목차
Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
2. Express
3. 실습: Express 프레임워크
B. 2교시
1. 필수 폴더 구조 / 파일 ★
2. app.js
C. 3교시
1. app.js (cont.)
Ⅱ. 오후 수업
A. 4교시
1. RAG: 웹 페이지 검색
2. RAG: 이미지 검색
3.
B. 5교시
1. RAG: 이미지 검색 (cont.)
C. 6교시
1. RAG: 이미지 검색 (cont.)
Ⅲ. CAREER UP
데이터베이스 특강
Ⅳ. 하루 돌아보기Ⅰ. 오전 수업
A. 1교시
1. 지난 시간 복습
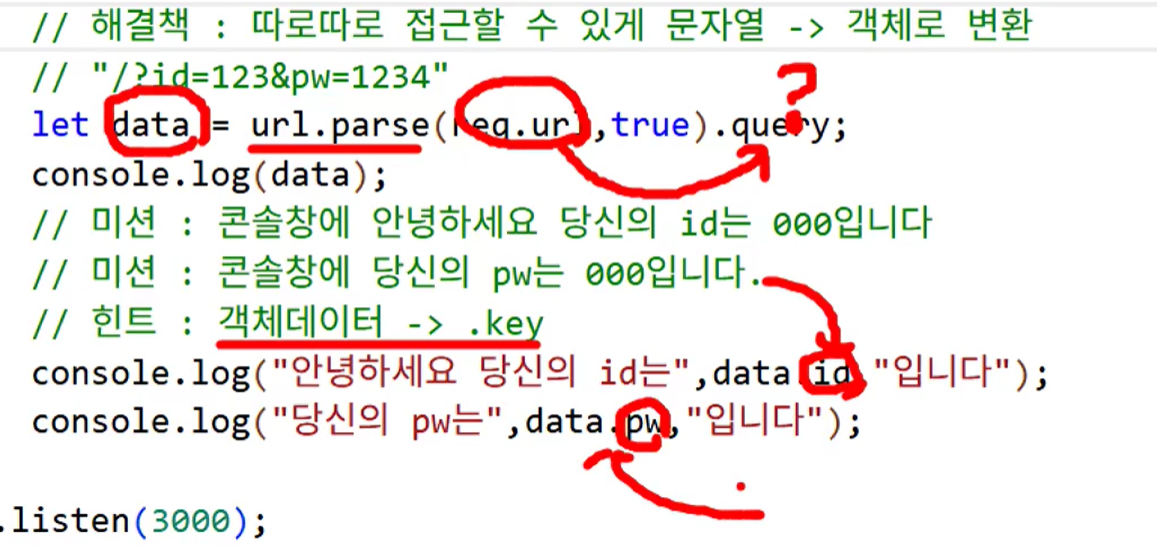
동작하는 방식만 이해하기
- GET 방식
- 사용자가 작성한 데이터를 url에 동반해서 통신
- 보안에 취약
- 보안이 필요 없을 때 사용: 검색 등
- 데이터 처리: String → Object
- 사용처: DB에서 변화가 없을 때 → 조회(SELECT)
- 데이터 용량에 제한 있음
- 보낼 수 있는 데이터의 양이 적음 (대신 빠름)
- POST 방식
- GET 방식의 단점들을 보완
- 데이터가 url에 동반되지 않음
- 데이터가 숨어서 넘어감
- 보안에 조금 더 좋다
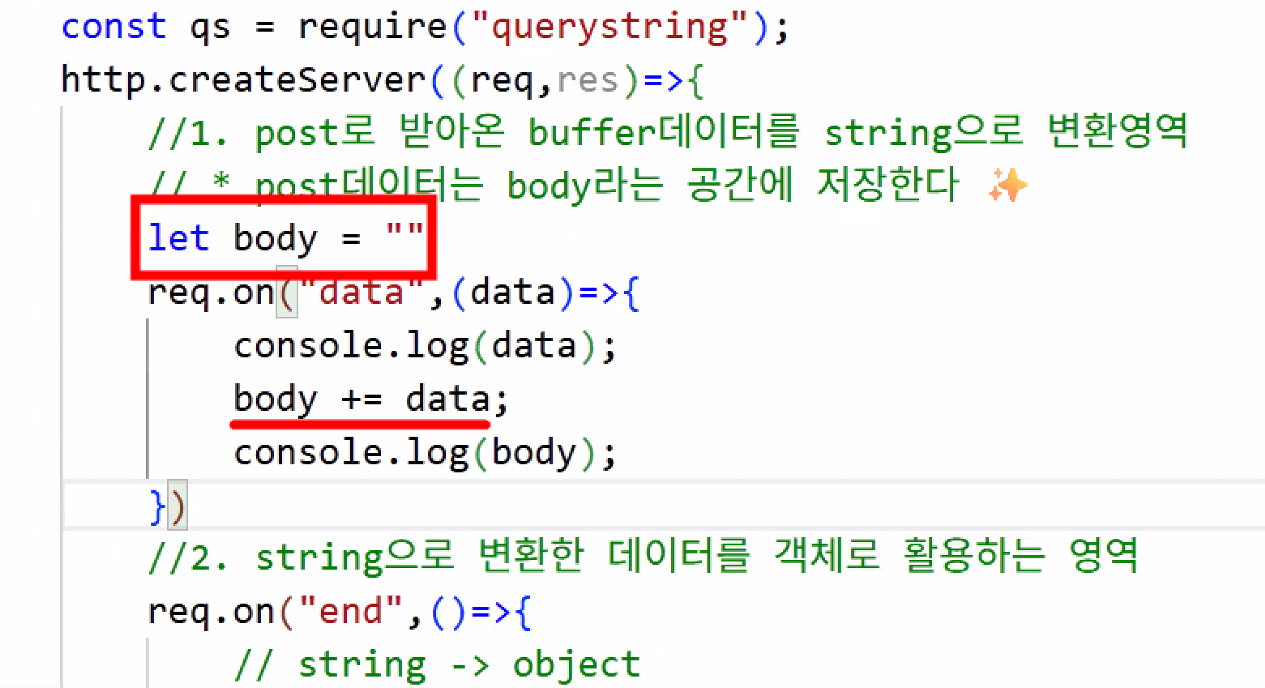
- 데이터 처리: buffer → String → Object
- 사용처: DB에서 변화가 발생할 때 → 삽입(INSERT), 갱신(UPDATE), 삭제(DELETE)
- CRUD 기능: '생성(Create)', '읽기(Read)', '갱신(Update)', '삭제(Delete)'의 네 가지 기본적인 데이터 처리 기능을 의미하며, 데이터베이스나 애플리케이션에서 데이터를 조작하는 데 필수적인 요소입니다. 사용자 인터페이스(UI)에서 정보를 참조, 검색, 갱신하는 기능을 가리키는 용어로도 사용됩니다.
- 데이터 형변환 vs. 파싱
- 데이터 형변환
- 타입을 바꾸는 것 (e.g., 문자 ↔ 숫자)
- 파싱(Parsing)
- 컴퓨터에서 원시 데이터나 텍스트를 특정 규칙에 따라 분해하고 분석하여 구조화된 형태로 변환하는 과정
- 형태 자체를 바꿔버리는 것 (e.g., .xlsx → .csv) : 정확하게는 "데이터 구조 자체"를 바꾸는 것
- 데이터 형변환
- 목표: 내가 받은 데이터를 어떻게든 '객체'로 만들자
- POST 방식
- 객체로 만들기

- 결과

- POST 방식
2. Express
- Framework의 등장
- Node.js: express를 이용하여 빠르고 안정적으로 개발해보자!
- 많아진 기능들을 관리하기가 너무 어려워요!
- 한 개의 서버 파일이 해야 하는 일이 너무 많아짐 → 가독성 문제, 유지 보수 문제
- 그럼 기능들을 모두 쪼개서 관리합시다
- 많아진 기능들을 관리하기가 너무 어려워요!
- express 등장 전까지의 처리 흐름
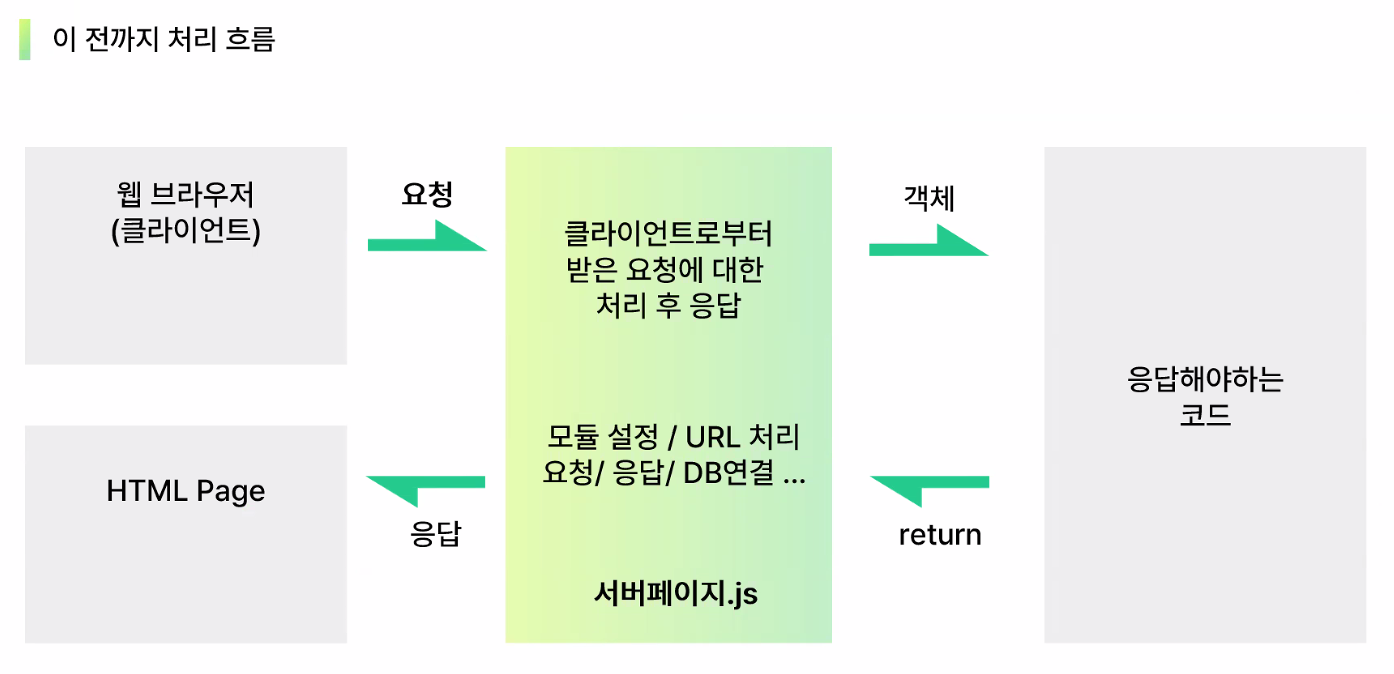
- 사용자가 많아짐 → 업무 과중화 → 서버 하나가 업무를 모두 처리하기에는 너무 부담스러워짐
- 기존 서버 문제점
- 유지보수의 어려움
- 코드의 중복화
- 통일감이 없음 (개발자마다 스타일이 다름)
라이브러리 vs. 프레임워크 ★
- 공통점: 개발에 도움을 주는 도구들
- 개발하는 과정에서 도움이 되는 내용을 모아놓은 것
- 라이브러리(Library)
- 개발을 위해 필요한 기능을 가져다 사용하는 기능들의 모음
- 도구 상자 같은 느낌
- 내가 필요한 기능들을 묶어 놓은 하나의 공간, 덩어리

