등을 제거하기 위해서 strip()으로 문자열 공백 제거
- utf-8로 설정하면 한글이 깨져 표출이 될 수 있기 때문에 utf-8-sig로 설정함

코딩하는 찍찍이 🐀