ML
1.내생에 첫 머신러닝
막상 ai trcak 공부를 시작하면서 내가 느낀 것은 무엇보다도 기본이 중요하다는 것 이였다. Ai 백엔드 개발자가 되고 싶다면 js나 프론트 관련 지식은 당연하며 ai track 공부는 그다음이라는 것 이다. 오늘은 머신러닝과 딥러닝의 차이도 몰랐던 내가 처음 머신
2.Logistic regression & pre-processing

지난번에는 머신러닝에 대한 개념과 선형회귀에 대한 개념을 포스팅 해 보았다. 앞서 말 했듯이, 선형회귀란 이세상의 거의 모든문제를 선형으로 나타낼수 있다는 가정에서 시작했다고 했다. 하지만 선형적으로 표현하기에 어려움이 있는 사회현상 들을 표현하기 위해서는 새로운 함수
3.Deep learning

오늘은 Deep learning에 대해 글을 써볼 생각이다..!딥러닝의 역사와 신경망을 이해하고 만드는 데 필요한 각종 개념을 알아본 후 신경망을 직접 디자인 해보자! 기존의 머신러닝은 AND,OR문제로부터 파생되었다. 이런 문제는 직선 하나만 있으면 되서, 논리회
4.Fast Style Transfer
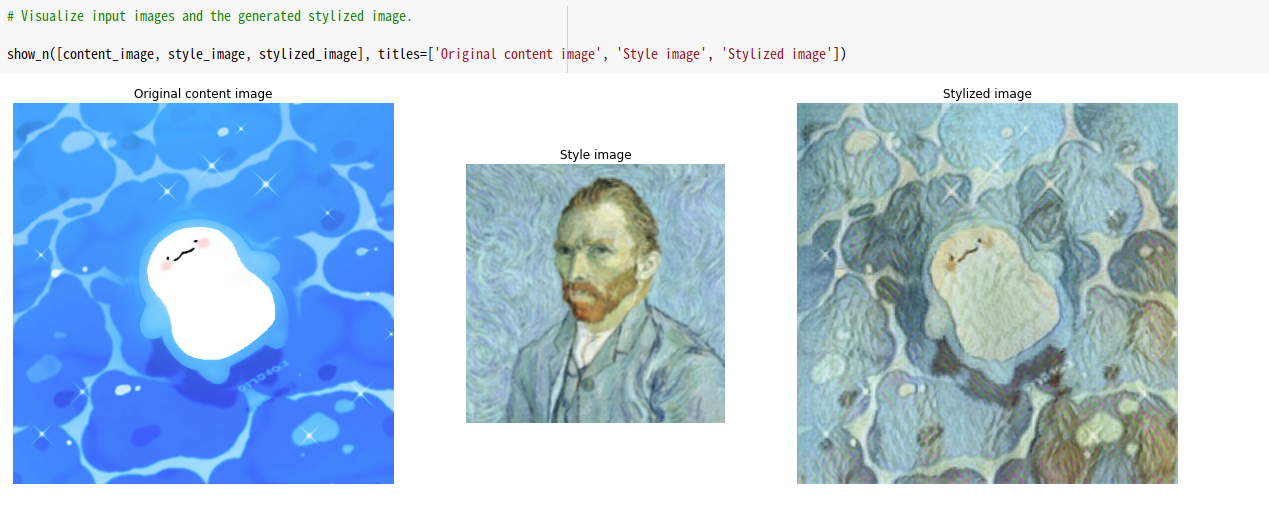
오늘은 코랩을 통해서 Style Transfer model을 직접 구성해보고 실습해 보려한다! 다소 어렵고 딱딱한 내용들이 많이 있지만 가볍게 다가가보도록 하자! 완성시 나오는 예 > ### 모든 실습은 import로 부터! 주석을 열심히 달아 두었긴 하지만 상세
5.규칙 기반(Rule - Based) 챗봇 만들어 보기!