- 프레임워크(Framework) → "틀", "설계도"
- 개발을 위해 여러 요소들과 메뉴얼인 룰을 제공하는 프로그램
- 공통된 도구를 쓰더라도 개발자마다 전혀 다른 모습으로 만들 수 있음 → 결과물을 일치시키려면 "틀"을 일치시켜야 함
- 공통된 도구를 쓰더라도 개발자마다 전혀 다른 모습으로 만들 수 있음 → 결과물을 일치시키려면 "틀"을 일치시켜야 함
- 개발을 위해 여러 요소들과 메뉴얼인 룰을 제공하는 프로그램
| 라이브러리 | 프레임워크 |
|---|---|
| 기능만 가져다 사용 | 제공된 틀 안으로 들어가 주어진 규칙을 지켜가며 사용 |
| 개발자가 골라서 사용 사용의 주체: 개발자 | 정해진 틀대로 개발해야 함 개발의 주체: 틀(프레임워크) |
→ 관성적으로 내가 하던 습관들을 버리고 틀에 맞춰야 함 (e.g., 사용할 이미지 파일은 모두 public 폴더에 넣으세요)
- 왜 라이브러리/프레임워크를 사용할까?
- 코드의 재사용
- 개발 일정 단축
Node.js를 위한 WEB Framework
- Express
- Node.js를 위한 빠르고 개발적이며 간결한 웹 어플리케이션 프레임워크
- 처리 흐름
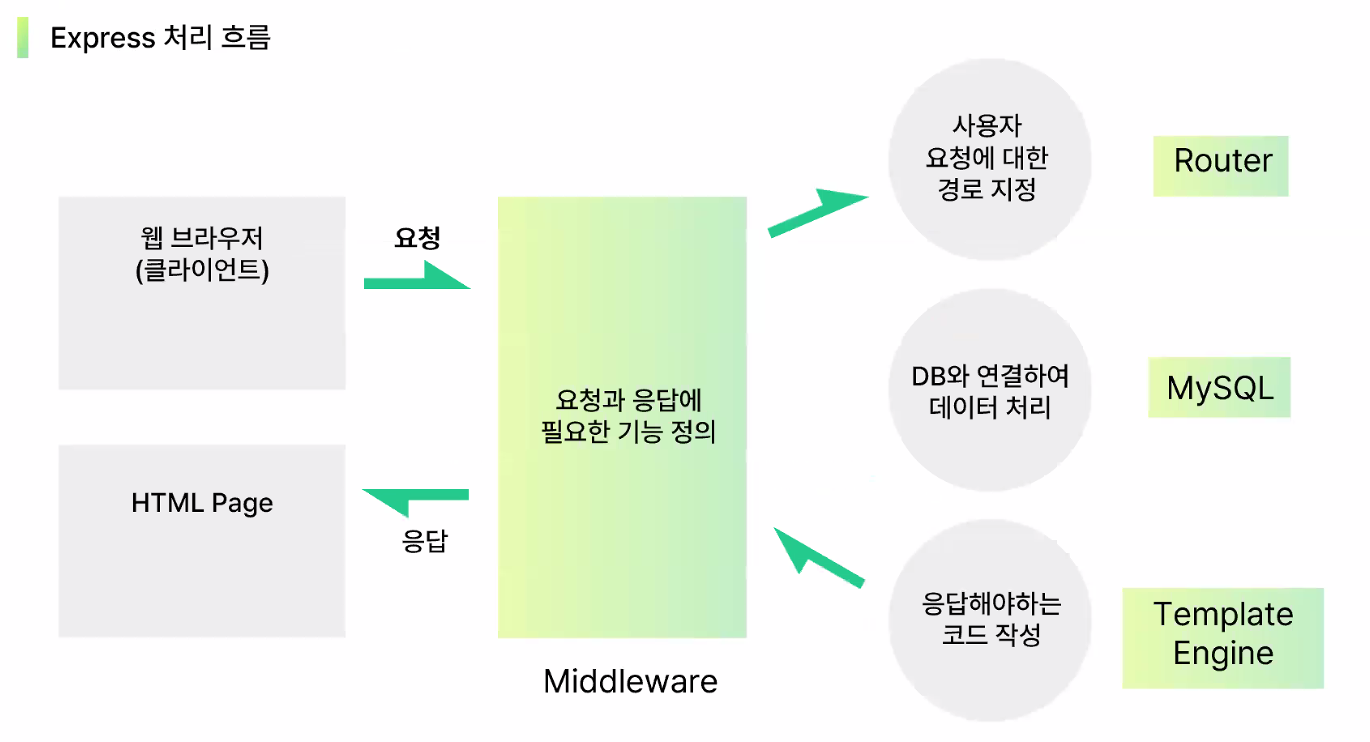
3. 실습: Express 프레임워크
- 이전까지의 코드는 서버 파일 하나에서 모든 업무를 처리하는 구조
- 생성, 파일 응답, DB 연결, …
- 사용자 증가 → 서버의 업무가 과중화 → 업무를 분배해서 관리하자!
- Express의 핵심은 업무 분배
- 업무를 담당할 폴더&파일 만들어서 관리
- 경로 설정하기
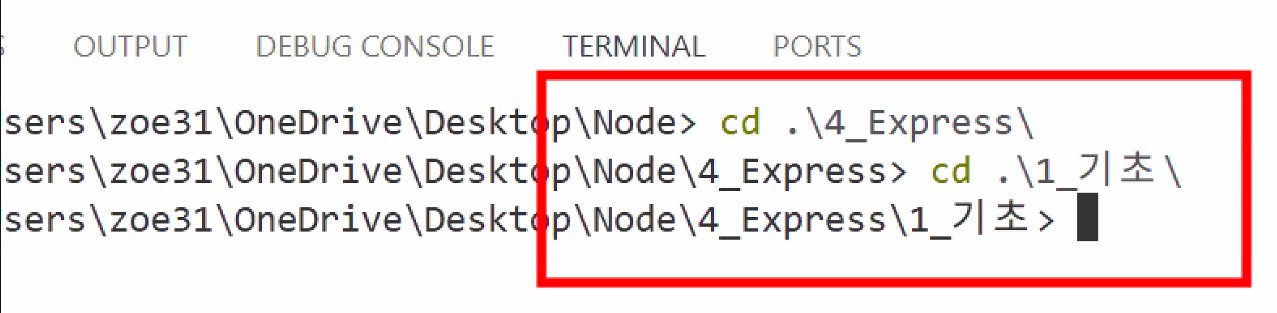
- express 모듈을 설치할 프로젝트 폴더로 경로를 알맞게 설정해 주어야 함
- Express 프레임워크
- 이전까지의 코드는 서버 파일 하나에서 모든 업무를 처리하는 구조
- 생성, 파일 응답, DB 연결, …
- 사용자 증가 → 서버의 업무가 과중화 → 업무를 분배해서 관리하자!
- Express의 핵심은 업무 분배 → 각각의 역할을 쪼개서 관리
- 이전까지의 코드는 서버 파일 하나에서 모든 업무를 처리하는 구조
B. 2교시
1. 필수 폴더 구조 / 파일 ★
- 기본적으로 설정해야 하는 폴더 구조 & 파일
- config: 설정에 관련된 파일들을 관리하는 공간 → DB 정보, API Key, …
- public: 정적인 파일들을 관리하는 공간
- 정적인 파일? 개발자가 손대지 않으면 바뀌지 않는 파일 (CSS, JS, img, video, …)
- 사용자가 들어왔을 때 항상 동일한 화면
- Asset 폴더 쓰는 프레임워크도 있음
- routes: 경로를 담당하는 공간 (사용자의 요청을 처리하는 역할) → 가장 중요한 역할
- "이정표"
- cf. 라우터(router): 분배기. 여러 네트워크를 연결하여 데이터가 적절한 경로를 통해 목적지로 전달되도록 하는 장치.
- views: 동적인 웹 페이지를 관리하는 공간 (사용자 값을 활용한 동적 페이지)
- app.js: 메인 서버 파일 → Express의 컨트롤 타워 (서버 제작, 모든 기능 관리)
TIP: 인터넷의 역사와 전길남 교수님
TIP 2: MPA vs. SPA
Express → MPA
REACT, VUE → SPA → views 폴더가 필요 없음!
- 4가지 폴더 & app.js 파일 만들기
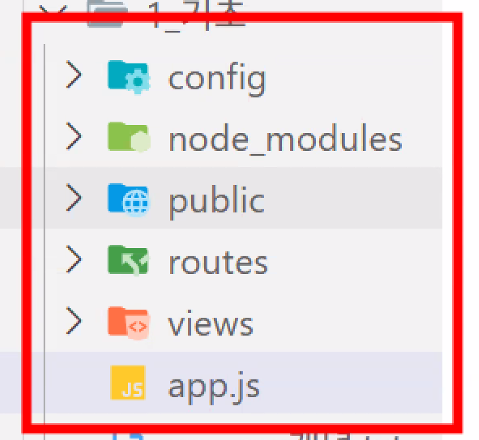
- config
- 설정에 관련된 파일들을 관리하는 공간
- DB 정보, API Key, …
- 설정에 관련된 파일들을 관리하는 공간
- public
- 정적인 파일들을 관리하는 공간
- 정적인 파일? 개발자가 손대지 않으면 바뀌지 않는 파일
- CSS, JS, img, video, …
- 어떤 사용자가 들어오든 항상 동일한 화면
- e.g. 로그인 전 네이버 메인 화면
- tip: 폴더 이름을 public 대신 'Asset'이라 쓰는 프레임워크도 있음
- 정적인 파일들을 관리하는 공간
- routes
- 경로를 담당하는 공간
- "이정표" 역할
- 사용자의 요청을 처리하는 역할 → 가장 중요한 역할!
- cf. router(라우터)
- 분배기
- 여러 네트워크를 연결하여 데이터가 적절한 경로를 통해 목적지로 전달되도록 하는 장치
- 경로를 담당하는 공간
- views
- app.js
- 사용법
- 워크스페이스 생성 (프로젝트를 생성 → 프레임워크는 프로젝트 단위)
- Express 설치 (Express 모듈 → npm i express)
- url, querystring, fs 모듈 등의 기능이 다 들어가 있음
- 폴더 구성
- app.js → 서버 생성
- Express 설치

