막상 ai trcak 공부를 시작하면서 내가 느낀 것은 무엇보다도 기본이 중요하다는 것 이였다. Ai 백엔드 개발자가 되고 싶다면 js나 프론트 관련 지식은 당연하며 ai track 공부는 그다음이라는 것 이다. 오늘은 머신러닝과 딥러닝의 차이도 몰랐던 내가 처음 머신러닝을 공부를 시작하며 느끼고 배운 것들을 기록하려 한다. 무엇보다도 몇년뒤 이 글을 읽는내가. 지금을 떠올리며 아무리 지쳤어도 다시 일어나길 바라며 글을 시작해보겠다! 
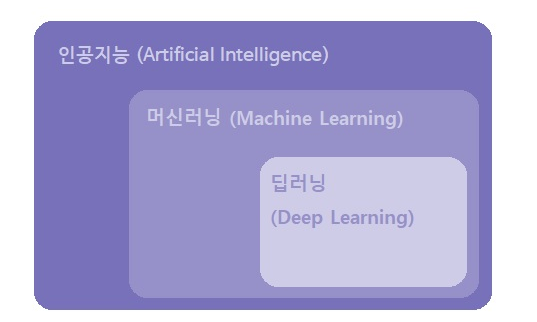
머신러닝과 딥러닝의 차이
정확히 말하자면, 딥러닝이 머신러닝에 포함된다. 머신러닝에는 없는 딥러닝의 특징은 무엇일까?
 출처 CODING WORLD NEWS
출처 CODING WORLD NEWS
머신러닝이란?
우선 머신러닝은 인공지능의 한 분야로, 누적된 경험을 통해 컴퓨터가 스스로 학습할 수 있게 하는 알고리즘이다. 처리해야 할 정보를 더 많이 학습하기 위해 많은 양의 데이터가 필요하다. 알고리즘을 이용해 데이터를 분석 및 학습하고, 학습한 내용을 기반으로 어떠한 결정을 판단하거나 예측한다. 머신러닝은 작업을 수행할 때마다 얻은 결과를 스스로 학습하여 향후 작업을 더 정확하게 수행한다.
딥러닝이란?
딥러닝은 머신러닝과 마찬가지로 인공지능의 하위 개념이며, 인공신경망에서 발전한 형태이다. 인공신경망(Artificial Neural Network)은 뇌의 뉴런과 유사한 정보 입출력 계층을 활용한 것으로, 블랙박스 형태로 데이터를 입력하면 자동으로 복잡한 수학식 모델링이 되는 기법이다. 딥러닝은 이러한 복잡한 인공신경망을 사용한 알고리즘을 통해 데이터를 학습한다.
둘의 차이점
머신러닝은 알고리즘이 부정확한 예측을 반환하면 엔지니어가 개입하여 조정해야 한다. 그러나 딥러닝은 알고리즘 자체 신경망을 통해 예측 정확성 여부를 스스로 판단한다. 또한, 딥러닝은 추상적인 정보를 인식하는 능력이 뛰어나기 때문에 머신러닝과 달리 개와 고양이를 식별할 수 있다. 머신러닝은 엔지니어가 미리 각 데이터가 개인지 고양이인지를 정의 내려야 하는 반면, 딥러닝은 개의 데이터와 개가 아닌 데이터들이 주어지면 자동으로 개인지 아닌지를 군집화하고 분류한다.
머신러닝에 대해 알아보자!
이렇게 읽고나면 추상적인 그림은 그려져도 완전히 머신러닝이 이러한 것이다! 라고 누군가 에게 설명하기는 어려울 것이다 그럼 기초적인 개념과 용어부터 정리해보면서 글쓴이가 이해한 FLOW를 따라가보자!