지금 진행중인 프로젝트에서 간단한 기능을 하는 Rule - Based 챗봇이 하나 필요 했는데! 이를 직접 구현해 보는 과정을 정리해 보려 한다. 규칙 기반(Rule - Based)이란?규칙 기반 시스템은 자신의 할 일만 하도록 프로그래밍 된 시스템이다. 더 적은 노력
6.back to basics -Regressions

양치를 하며 문득 들었던 생각이 "나는정말 머신러닝의 기초적인 것들을 다 알고 있기에 모델을 갖고 놀아보는 것인가?"였다. 다소 자조적인 질문일 수 도 있지만, 그 무엇이 '기본'보다 중요할 수 있을까? 당연히 나의 대답은 '아니다'였다. 그렇기에 나는 나 스스로에게
7.back to basics - simple linear regression

이번 시간에는 단순 선형회귀에 대한 실습을 구현해볼 것이다! <span style='background-color: =np,plt,pd는 꿈에서도 import 해오는것 같다. <span style='background-color: =연차에 따른 연봉에대한 데
8.Everything about regression
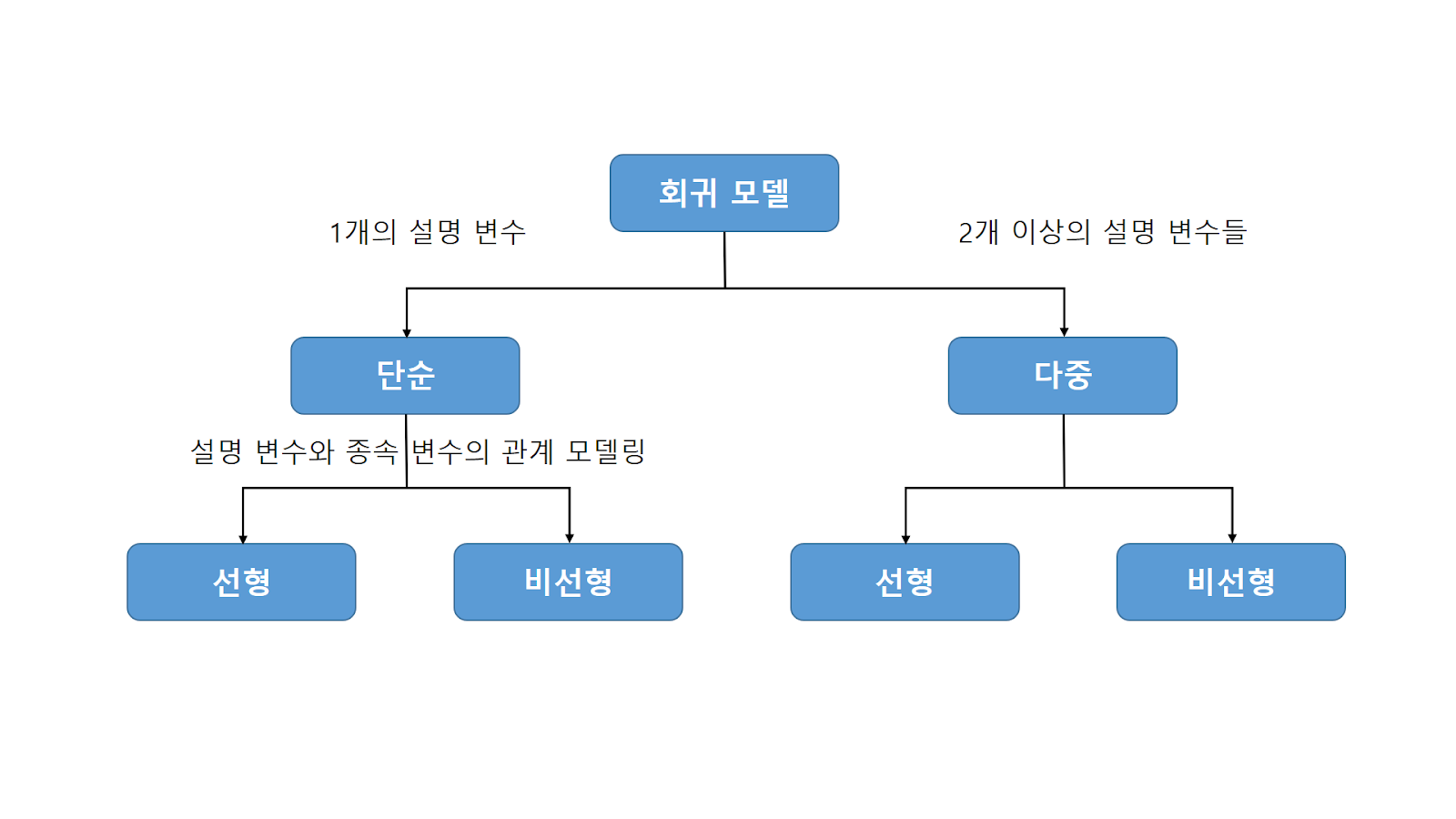