- 설치가 완료되면 두 개의 json 파일 확인 가능: 매우 중요한 파일이므로 절대 지우면 안 됨
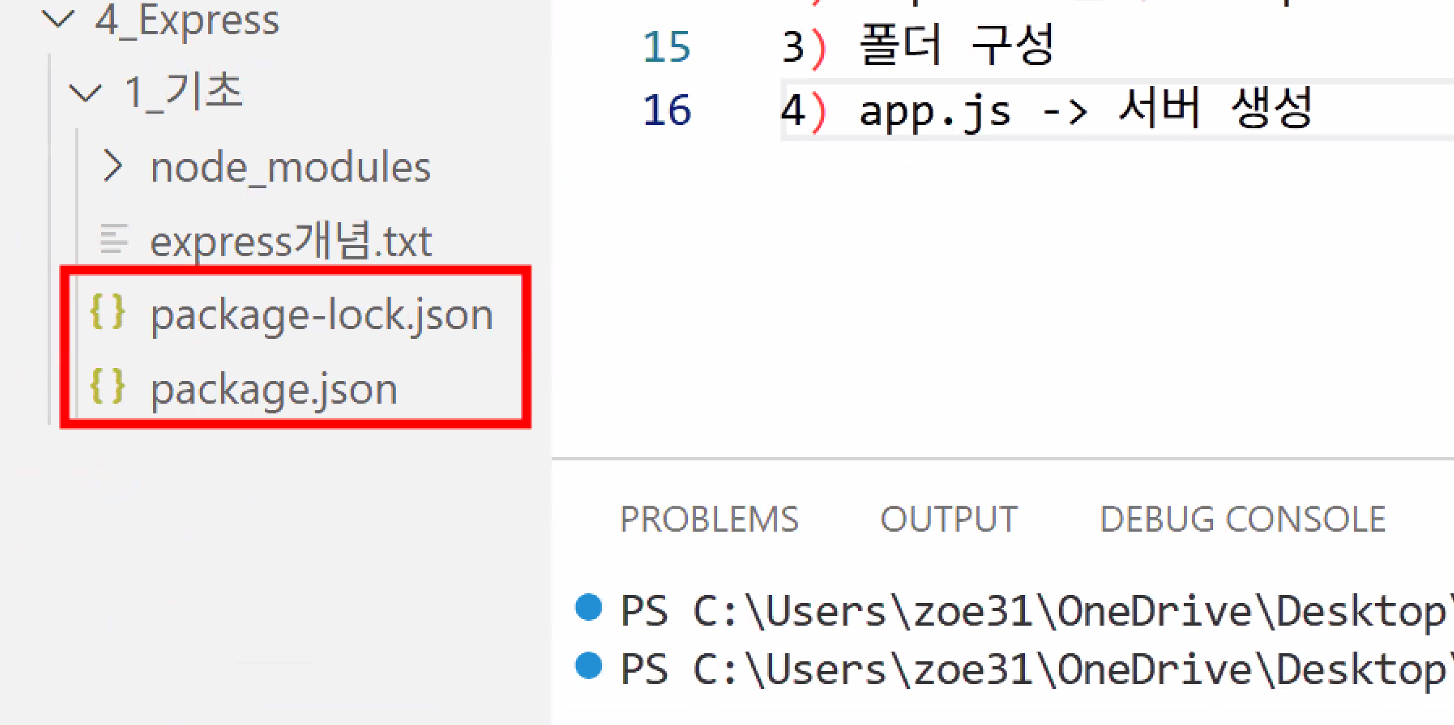
- package.json이 중요한 이유
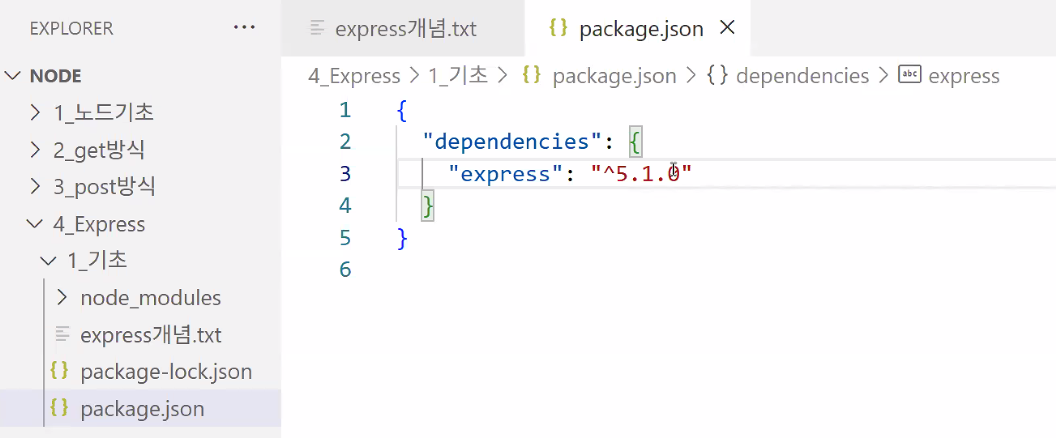
- 모듈에 대한 모든 정보가 모여 있음
- package.json이 있는 위치에서
npm i명령어 실행하면 package.json 안에 적혀 있는 모듈 설치 가능
- 설치가 완료되면 두 개의 json 파일 확인 가능: 매우 중요한 파일이므로 절대 지우면 안 됨
extension: Material Icon Theme
- vscode explorer 디자인 커스텀
2. app.js
- Express의 핵심 파일 → 서버 생성, 업무 분배
- 실질적인 서버 파일
프로세스
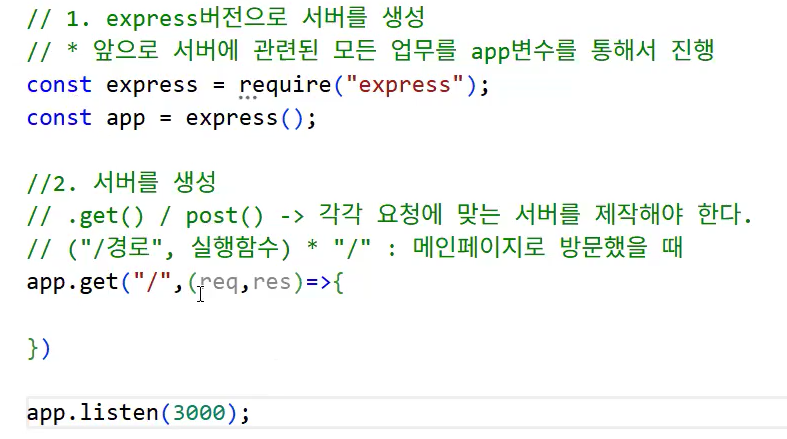
- Express 버전으로 서버를 생성
- 앞으로 서버에 관련된 모든 업무를 app 변수를 통해서 진행
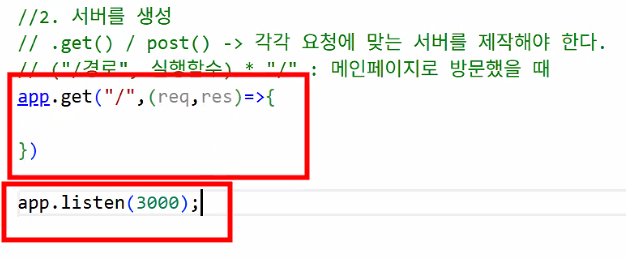
- 서버 생성: app.get() / app.post()
- 각각 사용자의 요청에 맞는 서버를 제작해야 한다.
- e.g., 메인 페이지는 app.get()
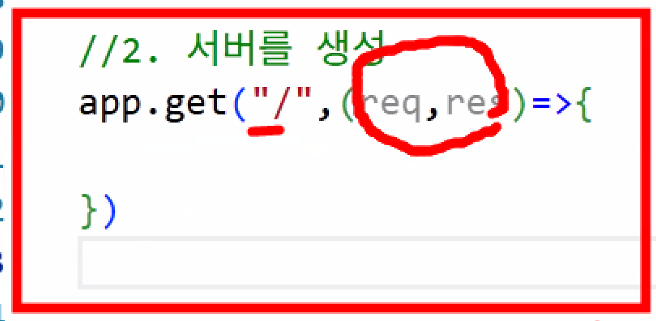
- e.g., 메인 페이지는 app.get()
- 들어가는 매개 변수: ("/경로",실행함수)
- 경로에 "/"만 있는 건 '메인 페이지로 방문했을 때'라는 의미
- 각각 사용자의 요청에 맞는 서버를 제작해야 한다.
- 서버 생성 마지막에 반드시 포트 번호 적어야 함
app.listen(3000);
C. 3교시
1. app.js (cont.)
- 응답 확인하기
- console.log()
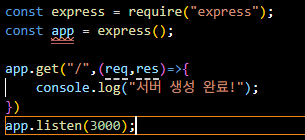
- 실행 결과
- console.log()
- 사용자에게 response 주기
- 응답 메서드 .send()
- writeHead, write, end 기능이 모두 하나로 합쳐짐
- express는 writehead + write + end → send 호출