선형회귀
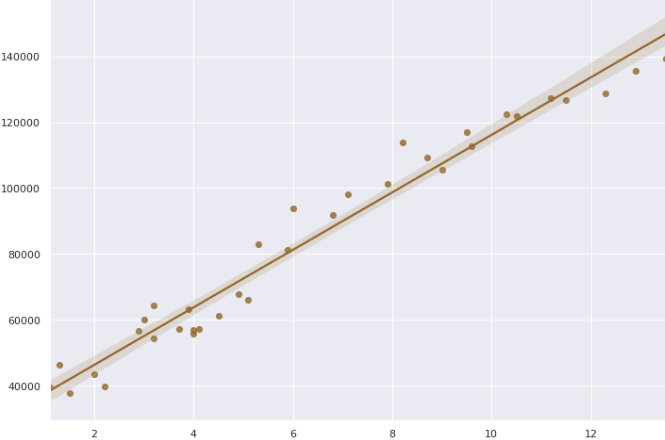
컴퓨터가 풀 수 있는 문제 중에 가장 간단한 것이 바로 두 데이터 간의 직선 관계를 찾아 내서 x값이 주어졌을 때 y값을 예측하는 것인데요! 이것을 선형회귀라고 한다!
우리가 중학교때 배웠던 함수를 생각해 보면 되는데, y = f(x) 즉 입력값과 출력값이 정의가되어야한다. 물론 그정의는 개발자가 정해주어야 한다. 우리가 분류와 회귀 방법중에 어떤 것을 적용할지는 전적으로 개발자의 선택이다.
출력값이 연속적인 문제 EX)나이,키,몸무게 등은 보통 회귀(regression) 으로 푼다
분류문제(Classification)은 비연속적인 출력값을 다룰때 유리하다 ex)A~F까지의 성적
물론 유리할 뿐이지 출력값이 연속적 이여도 출력값의 범위를 class화 시키면 분류문제로 풀듯이 유연한 사고는 개발자의 덕목이라 할 수 있다.
머신러닝에서 학습하는 방법
머신러닝의 학습방법에는 크게 3가지가 있다.
1.지도학습 Supervised Learning // Classfication&& Regression
2.비지도학습 Un Supervised Learning /정답값이 없는상황에서 너가알아서 학습해봐! 정확도는 지도학습이 높다.
3.강화학습 알파고를 생각해 보면 이해하기 쉽다.
조금더 자세히 알아보자!
지도학습 : 정답을 알려주면서 학습시키는방법
많은데이터가필요하다
데이터셋은 인풋값과 아웃풋값으로 나뉜다.
텍스트 데이터들이 필요하다.
라벨링이란? // 레이블링 어노테이션 정답을표시해주는 작업을 많이하게된다.
비지도 학습: 어노테이션이 없는경우, 정답을 알려주지않고 군집화(clustering)로 처리하게되는 과정이다. 정답값이 없을때 굉장히 효과적으로 나눌수 있는 방법이다.
비교적 입력값만 많은 데이터 자료형이다.
강화학습:위에서 예로 알파고를 언급 하였다. 강화학습이란 프로그램이 모든변수를 계산하면서 개발자가 정한 완벽에 가까워지는 길을 스스로 찾아가는 것이다. 프로그램은 더높은 보상을 받기위해 움직이게 되는데 게임을 예로들면 게임을 예로들면, 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임환경(Environment)에서 현재 상태(State)에서 높은점수(reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법이다. 단, 행동(Action)을 위한 행동목록은 사전에 정의가 되어야 한다.
선형회귀(Linear Regression)
상당히 중요한 개념이기에 조금더 깊숙히 들어가 보자!
선형회귀란 이세상에 모든 법칙은 거의다 선형적이다~ 라는 개념에서 시작된 logic이다
그래프내에서 직선을 그리는 것을 바로 선형 회귀라고 한다.
hypothesis = tf.matmul(X, W) + b
이번엔 실습을 통해 정리해보자!이미지에 주석을 열심히 달아두었다:)
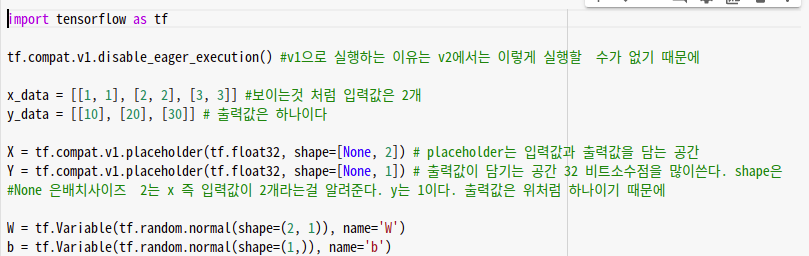
현재 TensorFlow도 Keras 사용을 권장하고 있지만. 선형회귀의 이해를 돕기위해 이처럼 작성한 것이다.