회귀란?회귀는 하나의 변수가 나머지 다른 변수들과의 선형적 관계를 갖는가의 여부를 분석하는 하나의 방법이다.즉 하나의 종속변수와 독립변수 사이의 관계를 명시하는 것을 우리는 회귀라고 한다. 회귀모델은 위의 사진과 같이 구분을 할 수 있다. 독립변수가 1개이면 단순회귀(
9.P-Value 와 통계적 유의성

<span style='background-color: =우선 통계적 유의성을 이해해 보도록 하자.<span style='background-color: -동전던지기로 생각을 해보도록 하자. 가능한 출력은 앞면,뒷면으로 예상할 수 있다. (입력이 동전을 던지
10.Everything about classification -1
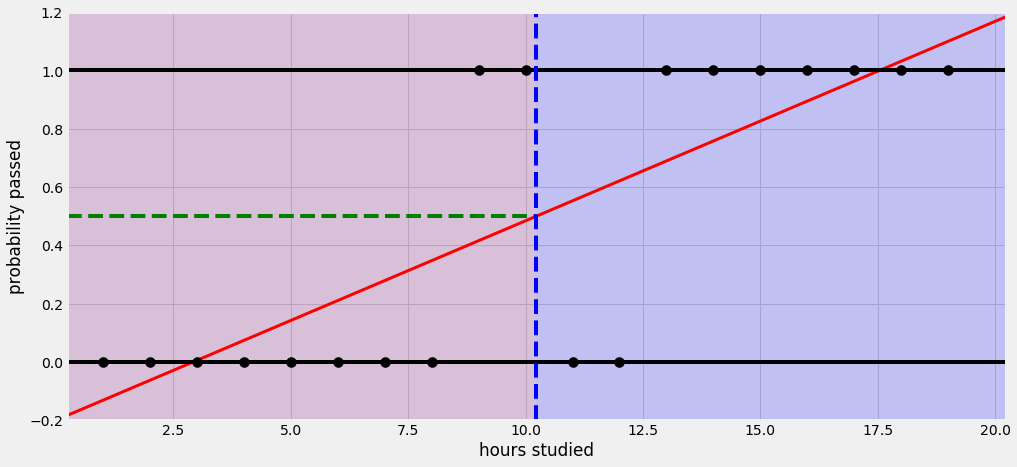
오늘 시간에는 classification에 대하여 포스팅을 할 생각이다. regression과 마찬가지로 너무나도 많이 이용되는 기법중 하나이며, 사실 regression과 classification은 서로 데이터라벨링차이에서 오는것이지 어떠한 문제에는 회귀로, 어떠한
11.Everything about classification -2