- 실행 결과

→ 인코딩도 알아서 처리
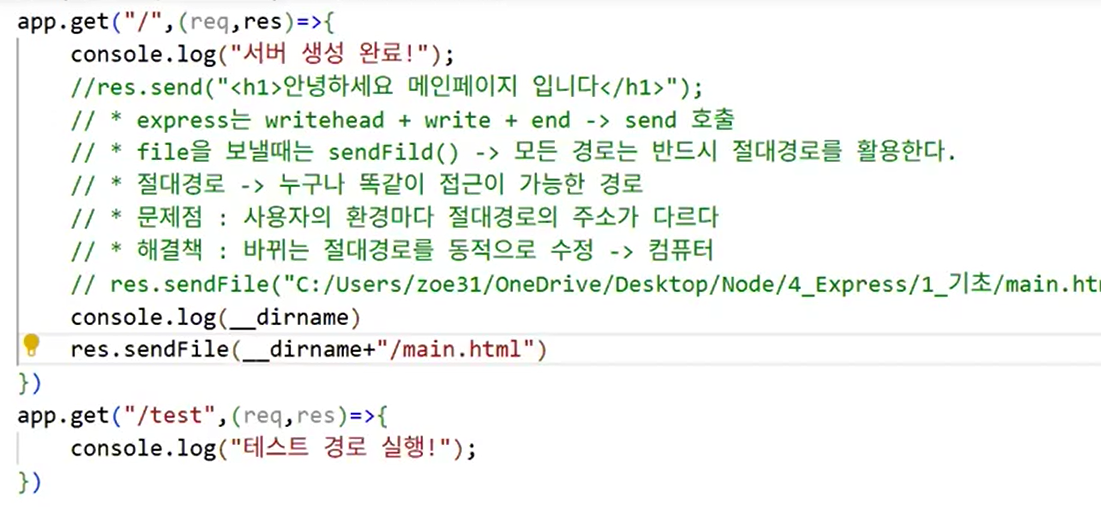
- 응답 메서드 .sendFile()
- fs, async/await 기능이 하나로 합쳐짐
- res.sendFile("main.html");로 쓰면 오류 발생 → 규칙에 어긋나는 작성법이라서
- TypeError: path must be absolute or specify root to res.sendFile
- 프레임워크는 룰과 규칙을 잘 지켜야 함!
- file을 보낼 때는 sendFile() → 모든 경로는 반드시 절대경로를 활용한다.
- 절대경로 → 누구나 똑같이 접근이 가능한 경로
- express 프레임워크의 특징: 틀을 제공해 '누구나 똑같은 환경'을 만듦 → 따라서 절대경로를 강제함!
- 문제점: 사용자의 환경마다 절대경로의 주소가 다르다
- 해결책: 바뀌는 절대경로를 동적으로 수정 → 컴퓨터
__dirname: 현재 작업 중인 파일을 포함하는 폴더까지가 기준
- 응답 메서드 .send()
Ⅱ. 오후 수업
A. 4교시
1. RAG: 웹 페이지 검색
# 웹페이지를 읽어주는 로더
loader = WebBaseLoader(web_path = ['https://n.news.naver.com/article/437/0000440499?sid=103'],
bs_kwargs= dict(
parse_only = bs4.SoupStrainer(
"div", attrs = {'class':['newsct_article _article_body','media_end_head_title',
'media_end_head_info_datestamp']}
)))
# 우리의 문서
docs = loader.load()
# RecursiveCharacterTextSplitter 객체 생성 (청크 최대 개수 1000, 겹치는 부분 100자)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000
, chunk_overlap=100
)
# 문서를 Chunk 단위로 분리하기 (docs)
chunks = text_splitter.split_documents(docs)
# 벡터화(임베딩) → FAISS DB 활용 → DB 저장
faiss_vec = FAISS.from_documents(documents=chunks, embedding=OpenAIEmbeddings())
# 검색기 설정 (유사 2개 데이터 활용)
retriever = faiss_vec.as_retriever(search_kwargs={'k':2}) # dict(k=2)로 써도 됨
# 단순 프롬프트 (해당 웹 페이지 정보에서 찾을 수 없다면 '주어진 정보에서 찾을 수 없습니다.' 출력)
prompt = PromptTemplate.from_template(
"""
당신은 질문-답변을 수행하는 정확하고 친절한 AI 어시스턴트입니다.
당신의 역할은 주어진 문맥(context)에서 주어진 질문(question)에 답하는 것입니다.
만약 주어진 문맥(context)에서 답을 찾을 수 없다면, 혹은 모른다면
'주어진 정보에서 찾을 수 없습니다.'라고 말해주세요.
한글로 답변해 주세요. 단, 기술적인 용어나 고유 이름은 번역하지 않고 그대로 사용해주세요.
{question}
{context}
"""
)
# llm 객체 생성
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# 체인 객체 생성
# RunnablePaththrough: 사용자가 입력한 데이터를 변경하지 않고 그대로 전달
chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser())
result = chain.stream("광주의 날씨는 어떤가요?")
stream_response(result)주어진 정보에서 찾을 수 없습니다.result = chain.stream("광주의 기온은 어떤가요?")
stream_response(result)주어진 정보에서 광주의 기온은 아침에 13도입니다.result = chain.stream("위 기사는 언제 기사인가요?")
stream_response(result)위 기사는 2025년 5월 12일에 작성된 기사입니다.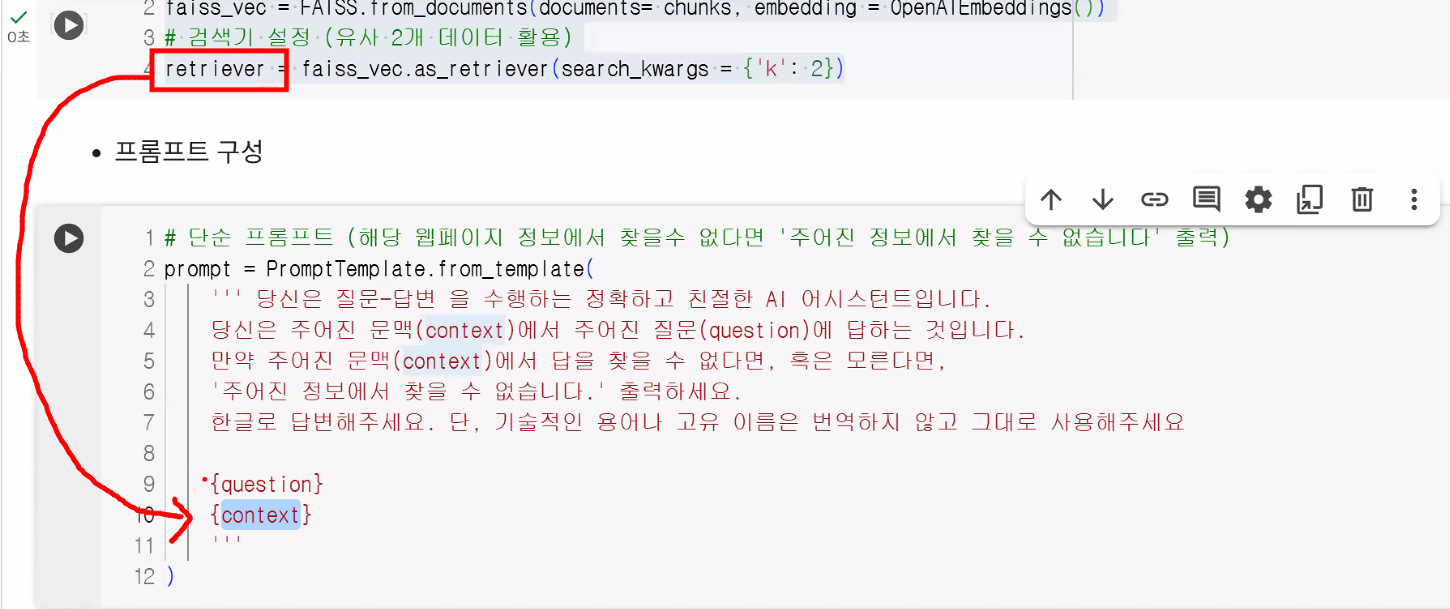
2. RAG: 이미지 검색
멀티모달(Multi Modal)
텍스트, 이미지, 음성, 비디오 등 여러 가지 유형의 데이터(모달리티)를 함께 학습하고 처리하는 인공지능(AI) 또는 기술
- 이미지를 검색해 텍스트로 소통 → 멀티모달!
- 이미지 데이터와 텍스트 데이터를 혼합하는 모델
# 구글 마운트 및 경로 설정(파일 위치 변경)
%cd /content/drive/MyDrive/Colab Notebooks/LangChain
# api key 설정
import os
with open("./key/.openai_api_key",'r') as f:
api_key = f.read().strip()
os.environ["OPENAI_API_KEY"] = api_key
# 라이브러리 다운로드
!pip install -qU openai langchain-openai langchain langchain_community
!pip install -qU tiktoken pypdf chromadb faiss-cpu
!pip install -qU langchain-teddynote
!pip install -qU huggingface_hub langchain_huggingface
# 라이브러리 불러오기
from langchain_community.document_loaders import WebBaseLoader
import bs4
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS, Chroma # Vector DB
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_teddynote.messages import stream_response
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQAWithSourcesChainRAG 기술을 활용하여 이미지 정보 추출 챗봇 만들기
- 멀티모달 모델 사용 (이미지, 텍스트)
- 프롬프트 입력으로 텍스트뿐만 아니라 이미지, 오디오 등 데이터를 사용할 수 있는 모델
- gpt-4o 모델과 gpt-4-turbo 모델: 이미지 인식(vision) 기능이 추가되어 있는 모델임
- gpt-4.1도 가능
- 사용 방법
- OpenAI SDK 호출 방법 (공식)
- LangChain + TeddyNote MultiModal 사용법
B. 5교시
1. RAG: 이미지 검색 (cont.)
teddynote의 MultiModal() 함수 사용해보기
- 내부적으로 OpenAI SDK 호출이 이미 설계된 상태
- 우리는 함수 형태로 가져다가 사용 → 간편
- 단점: 커스터마이징이 어렵다
- Langchain의 확장 패키지 중 하나로 쉽게 멀티모달 기능을 활용할 수 있도록 만들어진 라이브러리
from langchain_teddynote.models import MultiModal
# 모델 생성
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0, max_tokens=400)
# 멀티모달 객체 생성 (시스템 메시지(role)와 사용자 메시지(입력)를 포함)
system_message = "당신은 재무분석 전문가입니다. 재무재표를 분석해 중요한 내용을 정리해 주세요."
human_message = "재무재표를 분석해 기업의 상태를 알려주세요."
multimodal_llm = MultiModal(
llm
, system_prompt=system_message
, user_prompt=human_message
)
# 이미지 전송 후 입력
answer = multimodal_llm.stream("./data/table01.png")
stream_response(answer)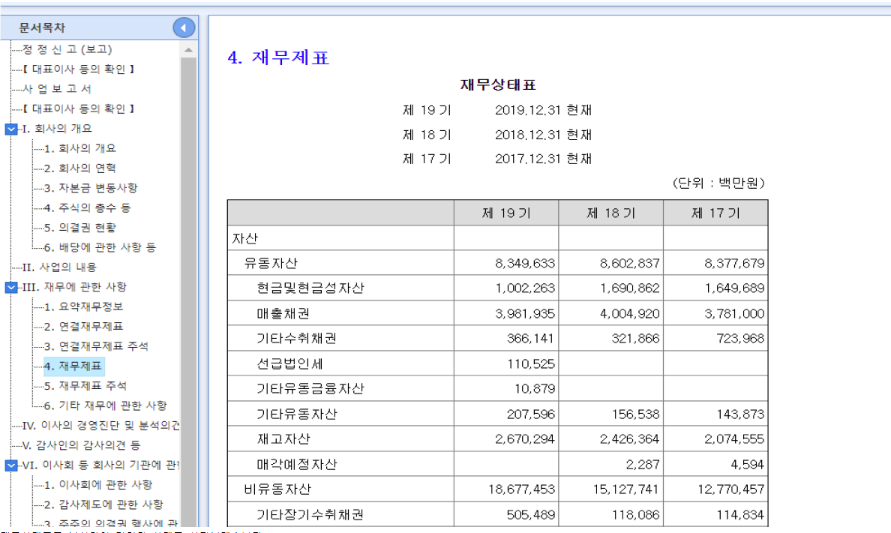
재무재표를 분석하여 기업의 상태를 정리해 보겠습니다.
### 자산 분석
1. **유동자산**:
- 2019년: 8,349,633
- 2018년: 8,602,837
- 2017년: 8,377,679
- **변화**: 유동자산은 2018년에 비해 감소하였으나, 2017년 대비 증가했습니다.
2. **비유동자산**:
- 2019년: 18,677,453
- 2018년: 15,127,741
- 2017년: 12,770,457
- **변화**: 비유동자산은 매년 증가하고 있으며, 이는 기업의 장기적인 투자나 자산 확장을 나타냅니다.
### 총 자산
- 2019년: 27,027,086
- 2018년: 23,730,578
- 2017년: 21,148,136
- **변화**: 총 자산이 매년 증가하고 있어 기업의 성장세를 보여줍니다.
### 결론
- **성장성**: 총 자산과 비유동자산의 증가가 긍정적이며, 기업이 안정적으로 성장하고 있음을 나타냅니다.
- **유동성**: 유동자산의 감소는 단기적인 유동성에 대한 우려를 불러일으킬 수 있으므로, 관리가 필요합니다.
이러한 분석을 바탕으로 기업의 재무 상태는 전반적으로 긍정적이나, 유동성 관리에 주의가 필요합니다. 추가적인 재무 지표나 손익계산서 분석이 필요할 수 있습니다.OpenAI SDK 활용하여 멀티모달 실습
- 막대 그래프, 원 그래프를 이미지화하여 이미지 분석 결과 출력
# 라이브러리 불러오기
import openai
import base64 # 이미지를 base64 문자열로 바꾸기 위한 라이브러리 (base64 → 이진 데이터를 텍스트로 바꿔주는 방식)