Kaggle에서 데이터를 다운로드 받은뒤 예측해보기!

임포트를 해온뒤
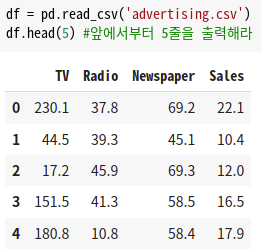
이렇게 데이터를 로드 하면된다.
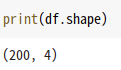
Tv,Radio,newspaper,Sales 위처럼 4개이기에 4가 출력되는 것을 볼수 있다.
이렇게 하고난뒤.
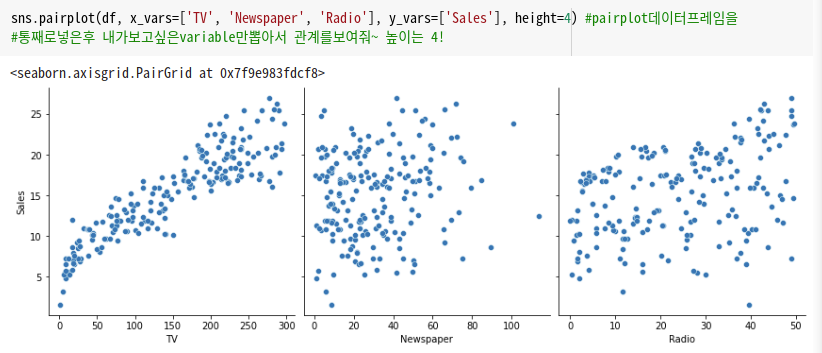
이렇게 점을 찍어준다.
Keras가 인식하기 편하도록 데이터셋을 가공해준다.
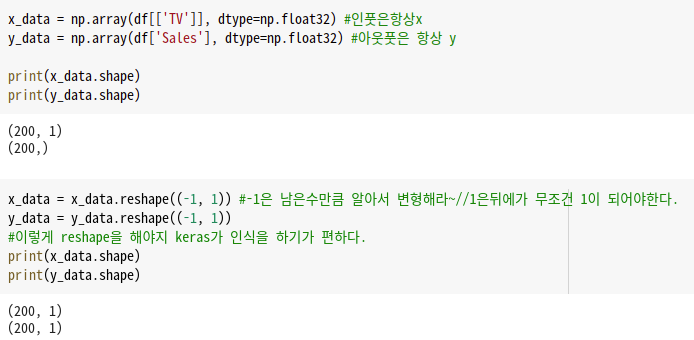
Reshape을 끝냈다면 데이터셋을 분할해 주어야 한다!
분할이 끝났다면 학습을 시키면 된다!

학습이 잘 되었는지 검증데이터로 예측할 일만 남았다!
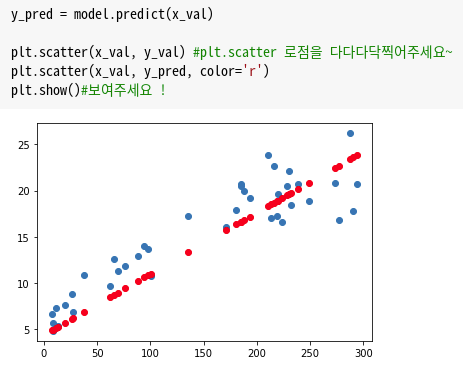
살짝만 보아도 빨간점이 파란점과 멀지않은 것으로 보아 나름 최선을 다해 학습하였구나! 우리가 가시적으로 확인할 수 있다!
글을 마치며
모르는게 부끄러운 것이 아니라, 알려하지 않는 것이 부끄러운 거라고 생각한다. 내리막길에 던져둔 작은 눈덩이처럼 나의 노력들이 내리막길이 끝나는 곳엔 분명 큰 눈뭉치가 되어 있을 거라 믿으니 오늘도 작은 눈덩이를 끊임 없이 굴려 보내고 싶다.


진짜 대단하세요!(최고)