<span style='background-color: =XOR은 본질적으로 linear 하게 분류를 할 수가 없습니다. 한 때 MLP도 무너뜨리고 AI의 겨울을 가져온 무시무시한 녀석입니다. 하지만 1992년에 커널 트이 등장하게 됩니다. 커널 트릭이 바로 sv
12.유방암 분류 프로젝트

오늘은 유방암 분류 프로젝트를 해볼 생각이다. 우선 데이터셋에는 30개의 특징(feature)이 있고 해당 데이터가 악성인지==0,혹은 음성인지==1 이진 분류가 되어있는 상태이다. 기법으로느 SVM을 사용할 예정이다. SVM = 분류(classification),
13.패션 클래스 분류 프로젝트
<span style='background-color: =7만개의 이미지중 6만개의 학습 이미지와 1만개의 검증 데이터셋으로 구성되어있는 데이터셋을 이용하여 프로젝트를 진행할 것이다. 각이미지의 크기는 28x28이며 그레이 스케일이미지로 구성되어있다. 그리고 해당
14.Everything about Clustering
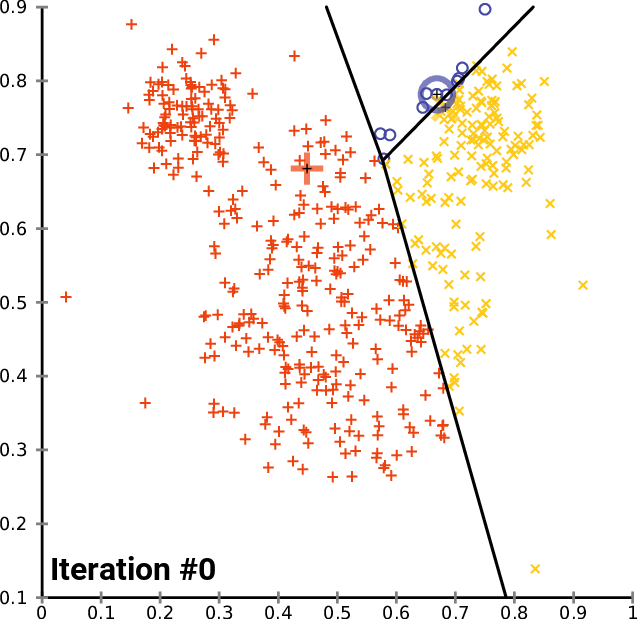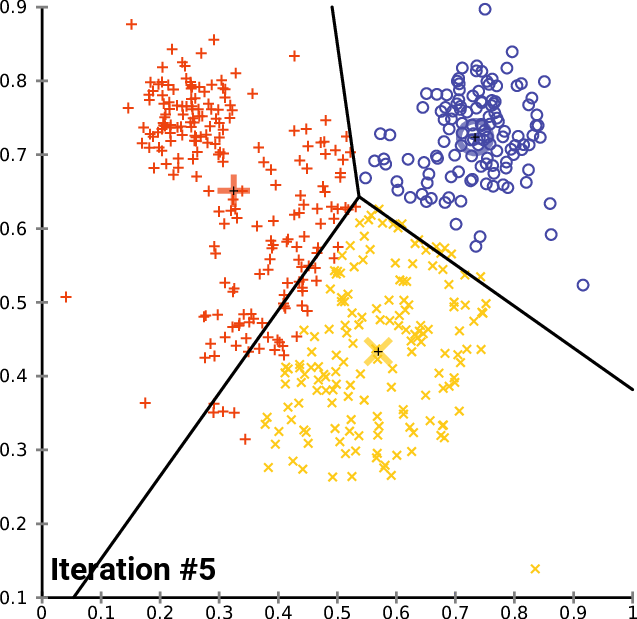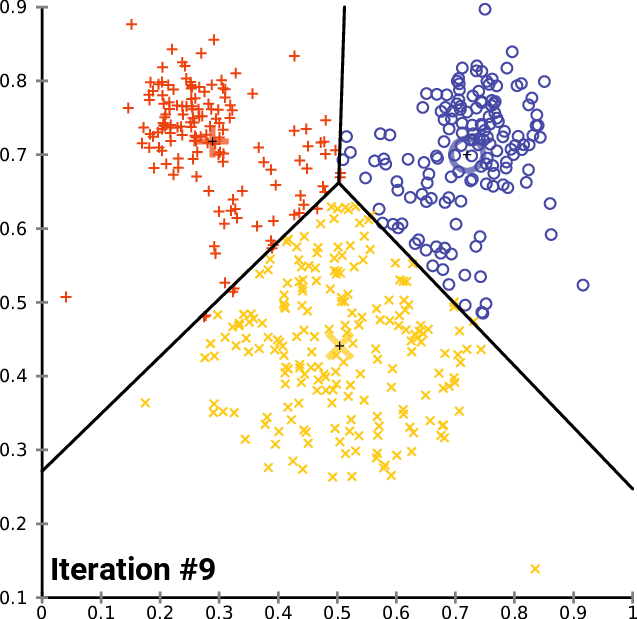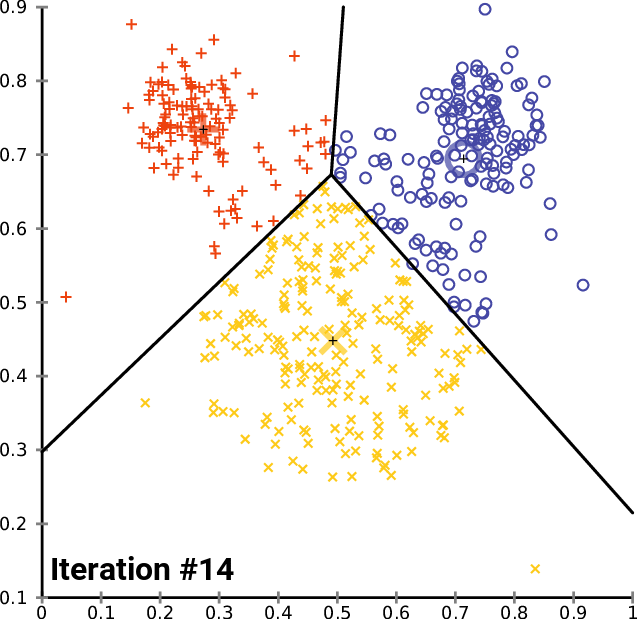