import matplotlib.pyplot as plt
import matplotlib.image as pimg # 이미지를 읽거나 저장하는 기능
# 텍스트 질문과 이미지 파일의 경로를 받아 모델에 질문을 보내고 답을 반환하는 함수 정의
# 이미지 + 텍스트 질의
def multimodal (query, image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
# gpt-4o 모델 사용
response = openai.chat.completions.create(
model="gpt-4o"
, messages=[
{
"role":"user"
, "content": [
{"type":"text", "text":query}
, {
"type": "image_url"
, "image_url": {
"url": "data:image/png;base64," + base64.b64encode(image_bytes).decode("utf-8")
}
}
]
}
]
)
return response.choices[0].message.content
# 그래프 이미지 넣어 출력
query="가장 많이 판매된 아이스크림 맛의 종류는 무엇인가요?"
print(multimodal(query, "./data/chart.png"))가장 많이 판매된 아이스크림 맛은 "애플"입니다.# 이미지 출력
img = pimg.imread("./data/chart.png")
plt.imshow(img)
plt.axis("off")
plt.show()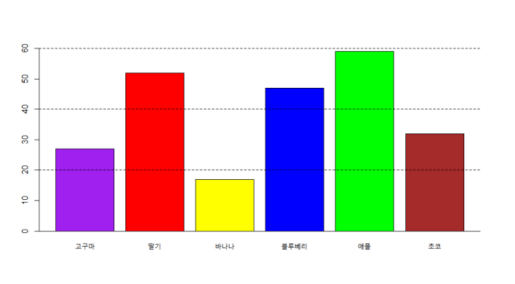
# chart2.png 파일을 활용하여 가장 많이 사용되는 프로그래밍 언어를 출력
query="가장 많이 사용되는 프로그래밍 언어는 무엇인가요?"
print(multimodal(query, "./data/chart2.png"))가장 많이 사용되는 프로그래밍 언어는 C입니다. 32%로 가장 큰 비율을 차지하고 있습니다.img = pimg.imread("./data/chart2.png")
plt.imshow(img)
plt.axis("off")
plt.show()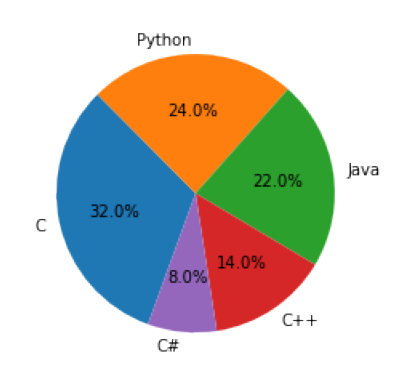
C. 6교시
1. 실습: 멀티모달(OpenAI SDK)
- 메시지 추가하기
def multimodal (query, image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
# gpt-4o 모델 사용
response = openai.chat.completions.create(
model="gpt-4o"
, messages = [
{
"role":"system"
, "content":"당신은 문자 인식 전문가입니다. 이미지에서 텍스트를 추출하세요"
}
, {
"role": "user"
, "content": [
{"type": "text", "text": query}
, {
"type": "image_url"
, "image_url": {
"url": "data:image/png;base64," + base64.b64encode(image_bytes).decode('utf-8')
}
}
]
}
]
,
)
return response.choices[0].message.content
# 이미지 출력
img = pimg.imread("./data/car_number.png")
plt.imshow(img)
plt.axis("off")
plt.show()
# 그래프 이미지 넣어 출력
query="이미지의 번호판 글자를 읽어오세요."
print(multimodal(query, "./data/car_number.png"))
이미지의 번호판은 "112고 8128"입니다.- 도로 노면 표시 텍스트 추출
def multimodal (query, image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
# gpt-4o 모델 사용
response = openai.chat.completions.create(
model="gpt-4o"
, messages = [
{
"role":"system"
, "content":"당신은 문자 인식 전문가입니다. 이미지에서 텍스트를 추출하세요"
}
, {
"role": "user"
, "content": [
{"type": "text", "text": query}
, {
"type": "image_url"
, "image_url": {
"url": "data:image/png;base64," + base64.b64encode(image_bytes).decode('utf-8')
}
}
]
}
]
,
)
return response.choices[0].message.content
# 이미지 출력
img = pimg.imread("./data/load_sign.png")
plt.imshow(img)
plt.axis("off")
plt.show()
# 그래프 이미지 넣어 출력
query="이미지의 도로에 적힌 글자를 읽어주세요."
print(multimodal(query, "./data/load_sign.png"))
도로에 적힌 글자는 "진입금지"입니다.# 이미지 출력
img = pimg.imread("./data/load_sign2.jpg")
plt.imshow(img)
plt.axis("off")
plt.show()
# 그래프 이미지 넣어 출력
query="이미지의 도로에 적힌 글자를 읽어주세요."
print(multimodal(query, "./data/load_sign2.jpg"))
이미지의 도로에 적힌 글자는 "어린이보호구역"입니다.def multimodal (query, image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
# gpt-4.1 모델 사용
response = openai.chat.completions.create(
model="gpt-4.1"
, messages = [
{
"role":"system"
, "content":"당신은 대한민국 도로 위 표지 이미지 인식 전문가입니다. 도로나 표지판에 보이는 노면 표시에 대해 한국 도로교통법에 기반하여 정확하게 답변하세요."
}
, {
"role": "user"
, "content": [
{"type": "text", "text": query}
, {
"type": "image_url"
, "image_url": {
"url": "data:image/jpg;base64," + base64.b64encode(image_bytes).decode('utf-8')
}
}
]
}
]
,
)
return response.choices[0].message.content
# 이미지 출력
img = pimg.imread("./data/load_sign3.jpg")
plt.imshow(img)
plt.axis("off")
plt.show()
# 그래프 이미지 넣어 출력
query="이미지의 도로에 보이는 노면 표시는 무엇을 의미하나요?"
print(multimodal(query, "./data/load_sign3.jpg"))
이미지에 보이는 **마름모(◇) 모양의 노면 표지**는 대한민국 도로교통법상 **"횡단보도 또는 어린이 보호 구역(스쿨존)이나 차로가 좁아지는 지점 등이 가까워짐을 알리는 예고 표시"**입니다.
주요 의미는 다음과 같습니다:
- **횡단보도가 가까워짐을 예고**: 운전자에게 앞에 횡단보도가 있음을 미리 경고하여, 감속 및 주의를 촉구합니다.
- **어린이 보호구역 예고**: 어린이 보호구역이 근접함을 사전에 알려 사고 예방에 도움을 줍니다.
- 그 외에도 **도로 폭이 좁아지거나, 주의가 필요한 구간**이 가까울 때도 사용할 수 있습니다.
이 표지가 보이면 속도를 줄이고, 주변 상황을 잘 살펴보아야 합니다.cf. gpt-4o로 하면 다른 답변이 나옴
def multimodal (query, image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
# gpt-4o 모델 사용
response = openai.chat.completions.create(
model="gpt-4o"
, messages = [
{
"role":"system"
, "content":"당신은 대한민국 도로 위 표지 이미지 인식 전문가입니다. 도로나 표지판에 보이는 노면 표시에 대해 한국 도로교통법에 기반하여 정확하게 답변하세요."
}
, {
"role": "user"
, "content": [
{"type": "text", "text": query}
, {
"type": "image_url"
, "image_url": {
"url": "data:image/jpg;base64," + base64.b64encode(image_bytes).decode('utf-8')
}
}
]
}
]
,
)
return response.choices[0].message.content
# 이미지 출력
img = pimg.imread("./data/load_sign3.jpg")
plt.imshow(img)
plt.axis("off")
plt.show()
# 그래프 이미지 넣어 출력
query="이미지의 도로에 보이는 노면 표시는 무엇을 의미하나요?"
print(multimodal(query, "./data/load_sign3.jpg"))
이미지의 도로에 보이는 노면 표시는 '버스전용차로'를 나타냅니다. 이 마름모 모양의 표시는 버스전용차로가 시작될 것임을 사전에 알리는 역할을 하며, 해당 차로에서는 버스 및 허가된 차량만 통행할 수 있습니다. 일반 차량은 이 차로를 사용해서는 안 됩니다.- 도로의 마름모 노면 표시
- 미국 도로에서는 '다인승 전용 차로'를 의미