<span style='background-color: =유사한 속성들을 갖는 데이터를 일정한 수의 군집으로 그룹핑하는 비지도 학습입니다.지금까지 다루었던 머신러닝 모델(선형회귀, 다중선형회귀, 결정트리)는 특정 독립변수에 대한 종속변수(레이블, 정답)이 있는 경
15.Everything about Association Rule#1
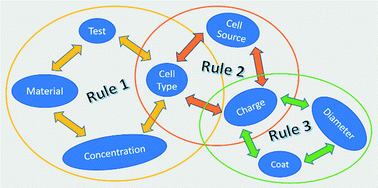
데이터 분석을 공부하는 사람이라면 누구나 한 번 쯤 들어보았을 예시가 있다. 바로, 마트에서 기저귀를 사 가는 사람들은 맥주를 같이 사간다는 예시이다. 이렇게 어떤 사건이 얼마나 자주 함께 발생하는지, 서로 얼마나 연관되어 있는지를 표시하는 것을 Association
16.Everything about Association Rule#2

연관규칙분석(Apriori 알고리즘) = 비지도 학습에 해당하는 연관규칙 분석에 Apriori 알고리즘을 소개 하도록 하겠다! 마케팅에서는 고객의 장바구니에 들어 있는 품목간의 관계를 알아본다는 의미에서 장바구니분석(market basket analysis)라고도