- 한국 도로에서는 '행단보도 예고'를 의미
- 경찰청 교통노면표시 설치·관리 업무편람 참고
- 미국 도로에서는 '다인승 전용 차로'를 의미
- 왜 이런 차이를 보일까?
- OpenAI API에서 GPT-4.1과 GPT-4o(Omni)는 같은 세대 모델군이고 학습 데이터 자체도 거의 동일하지만 설계 목적과 학습 구조에 약간 차이가 있기 때문이라고 함
- GPT-4o(Omni): 속도, 멀티모달(텍스트, 이미지, 음성) 상호작용에 최적화 → 일반적인 설명을 빠르게 주는 쪽에 치중하고 세세한 문헌 언급은 덜 강조됨
- GPT-4.1: 텍스트 기반 정밀 추론과 지식 참조에 더 집중 → 공식 문서, 규정, 메뉴얼 같은 근거 있는 자료를 잘 끄렁옴
- 즉, 지식 차이가 아닌 답변 스타일, 우선순위 차이 때문
- 4.1은 깊고 근거 중심
- 4o는 빠르고 대화 친화적
- OpenAI API에서 GPT-4.1과 GPT-4o(Omni)는 같은 세대 모델군이고 학습 데이터 자체도 거의 동일하지만 설계 목적과 학습 구조에 약간 차이가 있기 때문이라고 함
Ⅲ. CAREER UP
데이터베이스 특강
지난 시간 복습
SELECT 문
- SQL 의미와 종류
- SQL 실행 순서
- *와 DISTINCT, AS
- NULL 함수
- 자료형과 함수
- SQL 의미와 종류
- SQL(Structured Query Language): 구조화된 질의 언어
- 데이터베이스가 이해할 수 있도록 특정 문법에 맞춰서 질의하는 것
- 일반적인 영어 키워드를 사용
- DML, DDL, TCL, DCL
- DML(Data Manipulation Language): 테이블에 데이터 입력/삭제/수정
- DDL(Data Definition Language): 데이터 저장소 객체를 생성/수정/삭제
- TCL(Transaction Control Language): 트랜잭션 제어
- DCL(Data Control Language): 객체에 권한 부여
- SQL(Structured Query Language): 구조화된 질의 언어
- SELECT 문 ← DML
- 테이블에서 원하는 데이터를 조회
- 테이블: 엔터티를 모델링하여 DB가 이해할 수 있게 만든 결과 (데이터 저장소 기능)
- 테이블에서 원하는 데이터를 조회
- 구성 요소
- 필요에 따른 SQL문 사용
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- 필요에 따른 SQL문 사용
SELECT 문
관계형 데이터베이스
- 엔터티와 엔터티 간 관계를 통해 구현
- cf. vector DB는 vector를 이용해 구현
SQL 실행 순서