17.Everything about Reinforcement learning#1
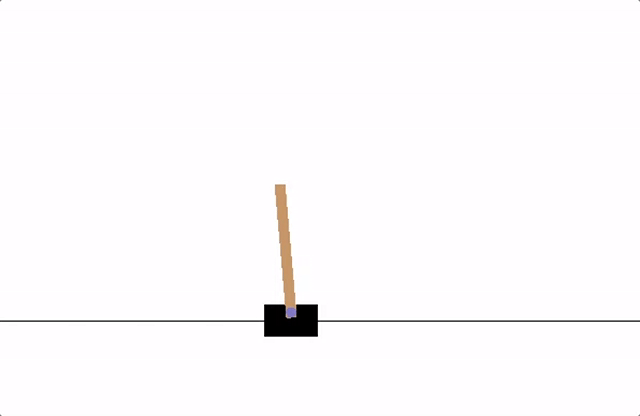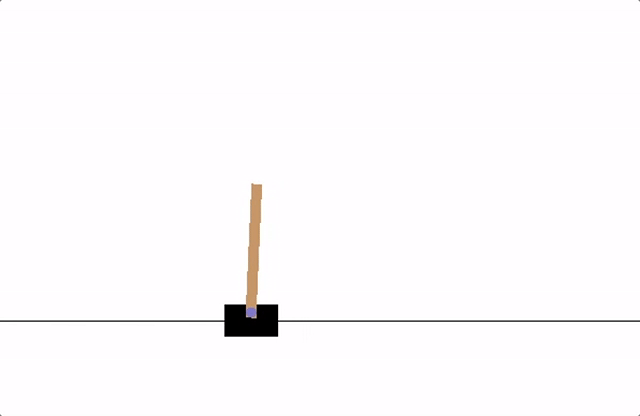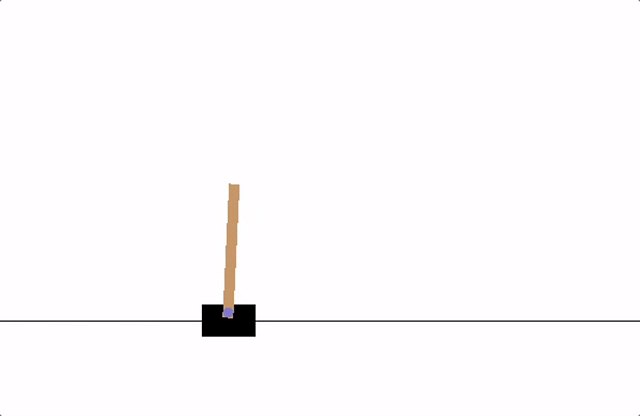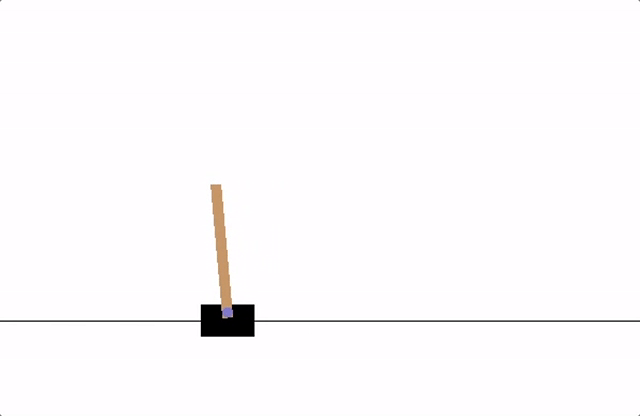
<span style='background-color: =강화학습은 컴퓨터 에이전트가 역동적인 환경에서 반복적인 시행착오 상호작용을 통해 작업 수행 방법을 학습하는 머신러닝 기법의 한 유형입니다. 이 학습 접근법을 통해 에이전트는 인간 개입 또는 작업 수행을 위한
18.Everything about PCA#1
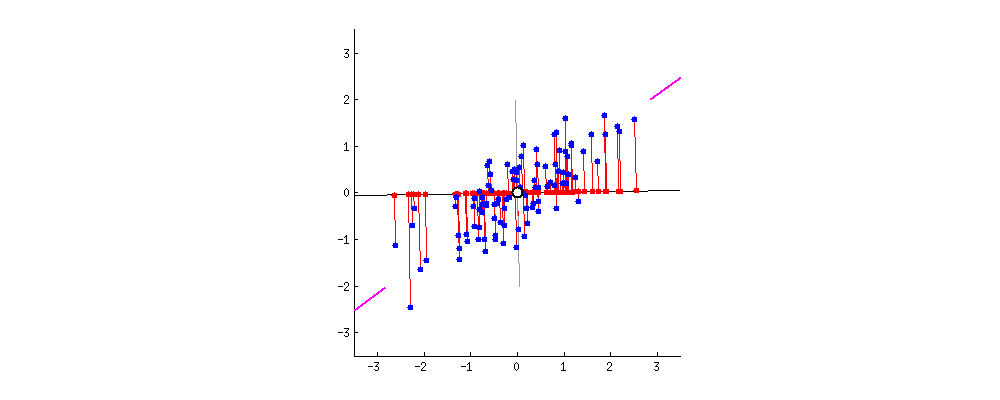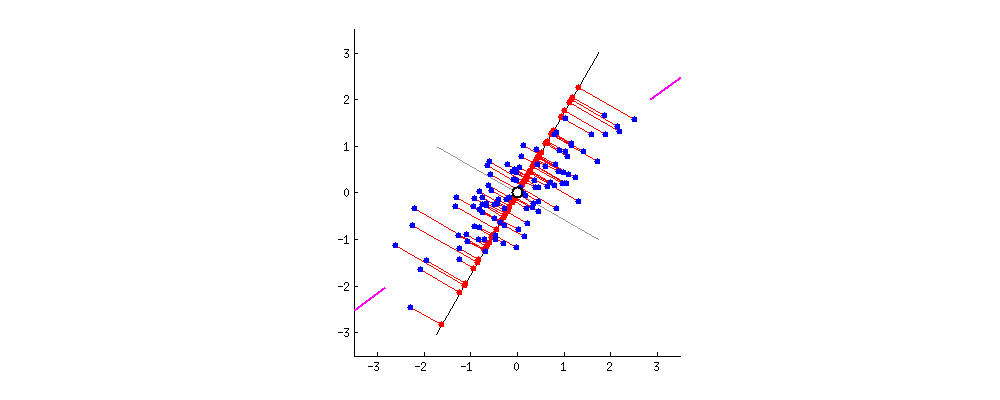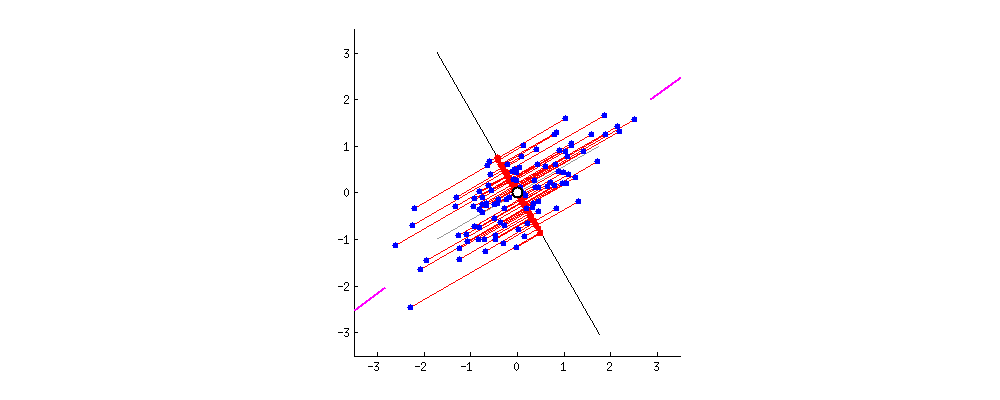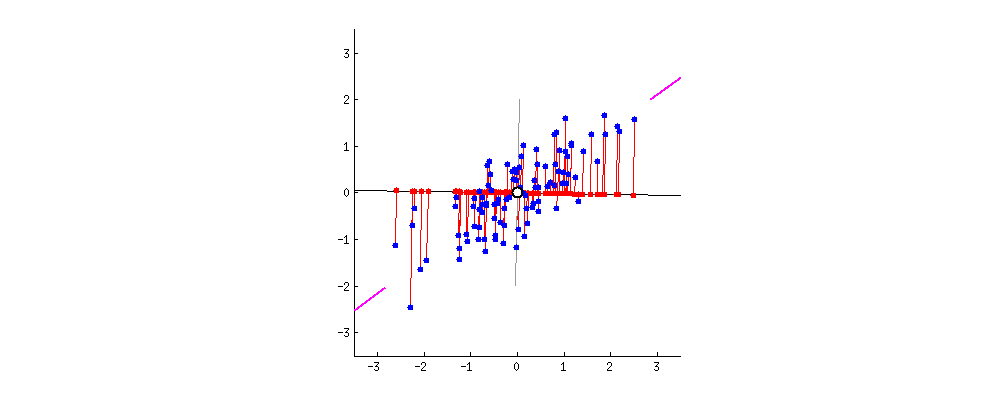
우리가 많은 사람의 방대한 특징을 기록한 데이터셋이 있다고 생각을 해보자! 이 데이터셋에는 그사람이 가장 좋아하는 음식, 싫어하는 동물 등등 너무나도 다양한 feature가 있다. 하지만 우리는 이 데이터 셋으로 자원봉사에 지원할 가능성을 예측하는 모델을 만든다고 생각
19.Everything about PCA#2
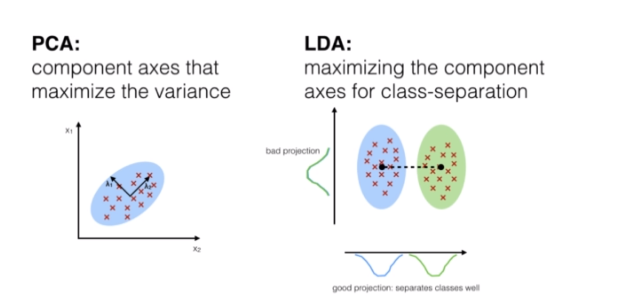
지난시간에 이어서 모델의 성능향상을 위한 '차원축소'에 관하여 다루고있는데, 오늘은 LDA에 대하여 포스팅해보려 한다. 이둘의 차이점, 공통점을 알아보며 쉽게 이해해보도록 하자!<span style='background-color: =<span style='
20.Everything about PCA#3
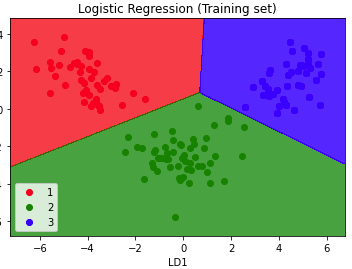
오늘은 지난시간에 이어 LDA실습을 colab환경에서 진행해 보려 한다. Importing the librariesImporting the datasetSplitting the dataset into the Training set and Test setFeature S
21.Everything about PCA#4