- SQL 문법 작성 순서
- SELCET → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT
- SQL 문법 실행 순서
- FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
| 실행 순서 | 데이터 조작어(DML) | 설명 |
|---|---|---|
| 5 | SELECT | 출력하고 싶은 컬럼만 작성하기 |
| 1 | FROM | 데이터를 가져올 테이블 입력 |
| 2 | WHERE | 원하는 튜플만 가져오도록 필터링(조건문) |
| 3 | GROUP BY | 특정 컬럼을 기준으로 그룹화 |
| 4 | HAVING | 그룹화 상테의 데이터를 필터링 |
| 6 | ORDER BY | 특정 컬럼으로 정렬하기 |
- SQL 순서에 따른 실행 원리
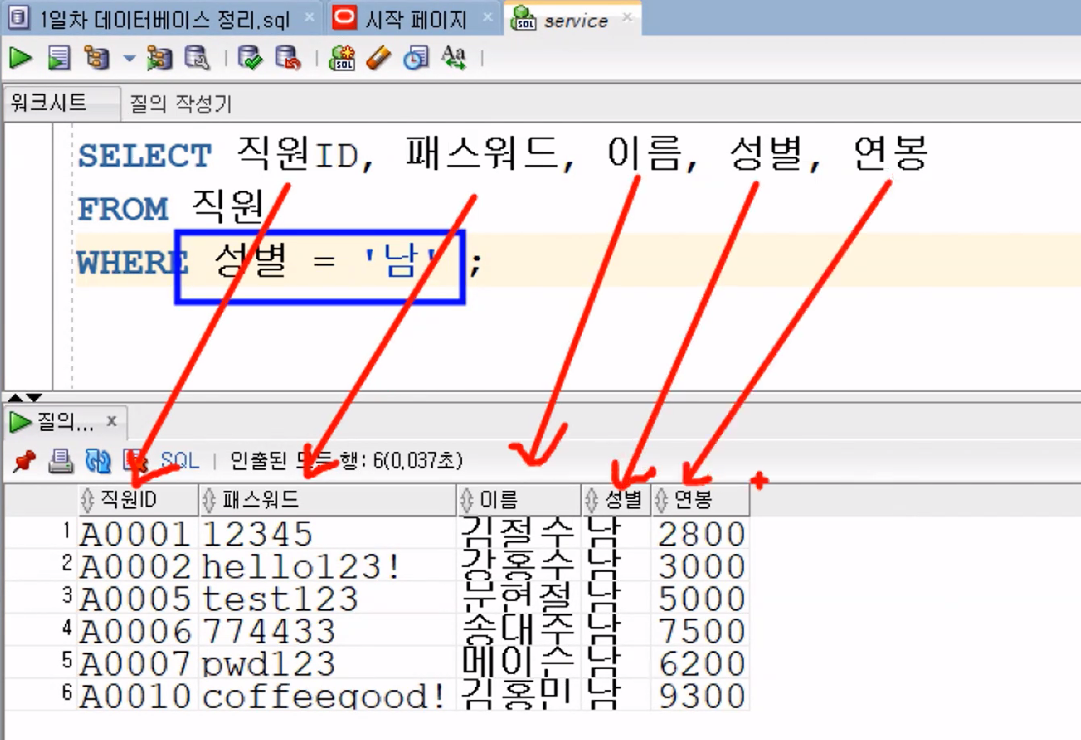
《실행 순서》SELECT 직원ID, 패스워드, 이름, 성별, 연봉 -- ③ FROM 직원 -- ① WHERE 성별='남'; -- ②- 직원 테이블에서(FROM) 데이터를 조회
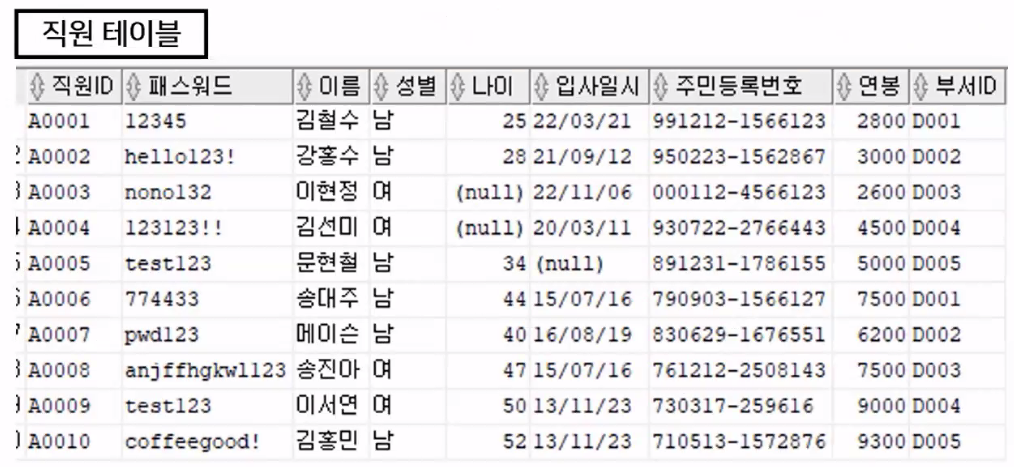
- 직원 테이블의 10개 튜플 중에서 성별 컬럼을 기준으로 '남'인 튜플만 출력
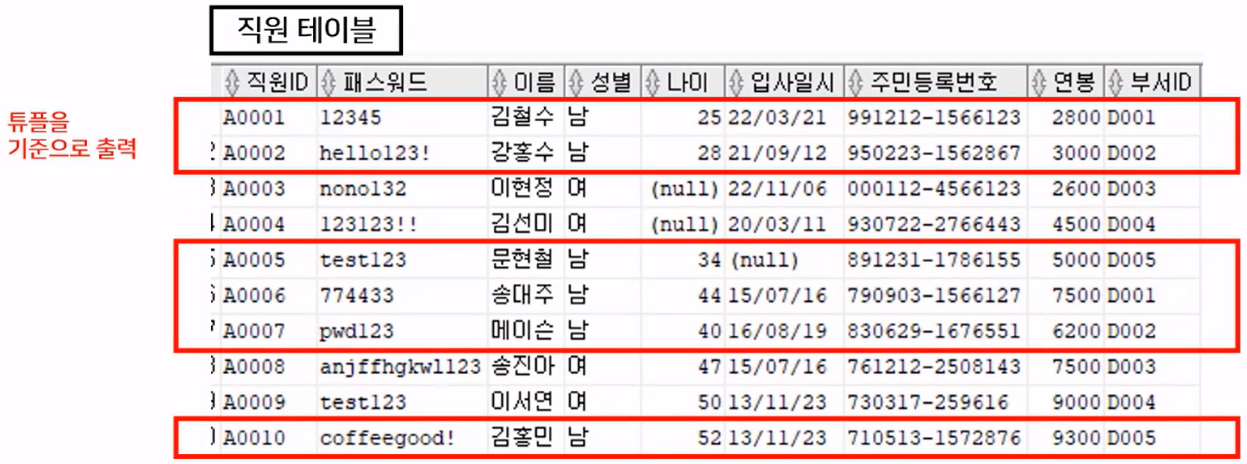
- 필요한 튜플을 다 가져옴!
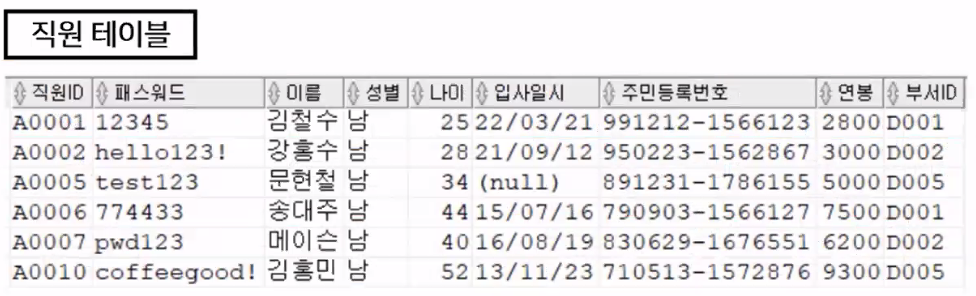
- 필요한 튜플을 다 가져옴!
- 출력되는 튜플 정보에서 직원ID, 패스워드, 이름, 성별, 연봉 정보만 출력
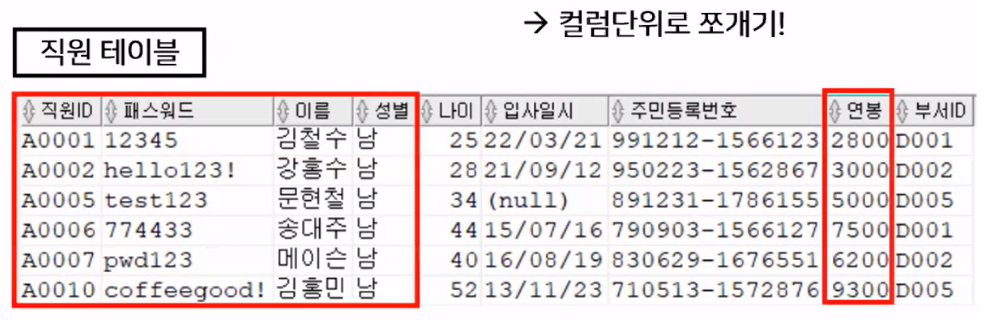
- 실행 결과
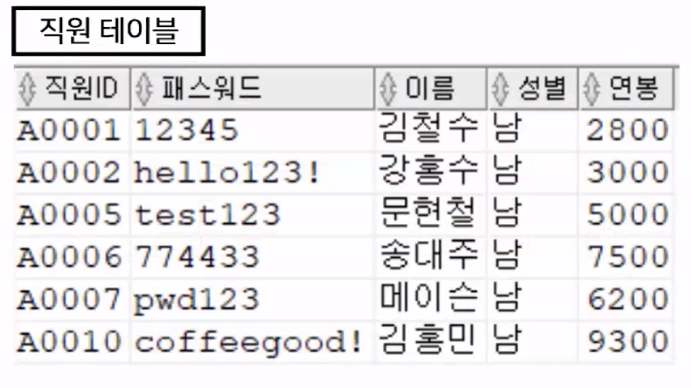
- 실행 결과
- 직원 테이블에서(FROM) 데이터를 조회
- 예시
- 속성 == 컬럼: 엔터티가 가지고 있는 공통적인 특징
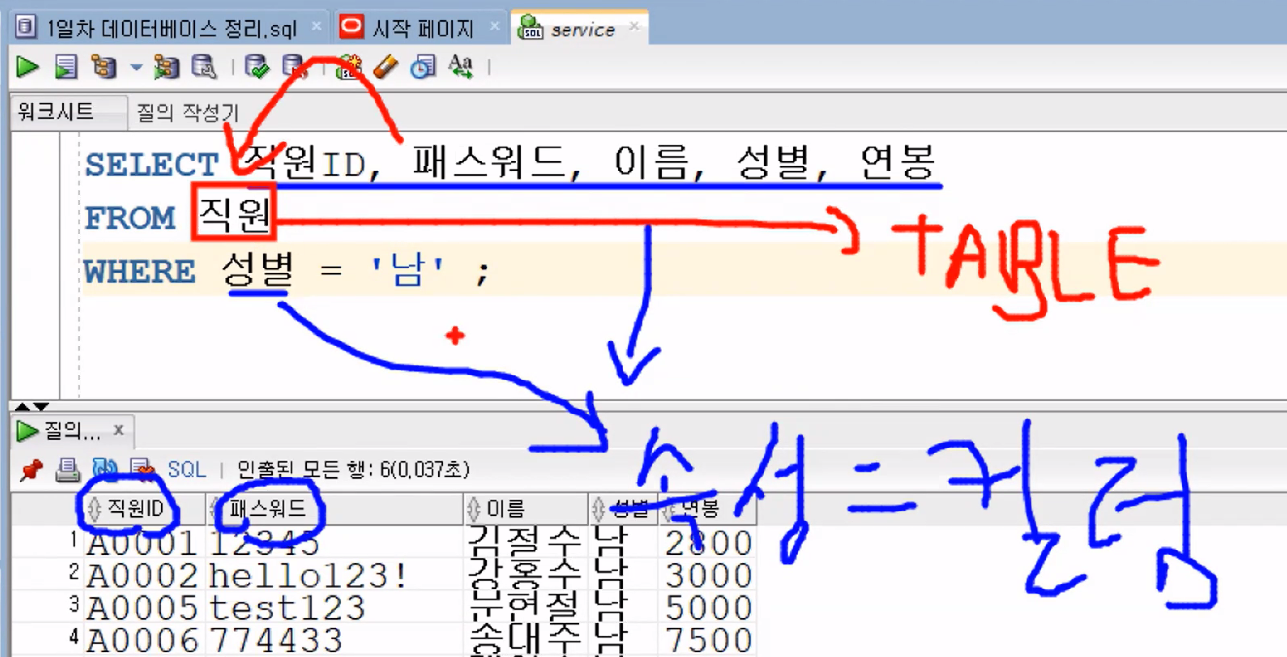
- FROM 절에서 불러온 테이블 안에 있는 속성만 써야 함
- 속성 == 컬럼: 엔터티가 가지고 있는 공통적인 특징
- 실습 문제
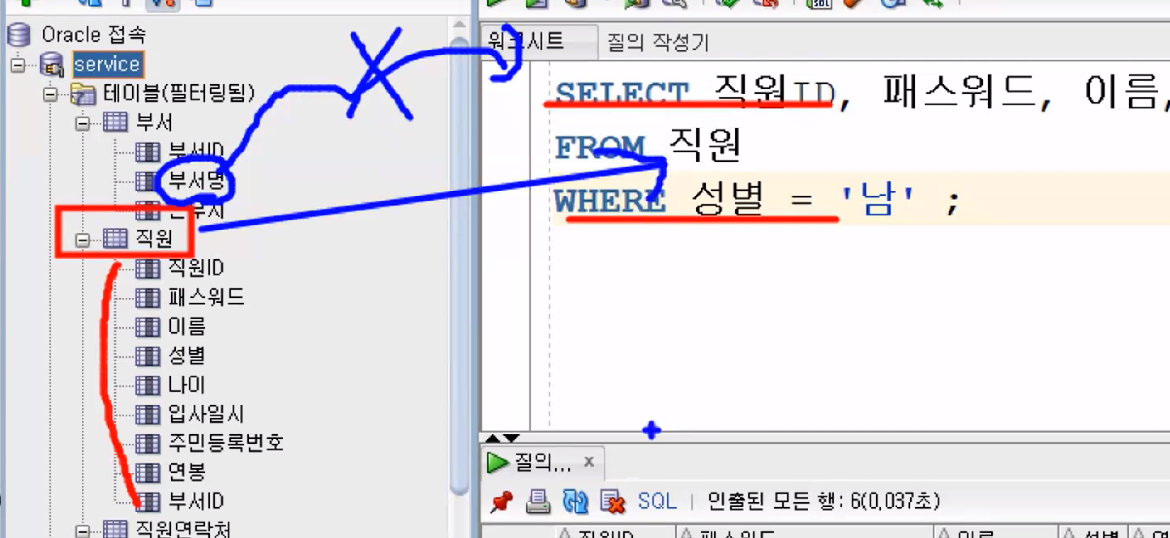
- 직원 테이블에서 직원ID, 입사일시, 주민등록번호, 연봉, 부서ID 정보를 출력해주세요.
- 부서 테이블에서 부서ID, 부서명, 근무지 정보를 출력해주세요.
- 직원연락처 테이블에서 직원ID, 구분코드, 연락처 정보를 출력해주세요.
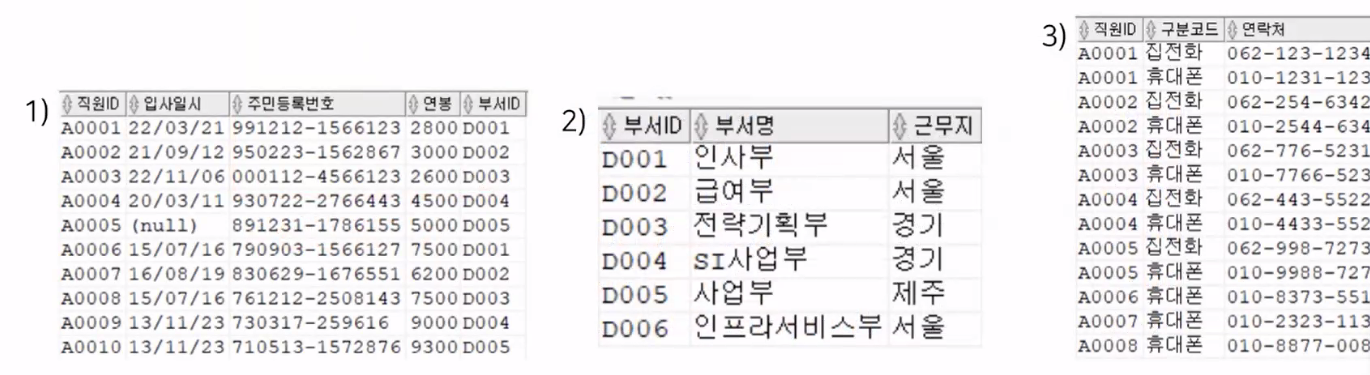
- 풀이