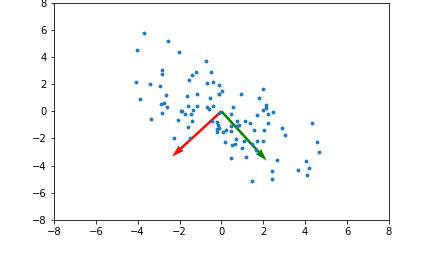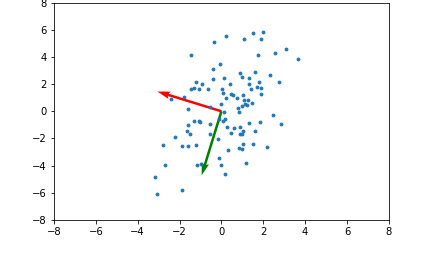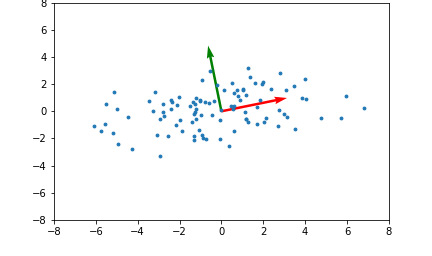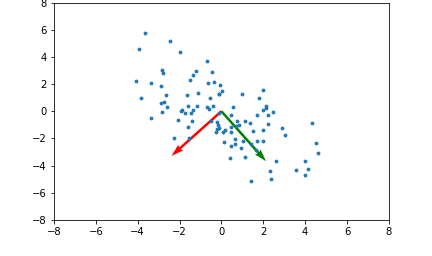
<span style='background-color: =PCA, SVM 등에서 사용되는 커널(kernel) 기법은 비선형 함수인 커널함수를 이용하여 비선형 데이터를 고차원 공간으로 매핑하는 기술입니다.아래 좌측의 데이터 분포를 보면 어떠한 방향으로의 선형변환으로
22.Everything about PCA#5
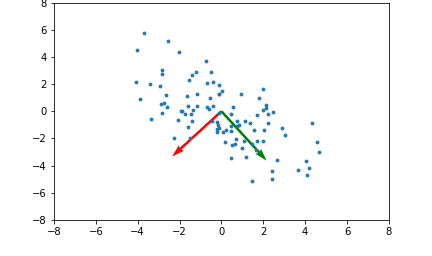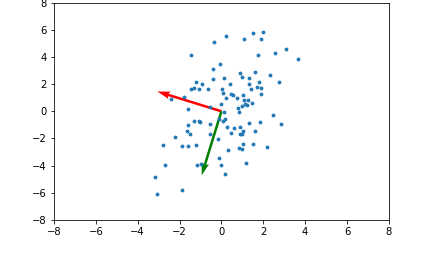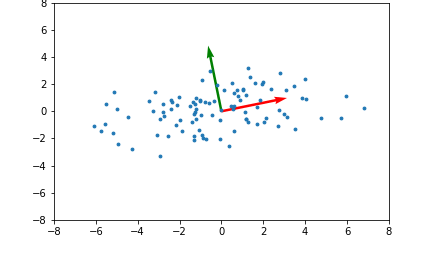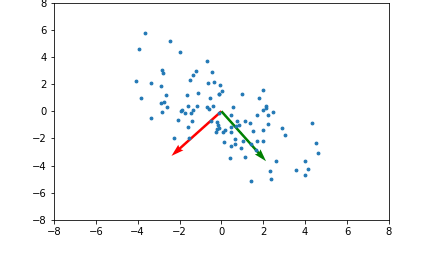
Importing the librariesImporting the datasetSplitting the dataset into the Training set and Test setFeature ScalingApplying Kernel PCATraining the Log