*와 DISTINCT, AS
*(ASTERISK)- 모든 컬럼 정보를 출력하는 키워드
- 모든 컬럼을 직접 입력해도 같은 결과 출력
SELECT *
FROM 직원;
-- 실무에서는 실행하지 않아도 테이블 안에 어떤 컬럼이 있는지 모두 볼 수 있는 걸 선호해서 아래와 같이 씀
SELECT 직원ID, 패스워드, 이름, 성별, 나이, 입사일시, 주민등록번호, 연봉, 부서ID
FROM 직원;- 실습 문제
- 직원 테이블의 모든 컬럼 정보를 출격해주세요.
- 직원주소 테이블의 모든 컬럼 정보를 출력해주세요.

- 풀이

DISTINCT: 출력할 컬럼 정보에서 중복 값을 없애 주는 키워드- Python의 unique 같은 역할
- SQL에서는 unique 예약어가 다른 역할을 하고 있어서 distinct 예약어를 씁니다.
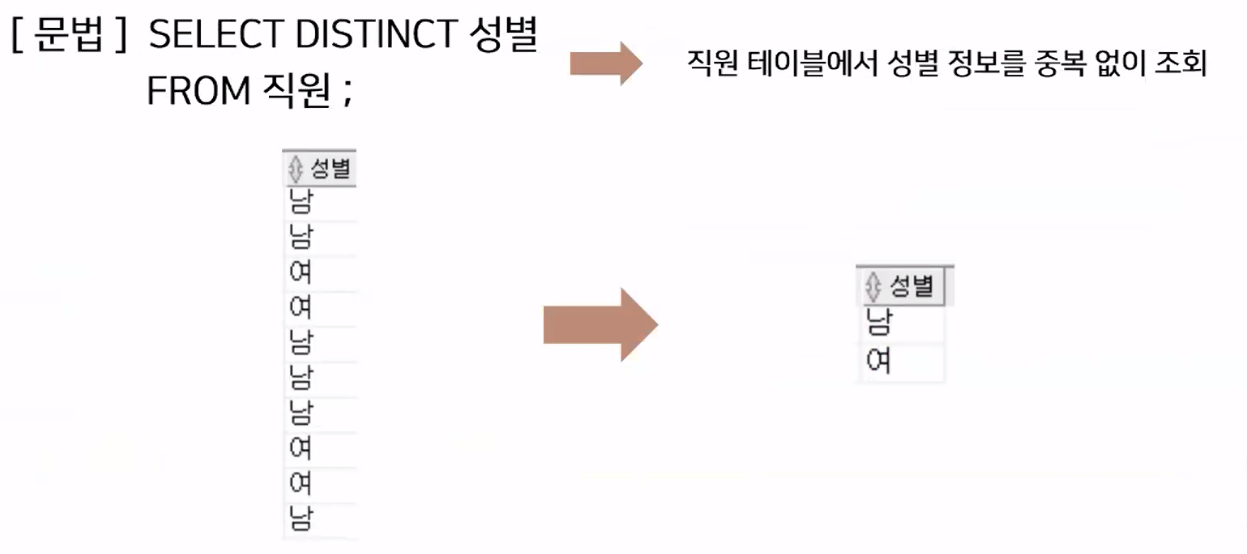
- SQL에서는 unique 예약어가 다른 역할을 하고 있어서 distinct 예약어를 씁니다.
- 컬럼을 여러 개 사용했을 경우?
- 중복 제거할 대상을 '출력할 튜플 단위로' 계산

- 중복 제거할 대상을 '출력할 튜플 단위로' 계산
- Python의 unique 같은 역할
- 실습 문제
- 직원연락처 테이블을 *(Asterisk)로 모든 컬럼 정보를 출력해주세요.
- 직원연락처 테이블에서 직원ID 정보만 중복없이 출력해주세요.

- 풀이

AS(ALIAS): 별칭, 통칭- AS는 SELECT 부분에서 출력하려는 컬럼에 대해 새로운 별칭(alias)을 부여

- SELECT 이외에서도 사용 가능
- 주의 사항
- 별칭 안에 띄어쓰기 불가
- 숫자, 특수문자 시작 불가 (영문자 가능)
- 특수문자는 $,_,#만 가능
- 예약어 불가
- AS 대신에 '공백' 가능(권장X):
SELECT 직원ID EMP_ID
- AS는 SELECT 부분에서 출력하려는 컬럼에 대해 새로운 별칭(alias)을 부여
WHERE 절
- WHERE 사용 이유와 원리
- 비교조건과 논리조건
- IN / BETWEEN / LIKE 조건 (SQL 연산자)
- NULL
WHERE 사용 이유와 원리
- 직원 'A0001'의 정보만 출력하고 싶을 때 → "조건"
- WHERE 문법을 모르는 경우
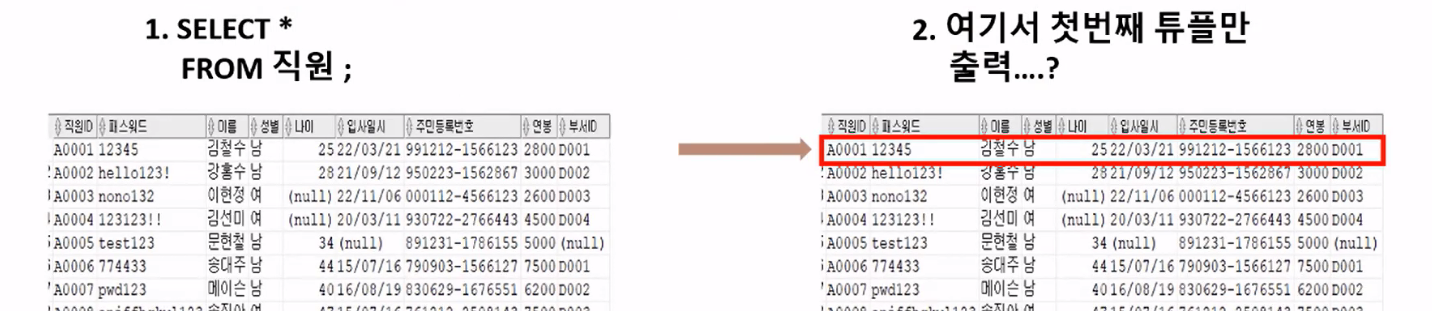
- WHERE 문법을 배우면

- WHERE 문법을 모르는 경우
- 원리
SELECT * FROM 직원 WHERE 부서ID='D001';- 직원 테이블 조회:
FROM 직원 - WHERE 조건에 부합하는 행(튜플) 선택:
WHERE 부서ID='D001'
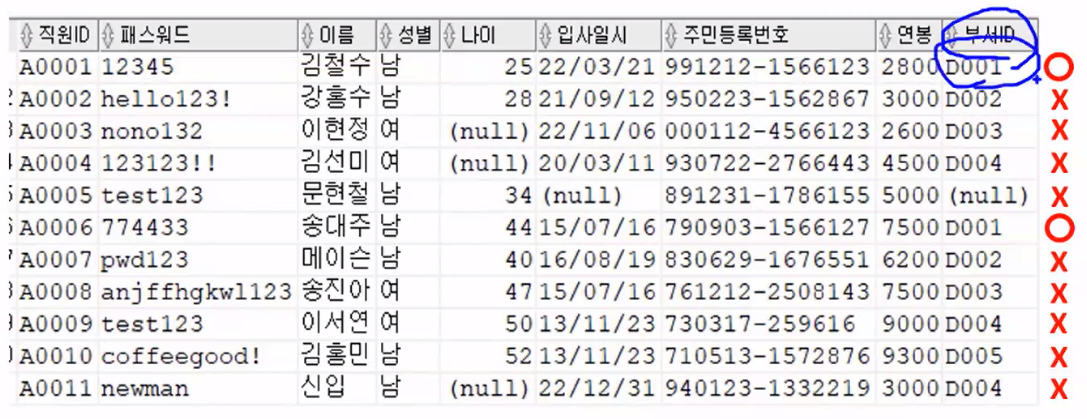
- SELECT에서 가져오려는 컬럼을 출력:
SELECT *

- 직원 테이블 조회:
비교조건과 논리조건
- 비교조건
- =, >, <= 등으로 비교하는 조건
- 동등 조건
- 비동등 조건
- =, >, <= 등으로 비교하는 조건
- 논리조건
- 개발자에게 논리조건이란 → TRUE or FALSE
- AND, OR 사용해 WHERE 조건 이외의 조건 추가 가능
조건1 AND 조건2: 조건1, 조건2 모두 TRUE여야 TRUE 반환. 하나라도 FALSE면 FALSE 반환조건1 OR 조건2: 조건1, 조건2 중 하나만 TRUE여도 TRUE 반환. 모두 FALSE면 FALSE
IN/BETWEEN/LIKE 조건 (SQL 연산자)
- 복잡하고 특별한 계산이 필요할 때 SQL 연산자를 사용
- 예: 직원 ID가 ‘A0001’, A0003’, ‘A0006’인 직원의 정보를 출력해주세요
- 등호(=)는 1:1 연산만 가능
- 1:N 연산 → IN 연산자!
- 예: 직원 ID가 ‘A0001’, A0003’, ‘A0006’인 직원의 정보를 출력해주세요
SELECT *
FROM 직원
WHERE 직원ID='A0001' OR 직원ID='A0005' OR 직원ID='A0007';
-- ↓
SELECT *
FROM 직원
WHERE 직원ID IN ('A0001', 'A0005', 'A0007');IN연산자- '='의 복수형 연산자
- IN 앞에 NOT이 있으면 특정 조건을 제외한 모든 경우 출력
BETWEEN연산자- BETWEEN A AND B의 형태로 사용하면 A와 B 사이에 있는 값을 출력 → 범위조건 연산
- 삼항연산자 이용한 병렬 연산 회피용
- 문자열 형태에도 사용 가능:
WHERE 직원ID BETWEEN 'A0001' AND 'A0004'
LIKE연산자- 매칭 연산자
- ~로 시작하는(끝나는) 단어 탐색
_와%를 이용해 다양한 결과 출력 가능
NULL
- 값이 아직 정해지지 않은 공란, 빈 칸
- cf. Python NaN(Not a Number) → 결측치
- null은 존재하지 않음을 뜻하는 독일어. NA는 not available의 줄임말. NaN은 not a number의 줄임말
- NULL값은 산술, 비교 연산이 불가능!
- BUT! NULL의 이런 특징을 이용해 산술 및 비교를 하는 시험문제는 다수 출제 → 꼭 알고 가야 하는 개념
- NULL이라는 개념을 왜 사용할까?
- 아직 정해지지 않은 값 표현 가능
- 테이블의 특성을 지키기 위해
- NULL 연산은 IS NULL / IS NOT NULL로 출력 가능
- tip: 부정 연산자 NOT
- IS NOT NULL, NOT LIKE 등의 특수한 연산 이외에는 권장 x
- tip: 부정 연산자 NOT
하루 돌아보기
👍 잘한 점
- 대답 많이 하고 질문도 많이 하고 수업 참여 열심히 함
👎 아쉬웠던 점
- 프레임워크를 정식으로 배워보는 게 처음이라 웹 수업에서 Express 다루는 게 아직 감이 잘 안 옴
- 리눅스 시험 잘 볼 수 있을까😅
🔬 개선점
- 시험 보기 전까지 기출문제 열심히 풀기!

2 B R 0 2 B